并行神经文本到语音转换的制作方法
并行神经文本到语音转换
1.相关申请的交叉引用
2.本申请是2019年2月15日提交的题为“systems and methods for parallel wave generation in end-to-end text-to-speech(用于在端到端文本到语音中并行波生成的系统和方法)”且发明人为wei ping、kainan peng和jitong chen的美国专利申请第16/277,919号(案号28888-2269(bn181015usn1))的部分继续申请且与其共同待审和共同拥有并要求该申请的优先权权益,而该美国专利申请第16/058,265号是2018年8月8日提交的题为“systems and methods for neural text-to-speechusing convolutional sequence learning(利用卷积序列学习进行神经文本语音转换的系统和方法)”且发明人为sercan ark、weiping、kainan peng、sharan narang、ajay kannan、andrew gibiansky、jonathan raiman和john miller的美国专利申请第16/058,265号(案号28888-2175(bn171012usn1))的部分继续申请且与其共同待审和共同拥有并要求该申请的优先权权益,上述美国专利申请第16/058,265号根据35u.s.c
§
119(e)要求于2017年10月19日提交的题为“systems and methods for neural text-to-speech using convolutional sequence learning(利用卷积序列学习进行神经文本语音转换的系统和方法)”且发明人为sercan ar1k,wei ping,kainan peng,sharan narang,ajay kannan,andrew gibiansky,jonathan raiman和john miller的美国临时申请第62/574,382号(案号28888-2175p(bn171012usn1临时))的优先权。上述每个专利文献的全部内容均通过引用结合到本文中并用于所有目的。
技术领域
3.本公开总体上涉及用于计算机学习的系统和方法,其可以提供改进的计算机性能、特征和使用。更具体地,本公开涉及用于通过深度神经网络的文本到语音转换的系统和方法。
背景技术:
4.人工语音合成系统(通常称为文本到语音(tts)系统)将书面语言转换为人类语音。tts系统被用于各种应用中,诸如人类技术接口,视觉受损的可访问性、媒体和娱乐。从根本上讲,它允许在不需要可视界面的情况下进行人-技术交互。传统的tts系统基于复杂的多级手工设计的管线。通常,这些系统首先将文本转换为紧凑的音频表示,然后使用被称为声码器的音频波形合成方法将该表示转换为音频。
5.由于它们的复杂性,开发tts系统可能是非常劳动密集型的和困难的。最近关于神经tts的工作已经证明了令人印象深刻的结果,产生了具有稍微简单的特征、较少的分量和较高质量的合成语音的管线。关于tts的最优神经网络结构还没有共识。
6.因此,需要用于创建、开发和/或部署改进的说话者文本到语音系统的系统和方法。
技术实现要素:
7.根据本申请的一方面,提供了一种用于使用包括编码器和非自回归解码器的文本到语音tts系统从输入文本合成语音的计算机实现的方法,该方法包括:使用所述tts系统的包括一个或多个卷积层的编码器将所述输入文本编码成包括一组键表示和一组值表示的隐藏表示;使用所述tts系统的所述非自回归解码器对所述隐藏表示进行解码,所述非自回归解码器包括:注意力块,所述注意力块使用位置编码和所述一组键表示来为每个时间步生成上下文表示,所述上下文表示作为输入被提供给多个解码器块中的第一解码器块;以及所述多个解码器块,其中解码器块包括:非因果卷积块,如果所述非因果卷积块是多个解码器块中的所述第一解码器块,则接收所述上下文表示作为输入,如果所述非因果卷积块是多个解码器块中的第二解码器块或后续解码器块,则接收从先前解码器块输出的解码器块作为输入,并输出包括查询和中间输出的解码器块输出;以及注意力块,所述注意力块使用位置编码和从所述非因果卷积块输出的查询来计算与所述中间输出组合以创建用于解码器块的解码器块输出的上下文表示;以及使用一组解码器块输出来生成表示所述输入文本的一组音频表示帧。
8.根据本申请的一方面,提供了一种非暂时性计算机可读介质或媒介,包括一个或多个指令序列,所述一个或多个指令序列在由一个或多个处理器执行时使得执行以下步骤:使用包括文本到语音(tts)系统的一个或多个卷积层的编码器将输入文本编码成包括一组键表示和一组值表示的隐藏表示;使用所述tts系统的非自回归解码器对所述隐藏表示进行解码,所述非自回归解码器包括:注意力块,所述注意力块使用位置编码和所述一组键表示来为每个时间步生成上下文表示,所述上下文表示作为输入被提供给多个解码器块中的第一解码器块;以及所述多个解码器块,其中解码器块包括:非因果卷积块,如果所述非因果卷积块是多个解码器块中的所述第一解码器块,则接收所述上下文表示作为输入,如果所述非因果卷积块是多个解码器块中的第二解码器块或后续解码器块,则接收从先前解码器块输出的解码器块作为输入,并输出包括查询和中间输出的解码器块输出;以及注意力块,所述注意力块使用位置编码和从所述非因果卷积块输出的查询来计算与所述中间输出组合以创建用于解码器块的解码器块输出的上下文表示;以及使用一组解码器块输出来生成表示所述输入文本的一组音频表示帧。
9.根据本申请的一方面,提供了一种信息处理系统,其包括:一个或多个处理器;以及非暂时性计算机可读介质或媒介,包括一个或多个指令序列所述一个或多个指令序列在由一个或多个处理器执行时使得执行以下步骤:使用包括文本到语音(tts)系统的一个或多个卷积层的编码器将输入文本编码成包括一组键表示和一组值表示的隐藏表示;使用所述tts系统的非自回归解码器对所述隐藏表示进行解码,所述非自回归解码器包括:注意力块,所述注意力块使用位置编码和所述一组键表示来为每个时间步生成上下文表示,所述上下文表示作为输入被提供给多个解码器块中的第一解码器块;以及所述多个解码器块,其中解码器块包括:非因果卷积块,如果所述非因果卷积块是多个解码器块中的所述第一解码器块,则接收所述上下文表示作为输入,如果所述非因果卷积块是多个解码器块中的第二解码器块或后续解码器块,则接收从先前解码器块输出的解码器块作为输入,并输出包括查询和中间输出的解码器块输出;以及注意力块,所述注意力块使用位置编码和从所述非因果卷积块输出的查询来计算与所述中间输出组合以创建用于解码器块的解码器块
输出的上下文表示;以及使用一组解码器块输出来生成表示所述输入文本的一组音频表示帧。
附图说明
10.将参考本公开的实施例,其示例可以在附图中示出。这些附图是说明性的,而不是限制性的。尽管在这些实施例的上下文中一般性地描述了本公开,但是应当理解,其并不旨在将本公开的范围限制于这些特定实施例。图中的项目可能不是按比例绘制的。
11.图1a描绘了根据本公开实施例的自回归序列到序列模型。
12.图1b描绘了根据本公开实施例的非自回归模型,该非自回归模型从预训练的自回归模型中提取注意力。
13.图2图示了根据本公开实施例的自回归架构200。
14.图3图示了根据本公开实施例的可选自回归模型架构。
15.图4描绘了根据本公开实施例的使用文本到语音架构的一般概观方法。
16.图5图示了根据本公开实施例的卷积块,该卷积块包括具有门控线性单元的一维(1d)卷积,以及残余连接。
17.图6图示了根据本公开实施例的注意力块。
