基于卷积循环网络和WPE算法的语音增强混合处理方法
基于卷积循环网络和wpe算法的语音增强混合处理方法
技术领域
1.本发明属于语音增强的领域,主要针对低信噪比、非稳态噪声、强混响情景下的语音增强任务。
背景技术:
2.在人类日常生活环境中采集语音过程往往存在以下干扰——背景噪声、混响声:背景噪声来源于说话人环境中的干扰声源,对于声能量随时间变化幅度较小的背景噪声,如空调机、洗衣机发出的声音等,它们被称为稳态噪声。而如音乐播放器的歌声、街道上突然响起的喇叭声等声能量随时间变化较为剧烈的噪声,则称为非稳态噪声。在语音信号处理中常用信噪比来衡量任意时刻目标语音与噪声能量的比值,而噪声是否稳态、信噪比高或低往往就对应着不同的噪声抑制策略。混响来源于声源辐射的声波经环境中物体表面,如墙面、天花板等,反射后再次被传声器接收,常用混响时间(声压级下降60db所需时间)来衡量环境的混响程度。在语音中保留早期混响对人的听感是有益的,而晚期混响则可能会造成音质的损失,因此构建出有效消除晚期混响的模型是十分必要的。上述干扰都可能会造成语音的失真,严重影响语音的清晰度、可懂性,给听者带来不良好的听感体验,也会给进一步的语音处理,如自动语音识别、情感分析等,带来更大的困难,而这些技术在目前的人工智能领域都有重要的应用,与人们的日常生活日益密切。因此提取含噪混响语音中清晰语音成分的语音增强技术是研究者们的重要课题。
3.谱减法可以用来实现噪声抑制。该方法基于最小均方误差(minimum mean-squared error,mmse)估计噪声功率谱(gerkmann t,hendriks r c.unbiased mmse-based noise power estimation with low complexity and low tracking delay[j].ieee transactions on audio speech&language processing,2012,20(4):1383
–
1393),随后将含噪语音功率谱减去噪声功率谱得到增强语音的功率谱,再结合含噪语音短时傅里叶谱的相位信息得到增强语音短时傅里叶谱,再经逆傅里叶变换得到增强语音信号。谱减法在许多场景下取得了良好的噪声抑制效果,但由于其假设的噪声和语音模型的限制,该算法在处理某些低信噪比、非稳态噪声场景语音的效果较差,容易导致语音的失真。
[0004]
wpe算法被用于语音的去混响(nakatani t,yoshioka t,kinoshita k,et al.speech dereverberation based on variance-normalized delayed linear prediction[j].ieee transactions on audio speech&language processing,2010,18(7):1717
–
1731)。它对语音短时傅里叶谱建立时帧的自回归模型,通过迭代的方式估计逆滤波器系数和早期混响的功率谱,进而求得清晰语音的短时傅里叶谱。wpe算法在语音去混响上取得了优越的效果,但算法的迭代特性使其难以运用在短延时的实时处理当中。
[0005]
近几年来,多种基于深度学习的模型被运用到语音增强领域。卷积循环网络在复杂环境语音噪声抑制上取得了突破(zhao h,zarar s,tashev i,et al.convolutional-recurrent neural networks for speech enhancement[c]//icassp2018-2018ieee international conference on acoustics,speech and signal processing(icassp)
