驾驶环境下基于智能手机音频感知的呼吸道症状检测方法与流程
[0001]
本发明涉及一种呼吸道症状检测方法,特别涉及一种驾驶环境下基于智能手机音频传感器,即扬声器和麦克风的音频感知能力的呼吸道症状检测方法,主要用于监测驾驶员和乘客是否存在咳嗽、打喷嚏和吸鼻子三种典型的呼吸道症状,属于移动计算应用技术领域。
背景技术:
[0002]
在与人类健康息息相关的呼吸道症状中,咳嗽、打喷嚏和吸鼻子是日常生活中最常见的几种呼吸道症状。尽管这些呼吸道症状看起来微不足道,它们确和超过100种疾病相关,比如感冒、流感、过敏等普通疾病,又比如肺炎、哮喘、慢性肺部疾病等较为严重的呼吸道疾病。这些呼吸道疾病大部分是可以治愈的,但仍需尽早发现,尤其是具有传染性的呼吸道疾病。因此,检测呼吸道症状不仅可以帮助个人发现健康问题,也可以帮助预防传染性疾病,促进公共卫生发展。
[0003]
目前,检测呼吸道症状的方法主要依靠部署在医院和医疗机构、与医疗系统相连的专用医疗设备。例如,利用呼吸监控装置检测病人嘴部的进出气量来判断病人是否咳嗽;通过在病人胸口安装一个带加速度计的设备来检测病人是否有异常呼吸状况。
[0004]
然而,这些方法通常存在成本较高、难于部署、只适用于医院和医疗机构等地的问题。在移动计算应用领域,存在一些利用音频传感器检测呼吸道症状的方法。例如,通过让用户佩戴一个麦克风装置来收集用户周围声音,从而判断用户是否咳嗽;利用用户手机上的麦克风收集用户周围的声音,来判断用户是否有咳嗽、打喷嚏和吸鼻子等行为。但是,这些方法存在抗干扰性不强、只适用于较为安静的室内环境等问题。在驾驶环境中,尤其是在出租车等商业车辆中,由于其空间较小、乘客与驾驶员距离较近,十分容易造成传染性呼吸道疾病的传播。由于驾驶环境中的噪声较大、不易于部署专用设备,现有的方法并不适用于在驾驶环境中检测咳嗽、打喷嚏和吸鼻子等呼吸道症状。
[0005]
综上所述,目前迫切需要一种利用驾驶员智能手机中的音频传感器来检测处于驾驶环境中的驾驶员和乘客是否有呼吸道症状的方法。
技术实现要素:
[0006]
本发明的目的是为了解决目前在驾驶环境中检测驾驶员和乘客的呼吸道症状成本过高、抗干扰性不强的问题,提出一种利用智能手机音频传感器检测驾驶员或乘客咳嗽、打喷嚏和吸鼻子等呼吸道症状的方法。
[0007]
本发明的核心思想是:利用智能手机的扬声器收集车内声音,通过基于自适应子带谱熵方法滤去汽车行驶噪声,然后提取去噪后声音的声学特征并将特征送入训练好的神经网络,来判断收集到的声音中是否存在咳嗽、打喷嚏和吸鼻子等呼吸道症状,并记录相关呼吸道症状的次数。本发明方法尤其适用于驾驶噪声较为平稳、小型汽车中驾驶员和乘客距离较近的驾驶环境。
[0008]
本发明的目的是通过以下技术方案实现的:
[0009]
驾驶环境下基于智能手机扬音频感知的呼吸道症状检测方法,包括以下步骤:
[0010]
步骤1:利用智能手机麦克风,收集驾驶环境中不同的驾驶员和乘客咳嗽、打喷嚏和吸鼻子的声音信号,基于自适应子带谱熵去噪方法,即abse去噪方法,滤去收集到声音信号中的汽车行驶噪声。
[0011]
具体地,步骤1的实现方法如下:
[0012]
步骤1.1:将智能手机置于车内,收集不同的驾驶员和乘客咳嗽、打喷嚏和吸鼻子三种行为的声音信号。
[0013]
步骤1.2:将步骤1.1收集到的每个声音信号分成相同长度的子段,选取开始部分的n个子段声音信号(如2至10段)进行快速傅里叶变换(fft),然后计算子段声音的平均能量谱,并初始化abse的阈值。
[0014]
abse的阈值t
s
=μ
θ
+α
·
σ
θ
;其中,;其中,h
b
(l)是第l个子段的abse值;α表示权值,根据实验结果选定。