18.图7示出了根据本公开实施例的非自回归模型架构(即,paranet实施例)。
19.图8图示了根据本公开实施例的卷积块。
20.图9图示了根据本公开实施例的注意力块。
21.图10描绘了根据本公开的实施例的以逐层的方式迭代地细化注意力对齐的paranet实施例。
22.图11描绘了根据本公开实施例的变分自动编码器(vae)框架的简化框图。
23.图12描述了根据本公开实施例的使用paranet实施例来从输入文本合成语音表示的一般方法。
24.图13描绘了根据本公开实施例的计算装置/信息处理系统的简化框图。
具体实施方式
25.在以下描述中,出于解释的目的,阐述了具体细节以提供对本公开的理解。然而,对于本领域技术人员来说,很明显,没有这些细节也可以实践本公开。此外,本领域技术人员将认识到,下面描述的本公开的实施例可以以多种方式实现,例如在有形计算机可读介质上的过程、装置、系统、设备或方法。
26.图中所示的部件或模块是本公开的示例性实施例的说明,并且旨在避免使本公开模糊。还应当理解,在整个讨论中,部件可以被描述为单独的功能单元,其可以包括子单元,但是本领域技术人员将认识到,各种部件或其部分可以被分成分开的部件或者可以集成在一起,包括集成在单个系统或部件内。应当注意,这里讨论的功能或操作可以实现为部件。部件可以用软件、硬件或其组合来实现。
27.此外,图中部件或系统之间的连接并不局限于直接连接。相反,这些部件之间的数据可以被中间部件修改、重新格式化或以其他方式改变。此外,可以使用更多或更少的连接。还应注意,术语“联接”、“连接”或“通信联接”应理解为包括直接连接、通过一个或多个
中间设备的间接连接以及无线连接。
28.说明书中对“一个实施例”、“优选实施例”、“实施例”或“一些实施例”的引用意味着结合该实施例描述的特定特征、结构、特性或功能包括在本公开的至少一个实施例中,并且可以在不止一个实施例中。此外,说明书中不同地方出现的上述短语不一定都指相同的实施例。
29.在说明书的不同地方使用某些术语是为了说明,并且不应被解释为限制。服务、功能或资源不限于单一的服务、功能或资源;这些术语的使用可以指相关服务、功能或资源的分组,这些服务、功能或资源可以是分布式的或聚合的。
30.术语“包括”、“包含”应理解为开放式术语,以下任何列表都是示例,并不意味着限于所列项目。
31.本文中使用的任何标题仅用于组织目的,并且不应用于限制说明书或权利要求的范围。本专利文件中提到的每个参考文献/文件通过引用整体并入本文。
32.此外,本领域技术人员应该认识到:(1)可以可选地执行某些步骤;(2)步骤可以不限于本文所述的特定顺序;(3)某些步骤可以以不同的顺序执行;以及(4)某些步骤可以同时进行。
33.应注意,本文提供的任何实验和结果仅通过说明的方式提供并且使用一个或多个具体实施例在具体条件下执行;因此,这些实验和它们的结果都不应被用来限制本专利文件的公开的范围。
34.a.引言
35.文本到语音(tts),也称为语音合成,长期以来在各种应用中一直是至关重要的工具,例如人机交互、虚拟助理和内容创建。传统的tts系统基于多级手动设计的管道。近年来,基于深度神经网络的自回归模型已经获得了最新的结果,包括高保真音频合成以及更简单的序列到序列(seq2seq)管道。特别地,最流行的神经tts管道之一的实施例包括两个组件(其实施例公开于在2018年8月8日提交的题为“systems and methods for neural text-to-speech using convolutional sequence learning(利用卷积序列学习进行神经文本语音转换的系统和方法)”且发明人为sercan arιk、wei ping、kainan peng、sharan narang、ajay kannan、andrew gibiansky、jonathan raiman和john miller的美国专利申请第16/058,265号(案号no.28888-2175),该专利文献在此全文引入作为参考,为方便起见,该公开内容可以被称为“深度语音3(deep voice 3)或dv3”):(i)自回归序列到序列模型,其从文本生成mel声谱图,以及(ii)自回归神经声码器(例如,wavenet),其从mel声谱图生成原始波形。该管道需要的专业知识要少得多,并且使用音频和副本对作为训练数据。
36.然而,这些模型的自回归性质使得它们在合成时相当慢,因为它们以波形样本或声学特征(例如,声谱图)的高时间分辨率顺序操作。最近,提出了并行wavenet和实施例(其公开于在2019年2月15日提交的题为“systems and methods for parallel wave generation in end-to-end text-to-speech(端到端文本到语音中并行波生成的系统和方法)”且发明人为wei ping、kainan peng和jitong chen的美国专利申请第16/277,919号(案号no.28888-2269),该专利文献在此全文引入作为参考,为方便起见,该公开内容可被称为“clarinet”),以用于并行波形合成,但是它们仍然依赖于自回归或循环分量来预测帧级声学特征(例如,每秒100帧),这在针对并行执行而优化的现代硬件上的合成方面可能是
缓慢的。
37.在该专利文献中,提出了非自回归文本到声谱图模型-完全并行神经tts系统-的实施例。本文提供的一些贡献包括但不限于:
38.1.用于tts的第一非自回归基于注意力的架构的实施例,其是完全卷积的并且将文本转换为mel声谱图。为方便起见,各种实施例通常被称为“paranet”。paranet的实施例以逐层的方式迭代地改进文本和声谱图之间的注意力对齐。
39.2.在语音质量、合成速度和注意力稳定性方面将非自回归paranet实施例与自回归对应实施例进行比较。paranet实施例的合成速度是自回归模型实施例的~46.7倍,同时使用wavenet声码器保持相当的语音质量。有趣的是,与自回归模型实施例相比,非自回归paranet实施例在挑战性测试句子上产生更少的注意力误差,因为它在教师强制训练和自回归推理之间没有麻烦的差异。
40.3.第一完全并行神经tts系统是通过将非自回归paranet实施例与基于逆自回归流(iaf)的神经声码器(例如,clarinet实施例)相结合来构建的。它通过单个前馈传递从文本生成语音。
41.此外,开发了一种新的方法,为方便起见称为wavevae,用于训练iaf作为波形采样的生成模型。与概率密度蒸馏方法相反,可以通过在变分自编码器(vae)框架中使用iaf作为解码器来从头开始训练wavevae。
42.本专利文件的其余部分如下。在章节b中讨论了相关工作。在章节c中描述了非自回归paranet架构的实施例。在章节d中呈现了wavevae实施例。在章节e中提供了实现细节和实验结果,并且在章节f中提供了一些结论。
43.b.相关工作
