一种基于双麦克风阵列的声源定位方法与流程
本发明属于声源定位技术领域,具体涉及一种基于双麦克风阵列的声源定位方法。
背景技术:
近年来,随着人工智能领域智能语音技术的不断发展,基于麦克风阵列的声源定位技术也持续受到业内高度关注。麦克风阵列声源定位技术是指利用一定拓扑结构的多个麦克风及其相关算法,对麦克风阵列采集的多路语音信号进行分析和处理,获取一个或多个目标声源方位的过程。声源定位技术广泛应用于军事、民用等领域,如军事领域中的被动声探测系统、枪声定位系统,民用领域的智能机器人、智能家居、视频会议系统等。因此,准确实时获取目标声源方位十分重要。
目前,常用的声源定位技术可分为三大类:基于到达时间差的声源定位技术、基于高分辨率谱估计的声源定位技术以及基于最大输出功率的可控波束形成的声源定位技术。基于到达时间差的声源定位技术计算量小,实时性好,应用也比较广泛。但是该算法需分两步进行,且对第一步中的时延估计高度依赖。同时,该算法在低信噪比和混响环境中性能急剧降低。基于高分辨率谱估计的声源定位技术一般用于处理窄带信号,在处理宽带自然语音信号时应用受限。基于最大输出功率的可控波束形成的声源定位技术,由于算法本身特性,使其具有一定的抗噪抗混响能力。虽然需要添加可控功率的搜索算法增加了计算量,但对于双麦克风阵列,其计算量依然较小,可实时实现。
双麦克风阵列以小巧灵活的构型以及电路、算力、成本要求都比较低而广泛应用于智能家居、智能家电、智能玩具等领域。但同时由于其麦克风数量较少,空间信息获取不足等原因导致双麦克风阵列对目标声源的定位不准确以及定位精度较低。若增加繁琐的处理算法,虽然提升了定位精度,但同时也会增加计算量,影响定位实时性,无法满足市场需求。
技术实现要素:
为克服现有技术存在的缺陷,本发明公开了一种基于双麦克风阵列的声源定位方法。
本发明所述基于双麦克风阵列的声源定位方法,包括如下步骤;
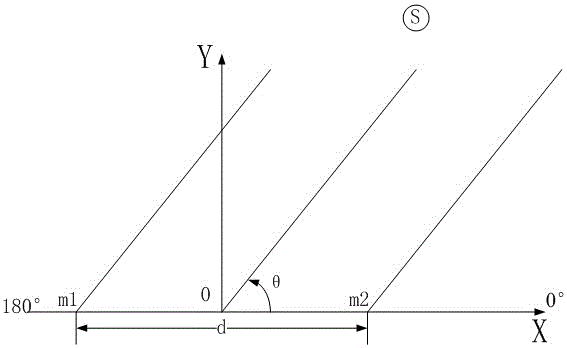
步骤1.以双麦克风阵列的两个麦克风所在直线为x轴,两个麦克风的中间点为原点,原点处垂直于x轴为y轴,建立xoy二维坐标系;
设置两个麦克风接收到的时域信号分别为x1,x2,每帧信号采样点长度为k,采样率为fs;
步骤2.对时域信号x1,x2进行分帧加窗及快速傅里叶变换,分别得到两个麦克风的频域信号
步骤3.将空间方位角区间[0°180°]均分为q等份,定义每一个方位角索引q=1,2,...,q;根据基于相位变换加权的可控功率响应算法,获得第q个方位角的波束为:
其中:
步骤4.遍历全部q个方位角,得到空间波束向量:
步骤5.对空间波束向量
最后对有效波束进行峰值搜索,峰值最大值所在的位置即为目标声源位置。
优选的:还包括对步骤5中筛选后的空间波束向量的卡尔曼滤波更新,更新后的有效波束进行峰值搜索。
优选的:所述卡尔曼滤波更新具体为:
步骤6.设置卡尔曼滤波初始状态参数,利用卡尔曼滤波预测方程和更新方程估计当前帧语音信号的波束;初始状态参数包括预测矩阵
其中,当帧数l大于1时,卡尔曼滤波预测方程为:
卡尔曼滤波更新方程为:
其中:
将筛选出的有效波束以上述卡尔曼滤波预测方程和卡尔曼滤波更新方程持续迭代,遍历所有帧;
步骤7.步骤5中未通过筛选的空间波束向量,代入卡尔曼滤波预测方程并以卡尔曼滤波预测波束
优选的:所述步骤5的筛选方法为:设置波束均值的阈值和方差阈值,筛选出大于方差阈值且小于均值阈值的波束作为有效波束进行下一步操作。
优选的:所述步骤2中的加窗为利用汉宁窗函数加窗。
采用本发明所述的基于双麦克风阵列的声源定位方法,具备如下优越性:
一.对每帧语音信号经过声源定位算法处理后形成的波束进行归一化处理并做统计分析,筛选出包含目标声源的有效波束,不仅可以检测到语音信号起始点,而且能够剔除由于静音段、连续语音间歇停顿段以及噪声干扰过大导致的无效波束。
二.对筛选出的有效波束进行卡尔曼滤波和预测,可以防止波束峰值位置突变,抑制瞬时噪声干扰,并减小目标声源方位角度波动范围,提高目标声源定位准确度和精确度。
附图说明
图1为基于双麦克风阵列建立坐标系的一种具体实施方式示意图,m1和m2表示不同的麦克风,s为声源;
图2为本发明所述定位方法的一种具体实施方式流程示意图。
具体实施方式
下面结合附图,对本发明的具体实施方式作进一步的详细说明。
本发明所述基于双麦克风阵列的声源定位方法,包括如下步骤:
步骤1.以双麦克风阵列的两个麦克风所在直线为x轴,两个麦克风的中间点为原点,原点处垂直于x轴为y轴,建立xoy二维坐标系,如图1所示;
设置两个麦克风接收到的时域信号分别为x1,x2,每帧信号采样点长度为k,采样率为fs;
步骤2.对时域信号x1,x2进行分帧加窗及快速傅里叶变换,分别得到两个麦克风的频域信号:
一个典型设置为,可设置帧长为512个采样点,选择帧移为k/2,加窗可选取汉宁窗或汉明窗,采样率为16khz。。
从时域信号x1,x2到频域信号
步骤3.将空间方位角区间[0°180°]均分为q等份,定义每一个方位角索引q=1,2,...,q;根据基于相位变换加权的可控功率响应算法,获得第q个方位角的波束为:
其中:
步骤4.遍历全部q个方位角,得到空间波束向量:
步骤5.对空间波束向量
对每帧语音信号经过声源定位算法处理后形成的波束进行归一化处理并做统计分析,筛选出包含目标声源的有效波束,不仅可以检测到语音信号起始点,而且能够剔除由于静音段、连续语音间歇停顿段以及噪声干扰过大导致的无效波束。
对于有效波束的筛选,可以根据统计规律进行,经统计方法分析,可发现在语音静音段、目标语音段及噪声干扰段,波束的均值和方差呈现出一定的规律性。因此,可以通过设置波束均值的阈值和方差阈值,筛选出有效波束进行下一步操作。
例如,可以设置波束均值阈值m=0.5,方差阈值α=0.1,筛选出大于方差阈值且小于均值阈值的波束作为有效波束进行下一步操作。
筛选后的波束可以进行卡尔曼滤波和预测,可以防止波束峰值位置突变,抑制瞬时噪声干扰,并减小目标声源方位角度波动范围,提高目标声源定位准确度和精确度。
具体的,卡尔曼预测和更新筛选后的有效波束进行后续操作如下:
步骤6.设置卡尔曼滤波初始状态参数,利用卡尔曼滤波预测方程和更新方程估计当前帧语音信号的波束;初始状态参数包括预测矩阵
其中,当帧数l大于1时,卡尔曼滤波预测方程为:
其中:
卡尔曼滤波更新方程为:
其中:
步骤7.如果在步骤5中某一帧信号没有筛选出有效波束,说明该帧语音没有有效波束,则直接以卡尔曼滤波预测波束
符合步骤5筛选标准的,对经过卡尔曼滤波更新后的波束
采用本发明所述的基于双麦克风阵列的声源定位方法,具备如下优越性:
一.对每帧语音信号经过声源定位算法处理后形成的波束进行归一化处理并做统计分析,筛选出包含目标声源的有效波束,不仅可以检测到语音信号起始点,而且能够剔除由于静音段、连续语音间歇停顿段以及噪声干扰过大导致的无效波束。
二.对筛选出的有效波束进行卡尔曼滤波和预测,可以防止波束峰值位置突变,抑制瞬时噪声干扰,并减小目标声源方位角度波动范围,提高目标声源定位准确度和精确度。
前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!