.2018),卷积网络提取了语音短时傅里叶谱的二维局部特征,而循环网络则建立起短时傅里叶谱帧与帧之间的联系,最近提出的双通道循环网络又进一步建立起了每一帧中各个频点的联系,这有利于分析语音中的谐波成分(luo y,chen z,yoshioka t.dual-path rnn:efficient long sequence modeling for time-domain single-channel speech separation[c]//icassp 2020-2020ieee international conference on acoustics,speech and signal processing(icassp).2020)。注意机制的引入又更好地过滤了噪声的特征信息(zhou l,gao y,wang z,et al.complex spectral mapping with attention based convolution recurrent neural network for speech enhancement[j].arxiv preprint arxiv:2104.05267,2021)。
[0006]
然而,在实际应用中,语音采集环境复杂多变,噪声的类型多种多样,传统基于规则的算法很难将所有情况统一至一个数学模型下,而数据驱动的深度神经网络运用多种噪声和混响环境下的语音进行训练,能适应低信噪比、非稳态噪声等复杂语音环境,达到良好的处理效果,而将传统算法融入深度神经网络框架有利于增强模型的鲁棒性。
技术实现要素:
[0007]
传统基于规则的方法在对低信噪比、非稳态噪声、强混响环境下的语音进行增强时往往难以去除噪声成分,甚至会造成严重的语音失真。本发明提出基于卷积循环神经网络和wpe去混响算法的混合语音增强方法,能对受干扰较为严重的语音进行增强,得到清晰语音成分。
[0008]
本发明采用的技术方案为:
[0009]
基于卷积循环网络和wpe算法的语音增强混合处理方法,其特征在于,该方法包括以下步骤:
[0010]
步骤1,使用清晰语音数据集、噪声数据集以及房间冲激响应数据集合成模拟含噪混响语音;
[0011]
步骤2,对模拟含噪混响语音数据和对应的清晰语音数据分别做短时傅里叶变换得到两者的短时傅里叶谱;
[0012]
步骤3,构建dpcarn-wpe模型,该模型结构由深度神经网络结构和wpe去混响算法结构组成;使用步骤2得到的短时傅里叶谱训练所述dpcarn-wpe模型权重;
[0013]
步骤4,对待增强的含噪混响语音信号做短时傅里叶变换得到短时傅里叶谱;
[0014]
步骤5,将步骤4获得的短时傅里叶谱输入步骤3完成训练的dpcarn-wpe模型,输出增强语音的短时傅里叶谱;
[0015]
步骤6,对增强语音的短时傅里叶谱进行逆短时傅里叶变换得到增强语音的时域信号。
[0016]
本发明的方法能够在强混响、低信噪比、非稳态噪声等多种复杂噪声场景下对语音进行增强,鲁棒性较高。与基于复高斯模型的传统噪声抑制算法相比,本发明的方法能适应更为复杂的噪声类型,且在低信噪比环境下仍能较为准确地区分噪声和语音成分;在去混响方面,本发明将神经网络与wpe算法相结合的结构能有效降低wpe算法的迭代次数,有利于实现线上实时运算。本发明的方法在crn的基础上,对其中的循环神经网络结构进行改进,使模型能对语音信号中的谐波特征进行建模,保证语音的主观听感,并在编码器和解码
器之间加入注意机制,进一步剔除噪声成分,保留更纯净的语音信息。
附图说明
[0017]
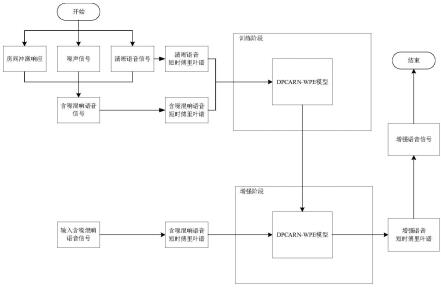
图1是本发明在训练阶段和增强阶段的方法处理流程图。
[0018]
图2为dpcarn-wpe模型具体框架,stft指短时傅里叶变换,encoder指编码器,cnn指卷积神经网络,dprnn指的是双通道循环神经网络,decoder指解码器,istft指的是逆傅里叶变换,attention指注意机制,elementwiseproduct指矩阵元素层面相乘。
[0019]
图3为本发明实施例中编码器的结构示意图。
[0020]
图4为本发明实施例中双通道循环神经网络的结构示意图。
[0021]
图5为本发明实施例中解码器的结构示意图。
[0022]
图6为本发明实施例中注意机制的结构示意图。
[0023]
图7为本发明方法与传统方法处理语音增强结果对比图,(a)清晰语音信号,(b)含噪混响信号,(c)传统方法处理结果,(d)本发明方法处理结果。
具体实施方式
[0024]
本实施例提供一种基于卷积循环网络和wpe算法的语音增强混合处理方法,如图1所示,包括以下步骤:
[0025]
步骤1,使用清晰语音数据集、噪声数据集以及房间冲激响应数据集合成模拟含噪混响语音;
[0026]
步骤2,对模拟含噪混响语音数据和对应的清晰语音数据分别做短时傅里叶变换得到两者的短时傅里叶谱;
[0027]
步骤3,构建dpcarn-wpe模型,该模型结构由深度神经网络结构和wpe去混响算法结构组成;使用模拟含噪混响语音数据和对应的清晰语音数据的短时傅里叶谱训练dpcarn-wpe模型权重;
[0028]
步骤4,对待增强的含噪混响语音信号做短时傅里叶变换得到短时傅里叶谱;
[0029]
步骤5,将待增强的含噪混响语音信号的短时傅里叶谱输入完成训练的dpcarn-wpe模型,输出增强语音的短时傅里叶谱;
[0030]
步骤6,对增强语音的短时傅里叶谱进行逆短时傅里叶变换得到增强语音的时域信号。
[0031]
1、wpe去混响算法
[0032]
wpe去混响算法用迭代的方式估计期望清晰语音的功率谱密度,设计逆滤波器消除语音中的晚期混响成分,具体过程如下:
[0033]
在短时傅里叶变换域中,考虑n点混响信号y(n,k),n=0,1,2,...,n-1,n为时域帧索引,k为频点索引,且混响信号满足以下自回归模型:
[0034]
y(n,k)=d(n,k)+gh(k)y(n-d,k)
ꢀꢀꢀ
(1)
[0035]
g(k)=[g(0,k),g(1,k),...,g(l
g-1,k)]
t
ꢀꢀꢀ
(2)
[0036]
y(n,k)=[y(n,k),y(n-1,k),...,y(n-lg+1,k)]
t
ꢀꢀꢀ
(3)
[0037]
其中d(n,k)为期望清晰信号的时频点,g(k)为每个频点k对应的逆滤波器系数,lg为逆滤波器阶数,d为划分早期混响和晚期混响的时刻点,()h表示矩阵的共轭转置,()
t
表
示矩阵的转置,()
*
表示复数共轭。
[0038]
假设期望信号d(n,k)满足零均值的复高斯分布,且方差λ(n,k)是随时间变化的,则概率密度函数为:
[0039][0040]
这里λ(n,k)可视为期望信号的功率谱密度,它也是一个待估计量。此时该高斯分布模型中需要估计的参数为g(k)和λ(n,k)。考虑采样的信号总帧数为n,则在每个独立的频点k上的似然函数为:
[0041][0042]
使用最大似然估计法寻找最优的参数解,但这里无法同时优化g(k)和λ(0,k),λ(1,k),
…
,λ(n-1,k)两组参数,因此选择迭代的方式逐步增大解得
[0043][0044]
其中
[0045][0046][0047][0048]
当收敛至稳定值或迭代达到最大迭代次数时结束迭代。wpe算法结构便输出增强后语音的短时傅里叶谱
[0049]
2、dpcarn-wpe模型的训练
[0050]
dpcarn-wpe模型的输入为含噪混响信号的短时傅里叶谱,记为y,其中n为时域总帧数,k为频率总点数,表示复数域,在输入模型后,解码器(decoder)输出为实现噪声抑制的复比率遮罩(complex raito mask,crm)m,运用crm的优点在于能同时对短时傅里叶谱的幅度和相位进行调整,则得到的噪声抑制信号短时傅里叶谱为:
[0051]sns
=m
·yꢀꢀꢀ
(10)
[0052]
·
表示元素层面相乘。随后s
ns
再经过1次迭代的wpe算法结构,得到的语音增强信号为:
[0053][0054]
设真实的清晰语音信号短时傅里叶谱为s,建立损失函loss(),计算增强后的信号与清晰语音信号之间的误差:
[0055][0056]
随后系统根据损失函数和误差进行反向传播,优化模型的可训练参数,以到达减
小误差e的目的。
[0057]
1)模型参数设置
[0058]
在模型训练过程中,所有音频数据的采样率为16khz,短时傅里叶变换的窗长为25ms,帧与帧之间的覆盖率为50%,为实现批量运算以提高计算效率,本实施例固定每一段输入语音的时长为5s。在实际处理中,常常把短时傅里叶谱y的实部信息和虚部信息分为两个不同的通道,分别记为yr和yi,故实际输入的短时傅里叶谱为尺寸(n,k,2)的实数张量,也同时用n,k,c表示时域帧、频率点、特征通道维度。
[0059]