44.神经语音合成已取得了最新的成果,并得到了广泛的关注。提出了几种神经tts系统,包括:公开于共同转让的在2018年1月29日提交的题为“systems and methods for real-time neural text-to-speech(用于实时神经文本到语音的系统和方法)”的美国专利申请第15/882,926号(案号28888-2105)以及在2017年2月24日提交的题为“systems and methods for real-time neural text-to-speech(实时神经文本语音转换的系统和方法)”的美国临时专利申请第62/463,482号(案号28888-2105p)的新颖架构,上述专利文献中的每一篇通过引用整体并入本文(为方便起见,其公开内容可称为“深度语音1(deep voice 1)或dv1”);公开于公开于共同转让的在2018年5月8日提交的题为“systems and methods for multi-speaker neural text-to-speech(用于多说话者神经文本语音转换的系统和方法)”的美国专利申请第15/974,397号(案号28888-2144)以及在2017年5月19日提交的题为“systems and methods for multi-speaker neural text-to-speech(用于多说话者神经文本语音转换的系统和方法)”的美国临时专利申请第62/508,579号(案号28888-2144p)的新颖架构,上述专利文献中的每一篇通过引用整体并入本文(为方便起见,其公开内容可称为“深度语音2(deep voice 2)”或“dv2”);在深度语音3(参考上文)中公开的新颖架构;在clarinet(参考上文)中公开的新颖架构;以及在tacotron、tacotron 2、char2wav和voiceloop中公开的新颖架构。
45.特别地,tacotron、char2wav以及深度语音3的实施例采用具有注意力机制的seq2seq框架,与传统的多级管道相比产生了简单得多的管道。它们的极好的可扩展性为诸
如语音克隆的若干挑战性任务带来了可喜的结果。所有这些最新的tts系统都基于自回归模型。
46.基于rnn的自回归模型,诸如tacotron和wavernn,在训练和综合上都缺乏并行性。基于cnn的自回归模型,诸如wavenet和深度语音3的实施例,在训练时允许并行处理,但是它们仍然在合成时顺序地操作,因为在下一时间步每个输出元件能够作为输入被传递之前,必须生成各个输出元件。最近,提出了一些非自回归神经机器翻译模型。gu等人(j.gu、j.bradbury、c.xiong、v.o.li和r.socher;非自回归神经机器翻译;iclr,2018)训练以生产力值为条件的前馈神经网络,所述生产力值是从外部对齐系统获得的。kaiser等人(kaiser、a.roy、a.vaswani、n.pamar、s.bengio、j.uszkoreit和n.shazeer;使用离散潜在变量的序列模型中的快速解码;icml,2018)提出了一种用于快速解码的潜在变量模型,同时它在潜在变量之间保持自回归。lee等人(j.lee、e.mansimov和k.cho;通过迭代精化的确定性非自回归神经序列建模;emnlp,2018)通过去噪自编码器框架迭代地细化输出序列。可论证的是,非自回归模型在文本到语音的转换中起更重要的作用,其中输出语音声谱图包括用于具有几个单词的短文本的数百个时间步。就我们所知,该工作是tts的第一非自回归序列到序列(seq2seq)模型,并且提供了比自回归对应实施例高达46.7倍的合成速度。
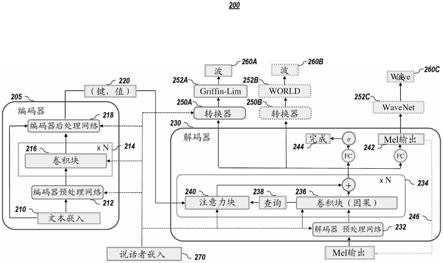
47.归一化流是一族生成模型,其中通过应用一系列可逆变换将简单的初始分布变换为更复杂的初始分布。逆自回归流(iaf)是一种特殊类型的归一化流,其中每个可逆变换基于自回归神经网络。iaf并行地执行合成,并且可以容易地重用表达自回归架构,诸如wavenet,这导致用于语音合成的最新技术的结果。iaf中的似然性评估是自回归的和缓慢的,因此先前的训练方法依赖于来自预先训练的自回归模型的概率密度蒸馏。realnvp和glow是不同类型的归一化流,其中合成和似然性评估都可以通过实施双向架构约束来并行执行。最近,两种方法都被用作并行神经声码器。与自回归和iaf模型相比,这些模型表达性稍逊,因为变量的一半在每次变换之后不会改变。结果,这些双向流通常需要更深的层,更大的隐藏尺寸和大量的参数。例如,waveglow具有~200m参数,而wavenet和clarinet实施例仅使用~1.7m参数,使得它们在生产部署中更优选。在该专利文献中,一个焦点在于自回归且基于iaf的神经声码器。
48.变分自编码器(vae)已被应用于自然语音的表示学习多年。它对波形样本的生成过程或声谱图进行建模。自回归或递归神经网络已经被用作vae的解码器,但是它们在合成时可能相当慢。在这里的实施例中,前馈iaf被用作解码器,其允许并行波形合成。
49.c.非自回归序列到序列模型实施例
50.并行tts系统的实施例包括两个组件:1)前馈文本到声谱图模型,以及2)以声谱图为条件的并行波形合成器。在本节中,首先提出了诸如从深度语音3导出的自回归文本到声谱图模型。然后,提出了paranet实施例-非自回归文本到声谱图模型。
51.通过一般比较,考虑图1a(自回归)和图1b(非自回归)的高阶图表。图1a描绘根据本公开实施例的自回归序列到序列模型。虚线145描述了在推断时对mel声谱图的自回归解码。图1b描绘了根据本公开实施例的非自回归模型,该非自回归模型从预训练的自回归模型中提取(蒸馏)出注意力。
52.1.自回归架构实施例
53.a)示例性模型架构实施例
54.自回归模型的实施例可以基于深度语音3实施例或多个实施例-完全卷积的文本到声谱图模型,其包括三个部分:
55.编码器115:卷积编码器,其获取文本输入并将其编码为内部隐藏表示。
56.解码器125:因果卷积解码器,其利用注意力机制120以自回归的方式将编码器表示解码为对数(log)-mel声谱图135,其中解码器在一时间步处的输出被用作解码器的下一时间步的具有损失的输入,其从1
×
1卷积开始,对输入的对数-mel声谱图进行预处理。
57.转换器130:非因果卷积后处理网络,其使用过去和将来的上下文信息来处理来自解码器的隐藏表示,并预测具有损失的对数线性声谱图。它允许双向处理。
58.在一个或多个实施例中,所有这些部件使用与门控线性单元相同的1-d卷积。paranet模型的实施例和dv3实施例之间的主要区别在于解码器结构。dv3实施例100的解码器125具有基于注意力的多个层,其中每一层包括由注意力块跟随的因果卷积块。为了简化在章节c.3.a中描述的注意力蒸馏,这里的自回归解码器的实施例在其第一层具有一个注意力块。发现减少注意力块的数量通常不会损害所产生的语音质量。
59.图2图示了根据本公开实施例的示例性自回归架构200。在一个或一个以上实施例中,架构200使用编码器205中的残余卷积层将文本编码成用于基于注意力的解码器230的每时间步键和值向量220。在一个或多个实施例中,解码器230使用这些来预测与输出音频相对应的mel标度对数幅度声谱图242。在图2中,虚线箭头246描绘推断期间的自回归合成过程(在训练期间,使用来自对应于输入文本的参考真值(ground truth)音频的mel声谱图帧)。在一个或多个实施例中,解码器230的隐藏状态然后被馈送到转换器网络250,以预测用于波形合成的声码器参数,从而产生输出波260。
60.在一个或多个实施例中,要优化的总目标函数可以是来自解码器和转换器的损耗的线性组合。在一个或多个实施例中,解码器210和转换器250是分开的,并且应用多任务训练,因为它使得注意力学习在实践中更容易。具体来说,在一个或一个以上实施例中,由于除了声码器参数预测之外还用来自mel声谱图预测的梯度(例如,使用mel声谱图的l1损失)来训练注意力,所以mel声谱图预测的损失引导注意力机制的训练。
61.在多说话者实施例中,如在深度语音2实施例中的可训练说话者嵌入270可以在编码器205、解码器230和转换器250上使用。
