一种基于深度学习的智能语音交互设备的制作方法
本发明涉及语音交互技术领域,特别是一种基于深度学习的智能语音交互设备。
背景技术:
随着人工智能的不断发展,语音识别技术取得显著进步,开始从实验室走向市场。语音识别技术已经开始进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。
现有技术中,智能音箱也不断走入人们的视野,如,siri系统、小米智能音箱、nano智能音箱以及各种儿童语音交互玩具等。这些系统虽然能够完成基本的交互过程但往往存在以下缺陷,每次输入语音前,需要手动或通过特定的词语将系统调至特定获取语音的状态,才能够顺利识别语音。这就给交互过程带来了不便。
技术实现要素:
本发明的一个目的是提供一种基于深度学习的智能语音交互设备,以解决现有技术中的不足,它能够实时进行拾音,能够使得在语音输出的过程中,也能够准确获得外部的有效语音。使语音交互过程更加智能化。
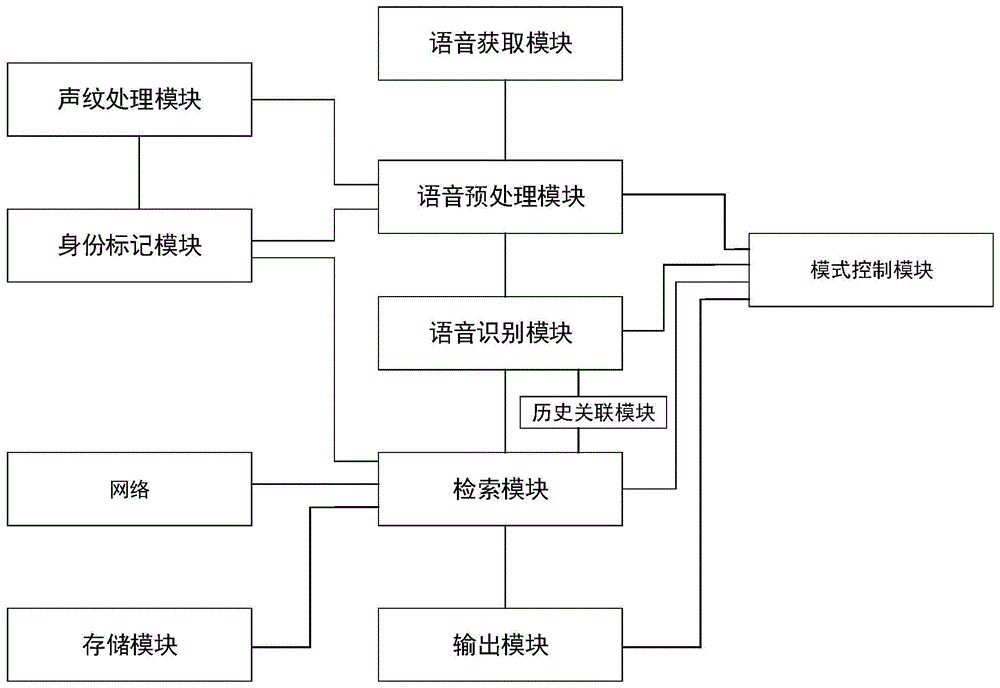
本发明提供了一种基于深度学习的智能语音交互设备,其中,
所述智能语音交互设备具有唤醒模式和非唤醒模式两种状态;该智能语音交互设备包括:
语音获取模块,所述语音获取模块用于实时获取声音信息;
语音预处理模块,所述语音预处理模块与所述语音获取模块连接,所述语音预处理模块用于获取所述声音信息,并对所述声音信息进行噪声滤除,得到目标语音;并在非唤醒模式下判断所述目标语音是否为设定的唤醒词,如果是,进入唤醒模式,如果否,保持非唤醒模式;
语音识别模块,所述语音识别模块用于在唤醒模式下识别所述目标语音,获得目标内容;
检索模块,所述检索模块分别与所述语音识别模块、预存储有应答语句的存储模块连接,所述检索模块用于在唤醒模式下根据所述目标内容从所述存储模块中、或根据所述目标内容从网络上获取应答内容;
输出模块,所述输出模块与所述检索模块连接,所述输出模块用于在唤醒模式下获取所述应答内容,并将所述应答内容输出;
所述智能语音交互设备在设定时间内无内容输出且无声音信息被获取时,进入非唤醒模式。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,还包括模式控制模块,所述模式控制模块分别与所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块电连接;
所述模式控制模块用于获取模式信息,并将当前模式信息分别发送给所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块;
在非唤醒模式下,所述模式控制模块根据所述语音预处理模块的对于所述目标语音是否为设定的唤醒词的判断结果,并在所述目标语音是为设定的唤醒词的情况下,生成唤醒状态标识,并将该唤醒状态标识分别输出给所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块;
在唤醒模式下,所述模式控制模块获取所述应答内容输出完毕的时间节点,并实时监控所述语音预处理模块是否获取到目标内容;如在设定时间内,未获取到目标内容,则生成非唤醒状态标识,并将该非唤醒状态标识分别输出给所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,还包括声纹处理模块和身份标记模块;
