一种基于加性角惩罚焦点损失的语音情感识别方法
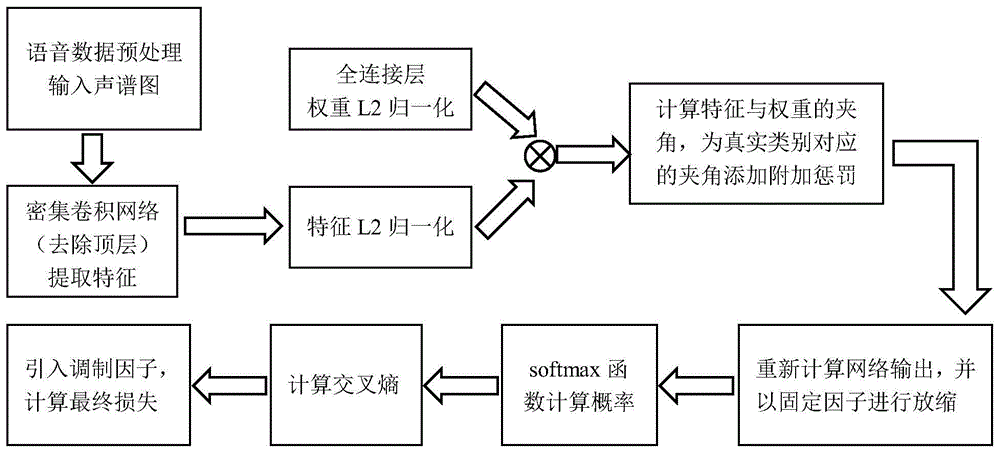
本发明涉及语音信号处理、情感识别技术,具体涉及一种基于加性角惩罚焦点损失的语音情感识别方法。
背景技术:
语音是人类之间相互沟通的工具,是信息交互的重要桥梁。它不仅显式地表达了语言学内容,还隐式地蕴含着说话人的副语言信息。语音包含着说话人在某一情境下的情感状态,能够促进交流的双方更好地相互理解。对于人机交互系统来说,具有智能情感是必不可少的。语音情感识别的目的就是通过分析人类语音关于情感的变化规律,利用计算机从中提取有效的情感差异特征,并根据这些特征判断对象的情感状态,从而基于这一判别结果进行更加合理的反馈。对于情感,一般使用离散标签进行描述,基本的情感状态包括高兴、愤怒、恐惧、惊讶、悲伤以及中性情感等。语音情感识别具有重要的现实研究意义,比如在日常娱乐方面,各种音乐软件可以根据用户语音中体现的情感状态,推荐更加合适的风格的歌曲,舒缓用户的心理压力;在医疗领域,在患者允许的情况下,可以通过收集患者的语音信息来辅助医生进行诊断和治疗;对于一个语音助手来说,具备优秀的语音情感识别能力可以为使用者提供更加优质、更加人性化的服务。语音情感识别技术可以应用到人类生活的方方面面,促进人与人之间的和睦相处,提升人们的生活质量,有助于社会的和谐进步。
语音情感识别系统的三个关键环节分别为语音信号特征提取、分类器选择和目标损失函数设计。语音信号特征提取的传统做法是使用专家根据语音的声学特性,再结合一些聚合函数,人工设计的特征,如egemaps、is09和compare语音特征集等。由于手工设计的特征一般是低水平特征,不足以特别有效地描述语音情感信息,因此近年来的研究开始使用深度学习模型作为特征学习器,提取语音高水平的情感差异特征。对于一个端到端的深度学习模型,通常会选择softmax分类器完成最后的分类。而目标损失函数是深度学习模型的训练目标,指导着模型在训练过程中迭代优化的方向。目前国内外研究者在实现语音情感识别这一任务上,大多数都是使用经典的交叉熵损失函数作为目标函数,而交叉熵损失函数并不具备鼓励模型学习特别有效的区分性特征的能力,这就导致了最终语音情感识别系统的性能不佳。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种识别准确率高的基于加性角惩罚焦点损失的语音情感识别方法。
本发明至少通过如下技术方案之一实现。
一种基于加性角惩罚焦点损失的语音情感识别方法,包括以下步骤:
s1、对语音情感数据库进行数据预处理,限制语音样本的最大长度,将数据从音频格式转换为相应的声谱图图像表示,再根据最大长度将声谱图调整至统一大小,作为深度学习模型的输入;
s2、搭建密集卷积网络作为深度学习模型,用于提取语音的情感差异特征;
s3、设计基于加性角惩罚的焦点损失函数,作为目标函数对深度学习模型进行训练;
s4、基于学得的区分性特征,使用softmax分类器完成情感识别。
优选的,所述步骤s1的数据预处理具体包括以下步骤:
s11、统计数据库中语音样本长度的分布情况,计算其四分之三位数作为最大长度l,对长度小于l的样本不作处理,对长度大于l的样本进行裁剪;
s12、使用傅里叶变换,将语音样本从时间域变换到频率域,整合两个域的信息,获得相应的声谱图图像表示,大小为时间维度t×频率维度f;
s13、记录音频长度为最大长度l的样本相应的声谱图的时间维度的大小tmax,对时间维度t小于tmax的所有声谱图进行零值填充,使得所有声谱图统一大小为tmax×f。
优选的,步骤s11中的最大长度l随数据库不同而改变。