62.图3图示了根据本公开实施例的可选自回归模型架构。在一个或多个实施例中,模型300使用深度残留卷积网络将文本和/或音素编码成注意力解码器330的每时间步键320和值322向量。在一个或多个实施例中,解码器330使用这些来预测对应于输出音频的mel频带对数幅度声谱图342。虚线箭头346描绘推断期间的自回归合成过程。在一个或多个实施例中,解码器的隐藏状态被馈送到转换器网络350以输出用于griffin-lim 352a的线性声谱图或用于world 352b的参数,其可用于合成最终波形。在一个或多个实施例中,将权重归一化应用于模型中的所有卷积滤波器和完全连接的层权重矩阵。如图3所示的实施例所示,wavenet 352不需要单独的转换器作为输入mel频带对数幅度声谱图。
63.下面表1中提供的模型实施例的示例性超参数。
64.表1:示例性超参数
[0065][0066][0067]
图4示出了根据本公开实施例的用于使用例如图1a、图2或图3中所示的文本到语音架构的一般概观方法。在一个或多个实施例中,使用嵌入模型(诸如文本嵌入模型210)将输入文本转换(405)为可训练嵌入表示。使用编码器网络205将嵌入表示转换(410)为注意力键表示220和注意力值表示220,编码器网络205包括一个或多个卷积块216的序列214。这些注意力键表示220和注意力值表示220由基于注意力的解码器网络使用,以生成(415)输入文本的低维音频表示(例如,242),其中基于注意力的解码器网络包括一个或多个解码器块234的序列234,其中解码器块234包括生成查询238和注意力块240的卷积块236。在一个或多个实施例中,输入文本的低维音频表示可以由预测(420)输入文本的最终音频合成的
后处理网络(例如,250a/252a、250b/252b或252c)进行附加处理。如上所述,可以在过程105、200或300中使用说话者嵌入270,以使得合成的音频呈现与说话者标识符或说话者嵌入相关联的一个或多个音频特征(例如,男性语音、女性语音、特定的口音等)。
[0068]
b)文本预处理实施例
[0069]
文本预处理对于良好的性能是重要的。馈送原始文本(具有间隔和标点的字符)在许多话语上产生可接受的性能。然而,一些发声可能具有罕见单词的错误发音,或者可能产生跳过的单词和重复的单词。在一个或多个实施例中,这些问题可以通过如下对输入文本进行归一化来减轻:
[0070]
1.大写输入文本中的所有字符。
[0071]
2.删除所有中间标点符号。
[0072]
3.用句号或问号结束每个发声。
[0073]
4.替换具有特殊分隔字符的单词之间的空格,上述特殊分隔字符表示由说话者插入的单词之间的停顿的持续时间。在一个或多个实施例中,可以使用四个不同的单词分隔符,表示(i)混合在一起的单词,(ii)标准发音和空格字符,(iii)单词之间的短停顿,以及(iv)单词之间的长停顿。例如,句子“either way,you should shoot very slowly,”,在“way”之后有长停顿,在“shoot”之后有短停顿,则其被写为“either way%you should shoot/very slowly%.”,其中%表示长停顿和/或短停顿以方便编码。在一个或多个实施例中,停顿持续时间可以通过手工标记或由诸如gentle的文本-音频对齐器估计来获得。在一个或多个实施例中,单说话者数据集通过手工来标记,并且多说话者数据集使用gentle来注释。
[0074]
c)字符和音素联合表示的实施例
[0075]
在一个或多个实施例中,部署的tts系统可以优选地包括修改发音以校正常见错误(其通常涉及例如适当的名词、外语词和领域专用术语)的方式。这样做的常规方式是维护字典以将单词映射到它们的语音表示。
[0076]
在一个或多个实施例中,模型可以直接将字符(包括标点符号和间隔)转换为声学特征,并且因此学习隐式字素到音素模型。当模型出错时,这种隐式转换很难校正。因此,除了字符模型之外,在一个或多个实施例中,可以通过显式地允许音素输入选项来训练纯音素模型和/或混合的字符和音素模型。在一个或多个实施例中,除了编码器的输入层有时接收音素和音素重音嵌入而不是字符嵌入之外,这些模型可以与仅字符模型相同。
[0077]
在一个或多个实施例中,仅音素模型需要预处理步骤来将单词转换为它们的音素表示(例如,通过使用外部音素词典或单独训练的音素到音素模型)。对于实施例,使用卡内基梅隆大学发音词典cmudict0.6b。在一个或多个实施例中,混合的字符和音素模型需要类似的预处理步骤,除了不在音素词典中的单词之外。这些词汇表外/词典外单词可以作为字符输入,从而允许模型使用其隐式学习的字素对音素模型。在训练混合的字符-音素模型的情况下,在每次训练迭代时,用其具有一定固定概率的音素表示来代替每个单词。发现这提高了发音精度并最小化了注意力误差,特别是当泛化到比训练期间看到的更长的话语时。更重要的是,支持音素表示的模型允许使用音素词典来校正错误发音,音素词典是所部署的系统的期望特征。
[0078]
在一个或多个实施例中,文本嵌入模型可以包括仅音素模型和/或混合字符和音
素模型。
[0079]
d)用于顺序处理的卷积块实施例
[0080]
通过提供足够大的接收场,堆叠的卷积层可以按顺序利用长期上下文信息,而不会在计算中引入任何顺序相关性。在一个或多个实施例中,卷积块被用作主顺序处理单元以对文本和音频的隐藏表示进行编码。
[0081]
图5图示了根据本公开实施例的卷积块,该卷积块包括具有门控线性单元的一维(1d)卷积,以及残余连接。在一个或多个实施例中,卷积块500包括一维(1d)卷积滤波器510、作为可学习非线性的门控线性单元515、到输入505的残余连接520和缩放因子525。在所描述的实施例中,缩放因子是尽管也可以使用不同的值。缩放因子有助于确保在训练的早期保持输入变化。在图5中所描绘的实施例中,c(530)表示输入505的维度,且大小为2c(535)的卷积输出可被分割540成相等大小的部分:门向量545和输入向量550。门控线性单元提供用于梯度流的线性路径,这减轻了堆叠卷积块的消失梯度问题,同时保持非线性。在一个或多个实施例中,为了引入依赖于说话者的控制,可以在softsign函数之后将说话者依赖嵌入555作为偏置添加到卷积滤波器输出。在一个或多个实施例中,使用softsign非线性,因为它限制了输出的范围,同时也避免了基于指数的非线性有时表现的饱和问题。在一个或多个实施例中,在整个网络中利用零均值和单位方差激活来初始化卷积滤波器权重。
[0082]
架构中的卷积可以是非因果的(例如,在编码器205/305和转换器250/350中)或因果的(例如,在解码器230/330中)。在一个或多个实施例中,为了保持序列长度,对于因果卷积,用左边的k-1个时间步的零填充输入,以及对于非因果卷积,用左边和右边的(k-1)/2个时间步的零填充输入,其中k是奇数卷积滤波器宽度(在实施例中,使用奇数卷积宽度来简化卷积算法,尽管也可以使用偶数卷积宽度和偶数k值)。在一个或多个实施例中,在用于正则化的卷积之前,对输入应用丢弃560。
[0083]
e)编码器实施例
[0084]
在一个或多个实施例中,编码器网络(例如,编码器205/305)从嵌入层开始,嵌入层将字符或音素转换为可训练向量表示。在一个或多个实施例中,首先经由完全连接的层将这些嵌入h
e
从嵌入维度投影到目标维度。然后,在一个或多个实施例中,通过一系列卷积块对它们进行处理,以提取与时间有关的文本信息。最后,在一个或多个实施例中,它们被投影回嵌入维度以创建注意力键向量h
k
。可以从注意力键向量和文本嵌入来计算注意力值向量,以共同考虑h
e
中的局部信息和h
k
中的长期上下文信息。键向量h
k
由每个注意力块用来计算注意力权重,而最终的上下文向量被计算为值向量h
v
上的加权平均。
[0085]
f)解码器实施例
[0086]
