一种提取病理语音MFCC特征用于人工智能分析的标准化采样方法与流程
本发明属于智能识别的
技术领域:
,具体涉及一种提取病理语音mfcc特征用于人工智能分析的标准化采样方法。
背景技术:
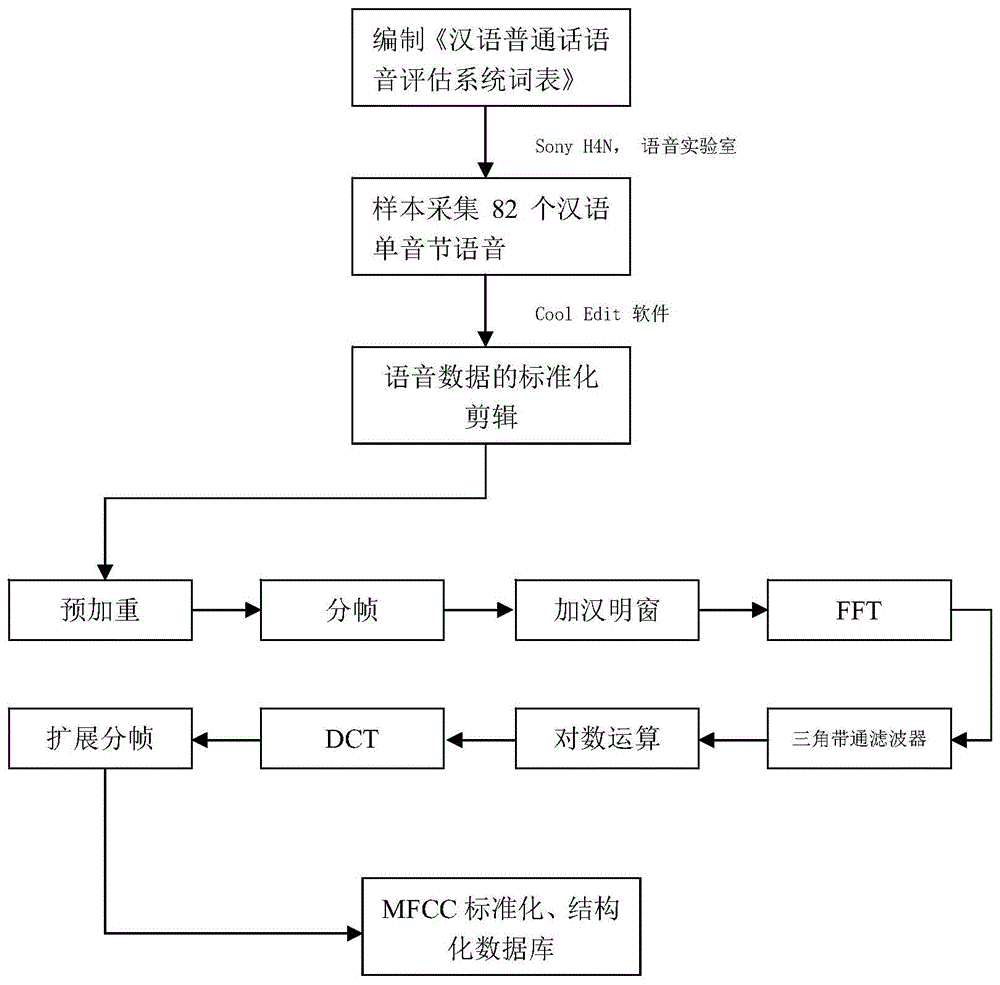
:目前国内语言障碍人数逐年增加,其中构音障碍导致的沟通交流障碍严重影响患者重返社会。虽然我国构音障碍患者数量重多,但是2016年林强和卢建亮的调查研究发现目前的评估方法并不能满足治疗师对精准言语康复的需求。国内康复科和言语康复机构应用较多的仍然是以主观听觉评价和(或)需要主观判断的量表为主要评估手段,缺乏客观性和效率。此外,我国言语治疗师数量严重不足、大多数非本专业毕业,诊断评估能力偏弱。近年来,基于人工智能技术的快速发展,如人工神经网络(artificialneuralnetwork,ann)和深度学习(deeplearning,dl)在正常语音分析与识别、语言教育、智能语音导医等方面的应用研究取得了一些成果。国务院《新一代人工智能发展规划》中涉及医疗方面提出应加快人工智能创新应用,研究声学参数在构音障碍的特征性与规律性,并基于人工神经网络诊断和分类各种构音障碍,从而提高病理语音评估的客观性和效率,解放人力。要对病理语音进行大数据和人工智能分析,必须要有数字化、标准化和结构化的数据集。目前国内外对病理语音的大数据分析、人工智能研究尚无统一方法和标准,亟需一种统一高效的病理语音特征采集方法。技术实现要素:本发明的主要目的在于克服现有技术的缺点与不足,提供一种提取病理语音mfcc特征用于人工智能分析的标准化采样方法,服务于病理语音特征大数据和人工智能分析的各项应用,提高病理语音研究与应用的客观性和效率。为了达到上述目的,本发明采用以下技术方案:一种提取病理语音mfcc特征用于人工智能分析的标准化采样方法,包括下述步骤:采集语音数据,按《汉语普通话语音评估系统词表》的顺序进行82的汉语普通话音节的语音数据采集;对采集的语音数据进行剪辑处理,完成82个音节的剪辑工作,然后分类归档,其中单元音28个,复合元音23个,辅音21个,序列语音10个;对剪辑后的82个音节进行信号提取,通过指定预加重、分帧、加窗、快速傅里叶变换、三角带通滤波器以及扩展分帧处理,提取每个音节的mfcc特征;将处理后的数据构成结构化语音库,mfcc语音库的标准化数据具体为:82个音节样本的每一个音节数据经预处理后的语音样本共有4种mfcc特征分别存在于a、b、c、d四组,分别是13帧、19帧、13+3帧、19+3帧的标准化mfcc数据;结构化数据库:将a、b、c、d四组数据入库元音与声调子库,并分列标记为元音与声调子库a组、元音与声调子库b组、元音与声调子库c组和元音与声调子库d组。作为优选的技术方案,所述《汉语普通话语音评估系统词表》包括3个分表4个主要部分,即单元音声调部分、序列语言部分、复合元音部分和辅音部分;所述单元音与声调部分,由同一或对等音位的声母与单韵母的1-4声调组成的24个单音节汉语普通话词,包括:八,拔,把,爸,逼,鼻,笔,必,都,读,赌,杜,哥,隔,葛,个,波,脖,跛,簸,淤,鱼,雨和玉;序列语言部分,由声母和韵母组成数字1-10的汉语普通话词,包括:1,2,3,4,5,6,7,8,9和10;复合元音部分,由同一或对等音位的声母与复韵母1声调组成的23个单音节汉语普通话词,包括:掰,虾,包,瓜,丢,龟,杯,憋,标,边,班,宾,奔,帮,冰,崩,锅,光,关,沟,乖,靴和兄;辅音部分,由21种声母与单韵母a或i的1声调组成的21个单音节汉语普通话词,包括:八,趴,搭,他,嘎,咖,机,七,知,吃,资,疵,发,哈,西,师,思,日,妈,那和拉。作为优选的技术方案,在进行语音数据采集时,受试者口唇距录音机为9cm-11cm,语速自然平稳、音量适中,将词表重复录2次。作为优选的技术方案,所述预加重具体为:将处理后的语音信号通过下式的高通滤波器进行处理:h(z)=1-μz-1上式中μ的值为0.9-1.0。