[0015]
步骤1.3:计算下一子段声音信号的abse值,并和步骤1.2得到的阈值进行对比。若该子段声音的abse值超过阈值,则对该子段声音进行fft并计算能量谱,然后用该子段声音的能量谱减去步骤1.2得到的平均能量谱,并进行逆快速傅里叶变换(ifft),得到该子段声音去噪后的声音信号。若该子段声音的abse值未超过阈值,则根据该子段声音的能量谱更新平均能量谱。
[0016]
步骤1.4:重复步骤1.3,直到所有声音信号去噪完毕。将去噪后的声音信号通过高通滤波器滤去低频段的信号,然后取出滤波后的声音信号中包含咳嗽、打喷嚏和吸鼻子声音段,将这些声音段切分成不同信号帧,每一信号帧包含一次呼吸道症状,并用相应的行为对这些信号帧进行标记。
[0017]
步骤2:对于步骤1中得到的去噪且标记的信号帧,提取每一帧的基于梅尔倒频谱系(mfcc)和伽马倒频谱系数(gfcc)的混合式声学特征,利用该特征训练一个基于长短时记忆(lstm)神经网络的分类器。
[0018]
具体地,步骤2的实现方法如下:
[0019]
步骤2.1:对于步骤1得到的每个包含一次呼吸道症状的信号帧,分成长度相同的子帧,计算每个子帧的12维mfcc特征,并取每个子帧的前10维mfcc特征拼接成为该帧的mfcc特征向量。
[0020]
步骤2.2:对于步骤1得到的每个包含一次呼吸道症状的信号帧,分成长度相同的子帧,计算每个子帧的31维的gfcc特征,并取每个子帧的前20维gfcc特征拼接成为该帧的gfcc特征向量。
[0021]
步骤2.3:将步骤2.1得到的mfcc向量和步骤2.2得到的gfcc向量,拼接成一个混合式特征向量,然后将该混合式特征向量送入一个3层的lstm网络进行训练,得到驾驶环境下三种呼吸道症状声音的分类器。
[0022]
步骤3:在实际应用中,利用车内智能手机的麦克风持续收集车内的声音信号。利用步骤1.2的方法,从收集到的声音信号中去除汽车行驶噪声,并将去噪后的声音信号进行
切分和补齐,使得每一段声音信号成为等长的信号帧。然后利用步骤2.2的方法,提取每一信号帧的声学特征,并将特征送入训练好的分类器进行判断。一旦分类器判断出有咳嗽、打喷嚏或者吸鼻子行为,则记录相应呼吸道症状并记录累计发生次数。
[0023]
具体地,步骤3的实现方法如下:
[0024]
步骤3.1:将用户手机的扬声器采样率设置为48khz,该手机麦克风持续接受车内的声音信号。
[0025]
步骤3.2:对于步骤3.1收集到的声音信号,先利用步骤1.2和1.3的方法去除收集到的声音信号中的驾驶噪声,选出abse值超过阈值的声音子段。若连续几个超过阈值的声音子段的总时长超过时间阈值t_1,则将该子段和切分成重叠的固定长度的子帧。若连续几个超过阈值的声音子段的总时长小于另一时间阈值t_2,则舍弃该子段和。若连续几个超过阈值的声音子段的总时长大于t_2小于t_1,则扩展该子段和长度为固定的帧长。将每个帧通过一个高通滤波器进行滤波。
[0026]
步骤3.3:对于步骤3.2得到的每个固定长度的滤波后的帧,利用步骤2.1计算该帧的mfcc特征向量,然后利用步骤2.2计算该帧的gfcc特征向量,将两个向量拼接成该帧的混合式特征向量,然后送入训练好的lstm网络进行分类,判断该帧是否包含咳嗽、打喷嚏或吸鼻子行为。
[0027]
有益效果
[0028]
1.本发明方法,相较现有技术,仅依靠智能手机中的麦克风持续接收驾驶环境中的声音信号,就可以实现对驾驶员和乘客的呼吸道症状的检测。因此本发明不依赖于各类预先架设的专业医疗设备,成本低、抗干扰性强、不存在泄露隐私问题,适用于驾驶噪声较平稳、驾驶员和乘客距离较近的检测环境。
[0029]