在一个或多个实施例中,解码器网络(例如,解码器230/330)通过预测一组以过去音频帧为条件的r个未来音频帧来以自回归方式产生音频。由于解码器是自回归的,在实施例中,它使用因果卷积块。在一个或多个实施例中,选择mel频带对数幅度声谱图作为紧凑的低维音频帧表示,尽管也可以使用其它表示。经验上观察到,将多个帧一起解码(即,其中r>1)产生更好的音频质量。
[0087]
在一个或多个实施例中,解码器网络从具有整流线性单元(relu)非线性的多个完全连接的层开始,以预处理输入的mel声谱图(在图1中表示为“预处理网络(prenet)”)。然后,在一个或多个实施例中,后面跟随一系列解码器块,其中解码器块包括因果卷积块和注意力块。这些卷积块生成用于查看编码器的隐藏状态的查询。最后,在一个或多个实施例中,完全连接的层输出下一组r个音频帧以及二进制“最终帧”预测(指示发声的最后一帧是否已被合成)。在一个或多个实施例中,在注意力块之前,除了第一注意力块之外,在每个完全连接的层之前应用丢弃。
[0088]
可以使用输出mel声谱图来计算l1损失,并且可以使用最终帧预测来计算二进制交叉熵损失。选择l1损失,因为它凭经验得到最佳结果。其它损失,诸如l2,可能受到可对应于非语音噪声的离群值频谱特征的影响。
[0089]
g)注意力块实施例
[0090]
图6图示了根据本公开实施例的注意力块的实施例。如图6所示,在一个或多个实施例中,可以分别以ω
key 405和ω
query 410的速率将位置编码添加到键620和查询638向量。强制单调性可以在逻辑对数上添加一个较大的负值掩码来进行推断。可以使用两种可能的注意力方案之一:softmax或单调注意力。在一个或多个实施例中,在训练期间,注意力权重被丢弃。
[0091]
在一个或多个实施例中,使用点积注意力机制(图6中所示)。在一个或多个实施例中,注意力机制使用来自编码器的查询向量638(解码器的隐藏状态)和每时间步键向量620来计算注意力权重,然后输出作为值向量621的加权平均值计算的上下文向量615。
[0092]
在一个或多个实施例中,通过引入感应偏压(inductive bias)观察到经验益处,其中注意力在时间上遵循单调进展。因此,在一个或多个实施例中,位置编码被添加到键和查询向量两者。这些位置编码h
p
可以被选择为h
p
(i)=sin(ω
s
i/10000
k/d
)(对于偶数i)或cos
s
i/10000
k/d
)(对于奇数i),其中i是时间步索引,k是位置编码中的信道索引,d是位置编码中的信道总数,并且ω
s
是编码的位置速率。在一个或多个实施例中,位置速率指示注意力分布中的线的平均斜率,大致对应于语音速度。对于单说话者,ω
s
可以针对查询设置为1,并且可以针对键固定为输出时间步与输入时间步的比率(在整个数据集上计算)。对于多说话者数据集,ω
s
可以针对每个说话者的来自说话者嵌入的键和查询(例如,在图6中所示)来计算。由于正弦和余弦函数形成了正交基,这种初始化产生了对角线形式的注意力分布。在一个或多个实施例中,用于计算隐藏注意力向量的完全连接的层权重针对查询投影和键投影被初始化为相同的值。位置编码可用于所有注意力块中。在一个或多个实施例中,使用上下文正规化。在一个或多个实施例中,完全连接的层被应用于上下文向量以生成注意力块的输出。总之,位置编码改善了卷积注意力机制。
[0093]
生产质量tts系统对注意力误差具有非常低的容差。因此,除了位置编码之外,还考虑了附加的策略来消除重复或跳过单词的情况。可以使用的一种方法是用单调注意力机制代替规范的注意力机制,其通过期望训练来近似硬单调随机解码和软单调注意力。硬单调注意力也可以通过采样来实现。目的是通过处理经由采样选择的状态来提高推理速度,从而避免在将来的状态上进行计算。本文的实施例不受益于这种加速,并且在一些情况下观察到不良的注意力行为,例如卡在第一个或最后一个字符上。尽管改善了单调性,但是这种策略可以产生更分散的注意力分布。在一些情况下,同时处理几个字符,并且不能获得高
质量的语音。这可能归因于软对齐的非正规化注意力系数,从而可能导致来自编码器的弱信号。因此,在一个或多个实施例中,使用了仅以单调的推断来约束注意力权重的替代策略,从而在没有任何约束的情况下保持训练过程。代替在整个输入上计算柔性最大值(softmax),可以在固定窗口上计算柔性最大值,该固定窗口开始于最后处理的位置并向前进行几个时间步。在实验中,使用尺寸为三的窗口,尽管也可以使用其它尺寸的窗口。在一个或多个实施例中,初始位置被设置为零,并且稍后被计算为当前窗口内的最高注意力权重的索引。
[0094]
2.非自回归架构实施例
[0095]
图7示出了根据本公开实施例的非自回归模型架构(即,paranet实施例)。在一个或多个实施例中,模型架构700可以使用与在先前章节中呈现的自回归模型实施例相同或相似的编码器架构705。在一个或多个实施例中,仅以来自编码器的隐藏表示为条件的paranet的解码器730以前馈方式预测对数-mel声谱图的整个序列。结果,它的训练和合成都可以并行完成。在一个或多个实施例中,编码器705提供键和值710作为文本表示,并且解码器中的第一注意力块715获得位置编码720作为查询,并且之后是一组解码器块734,其包括非因果卷积块725和注意力块735。图8图示了根据本公开实施例的卷积块,诸如卷积块725。在实施例中,卷积块的输出包括查询和中间输出,其中查询可以被发送到注意力块,并且中间输出可以与来自注意力块的上下文表示相组合。图9图示了根据本公开实施例的注意力块,诸如注意力块735。应注意,卷积块800和注意力块900与图5中的卷积块500和图6中的注意力块600类似,除了以下若干例外:(1)与说话嵌入相关的元素已经在两个块中被去除(尽管实施例可以包括它们),以及(2)图9中的注意力块的实施例描述了不同的掩蔽实施例。即,下面更详细地描述的注意力掩蔽。
[0096]
在一个或多个实施例中,可以对诸如dv3的自回归序列到序列模型进行以下主要架构修改,以创建非自回归模型:
[0097]
非自回归解码器730实施例:在没有自回归生成约束的情况下,解码器可以使用非因果卷积块来利用未来的上下文信息并改善模型性能。除了对数-mel声谱图之外,它还预测稍微更好的性能的具有损失的对数线性声谱图。在实施例中,卷积块725的输出包括查询和中间输出,其可以被拆分,其中查询被发送到注意力块,并且中间输出与来自注意力块735的上下文表示相组合,以便形成解码器块730输出。解码器块输出被发送到下一个解码器块,或者如果它是最后一个解码器块,则可以被发送到完全连接的层以获得最终的输出表示(例如,线性声谱图输出、mel声谱图输出等)。)
[0098]
无转换器:非自回归模型实施例去除非因果转换器,因为它们已经采用了非因果解码器。应注意,在深度语音3实施例中引入非因果转换器的动机是基于由非因果卷积提供的双向上下文信息来精细化解码器预测。
[0099]
3.注意力机制实施例
[0100]
对于非自回归模型实施例来说,学习输入文本和输出声谱图之间的精确对齐可能是具有挑战性的。先前的非自回归解码器依赖于外部对齐系统或自回归潜在变量模型。在一个或多个实施例中,提出了几种简单且有效的技术,其通过多步注意力获得精确和稳定的对齐。这里的非自回归解码器的实施例可以以逐层的方式迭代地细化文本和mel声谱图之间的注意力对齐,如图10所示。在一个或多个实施例中,非自回归解码器采用点积注意力
机制,并且包括k个注意力块(参见图7),其中每个注意力块使用来自卷积块的每时间步查询向量和来自编码器的每时间步键向量来计算注意力权重。然后,注意力块将上下文向量计算为来自编码器的值向量的加权平均。在一个或多个实施例中,解码器从注意力块开始,其中,查询向量仅是位置编码(关于其它细节,参见章节c.3.b)。然后,第一注意力块在下一个基于注意力的层为卷积块提供输入。