作为优选的技术方案,所述分帧具体为:分帧时间20-30ms为一分帧,两相邻帧之间重叠区域设置为10-15ms,即帧移;语音样本采样率为8khz或16khz,每分帧采样点n为256-512。作为优选的技术方案,所述加窗具体为:分帧后将每一帧乘以汉明窗,增加帧左端和右端的连续性,假设分帧后的信号为s(n),其中n代表分帧长度减1,s(n)乘上汉明窗后的信号值为x(n),x(n)=s(n)×w(n)其中,w(n)是汉明窗,其公式如下:上式中a值取0.46,n值取0,1,...n-1。作为优选的技术方案,所述快速傅里叶变化具体为:对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱值,并对语音信号的频谱取模平方得到语音信号的功率谱,设定语音信号的离散傅里叶变换,公式如下:上式中x(n)为输入的语音信号,n表示傅里叶变换的点数。作为优选的技术方案,所述三角带通滤波器的处理具体为:将xa(k)通过一组24个三角形滤波器,该三角形滤波器中心频率指定为f(m),m=1,2,...,24,各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽,三角带通滤波器的公式如下:上式中,作为优选的技术方案,每个滤波器组输出的对数频率值,hm(k)代入下列公式:作为优选的技术方案,所述离散余弦变换具体为:将s(m)代入下列公式:上式l指mfcc系数阶数,取12-16;m是三角滤波器个数;c(n)为每一分帧的mfcc值;13阶和19阶各分帧连接获得2组mfcc值入库,即a组和b组。作为优选的技术方案,所述扩展分帧具体为:将共振峰f1、f2和f0各中点值作为一个分帧加入a组、b组,获得2组mfcc入库,即c组、d组。本发明与现有技术相比,具有如下优点和有益效果:根据发明人之前在病理语音人工智能识别的研究基础上,设计《汉语普通话构音障碍评估词表》(下文简称,《词表》)。该《词表》中有82个音节的汉语词汇,通过标准化流程方法,提取每个音节特定mfcc特征,构建数字化、标准化、结构化的语音数据库。本发明可服务于病理语音特征大数据和人工智能分析的多种应用,提高病理语音研究与应用的客观性和效率。附图说明图1是本发明的方法流程图;图2是本发明的mel频率滤波器组模式图。具体实施方式下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。实施例在语音识别(speechrecognition)和声纹识别(voiceprintrecognition)方面,最常用到的语音特征就是梅尔倒谱系数(mel-scalefrequencycepstralcoefficients,简称mfcc)。人耳对不同频率的声波有不同的听觉敏感度。从200hz到5000hz的语音信号对语音的听理解度的影响最大。由于低频频域的声音掩蔽的临界带宽较高频小。因此从低频到高频依据临界带宽大小安排由密到疏的28个带通滤波器,对输入信号进行滤波处理。将每个带通滤波器输出的信号能量作为信号的基本特征,这种基于人耳特性的声学特征即为mfcc。人体声道的形状可以用短时功率谱包络的形式呈现,mfcc可以准确表示这个包络,即用声学特征反映声道官腔结构变化,间接反映病理生理改变。此外,由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,兼顾了听觉模型的研究成果,广泛用于数字化语音识别。因此,这种参数比基于声道模型的lpcc相比具有更好的鲁邦性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。综上所述,mfcc适合作为大数据研究和人工智能分析的数字化语音输入特征。