音信号合成方法、生成模型的训练方法、音信号合成系统及程序与流程
1.本发明涉及将音信号进行合成的音源技术。
背景技术:
2.提出有专利文献1所示的nsynth、或者非专利文献1所示的npss(neural parametric singing synthesizer)等使用神经网络(下面,称为“nn”)而生成与条件输入相对应的声音波形的音源(下面,称为dnn(deep neural network)音源)。nsynth与嵌入(embedding/嵌入向量)相应地,针对每个采样周期而生成音信号的样本。npss的timbre模型与音调及定时信息相应地,针对每个帧而生成音信号的频谱。
3.专利文献1:美国专利第10068557号说明书
4.非专利文献1:merlijn blaauw,jordi bonada,、“a neural parametric singing synthesizer modeling timbre and expression from natural songs”,appl.sci.2017,7,1313
技术实现要素:
5.以往,作为表示音高的音高数据的形式而提出了one
‑
hot(独热)表达。one
‑
hot表达是通过与不同的音高相对应的n个(n为2以上的自然数)位而表达音高的方法。例如,在表达1个音高的one
‑
hot表达的向量中,将构成音高数据的n个位之中的与该音高相对应的1个位设定为“1”,将剩余的(n-1)个位分别设定为“0”。
6.在专利文献1的nsynth中,通过将one
‑
hot表达的音高数据输入至wavenet模型,从而生成与音高数据相对应的样本的时间序列。另外,在非专利文献1的npss中,通过将one
‑
hot表达的音高数据输入至f0模型而生成音高f0的轨迹,生成与其音高f0的轨迹相对应的谱包络的时间序列。这些one
‑
hot表达的音高数据是与在希望生成的音信号的音域内存在的音阶的总数同等大小的维数,由此,存在dnn音源的规模变大这样的问题。
7.在自然界的声音的生成机理中,大量发现人类的发声器官或者管乐器的发音机构等通过大致相同的物理构造而生成相差八度(octave)的音的情形。原本现有的dnn音源无法有效使用在上述相差八度的音之间共通的特征。
8.本发明的目的在于,有效使用相差八度的音的共通性,通过比较小的规模而高品质地生成宽音域的音高的音信号。
9.本发明的一个方式所涉及的音信号合成方法生成控制数据,该控制数据包含表示与应该合成的音信号的音高相对应的音名的音名数据和表示该音高的八度的八度数据,通过向对包含表示与参照信号的音高相对应的音名的音名数据及表示所述音高的八度的八度数据在内的控制数据和表示所述参照信号的输出数据之间的关系进行了学习的生成模型输入所生成的所述控制数据,从而对表示所述音信号的输出数据进行推定。
10.本发明的一个方式所涉及的生成模型的训练方法准备某音高的参照信号、表示与
该音高相对应的音名的音名数据、以及表示该音高的八度的八度数据,训练生成模型以与包含所述音名数据和所述八度数据在内的控制数据相应地生成表示所述参照信号的输出数据。
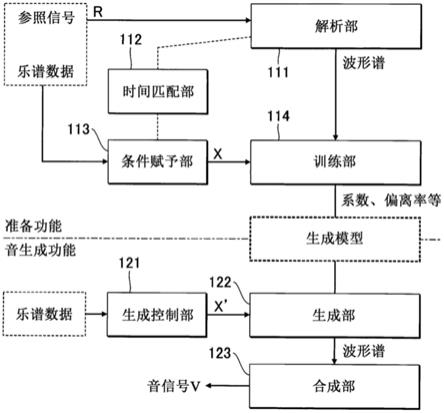
11.本发明的一个方式所涉及的音信号合成系统具有1个以上的处理器和1个以上的存储器,在该音信号合成系统中,所述1个以上的存储器对生成模型进行存储,该生成模型对包含表示与参照信号的音高相对应的音名的音名数据及表示该音高的八度的八度数据在内的控制数据和表示所述参照信号的输出数据之间的关系进行了学习,所述1个以上的处理器生成包含表示与应该合成的音信号的音高相对应的音名的音名数据和表示该音高的八度的八度数据在内的控制数据,通过将所生成的所述控制数据输入至所述生成模型,从而对表示所述音信号的输出数据进行推定。
12.本发明的一个方式所涉及的程序使计算机作为生成控制部及生成部起作用,该生成控制部生成控制数据,该控制数据包含表示与应该合成的音信号的音高相对应的音名的音名数据和表示该音高的八度的八度数据,该生成部通过向对包含表示与参照信号的音高相对应的音名的音名数据及表示所述音高的八度的八度数据在内的控制数据和表示所述参照信号的输出数据之间的关系进行了学习的生成模型输入所生成的所述控制数据,从而对表示所述音信号的输出数据进行推定。
附图说明
13.图1是表示音信号合成系统的硬件结构的框图。
14.图2是表示音信号合成系统的功能结构的框图。