[0101]
图10描绘了根据本公开的实施例以逐层的方式迭代地细化注意力对齐的paranet实施例。可以看到,第一层注意力主要由先前的位置编码支配。对于后续层的对齐越来越有信心。
[0102]
a)注意力蒸馏实施例
[0103]
在一个或多个实施例中,来自预训练的自回归模型的注意力对齐被用于引导非自回归模型的训练。在一个或多个实施例中,最小化来自非自回归paranet的注意力分布和经过预训练的自回归模型之间的交叉熵。来自非自回归paranet的注意力权重可以被表示为其中i和j分别索引编码器和解码器的时间步,并且k是指解码器内的第k个注意力块。应注意,注意力权重形成有效分布。注意力损失可以计算为学生和教师注意力分布之间的平均交叉熵::
[0104][0105]
其中是来自自回归教师的注意力权重,m和n分别是编码器和解码器的长度。在一个或多个实施例中,最终损失函数是来自声谱图预测的损失和l
atten
的线性组合。在一个或多个实施例中,l
atten
系数为4,且其它系数为1。
[0106]
b)位置编码实施例
[0107]
在一个或一个以上实施例中,可在每一注意力块处使用位置编码,例如在深度语音3实施例中。位置编码可以被添加到注意力块中的键和查询向量两者,这形成了单调注意力的归纳偏置。应注意,非自回归模型依赖于其注意力机制来从编码的文本特征解码mel声谱图,而没有任何自回归输入。这使得位置编码在训练开始时引导注意力随着时间的单调进展而言更加重要。位置编码h
p
(i)=sin(ω
s
i/10000
k/d
)(对于偶数i)或cosω
s
i/10000
k/d
)(对于奇数i),其中i是时间步索引,k是信道索引,d是位置编码中信道的总数,并且ω
s
是指示注意力分布中线的平均斜率并且大致对应于语音速度的位置速率。在一个或多个实施例中,ω
s
可以以以下方式设置:
[0108]-对于自回归模型,ω
s
针对查询的位置编码设置为1。对于键,它被设置为声谱图的时间步与文本特征的时间步的平均比率,该比率在这里使用的训练数据集中大约是6.3。考虑到使用衰减因子4来简化注意力机制的学习,在训练和合成两者上,对于键,ω
s
简单地设置为6.3/4。
[0109]-对于非自回归paranet模型实施例,ω
s
针对查询也可以设置为1,而对键,ω
s
以不同方式进行计算。在训练时,针对每个单独训练实例,ω
s
设定为声谱图和文本的长度的比率,其也除以衰减因子4。在合成时,应该指定输出声谱图的长度和相应的ω
s
,其控制所产生的音频的语音速率。为了比较,ω
s
设定为如自回归模型中的6.3/4,并且将输出谱图的长
度设定为输入文本的长度的6.3/4倍。这种设置以对角线的形式产生初始注意力,并引导非自回归解码器逐层细化其注意力(参见图10)。
[0110]
c)注意力掩蔽实施例
[0111]
合成时的非自回归paranet实施例可以使用与自回归dv3实施例中所使用的注意力掩蔽不同的注意力掩蔽。在一个或多个实施例中,对于来自解码器的每个查询,在一个或多个实施例中,在以目标位置为中心的固定窗口上计算柔性最大值,并向前和向后进行若干时间步(例如,3个时间步),而不是在整个编码器键向量集上计算柔性最大值。目标位置可以被计算为其中,i
query
是查询向量的时间步索引,并且是舍入运算符。观察到这种策略减少了严重的注意力误差,例如重复或跳过单词,并且还由于其更集中的注意力分布而产生更清晰的发音。这种注意力掩蔽可以在所有注意力块之间共享,一旦它被生成,它就不会阻止非自回归模型的并行合成。
[0112]
d.wavevae实施例
[0113]
在一个或多个实施例中,并行神经tts系统将预测的mel声谱图从非自回归paranet模型实施例馈送到类似于上面引用的clarinet实施例的基于iaf的并行声码器。在本章节中,提出了用于训练iaf作为原始波形x的生成模型的可选实施例。在一个或多个实施例中,该方法使用自动编码变分贝叶斯/变分自编码器(vae)框架,因此为了方便,可以将其称为wavevae。与概率密度蒸馏方法相反,可以通过联合优化编码器q
φ
(z|x,c)和解码器p
θ
(x|z,c)来从头开始训练wavevae实施例,其中z是潜在变量,并且c是mel声谱图调节器。为了以后的简明记号,省略了c。图11描绘了根据本公开实施例的变分自编码器(vae)框架的简化框图。
[0114]
1.编码器实施例
[0115]
在一个或多个实施例中,wavevae的编码器q
φ
(z|x)由高斯自回归wavenet实施例参数化,该实施例将参考真值音频x映射到相同长度的潜在表示z。具体地,高斯wavenet实施例在先前采样x
<t
给定为的情况下对x
t
进行建模,,其中平均值(x
<t
;φ)和标度σ(x
<t
;φ)分别由wavenet预测。编码器后部可以构造为:
[0116][0117]
应注意,平均值(x
<t
;φ)和标度σ(x
<t
;φ)用于“白化”后验分布。在一个或多个实施例中,可训练标量ε>0以捕获全局变化,这将易于优化过程。在给定观察到的x的情况下,q
φ
(z|x)准许对潜在表示z的平行采样。可以在wavevae的编码器和clarinet实施例的教师模型之间建立连接,因为它们都使用高斯wavenet来引导用于并行波产生的逆自回归流(iaf)的训练。
[0118]
2.解码器实施例
[0119]
在一个或多个实施例中,解码器p
θ
(x|z)是iaf。假设z
(0)
=z并从z
(0)
→…
z
(i)
→…
z
(n)
应用iaf转换的堆栈,并且每个转换z
(i)
=f(z
(i-1)
;θ)被定义为:
[0120]
z
(i)
=z
(i-1)
.σ
(i)
+μ
(i)
ꢀꢀꢀ
(3)
[0121]
其中和是由高斯wavenet建模的移位和缩放变量。结果,从高斯先验或编码器给定每步也遵循如下标度和平均值的高斯,
[0122][0123]
最后,x可以被设置为x=∈
·
σ
tot
+μ
tot
,其中因此,对于生成过程,在一个或多个实施例中,使用标准高斯先验
[0124]
3.vae客观实施例
[0125]
在一个或多个实施方案中,目标是最大化在vae中观察到的x的证据下限(elbo):
[0126][0127]
其中kl发散度可以以闭合形式计算,因为q
φ
(z|x)和p(z)两者均为高斯:
[0128][0129]
等式(5)中的重构项是难以精确计算的。在一个或多个实施例中,随机优化可以通过重新参数化从编码器中提取样本并评估似然对数p
θ
(x|z)来执行。为了避免“后部塌陷”,其中后部分布q
φ
(z|x)在训练的早期阶段迅速塌陷成白噪声先验p(z),在一个或多个实施例中,应用用于kl发散的退火策略,其中其重量经由s形(sigmoid)函数从0逐渐增加到1。通过它,编码器可以在早期训练时将足够的信息编码到潜在表示中,然后通过增加kl发散度的权重来逐渐规则化潜在表示。
[0130]
4.短期傅立叶变换(stft)实施例
[0131]
与clarinet实施例类似,可以添加基于短时傅立叶变换(stft)的损耗以改善合成语音的质量。在一个或多个实施例中,stft损耗可以被定义为在输出音频和参考真值音频之间的stft的幅度上的损耗与stft的对数幅度上的损耗之和。在一个或多个实施例中,对于stft,12.5毫秒(ms)的帧移位,50ms的汉宁窗长度,且fft大小设置为2048。客观上考虑两种stft损耗:(1)利用编码器q
φ
(z|x)实现参考真值音频与重构音频之间的stft损耗;以及(ii)使用先验p(z)的参考真值音频和合成音频之间的stft损耗,目的是减小重建和合成之间的间隙。在一个或多个实施例中,最终损失是等式(5)中的项与stft损失的线性组合。在本文的实验中,相应的系数被简单地设置为1。