优选的,步骤s12中的时间维度t是变值,其上限取决于步骤s11计算得到的最大长度l相应的声谱图的时间维度大小tmax,频率维度f是定值。
优选的,步骤s2采用在imagenet图像数据库上预训练的密集卷积网络densenet169作为深度特征提取器,将其顶部的全连接层修改为一个输出维度为d的全连接层。
优选的,修改的全连接层的输出维度d取决于使用的语音情感数据库包含的情感类别数。
优选的,步骤s3中基于加性角惩罚的焦点损失函数apfl训练深度学习模型具体包括以下步骤:
s31、将深度学习模型最后一个全连接层的输入和权重进行l2归一化,并将其偏置项置为零,此时该全连接层的输出为cosθj,其中θj是最后一层全连接层的权重向量wj和第i个样本的特征向量xi之间的夹角,j∈[1,…,yi,…,n],yi为第i个样本对应的真实类别,n为数据库包含的情感类别数;
s32、利用反余弦三角函数计算得到最后一层全连接层的权重向量wj和第i个样本的特征向量xi之间的夹角θj;
s33、对目标项
s34、通过softmax函数计算概率
s35、引入调制系数γ,得到最终的损失函数apfl,具有以下形式:
其中n是数据库的训练样本总量;n是数据库所包含的情感类别数;yi是第i个样本对应的真实类别;θj是最后一层全连接层的权重向量wj和第i个样本的特征向量xi之间的夹角;超参数s是用于帮助模型快速收敛的放缩因子;超参数m是附加的角度惩罚项,引导模型朝同类样本更加密集、异类样本更加分散的方向训练;超参数γ是调制系数,控制困难样本和简单样本对损失值的影响权重;
s36、以apfl作为目标函数训练深度学习模型。
优选的,步骤s4基于以apfl作为目标函数训练模型学习得到的特征作为分类器的输入,实现语音情感识别。
本发明相对于现有技术具有如下的优点及效果:
1、使用密集卷积网络提取高级差异特征,缓解人工特征不够有效的问题。
2、设计并采用新颖的基于加性角惩罚的焦点损失函数,具有以下三个优点:
(1)减小同类样本之间的距离,使得同类簇更加密集;
(2)增大异类样本之间的距离,使得异类簇更加分散,决策边界更加清晰;
(3)对难以正确分类的困难样本给予更多的关注,提高其在总损失中的权重,降低简单样本的影响,避免模型的训练被简单样本淹没。
这些优点在不同的层次上发挥作用,可以共同提高语音情感识别的准确率。
3、提出的损失函数apfl具备更优的性能和更强的稳定性。
附图说明
图1是基于加性角惩罚焦点损失的语音情感识别方法的模型训练框架图;
图2是采用的密集卷积网络的结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行完整、清晰的描述。显然,所描述的实施例是本发明的一个实施例,而不是全部的实施例。
如图1所示,本实施例公开了一种基于加性角惩罚焦点损失的语音情感识别方法,具体包括以下步骤:
s1、对语音情感数据库进行数据预处理,限制语音样本的最大长度,将数据从音频格式转换为相应的声谱图图像表示,再根据最大长度将声谱图调整至统一大小,作为深度学习模型的输入;
s11、本实施例选用iemocap英语语料数据库、emodb德语语料数据库和savee英语语料数据库,分别包含4种、7种和7种情感类型;统计数据库中语音样本长度的分布情况,计算其四分之三位数作为最大长度l,对长度小于l的样本不作处理,对长度大于l的样本进行裁剪;对于iemocap、emodb和savee三个语料数据库,计算得到的最大长度l分别为6s、4s和5s。
s12、使用傅里叶变换,将语音样本从时间域变换到频率域,整合两个域的信息,获得相应的声谱图图像表示,大小为时间维度t×频率维度f;时间维度t为变值,频率维度f为定值;对于iemocap、emodb和savee三个语料数据库,时间维度t的上限分别为600、400和500,频率维度f均为400。