本发明的主要技术方案为,按《汉语普通话语音评估系统词表》(表1-表3所示)的顺序进行82个汉语普通话的语音数据采集,根据本专利的规定方法进行预处理,完成82个音节的剪辑工作,每个音节提取mfcc特征,按本方法预处理后进入单元音、复合元音、辅音、序列语言、声调的结构化语音库。更进一步的,所述《汉语普通话语音评估系统词表》包括3个分表4个主要部分,即单元音声调部分、序列语言部分、复合元音部分、辅音部分:单元音与声调部分,由同一或对等音位的声母与单韵母的1-4声调组成的24个单音节汉语普通话词,八(ba1),拔(ba2),把(ba3),爸(ba4),逼(bi1),鼻(bi2),笔(bi3),必(bi4),都(du1),读(du2),赌(du3),杜(du4),哥(ge1),隔(ge2),葛(ge3),个(ge4),波(bo1),脖(bo2),跛(bo3),簸(bo4),淤(yu1),鱼(yu2),雨(yu3),玉(yu4);序列语言部分,由声母和韵母组成数字1-10的汉语普通话词,1(yi1),2(er4),3(san1),4(si4),5(wu3),6(liu4),7(qi1),8(ba1),9(jiu3),10(shi2);复合元音部分,由同一或对等音位的声母与复韵母1声调组成的23个单音节汉语普通话词,掰(bai1),虾(xia1),包(bao1),瓜(gua1),丢(diou1),龟(guei1),杯(bei1),憋(bie1),标(biao1),边(bian1),班(ban1),宾(bin1),奔(ben1),帮(bang1),冰(bing1),崩(beng1),锅(guo1),光(guang1),关(guan1),沟(gou1),乖(guai1),靴(xüe1),兄(xiong1);辅音部分,由21种声母与单韵母a或i的1声调组成的21个单音节汉语普通话词,八(ba1),趴(pa1),搭(da1),他(ta1),嘎(ga1),咖(ka1),机(ji1),七(qi1),知(zhi1),吃(chi1),资(zi1),疵(ci1),发(fa1),哈(ha1),西(xi1),师(shi1),思(si1),日(ri4),妈(ma1),那(na1),拉(la1)。汉语普通话语音评估系统词表1(元音、声调、序列语言)汉语普通话语音评估系统词表2(元音变化、部分韵母)汉语普通话语音评估系统词表3(辅音)序号辅音类型字声母韵母声调1不送气塞音八ba12送气塞音趴pa13不送气塞音搭da14送气塞音他ta15不送气塞音嘎ga16送气塞音咖ka17不送气塞擦音机ji18送气塞擦音七qi19不送气塞擦音知zhi110送气塞擦音吃chi111不送气塞擦音资zi112送气塞擦音疵ci113清擦音发fa114清擦音哈ha115清擦音西xi116清擦音师shi117清擦音思si118浊擦音日ri419鼻音妈ma120鼻音那na121边音拉la1为了进一步的说明本发明的技术方案,以单音节词“巴”为例,做如下介绍:在进行本实施例的标准化采样前,需要进行录音环境的选择。可选的,本实施例的录音环境选择:最在装有隔音门、吸音岩绵的语音实验室内进行,隔音度45db。可选的,本实例的录音仪器及参数选择:选用sonyzoomh4n的录音笔,存储用44.1khz的采样率和16bit的音质,录音后拷贝到计算机硬盘。如图1所示,本实施例一种提取病理语音mfcc特征用于人工智能分析的标准化采样方法,包括下述步骤:s1、采集语音数据,按《汉语普通话语音评估系统词表》的顺序进行82个汉语普通话音节的语音数据采集;具体为:参照《汉语普通话语音评估系统词表》(表1)的82个汉语词汇采集82个汉语普通话音节的语音数据,对受试者进行录音。录音时受试者取端坐位,笔者手拿录音机,受试者口唇距录音机约10cm,当看到屏幕出现“巴”字后,以自然平稳语速、适中音量朗读“巴(/bā/)”,并重复录2次。录音笔记录的波形波动幅度要求在屏幕1/3-2/3范围。s2、对采集的语音数据进行剪辑处理,具体为:将每位受试者的音档用cooleditpro2.1将目标音/bā/第一次录音分别剪切出来。