所述声纹处理模块分别与所述语音预处理模块和所述身份标记模块电连接;所述身份标记模块与所述检索模块连接;所述声纹处理模块用于在获取到与预设的唤醒词内容相同的目标语音时,获取该目标语音的声纹信息,并查找所述身份标记模块中是否存在与该声纹信息相对应的身份文件,如果是,则将该身份文件与所述检索模块建立关联,以使输出的内容与该身份文件相适配,同时,将本次交互过程中所获取的涉及身份喜好的内容信息存储到对应该声纹的身份文件中,如果否,在所述身份标记模块中生成与该声纹信息相对应的身份文件。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,所述语音获取模块,在获取声音信息时,当所述声音信息中的停顿达设定时间后,将该声音信息记为第一声音信息发送给所述语音预处理模块,并根据所述第一声音信息获取所述第一目标语音;所述语音获取模块断续获取后续声音信息记为第二声音信息;
所述语音识别模块识别所述第一目标语音,获得第一目标内容,并判断所述第一目标内容是否为完整信息,如所述第一目标内容信息是否完整,如不完整,则将所述第一目标语音和所述第二目标语音组合成整体目标语音,并对该整目标语音进行识别,从而得到整体目标内容。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,所述语音预处理模块还与所述输出模块电连接;
在所述输出模块输出语音时:
所述语音预处理模块从所述语音获取模块中获取声音信息、从所述输出模块获取中待滤除声音,所述语音预处理模块将所述待滤除声音从所述声音信息中滤除,得到第三声音信息,并对所述第三声音信息进行识别;判断所述第三声音信息是否为有效语音信息,如果是,控制所述输出模块停止输出语音,并控制所述输出模块输出以所述第三声音信息为基础得到的应答内容,如果否,继续输出正在输出的语音。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,以所述第三声音信息为基础得到应答内容的方法为:
所述语音识别模块识别所述第三声音信息,得到中断目标内容;
检索模块根据所述中断目标内容,从所述存储模块中、或根据所述目标内容从网络上获取应答内容。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,还包括历史关联模块;
所述历史关联模块分别与所述检索模块、所述语音识别模块电连接;
所述历史关联模块用于在进入唤醒模式时,清空;并在唤醒模式时获取所述检索模块检索到的应答内容,将该应答内容记录在所述历史关联模块中;
所述检索模块根据从历史关联模块中获取与所述目标内容相关的历史信息,并根据所述历史信息和所述目标内容获取应答内容。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,所述历史关联模块还用于在输出应答内容被打断后,将对应的所述应答内容从所述历史关联模块中删除。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,所述语音获取模块包括麦克风,所述输出模块包括扬声器。
如上所述的基于深度学习的智能语音交互设备,其中,可选的是,所述语音识别模块基于深度神经网络对语音进行识别。
与现有技术相比,本发明通过将语音获取模块实时获取声音信息,使得交互设备无论在“唤醒模式”还是“非唤醒模式”均能够识别相应的有效语音信息。而在唤醒模式下,在交互的过程中,不需要使用者在每句话前都增加特定的唤醒词,从而能够使交互过程更加的自由和随意,从而提高了交互设备的智能化。另外,由于语音获取模块实时获取声音信息,即便是交互设备正在语音输出的过程中,也能够准确识别有效语音信息,从而允许交互设备在输出语音的过程中,可以被打断,使得交流更加的高效和顺畅。
通过以下参照附图对本发明的示例性实施例的详细描述,本发明的其它特征及其优点将会变得清楚。
附图说明
被结合在说明书中并构成说明书的一部分的附图示出了本发明的实施例,并且连同其说明一起用于解释本发明的原理。
图1是本发明整体框图;
图2是本发明使用时的步骤流程图。
具体实施方式
现在将参照附图来详细描述本发明的各种示例性实施例。应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本发明的范围。