15.图3是音名数据和八度数据的说明图。
16.图4是训练部和生成部的处理的说明图。
17.图5是准备处理的流程图。
18.图6是发音单位的音生成处理的流程图。
具体实施方式
19.a:第1实施方式
20.图1是例示本发明的音信号合成系统100的结构的框图。音信号合成系统100是通过具有控制装置11、存储装置12、显示装置13、输入装置14和放音装置15的计算机系统实现的。音信号合成系统100例如为移动电话、智能手机或者个人计算机等信息终端。此外,音信号合成系统100除了由单体的装置实现以外,也由相互地分体构成的多个装置(例如服务器-客户端系统)实现。
21.控制装置11是对构成音信号合成系统100的各要素进行控制的单个或者多个处理器。具体地说,例如通过cpu(central processing unit)、spu(sound processing unit)、dsp(digital signal processor)、fpga(field programmable gate array)或者asic(application specific integrated circuit)等1种以上的处理器而构成控制装置11。控制装置11生成表示合成音的波形的时间区域的音信号v。
22.存储装置12是对由控制装置11执行的程序和控制装置11所使用的各种数据进行存储的单个或者多个存储器。存储装置12例如由磁记录介质或者半导体记录介质等公知的
记录介质,或者多种记录介质的组合而构成。此外,也可以准备与音信号合成系统100分体的存储装置12(例如云储存器),控制装置11经由移动体通信网或者互联网等通信网而执行相对于存储装置12的写入及读出。即,存储装置12可以从音信号合成系统100被省略。
23.显示装置13对由控制装置11执行的程序的运算结果进行显示。显示装置13例如为显示器。显示装置13可以从音信号合成系统100被省略。
24.输入装置14接受用户的输入。输入装置14例如为触摸面板。输入装置14可以从音信号合成系统100被省略。
25.放音装置15对由控制装置11生成的音信号v所表示的声音进行播放。放音装置15例如为扬声器或者耳机。此外,关于将由控制装置11生成的音信号v从数字变换为模拟的d/a变换器和对音信号v进行放大的放大器,为了方便起见而省略了图示。另外,在图1中,例示出将放音装置15搭载于音信号合成系统100的结构,但也可以将与音信号合成系统100分体的放音装置15通过有线或者无线而与音信号合成系统100连接。
26.图2是表示音信号合成系统100的功能结构的框图。控制装置11通过执行在存储装置12中存储的程序,从而实现生成功能(生成控制部121、生成部122及合成部123),即,使用生成模型而生成表示歌手的歌唱音或者乐器的演奏音等声音波形的时间区域的音信号v。另外,控制装置11通过执行在存储装置12中存储的程序,从而实现准备功能(解析部111、时间匹配部112、条件赋予部113及训练部114),即,进行在音信号v的生成中使用的生成模型的准备。此外,也可以通过多个装置的集合(即系统)而实现控制装置11的功能,也可以将控制装置11的功能的一部分或者全部由专用的电子电路(例如信号处理电路)实现。
27.首先,对音名数据及八度数据、与音名数据及八度数据相应地生成输出数据的生成模型、以及在生成模型的训练中使用的参照信号r进行说明。
28.音名数据和八度数据是通过两数据的数据对而表示音信号v的音高。音名数据(pitch notation data,下面,称为“pn数据”)x1表示与1个八度的12个音阶分别对应的12个音高音之中的音信号v的音高的音名(“c”、“c#”、“d”、
…“
a#”、“b”)。八度数据(octave data,下面,称为“oct数据”)x2表示不同的多个八度之中的音信号v的音高所属的八度(是从基准起第几个八度)。如图3中例示那样,pn数据x1和oct数据x2可以如以下例示那样,各自为one
‑
hot表达。
29.pn数据x1由与不同的音名相对应的12个位构成。构成pn数据x1的12位之中的与音信号v的音高的音名相对应的1位设为“1”,剩余的11位设为“0”。oct数据x2由与不同的八度(o1~o5)相对应的5个位构成。构成oct数据x2的5位之中的与包含音信号v的音高的八度相对应的1位设为“1”,剩余的4位设为“0”。此外,第1实施方式的oct数据x2是与5个八度量相对应的5位的数据,但能够由oct数据x2表达的八度数是任意的。表示n个八度(n为1以上的自然数)的任意者的oct数据x2是由n位构成的数据。