2.本发明针对典型呼吸道症状的声音信号与驾驶噪声的特征不同,采用基于自适应子带谱熵的去噪方法来消除各种驾驶噪声的影响,使得系统对于环境噪声的鲁棒性较强。
[0030]
3.本发明针对三种典型呼吸道症状的声音信号特征不同,提取混合式声学特征,结合神经网络和深度学习技术,准确高效地实现对三种典型呼吸道症状的检测和分类。
附图说明
[0031]
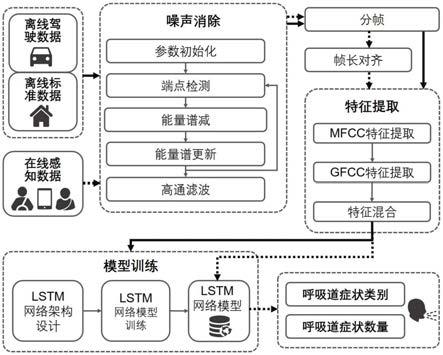
图1为本发明方法的原理图。
[0032]
图2为本发明实施例不同呼吸道症状检测方法的准确率。
[0033]
图3为本发明实施例不同呼吸道症状检测混淆矩阵。
[0034]
图4为本发明实施例不同呼吸道症状在不同场景下的召回率。
具体实施方式
[0035]
下面结合实施例和附图,对本发明方法做进一步详细说明。
[0036]
如图1所示,一种驾驶环境下基于智能手机音频感知的呼吸道症状检测方法,包括以下步骤:
[0037]
步骤1:利用智能手机的麦克风收集驾驶环境中不同的驾驶员和乘客咳嗽、打喷嚏和吸鼻子的声音信号,设计一种基于自适应子带谱熵(abse)的去噪方法滤去收集到声音信
号中的汽车行驶噪声。
[0038]
步骤1.1:招募16位志愿者作为驾驶员或者乘客来驾驶或乘坐测试车辆,志愿者将智能手机置于车内,收集车辆行驶过程中的咳嗽、打喷嚏和吸鼻子三种行为的声音信号。
[0039]
步骤1.2:将步骤1.1收集到的每个声音信号分成长度为0.2秒的不重叠的子段,取开始10个子段的声音信号,进行快速傅里叶变换(fft)后计算这些子段声音的平均能量谱e,并初始化abse的阈值t
s
=μ
θ
+α
·
σ
θ
,其中,其中h
b
(l)是第l个子段的abse值。权值α=0.1。
[0040]
步骤1.3:计算下一子段声音信号的abse值并和步骤1.2得到的阈值进行对比。若该子段声音的abse值超过阈值,则对该子段声音进行fft并计算能量谱,然后用该子段声音的能量谱减去步骤1.2得到的平均能量谱,并对相减后的信号进行逆快速傅里叶变换(ifft),得到该子段声音去噪后的声音信号。若该子段声音的abse值未超过阈值,则根据该子段声音的能量谱更新平均能量谱,即e
new
=0.7e+0.3e
current
,其中e
current
是当前子段的能量谱。
[0041]
步骤2:收集汽油汽车行驶时产生的音频信号,训练一个基于长短时记忆神经网络(lstm)的分类器。
[0042]
步骤2.1:对于步骤1得到的每个包含一次呼吸道症状的帧,分成长度为0.07秒子帧,且两相邻子帧之间有一段长度为0.03秒的重叠区域。计算每个子帧的12维mfcc特征,并取每个子帧的前10维mfcc特征拼接成为该帧的120维mfcc特征向量。
[0043]
步骤2.2:对于步骤1得到的每个包含一次呼吸道症状的帧,分成长度为0.07秒子帧,且两相邻子帧之间有一段长度为0.03秒的重叠区域。计算每个子帧的31维的gfcc特征,并取每个子帧的前20维gfcc特征拼接成为该帧的240维gfcc特征向量。
[0044]
步骤2.3:将步骤2.1得到的mfcc向量和步骤2.2得到的gfcc向量拼接成一个360维的混合式特征向量,然后将该混合式特征向量送入一个3层的lstm网络进行训练,得到驾驶环境下三种呼吸道症状声音的分类器。其中该lstm网络包含2个lstm层和1个全连接层,采用tanh作为激活函数,每个lstm层后面加上batch normalization层,用交叉熵代价函数作为损失函数。该lstm网络的timestep值设为6,即每次的输入为当前子帧的特征向量和当前子帧之前的5个子帧的特征向量。对于第t个timestep,lstm层利用公式h
t