以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本发明及其应用或使用的任何限制。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
在这里示出和讨论的所有例子中,任何具体值应被解释为仅仅是示例性的,而不是作为限制。因此,示例性实施例的其它例子可以具有不同的值。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
请参照图1,本发明提出了一种基于深度学习的智能语音交互设备,
所述智能语音交互设备具有唤醒模式和非唤醒模式两种状态;具体地,本发明中所指的唤醒模式是指,智能语音交互设备能够识别各种语音信息,而在非唤醒模式下,仅能识别特定的唤醒词,如“小a”、“小b”、“开机”、“亲爱的”等,这些唤醒词可以根据需要来具体设置,处于非唤醒模式下的所述智能语音交互设备只有在识别到特定的唤醒词后,才能够识别语音。而无论是唤醒模式还是非唤醒模式下,均能够识别特定的唤醒词,这就保证了当处于唤醒状态后,可以直接进行语音交流而不需要使用者在每次交流前都加上特定的唤醒词。
具体地,所述智能语音交互设备包括:
语音获取模块,所述语音获取模块用于实时获取声音信息;具体实施时,所述语音获取模块包括麦克风,具体地,麦克风的数量为多个,分布在语音交互设备的外周。通过设置语音获取模块,使得无论任何时候,都能够获取声音信息。
语音预处理模块,所述语音预处理模块与所述语音获取模块连接,所述语音预处理模块用于获取所述声音信息,并对所述声音信息进行噪声滤除,得到目标语音;并在非唤醒模式下判断所述目标语音是否为设定的唤醒词,如果是,进入唤醒模式,如果否,保持非唤醒模式。即,当处于唤醒模式下时,不需要对所述目标语音是否为设定的唤醒词进行判断,直接将目标语音输出给语音识别模块。通过在非唤醒模式下对目标语音是否为设定的唤醒词,使得设备能够进入到唤醒模式下。这就意味着,在唤醒模式下,不需要唤醒词就能够进行语音交流,从而能够使语音交流更加方便和有效,使交流过程更加符合人类交流习惯。即,在交流的过程中无需每句话前都需要加入唤醒词。
语音识别模块,所述语音识别模块用于在唤醒模式下识别所述目标语音,获得目标内容。即,所述语音识别模块仅在唤醒模式下工作,在非唤醒模式下不工作。具体地,语音识别模块基于深度学习网络对语音进行识别,所述语音识别模块可以是设置在智能语音交互设备上,也可以是设置在第三方服务器上。语音识别模块与语音处理模块电连接。当然,也可以是将语音预处理模块和语音识别模块均设置在第三方服务器上。但无论是将其设置在交互设备上还是设置在第三方服务器上,只要其实现自身的作用即可。
检索模块,所述检索模块分别与所述语音识别模块、预存储有应答语句的存储模块连接,所述检索模块用于在唤醒模式下根据所述目标内容从所述存储模块中、或根据所述目标内容从网络上获取应答内容。如此,通过设置检索模块,能够快速从目标网络或者存储模块中获取海量的信息,将选择较为匹配的内容作为应答内容。
输出模块,所述输出模块与所述检索模块连接,所述输出模块用于在唤醒模式下获取所述应答内容,并将所述应答内容输出。具体地,所述输出模块还包括语音转换模块,所述语音转换模块用于将所述应答内容转换为语音信息输出,当然,如果该应答内容为视频信息,也可以根据需要直接输出视频信息。如,当存在显示器的情况下,可以直接输出该视频信息。具体实施时,所述输出模块包括扬声器,具体地,也可以根据需要增加显示器。
所述智能语音交互设备在设定时间内无内容输出且无声音信息被获取时,进入非唤醒模式。具体地,当然,所述智能语音交互设备也可以在得到相应的切换为非唤醒模式的指令后,进入非唤醒模式。