[0132]
e.示例性实现方法
[0133]
图12描述了根据本公开实施例的使用paranet实施例来从输入文本合成语音表示的一般方法。如图12所示,用于从输入合成语音的计算机实现的方法包括使用编码器将输入文本编码(1205)为隐藏表示,该隐藏表示包括一组键表示和一组值表示,该编码器包括一个或多个卷积层。在一个或多个实施例中,非自回归解码器使用(1210)隐藏表示来获得
合成表示,其可以是线性声谱图输出、mel声谱图输出或波形。在一个或多个实施例中,非自回归解码器包括注意力块,该注意力块使用位置编码和该组键表示来为每个时间步生成上下文表示,该上下文表示作为输入被提供给多个解码器块中的第一解码器块。在一个或多个实施例中,注意力块使用位置编码来影响注意力对齐加权。
[0134]
在一个或多个实施例中,解码器块包括:非因果卷积块,如果它是多个解码器块中的第一解码器块,则接收上下文表示作为输入,并且如果它是多个解码器块中的第二或后续解码器块,则接收从先前解码器块输出的解码器块作为输入,并且输出包括查询和中间输出的解码器块输出;以及注意力块,其使用从非因果卷积块输出的查询以及位置编码来计算与中间输出组合以创建用于解码器块的解码器块输出的上下文表示。
[0135]
在一个或多个实施例中,使用(1215)该组解码器块输出来生成表示输入文本的音频表示帧的集合。该组音频表示帧可以是线性声谱图、mel声谱图或波形。在输出是波形的实施例中,获得波形可以包括使用声码器。在一个或多个实施例中,tts系统可以包括声码器,诸如基于iaf的并行声码器,其将音频表示帧的集合转换为表示输入文本的合成语音的信号。如上所述,基于iaf的并行声码器可以是在无蒸馏的情况下训练的wavevae实施例。例如,在一个或多个实施例中,可以通过使用声码器的编码器引导声码器解码器的训练,而无蒸馏地训练声码器解码器。这种方法的好处是编码器可以与声码器解码器联合训练。
[0136]
f.实验
[0137]
应注意的是,这些实验和结果是通过举例说明的方式提供的,并且使用一个或多个具体实施方案在具体条件下进行;因此,这些实验和它们的结果都不应用于限制本专利文件的公开范围。
[0138]
在该部分中,给出了评估实施例的几个实验。在实验中,使用包含来自女性说话者的语音数据的约20小时的内部英语语音数据集,采样速率为48khz。将音频下采样到24khz。
[0139]
1.基于iaf的波形合成
[0140]
首先,对基于iaf的波形合成,采用两种训练方法实施例,clarinet实施例和wavevae实施例。使用与上面引用的clarinet专利申请中描述的相同的iaf架构。它包括4个堆叠的高斯iaf块,分别由[10,10,10,30]层wavenet参数化,在加宽的卷积中使用64个剩余&跳跃信道和滤波器大小3。iaf以具有两层转置2-d卷积的对数-mel声谱图为条件,如在clarinet实施例中那样。对于clarinet和20层高斯自回归wavenet,训练了同样的教师-学生设置作为教师模型。对于wavevae中的编码器,使用以对数-mel声谱图为条件的20层高斯wavenet。应注意,在测试的实施例中,wavevae的编码器和解码器都共享相同的调节器网络。两种方法都使用具有1000k步长的adam优化器。学习速率在开始时被设定为0.001,并且每200k步退火一半。
[0141]
将crowdmos工具包(由f.ribeiro、d.florjncio、c.zhang和m.seltzer在“crowdmos:an approach for crowdsourcing meanopinion score studies(众包均数评分研究的一种方法)”,icassp,2011中开发)用于主观平均意见得分(mos)评估,其中将来自这些模型的多批样品提供给mechanical turk的工作者。mos结果示于表2中。尽管wavevae(先验)模型在合成时表现得比clarinet差,但是它被从头开始训练并且不需要任何预训练。在一个或多个实施例中,可以通过引入学习的先前网络来实现对wavevae的进一步改进,这将最小化具有编码器的重构语音和具有先验的合成语音之间的质量差距。
[0142]
表2:用于波形合成的具有95%置信区间的平均意见得分(mos)等级。我们将相同的高斯iaf结构用于clarinet和wavevae。应注意,wavevae(重构)是指通过使用来自编码器的潜在表示(latents)而重构的语音。
[0143][0144]
2.文本到语音
[0145]
评估了具有基于iaf的声码器的文本到声谱图paranet模型和并行神经tts系统的实施例,所述声码器包括clarinet和wavevae。使用在dv3专利申请中引入的字符和音素的混合表示。自回归和非自回归paranet实施例的所有超参数示于下表3中。发现较大的内核宽度和较深的层通常有助于提高语音质量。测试的非自回归模型在参数数方面比自回归模型大~2.57倍,但在合成方面获得了显著的提速。
[0146]
表3:在实验中测试的自回归序列到序列模型和非自回归序列到序列模型实施方案的超参数。
[0147]
[0148][0149]
a)合成加速
[0150]
在推断等待时间方面,将非自回归paranet实施例与自回归dv3实施例进行比较。构建自定义句子测试集,并对测试集(批大小被设置为1)中的每个句子运行50次推理。对于非自回归和自回归模型实施例,在加利福尼亚州santa clara的nvidia生产的nvidia geforce gtx 1080ti上的50次运行和语句测试集的平均推断等待时间分别为0.024和1.12秒。因此,与合成时的自回归对应实施例相比,paranet实施例产生了大约46.7倍的加速。
[0151]
b)注意力误差分析
[0152]
在自回归模型中,教师强制训练和自回归推理之间存在显著的差异,这种差异在综合过程中会产生累积误差。在神经tts系统中,这种差异导致在自回归推理中的不可预见的注意力误差,包括(i)重复的单词、(ii)错误发音、以及(iii)跳过的单词,这对于基于注意力的神经tts系统的在线部署可能是一个关键问题。在100句测试集上对非自回归paranet模型实施例执行注意力误差分析,所述100句测试集包括来自部署的tts系统的特别有挑战性的情况(例如,日期、首字母缩略词、url、重复单词、适当名词、外语单词等)。
[0153]
如表4所示,发现非自回归paranet实施例在合成时具有比其自回归对应实施例少得多的注意力误差(12和37)。尽管paranet实施例从自回归模型中引出了(教师强制的)注意力,但是它只在训练和合成时采用文本输入,并且不具有与自回归模型中类似的差异。以前,应用注意力掩蔽来实施单调注意力并减少注意力误差,并且在深度语音3实施例中被证明是有效的。发现测试的非自回归paranet实施例仍然具有比测试的自回归dv3实施例更少的注意力误差(表4中的6和8),当它们都使用注意力掩蔽技术时。
[0154]
表4:在100句测试集上的文本-声谱图模型的注意力误差计数。一个或多个错误发音、跳过和重复计为每个发音的单个错误。为方便起见,所有模型都使用griffin-lim作为声码器。具有注意力掩码的非自回归paranet实施例在合成时获得了最少的总注意力误差。
[0155][0156]
c)mos评价
[0157]