s13、记录音频长度为最大长度l的样本相应的声谱图的时间维度的大小tmax,对时间维度t小于tmax的所有声谱图进行零值填充,使得所有声谱图统一大小为tmax×f;对于iemocap、emodb和savee三个语料数据库,获得的声谱图大小分别为600×400、400×400和500×400。
s2、搭建密集卷积网络作为深度学习模型,用于提取语音的情感差异特征;
s3、设计基于加性角惩罚的焦点损失函数,作为目标函数对深度学习模型进行训练,具体包括以下步骤:
s31、将深度学习模型最后一个全连接层的输入和权重进行l2归一化,并将其偏置项bj置为零,此时该全连接层的输出为
s32、利用反余弦三角函数计算得到最后一层全连接层的权重向量wj和第i个样本的特征向量xi之间的夹角θj:θj=arccos(cosθj);
s33、对目标项
s34、通过softmax函数计算概率
s35、引入调制系数γ,得到最终的损失函数apfl,具有以下形式:
其中n是数据库的训练样本总量;n是数据库所包含的情感类别数;yi是第i个样本对应的真实类别;θj是最后一层全连接层的权重向量wj和第i个样本的特征向量xi之间的夹角;超参数s是用于帮助模型快速收敛的放缩因子;超参数m是附加的角度惩罚项,引导模型朝同类样本更加密集、异类样本更加分散的方向训练;超参数γ是调制系数,控制困难样本和简单样本对损失值的影响权重;
s36、以apfl作为目标函数训练深度学习模型。
s4、基于学得的区分性特征,使用softmax分类器完成情感识别。
本实施例中步骤s2选用的是在imagenet图像数据库上预训练的densenet169,保留其全局均值池化及之前的所有层,在全局均值池化层之后添加包含d个神经元(即输出维度为d)的全连接层,d值取决于使用的语音情感数据库所包含的情感类别数,最终具体网络结构如图2所示,其中四个密集连接模块分别由6、12、32、32个瓶颈结构密集连接而成,过渡层进行特征降维,所有的卷积操作实际上为批归一化-relu函数激活-卷积的结构;对于iemocap、emodb和savee三个语料数据库,d值分别为4、7和7;各数据库均采用k折交叉验证的训练策略,进行说话人独立实验,即每次仅使用一个说话人的数据作为测试集,其余作为训练集,并且每折进行多次实验以保证结果的可靠性;对于iemocap、emodb和savee三个语料数据库,k值分别为5、10和4。
本实施例中步骤s3设计的损失函数apfl具有超参数s、m和γ,对于iemocap的设置为s=10,m=0.30,γ=0.50,对于emodb的设置为s=10,m=0.50,γ=0.10,对于savee的设置为s=10,m=0.50,γ=5.0;深度学习模型densenet169使用adadelta优化器进行训练,其配置学习率为1,ε为1e-10,ρ为0.95。
在iemocap、emodb和savee数据库下,如表1所示为本实施例基于加性角惩罚焦点损失apfl的语音情感识别方法和现有损失函数celoss、focalloss和arcface指导的语音情感识别方法的识别准确率的对比,包括加权准确率wa(识别正确样本数/测试集总样本数)和未加权准确率ua(所有类别识别准确率之和/类别数)的均值及标准差;其中所有方法除了损失函数不同之外,其余配置均保持一致,且所有方法都为最佳超参数下的结果;可以看到本实施例方法的识别准确率均为最高,且模型基本更加稳定。
表1
以上实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所做的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!