具体使用时,请参照图2,开始时交互设备为非唤醒模式,先获取声音信息,并对声音信息进行预处理。判断是否需要进入到唤醒模式,如果是,进入唤醒模式,如果否,保持非唤醒模式。
在进入唤醒模式后,当获取声音信息后,对声音信息进行预处理,并对语音进行识别得到目标内容,并根据目标内容获取应答内容,然后将应答内容输出。如再次获得声音信息后,重复上述操作过程。而再次获得声音信息,并不限于一定要在应答内容完全输出后。
在唤醒模式下,在交互的过程中,不需要使用者在每句话前都增加特定的唤醒词,从而能够使交互过程更加的自由和随意,从而提高了交互设备的智能化。
作为一种较佳的实现方式,还包括模式控制模块,所述模式控制模块分别与所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块电连接。具体,当所述语音识别模块为第三方服务器时,当处于非唤醒状态时,只需要控制不通过网络向语音识别模块发送数据即可。
具体地,所述模式控制模块用于获取模式信息,并将当前模式信息分别发送给所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块。如此,能够通过模式控制模块来保证各模块能够得到统一的模式信息,保证整个交互设备在同一时刻处于同一模式下。
在非唤醒模式下,所述模式控制模块根据所述语音预处理模块的对于所述目标语音是否为设定的唤醒词的判断结果,并在所述目标语音是为设定的唤醒词的情况下,生成唤醒状态标识,并将该唤醒状态标识分别输出给所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块。当各模块获取所述唤醒状态标识后,各模块均进入到唤醒状态,直到获取到非唤醒状态标识。
在唤醒模式下,所述模式控制模块获取所述应答内容输出完毕的时间节点,并实时监控所述语音预处理模块是否获取到目标内容;如在设定时间内,未获取到目标内容,则生成非唤醒状态标识,并将该非唤醒状态标识分别输出给所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块。当各模块收到非唤醒状态标识后,各模块进入到非唤醒状态,直到获取到唤醒状态标识。当然,在具体实施时,为了便于通过语音控制,所述模式控制模块在唤醒状态下,当获取到进入非唤醒状态的指令后,生成非唤醒状态标识,并将该非唤醒状态标识分别输出给所述语音预处理模块、所述语音识别模块、所述检索模块和所述输出模块。
在现有的语音交互设备中,无法通过对交互者的身份识别来进行更加合适的交互过程,尤其是在家庭中使用的语音交互设备中,对于不同人物的需要可能不同,难以使家庭中的所有人都满意的交互体验。为了解决这个问题,本发明中所公开的智能语音交互系统还包括声纹处理模块和身份标记模块。具体地,所述声纹处理模块分别与所述语音预处理模块和所述身份标记模块电连接;所述身份标记模块与所述检索模块连接;所述声纹处理模块用于在获取到与预设的唤醒词内容相同的目标语音时,获取该目标语音的声纹信息,并查找所述身份标记模块中是否存在与该声纹信息相对应的身份文件,如果是,则将该身份文件与所述检索模块建立关联,以使输出的内容与该身份文件相适配,同时,将本次交互过程中所获取的涉及身份喜好的内容信息存储到对应该声纹的身份文件中,如果否,在所述身份标记模块中生成与该声纹信息相对应的身份文件。具体地,本次交互是指从进入唤醒模式到进入非唤醒模式为一次。通过设置身份标记模块,可以将不同使用者的喜好信息以及通常使用的指令加入到对应的身份标记模块中。如此,在后续的使用中,可以根据身份文件中的记录来选择更匹配的内容,以使整个交互过程更加高效且更能令使用者满意。如,通过记录某个使用者经常播放的歌曲的种类信息,在下次接到该使用者播放歌曲的指令时,选择对应的种类的歌曲,进行播放。这就能够使得交互过程更加智能化。