表5中报告了tts系统实施例的mos评估结果。通过用不同的神经声码器配对自回归和非自回归文本-声谱图模型进行实验。对来自dv3和非自回归模型实施例的预测mel声谱图分别训练wavenet声码器以获得更好的质量。clarinet声码器实施例和wavevae实施例都是在参考真值的mel声谱图上训练的,以用于稳定的优化。在合成时,所有这些以来自文本-声谱图模型实施方案的预测的mel声谱图为条件。应注意,非自回归paranet实施例可以提供与wavenet声码器实施例的自回归dv3相当的语音质量。当应用并行神经声码器时,语音的质量退化,部分原因是用于训练的参考真值mel声谱图与用于合成的预测mel声谱图之间的失配。通过在预测的mel声谱图上成功地训练基于iaf的神经声码器,可以实现进一步的改进。
[0158]
表5:用于比较的具有95%置信区间的平均意见得分(mos)等级。使用如表2中的crowdmos工具包。
[0159][0160]
g.部分结论
[0161]
本文提供了包括非自回归文本到声谱图模型并应用基于iaf的并行声码器的完全并行神经文本到语音系统的实施例。新型非自回归系统的实施例(为方便起见通常称为paranet)具有较少的注意力误差。测试实施例在合成时相比其自回归对应实施例获得了46.7倍的加速,而没有语音质量的微小退化。此外,开发了可选声码器(通常可称为wavevae)的实施例来训练用于并行波形合成的逆自回归流(iaf)。wavevae实施例避免了从单独训练的自回归wavenet蒸馏的需要,并且可以从头开始训练。
[0162]
h.计算系统实施例
[0163]
在一个或多个实施例中,本专利文件的各方面可以涉及、可以包括一个或多个信
息处理系统/计算系统或者可以在一个或多个信息处理系统/计算系统上实现。计算系统可以包括可操作来运算、计算、确定、分类、处理、发送、接收、检索、发起、路由、切换、存储、显示、通信、展示、检测、记录、再现、处置或利用任何形式的信息、情报或数据的任何手段或手段的集合。例如,计算系统可以是或可以包括个人计算机(例如笔记本计算机)、平板计算机、平板手机、个人数字助理(pda)、智能电话、智能手表、智能包、服务器(例如刀片服务器或机架式服务器)、网络存储设备、照相机或任何其他合适的设备,并且可以在尺寸、形状、性能、功能和价格上变化。计算系统可以包括随机存取存储器(ram)、一个或多个处理资源,诸如中央处理单元(cpu),或者硬件或软件控制逻辑、rom和/或其他类型的存储器。计算系统的附加部件可以包括一个或多个磁盘驱动器、一个或多个用于与外部设备通信的网络端口,以及各种输入和输出(i/o)设备,诸如键盘、鼠标、触摸屏和/或视频显示器。计算系统还可以包括一条或多条总线,所述总线可操作以在各种硬件部件之间传输通信。
[0164]
图13描绘了根据本公开实施例的计算设备/信息处理系统(或计算系统)的简化框图。应当理解,系统1300所示的功能可以操作为支持计算系统的各种实施例,但应当理解,计算系统可以被不同地配置并包括不同的部件,包括具有更少或更多的如图13所示的部件。
[0165]
如图13所示,计算系统1300包括提供计算资源并控制计算机的一个或多个中央处理单元(cpu)1301。cpu 1301可以用微处理器等实现,并且还可以包括一个或多个图形处理单元(gpu)1319和/或用于数学计算的浮点协处理器。系统1300还可以包括系统存储器1302,其可以是随机存取存储器(ram)、只读存储器(rom)或两者的形式。
[0166]
还可以提供多个控制器和外围设备,如图13所示。输入控制器1303表示各种输入设备1304的接口,诸如键盘、鼠标、触摸屏和/或触笔。计算系统1300还可以包括用于与一个或多个存储设备1308接口连接的存储控制器1307,每个存储设备包括诸如磁带或磁盘的存储介质,或者可以用于记录操作系统、实用工具和应用程序的指令程序的光学介质,所述指令程序可以包括实现本公开的各个方面的程序的实施例。存储设备1308也可以用于存储已处理的数据或根据本公开要处理的数据。系统1300还可以包括显示器控制器1309,用于提供显示设备1311的接口,该显示设备可以是阴极射线管(crt)、薄膜晶体管(tft)显示器、有机发光二极管、电致发光面板、等离子面板或其他类型的显示器。计算系统1300还可以包括一个或多个外围设备1306的一个或多个外围控制器或接口1305。外围设备的示例可以包括一个或多个打印机、扫描仪、输入设备、输出设备、传感器等。通信控制器1314可以与一个或多个通信设备1315接口连接,这使得系统1300能够通过包括互联网、云资源(例如以太网云、以太网光纤通道(fcoe)/数据中心桥接(dcb)云等)、局域网(lan)、广域网(wan)、存储区域网(san)在内的各种网络中的任何一种或通过任何合适的电磁载波信号(包括红外信号)连接到远程设备。
[0167]
在所示的系统中,所有的主要系统部件都可以连接到总线1316,该总线可以表示布置一条物理总线。然而,各种系统部件可以或可以不彼此物理接近。例如,输入数据和/或输出数据可以从一个物理位置远程传输到另一个物理位置。此外,可以通过网络从远程位置(例如,服务器)访问实现本公开各方面的程序。这种数据和/或程序可以通过各种机器可读介质中的任何一种来传送,包括但不限于:诸如硬盘、软盘和磁带的磁性介质;诸如cd-rom和全息设备的光学介质;磁光介质;以及专门被配置为存储或存储并执行程序代码的硬
件设备,诸如专用集成电路(asic)、可编程逻辑设备(pld)、闪存设备以及rom和ram设备。
[0168]
本公开的各方面可以用指令编码在一个或多个非暂时性计算机可读介质上,该指令用于一个或多个处理器或处理单元以使得步骤得以执行。应当注意,一个或多个非暂时性计算机可读介质可包括易失性和/或非易失性存储器。应当注意,替代实现方式是可能的,包括硬件实现方式或软件/硬件实现方式。硬件实现的功能可以使用asic、可编程阵列、数字信号处理电路等来实现。因此,任何权利要求中的术语“装置”旨在涵盖软件和硬件实现方式。类似地,这里使用的术语“计算机可读介质”包括其上具有指令程序的软件和/或硬件,或者它们的组合。考虑到这些实现方式,应当理解,附图和所附描述提供了本领域技术人员编写程序代码(即,软件)和/或制造电路(即,硬件)以执行所需处理所需的功能信息。
[0169]
应当注意,本公开的实施例还可以涉及具有非暂时性有形计算机可读介质的计算机产品,该计算机可读介质上具有用于执行各种计算机实现的操作的计算机代码。介质和计算机代码可以是为本公开的目的专门设计和构造的那些,或者它们可以是相关领域技术人员已知或可获得的类型。有形计算机可读介质的示例包括但不限于:诸如硬盘、软盘和磁带的磁性介质;诸如cd-rom和全息设备的光学介质;磁光介质;以及专门被配置为存储或存储并执行程序代码的硬件设备,诸如专用集成电路(asic)、可编程逻辑设备(pld)、闪存设备以及rom和ram设备。计算机代码的示例包括机器代码,诸如由编译器产生的代码,以及包含由计算机使用解释器执行的高级代码的文件。本公开的实施例可以全部或部分实现为机器可执行指令,其可以在由处理设备执行的程序模块中。程序模块的示例包括库、程序、例程、对象、部件和数据结构。在分布式计算环境中,程序模块可以物理地位于本地、远程或两者兼有的环境中。
[0170]
本领域技术人员将认识到,没有任何计算系统或编程语言对本公开的实践是至关重要的。本领域技术人员还将认识到,上述许多元件可以在物理上和/或功能上分成子模块或组合在一起。
[0171]
本领域技术人员将理解,前面的示例和实施例是示例性的,并不限制本公开的范围。本领域技术人员在阅读说明书和研究附图后显而易见的所有置换、增强、等同物、组合和改进都包含在本公开的真实精神和范围内。还应当注意,任何权利要求的元素可以用不同的方式布置,包括具有多个从属性、配置和组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1