30.生成模型是与包含pn数据x1和oct数据x2在内的控制数据x相应地,用于生成音信号v的波形谱(例如,梅尔谱图)的时间序列的统计模型。控制数据x是对应该合成的音信号v的条件进行指定的数据。生成模型的生成特性由在存储装置12中存储的多个变量(系数及偏离率等)规定。统计模型是对波形谱进行推定的神经网络。其神经网络例如可以是基于如wavenet(tm)这样的音信号v的过去的多个样本,对当前的样本的概率密度分布进行推定的回归类型。另外,其算法也是任意的,例如可以是cnn(convolutional neural network)类
型,也可以是rnn(recurrent neural network)类型,也可以是其组合。并且,可以是具有lstm(long short
‑
term memory)或者attention等附加要素的类型。生成模型的多个变量通过使用后面记述的准备功能所涉及的训练数据的训练而建立。建立了多个变量的生成模型在后面记述的生成功能中用于音信号v的生成。
31.存储装置12为了生成模型的训练,记录有多个表示由播放器对某乐谱进行了演奏的时间区域的波形的音信号(下面,称为“参照信号”)r和表示该乐谱的乐谱数据。各乐谱数据包含音符的时间序列。与各乐谱数据相对应的参照信号r包含与该乐谱数据所表示的乐谱的音符的系列相对应的部分波形的时间序列。各参照信号r是由针对每个采样周期(例如,48khz)的样本的时间序列构成,表示音的波形的时间区域的信号。演奏并不限定于由人进行的乐器的演奏,也可以是由歌手进行的歌唱、或者乐器的自动演奏。为了通过机器学习而生成良好的音,通常要求充分数量的训练数据,因此关于设为目标的乐器或者播放器等,事先收录很多演奏的音信号,作为参照信号r而存储于存储装置12。
32.对在图2的上部图示的准备功能进行说明。解析部111关于与多个乐谱各自对应的多个参照信号r,分别针对时间轴上的每个帧(时间帧)对频率区域的频谱(下面,称为波形谱)进行计算。在计算参照信号r的波形谱时,例如使用离散傅立叶变换等公知的频率解析。
33.时间匹配部112基于通过解析部111得到的波形谱等信息,使各参照信号r所对应的乐谱数据中的多个发音单位的开始时刻和结束时刻,与参照信号r中的该发音单位所对应的部分波形的开始时刻和结束时刻对齐。在这里,发音单位例如是指定出音高和发音期间的1个音符。此外,也可以将1个音符以音色等的波形的特征变化的点进行分割而分为多个发音单位。
34.条件赋予部113基于与各参照信号r时间对齐的乐谱数据的各发音单位的信息,针对以帧为单位的每个时刻t,生成与参照信号r之中的该时刻t的部分波形相对应的控制数据x而输出至训练部114。控制数据x如前述那样,对应该合成的音信号v的条件进行指定。控制数据x如图4所例示那样,包含pn数据x1、oct数据x2、开始停止数据x3和关联性数据x4(concontext data)。pn数据x1表示参照信号r的部分波形中的音高的音名。oct数据x2表示该音高所属的八度。即,参照信号r的部分波形的音高通过pn数据x1和oct数据x2的数据对进行表达。开始停止数据x3表示各部分波形的开始期间(起音)和结束期间(释音)。与1个音符相当的部分波形内的1个帧的关联性数据x4是表示该音符和前后的音符之间的音高差或者乐谱内的该音符的相对位置的信息等,表示与多个发音单位之间的关系(即关联性)。在控制数据x中,还可以包含乐器、歌手或者演奏方法等其他信息。
35.准备用于对生成模型进行训练的多个发音单位数据,该生成模型根据通过解析部111及条件赋予部113进行的处理的结果、多个参照信号r和多个乐谱数据而生成规定的音高范围内的音信号v。各发音单位数据是由条件赋予部113生成的控制数据x和由解析部111生成的波形谱的数据集。多个发音单位数据在通过训练部114进行训练之前,分为用于生成模型的训练的训练数据和用于生成模型的测试的测试数据。将多个发音单位数据的大部分设为训练数据,将一部分设为测试数据。通过训练数据进行的训练是将多个发音单位数据以每规定数量的帧为一批次(batch)进行分割,以批次单位在全部批次范围而依次进行。
36.训练部114如图4的上部例示那样,接收训练数据,依次使用其各批次的多个发音单位的波形谱和控制数据x而对生成模型进行训练。生成模型针对每个帧(时刻t),对表示