作为一种较佳的实现方式,所述语音获取模块,在获取声音信息时,当所述声音信息中的停顿达设定时间后,将该声音信息记为第一声音信息发送给所述语音预处理模块,并根据所述第一声音信息获取所述第一目标语音;所述语音获取模块断续获取后续声音信息记为第二声音信息。具体实施时,所述设定时间可以是0.5秒、1秒或1.2秒。由于语音获取模块是实时获取声音信息的,对声音信息进行中断,就成了重要的问题。利用停顿对声音信息进行拆分,能够更好地理解交互人员的意思,但在识别中,由于交互人员在说话的过程中,有可能存在停顿,就存在误判的可能,为了解决这种问题。所述语音识别模块识别所述第一目标语音,获得第一目标内容,并判断所述第一目标内容是否为完整信息,如所述第一目标内容信息是否完整,如不完整,则将所述第一目标语音和所述第二目标语音组合成整体目标语音,并对该整目标语音进行识别,从而得到整体目标内容。如此,一方面能够使语音识别的时间缩减,另一方面又能够解决由于交互者在说话停顿时间较长的情况下而产生的无法识别的问题。具体地,第一目标内容信息是否完整,可以根据是否能识别出一句完整的意思来判断。当无法识别第一目标内容信息的意思的情况下,将所述第一目标语音和第二目标语音组合。
由于所述语音获取模块是实时获取语音信息的,也就是说,在输出模块输出语音时,语音获取模块所获取的声音信息包含了输出模块所述输出的声音。为了消除交互设备自身输出声音的影响,所述语音预处理模块还与所述输出模块电连接;在所述输出模块输出语音时:所述语音预处理模块从所述语音获取模块中获取声音信息、从所述输出模块获取中待滤除声音,所述语音预处理模块将所述待滤除声音从所述声音信息中滤除,得到第三声音信息,并通过语音识别模块对所述第三声音信息进行识别;判断所述第三声音信息是否为有效语音信息,如果是,控制所述输出模块停止输出语音,并控制所述输出模块输出以所述第三声音信息为基础得到的应答内容,如果否,继续输出正在输出的语音。第三声音信息是否为有效语音信息,根据所述语音识别模块的识别结果来判断,如第三语音识别模块无法识别出对应的含义,则认为为无效语音信息。
进一步地,以所述第三声音信息为基础得到应答内容的方法为:
所述语音识别模块识别所述第三声音信息,得到中断目标内容。检索模块根据所述中断目标内容,从所述存储模块中、或根据所述目标内容从网络上获取应答内容。
作为一种较佳的实现方式,本交互设备还包括历史关联模块。具体地,所述历史关联模块分别与所述检索模块、所述语音识别模块电连接。
所述历史关联模块用于在进入唤醒模式时,清空。即,清除历史关联模块中之前的历史交互信息,从本次交互开始记录。并在唤醒模式时获取所述检索模块检索到的应答内容,将该应答内容记录在所述历史关联模块中。所述检索模块根据从历史关联模块中获取与所述目标内容相关的历史信息,并根据所述历史信息和所述目标内容获取应答内容。如此,能够在一次交互(包含多次对话)中,对于前后对话内容进行关联,使得交互过程中,能够具有关联性。相比与现有技术中,交互设备无法识别前后句之间关联的现象,本发明能够实现前后对话之间的关联,具有更高的智能性。进一步地,所述历史关联模块还用于在输出应答内容被打断后,将对应的所述应答内容从所述历史关联模块中删除。如此,由于被打断的应答内容通常为无效内容,能够减少历史关联模块的存储量,有利于降低硬件要求。
具体实施时,所述语音识别模块基于深度神经网络对语音进行识别。
虽然已经通过例子对本发明的一些特定实施例进行了详细说明,但是本领域的技术人员应该理解,以上例子仅是为了进行说明,而不是为了限制本发明的范围。本领域的技术人员应该理解,可在不脱离本发明的范围和精神的情况下,对以上实施例进行修改。本发明的范围由所附权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!