=δ(w0[h
t-1
,x
t
+b0])
·
tanh(s
t
),将输入x
t
映射为一个压缩向量h
t
,其中w0和b0分别表示权重矩阵和偏置向量,s
t
代表第t个timestep的状态,h
t-1
表示前一个timestep对应的压缩向量,δ()表示激活函数。经过训练,得到三种典型呼吸道症状的分类器。
[0045]
步骤3:在实际应用中,车内智能手机的麦克风持续收集车内的声音信号。利用步骤1.2的方法从收集到的声音信号中去除汽车行驶噪声,并将去噪后的声音信号进行切分和补齐,使得每一段声音信号成为等长的帧。然后利用步骤2.2的方法,提取每一帧的声学特征,并将特征送入训练好的分类器进行判断。一旦分类器判断出有咳嗽、打喷嚏或者吸鼻子行为,则记录相应呼吸道症状并记录累计发生次数。
[0046]
步骤3.1:在实际应用时,将用户智能手机的扬声器采样率设置为44.1khz,该智能手机麦克风持续地接受车内的声音信号。
[0047]
步骤3.2:对于步骤3.1收集到的声音信号,先利用步骤1.2和1.3的方法去除收集到的声音信号中的驾驶噪声,选出abse值超过阈值的声音子段。我们记连续几个超过阈值的声音子段的总时长为d,若d>0.4秒,则将该子段和切分成长度为0.4秒、重叠区域长度为0.2秒的子帧;若d<0.2秒,则舍弃该子段和;若0.2<d<0.4,则分别向前和向后取1/2(0.4-d)秒长度的声音信号加入该子段和,使其成为长度为0.4秒的帧。将每个帧通过一个高通滤波器滤去800hz以下的声音。
[0048]
步骤3.3:对于步骤3.2得到的每个固定长度的滤波后的帧,利用步骤2.1计算该帧的120维mfcc特征向量,然后利用步骤2.2计算该帧的240维gfcc特征向量,将两个向量拼接成该帧的360维混合式特征向量,然后送入训练好的lstm网络进行分类,判断该帧是否包含咳嗽、打喷嚏或吸鼻子行为。
[0049]
实施例
[0050]
为了测试本方法的性能,将本方法编写成一个安卓应用程序部署在不同型号的安卓手机中。并且招募了16位志愿者分别作为驾驶员和乘客,在不同的真实场景中驾驶和乘坐测试车辆。
[0051]
首先,测试本方法在驾驶环境下的总体准确率。图2显示了本方法和另外两种检测呼吸道症状方法(symdetector和coughsense)的总体准确率。由图可以看出,本方法的检测三种典型呼吸道症状的总体准确率为93.91%,而其他两种方法的总体准确率只有70.55%和67.64%,充分说明本方法在驾驶环境下有较高的准确性。
[0052]
然后,测试基于lstm的三种典型呼吸道症状分类器的准确性。图3显示了该分类器的混淆矩阵。由图可以看出,每类呼吸道症状的识别准确率都在93.64%以上,平均的识别准确率为95.52%。极少量的数据被分到了错误的类别,是因为当智能手机距离用户较远时,一些声音较小的呼吸道症状容易被误分到其他类,体现了本发明准确率高。
[0053]
最后,测试本方法在不同驾驶场景下的检测准确性。图4显示了每类呼吸道症状在城市街道、高速公路、乡村道路和停车场的检测召回率,由图可以看出停车场环境最安静,因此三类呼吸道症状在该区域中的检测召回率最高;高速公路上驾驶噪声较大,乡村道路不平整容易造成车辆颠簸,因此三类呼吸道症状在这两个区域中的检测召回率略低。然而在所有场景下三类呼吸道症状的检测召回率均不低于88.37%,体现了本发明普适性高。
[0054]
以上所述的具体实例是对本发明的进一步解释说明,并不用于限定本发明的保护范围,凡在本发明原则和精神之内,所做的更改和等同替换都应是本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1