波形谱的输出数据进行推定。输出数据可以是对构成波形谱的多个成分各自的概率密度分布进行表示的数据,也可以是各成分的值。训练部114通过将1个批次量的各发音单位数据中的控制数据x输入至生成模型,由此对与该控制数据x相对应的输出数据的时间序列进行推定。训练部114基于推定出的输出数据和训练数据之中的相对应的波形谱(即正确值)对损失函数l(对应于1批次量的累积值)进行计算。而且,训练部114将生成模型的多个变量进行优化,以使得其损失函数l最小化。例如,作为损失函数l,在输出数据为概率密度分布的情况下使用交叉熵函数等,在输出数据为波形谱的值的情况下使用平方误差函数等。训练部114直至关于测试数据而计算的损失函数l的值变得充分小、或者相前后的损失函数l的变化变得充分小为止反复进行使用训练数据的上述的训练。这样建立的生成模型对在多个发音单位数据中的各控制数据x和对应的波形谱之间潜在的关系进行学习。通过使用该生成模型,从而生成部122关于未知的音信号v的控制数据x’,也能够生成品质良好的波形谱。
37.图5是准备处理的流程图。准备处理例如是以来自音信号合成系统100的利用者的指示为契机而开始的。
38.如果准备处理开始,则控制装置11(解析部111)根据多个参照信号r的各个而分别生成各部分波形的波形谱(sa1)。接下来,控制装置11(时间匹配部112及条件赋予部113)根据与其部分波形相对应的乐谱数据,创建包含与其部分波形相对应的发音单位的pn数据x1和oct数据x2在内的控制数据x(sa2)。控制装置11(训练部114)使用各发音单位的控制数据x和与该发音单位相对应的波形谱而对生成模型进行训练,建立生成模型的多个变量(sa3)。
39.在以上说明的方式中,例示出以pn数据x1和oct数据x2的数据集表示音高的结构,但还设想到利用对遍及多个八度的多个音高(12半音
×
n八度)的任意者进行表示的one
‑
hot表达的音高数据的结构(以下称为“对比例”)。与对比例相对照,在第1实施方式中,将包含pn数据x1和oct数据x2在内的控制数据x作为输入而对生成模型进行训练。因此,所建立的生成模型成为充分发挥出自然界的相差八度的音的共通性的模型。该生成模型能够以比对比例的通过音高数据进行训练的通常的生成模型小的规模,掌握同等品质的音信号v的生成能力。或者,能够以与通常的生成模型相同的规模,掌握更高品质的音信号v的生成能力。并且,在第1实施方式的生成模型中,在训练时,在关于某八度的音高没有执行使用参照信号r的训练的情况下,在生成时也通过pn数据x1和oct数据x2对其音高进行指定,由此生成其音高的音信号v的可能性变高。
40.接下来,对在图2的下部图示的使用生成模型而生成音信号v的音生成功能进行说明。生成控制部121基于应该播放的乐谱数据所表示的一系列的发音单位的信息,生成控制数据x’而输出至生成部122。控制数据x’表示乐谱数据的各时刻t的发音单位的条件。具体地说,控制数据x’包含pn数据x1’、oct数据x2’、开始停止数据x3’和关联性数据x4’。此外,控制数据x’也可以还包含乐器、歌手或者演奏方法等其他信息。
41.生成部122如图4的下部例示那样,使用建立有多个变量的生成模型,生成与控制数据x相对应的波形谱的时间序列。生成部122使用生成模型,针对每个帧(时刻t),对表示与控制数据x’相对应的波形谱的输出数据进行推定。在推定的输出数据表示构成波形谱的多个成分各自的概率密度分布的情况下,生成部122生成按照其成分的概率密度分布的随机数,将该随机数作为波形谱的成分值而输出。在所推定的输出数据表示多个成分的值的
情况下,输出其成分值。
42.合成部123对频率区域的波形谱的时间序列进行接收,将与其波形谱的时间序列相对应的时间区域的音信号v进行合成。合成部123为所谓的声码器。例如,合成部123根据波形谱而求出最小相位谱,通过针对这些波形谱和相位谱执行逆傅立叶变换而将音信号v进行合成。或者,使用对在波形谱和音信号v之间潜在的关系进行了学习的神经声码器,从波形谱直接地合成音信号v。
43.图6是各发音单位的音生成处理的流程图。该音生成处理例如是在以来自音信号合成系统100的利用者的指示为契机而行进的时刻t每次到达乐谱数据所表示的各发音单位(例如音符)的开始时刻时,为了其发音单位而开始的。