如果第一次录音出现噪音、干扰、波形波动幅度超过窗口值1/3-2/3范围、波形提示能量不足,则选用第二次录音数据进行处理。然后将有效的预处理后样本分类归档至单元音组。s3、对剪辑后的信号进行特征提取:基于剪辑处理后的样本,通过预加重、分帧、加窗、快速傅里叶变换、三角带通滤波器和扩展分帧处理等处理,完成音节/bā/的数字语音信号的mfcc特征提取,具体预处理步骤如下:s31、指定预加重:将处理后的语音信号通过下式的高通滤波器进行处理:h(z)=1-μz-1上式中μ的值为0.97。s32、指定分帧:以时间25ms为一分帧,两相邻帧之间重叠区域设置为10ms,即帧移。语音样本/bā/的采样率为16khz,每分帧长度n值为400。本实施例中取13和19分帧,若不足补零处理。s32、指定加窗:将步骤s32中分帧后将每一帧乘以汉明窗(hammingwindow),以增加帧左端和右端的连续性。假设分帧后的信号为s(n),其中n代表分帧长度减1,s(n)乘上汉明窗后的信号值为x(n),x(n)=s(n)×w(n)w(n)是汉明窗,其公式如下:上式中a=0.46,n=0,1,...n-1。s33、快速傅里叶变换:对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱值,并对语音信号的频谱取模平方得到语音信号的功率谱,设定语音信号的离散傅里叶变换(dft)公式如下:上式中x(n)为输入的语音信号,n表示傅里叶变换的点数。s33、三角带通滤波器:将xa(k)通过一组24个三角形滤波器,该滤波器中心频率指定为f(m),m=1,2,...,24。各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽,如图2示。三角带通滤波器一是对频谱进行平滑化,并有消除谐波的作用,因此不受一段语音的音调或音高影响。二是降低后继运算量。其公式如下:上式中,s34、对数运算,每个滤波器组输出的对数频率值,hm(k)代入下列公式:s35、离散余弦变换(dct),s(m)代入下列公式:上式l指mfcc系数阶数,本方法指定13和19;m是三角滤波器个数,本方法指定为24;c(n)为每一分帧的mfcc值。13阶和19阶各分帧连接获得2个mfcc值入a组、b组。s36、扩展分帧:将/bā/共振峰f1、f2和f0的中点值各作为一个分帧加入a组、b组,获得另外2个mfcc入库c组、d组。s4、将处理后的数据构成mfcc语音库:单音节“巴”在mfcc语音库的标准化数据:82个音节样本的每一个音节数据经[0033]和[0034]预处理后语音样本/bā/共有4种mfcc特征分别存在于a、b、c、d四组,分别是13帧、19帧、13+3帧、19+3帧的标准化mfcc数据结构化数据:上述4组数据入库元音与声调子库,并分列标记为元音与声调子库a组、元音与声调子库b组、元音与声调子库c组和元音与声调子库d组。其它81个音节的处理方法与单音节“巴”的处理方法一样,在此不再赘述本发明研究了新的基于mfcc特征的病理语音标准化采样方法,与传统的语音录音采样方法不同,本发明基于发明人的前期研究成果制定包括82个汉语音节的《词表》,并采用标准化、结构化数据采样方法,基于声学指标mfcc的基础上,将每一个音节处理为4种不同的数据。可方便用于病理语音库的构建、大数据语音分析和人工智能运算的需求。国内针对病理语音的结构化采样标准的研究较少,本发明提供的方法已经在病理语音库、人工神经网络、深度学习等应用上进行了实践,并证明可靠、操作简便,使最终成为本领域的标准成为可能。基于人工智能大数据的评估方法使人力解放,依靠于智能化的发展,是智能化时代的结晶,与智能发展相结合,是时代进步以及科学发展的结果。本发明将为病理语音的人工智能研究与科学诊断提供一种方法选择。上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1