44.如果与某发音单位相关的音生成处理开始,则控制装置11(生成控制部121)基于乐谱数据,生成其发音单位的控制数据x’(sb1)。接下来,控制装置11(生成部122)使用生成模型,生成与所生成的控制数据x’相对应的其发音单位的音信号v的波形谱(sb2)。接下来,控制装置11(合成部123)与所生成的波形谱相应地,合成其发音单位的音信号v(sb3)。以上的处理关于乐谱数据的多个发音单位而依次进行,由此生成与乐谱数据相对应的音信号v。此外,在时间相前后的发音单位的音信号v重叠的情况下,将它们混合而计算音信号v。
45.在这里,通过在控制数据x’所包含的pn数据x1’和oct数据x2’而指定出应该合成的音信号v的音高,充分发挥自然界的相差八度的音的共通性而有效地进行训练,使用所建立的生成模型,能够生成与控制数据x’相对应的高品质的音信号v。
46.b:第2实施方式
47.第1实施方式的生成部122生成波形谱,但在第2实施方式中,生成部122使用生成模型而生成音信号v。第2实施方式的功能结构基本上与图2相同,但不需要合成部123。训练部114使用参照信号r对生成模型进行训练,生成部122使用其生成模型而生成音信号v。第1实施方式中的训练用的发音单位数据为控制数据x和波形谱的数据集,与此相对,第2实施方式中的训练用的发音单位数据为各发音单位的控制数据x和参照信号r的部分波形(即,参照信号r的样本)的数据集。
48.第2实施方式的训练部114对训练数据进行接收,依次使用其各批次的多个发音单位的部分波形和控制数据x对生成模型进行训练。生成模型针对每个采样周期(时刻t),对表示音信号v的样本的输出数据进行推定。训练部114基于根据控制数据x而推定出的输出数据的时间序列和训练数据之中的相对应的部分波形而对损失函数l(对应于1个批次量的累积值)进行计算,将生成模型的多个变量进行优化以使得其损失函数l最小化。这样建立的生成模型对在多个发音单位数据中的各控制数据x和参照信号r的部分波形之间潜在的关系进行了学习。
49.第2实施方式的生成部122使用所建立的生成模型,生成与控制数据x’相对应的音信号v。生成部122使用生成模型,针对每个采样周期(时刻t),对表示与控制数据x’相对应的音信号v的样本的输出数据进行推定。在输出数据表示多个样本各自的概率密度分布的情况下,生成部122生成按照其成分的概率密度分布的随机数,将该随机数作为音信号v的样本而输出。在输出数据表示样本的值的情况下,输出其样本。
50.c:第3实施方式
51.在图2所图示的第1实施方式中,例示出基于乐谱数据的一系列的发音单位的信息
而生成音信号v的音生成功能,但也可以基于从键盘等供给的发音单位的信息而实时地生成音信号v。在该情况下,生成控制部121基于直至该时刻t为止所供给的发音单位的信息,生成各时刻t的控制数据x。在这里,在控制数据x所包含的关联性数据x4中,基本上无法包含未来的发音单位的信息,但可以根据过去的信息而预测未来的发音单位的信息,使得包含未来的发音单位的信息。
52.上述实施方式的pn数据x1和oct数据x2各自为one
‑
hot表达,但也可以是其他表达形式。例如,可以将pn数据x1及oct数据x2的任一者或者两者的数据设为coarse表达。
53.上述实施方式的pn数据x1和oct数据x2各自固定维数而进行了说明,但可以是任意的维数。例如,可以将pn数据x1的维数设为比12维小的维数,利用表示分配给不同的音高的多个数值之中的任意者的pn数据x1。也可以将pn数据x1的维数设为比12维大的维数,对各音名的中间音高进行表达。另外,也可以额外地追加oct数据x2的维数。音信号v可以与表示演奏音的乐器的八度宽度相应地改变oct数据x2的维数,也可以将oct数据x2的维数通过表示多种乐器之中的音域宽度最大的乐器的音高所需的维数进行固定。
54.此外,由音信号合成系统100进行合成的音信号v并不限定于乐器音或者语音,也可以是动物的鸣叫声或者风声及波浪声这样的自然界的音,在希望进行其音高的动态控制的情况下,能够应用本发明。
55.标号的说明
56.100
…
音信号合成系统,11
…
控制装置,12
…
存储装置,13
…
显示装置,14
…
输入装置,15
…
放音装置,111
…
解析部,112
…
时间匹配部,113
…
条件赋予部,114
…
训练部,121
…
生成控制部,122
…
生成部,123
…
合成部。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1