在编码器(encoder)部分,本实施例使用5个二维卷积层(conv2d),其特征通道数(filters)、卷积核尺寸(kernel-size)、步长(stride)分别为{32,32,32,64,128},{(2,5),(2,3),(2,3),(2,3),(2,3)},{(1,2),(1,2),(1,1),(1,1),(1,1)},每个conv2d后都紧接着归一化层(batch normalization)和prelu激活函数。encoder具体框架如图3。
[0060]
编码器将输入短时傅里叶谱的特征提取到了更多的通道,同时降低了特征的分辨率。随后编码器的输出作为dprnn的输入,假设此时的张量尺寸为(n
′
,k
′
,c
′
)。在intra-chunk部分,rnn使用1个双向长短期记忆网络(bidirectional long short-term memory,blstm)建立起每一帧频率点之间的联系,隐藏单元数(units)设为64,随后紧接1个单元数为128的全连接层(fc)和1个层归一化(layer normalization)层,输出的结果再与输入相加,得到intra-chunk的最终输出。为了在inter-chunk中建立时域帧之间的联系,需要用转置层(transpose)层对intra-chunk输出张量的维度进行变换(n,k,c)
→
(k,n,c)。在inter-chunk中,rnn使用1个长短期记忆网络(long short-term memory,lstm)建立起时域帧信息之间的联系,units为128,随后紧接1个单元数为128的全连接层和1个层归一化(layer normalization)层,输出的结果再与输入相加,得到inter-chunk的最终输出。以上便是一个dprnn块结构,具体框架如图4。在本实施例中使用两个串联的dprnn块。
[0061]
解码器(decoder)使用5个逆卷积层(convtranspose2d),其特征通道数、卷积核尺寸、步长分别为{64,32,32,32,2},{(2,3),(2,3),(2,3),(2,3),(2,5)},{(1,1),(1,1),(1,1),(1,2),(1,2)},每个convtranspose2d后都紧接着归一化层(batch normalization)和prelu激活函数。dprnn或逆卷积层的输出在输入下一层逆卷积层之前,都与对应encoder层的输入通过attention结构相连接,具体框架如图5。
[0062]
每个attention结构都由3个conv2d构成,具体框架如图6。其中conv2d_1和conv2d_2的特征通道数为输入张量通道数的2倍,卷积核尺寸都为(3,3),步长都为(1,1),它们的输出相加后经过sigmoid激活函数,conv2d_3特征通道数与b通道数相同,卷积核尺寸为(3,3),步长为(1,1),它的输出经过sigmoid激活函数后与b进行元素层面相乘,最终得到attention结构的输出,它与b在c维度相接(concatenate),作为下一个逆卷积层的输入。
[0063]
在经过decoder后得到m和y一样,也分为实部和虚部两个通道,分别记为mr和mi故(10)式可写为:
[0064]
real(s
ns
)=yrm
r-yimiꢀꢀꢀ
(13)
[0065]
imag(s
ns
)=yrmi+yimrꢀꢀꢀ
(14)得到的s
ns
经过1次迭代的wpe算法结构,得到增强信号
[0066]
2)损失函数
[0067]
同时从时域和短时傅里叶变换域考虑损失函数。首先在时域,设s和经逆傅里叶
变换得到的时域信号为s和定义负snr损失函数为:
[0068][0069]
|
·
|2表示向量的二阶范数。在短时傅里叶变换域,定义基于均方差(mse)的损失函数为:
[0070][0071]
其中
[0072]
s=sr+jsiꢀꢀꢀ
(17)
[0073][0074]
|
·
|
∞
表示矩阵的无穷范数。总损失函数为
[0075][0076]
这里的二阶范数和无穷范数本质上都是计算mse,这是利用了其凸函数特性,更利于反向传播中的求导运算,以收敛至损失函数的极小值点。训练使用adam优化器以0.001的学习率进行优化。
[0077]
3、数据集与评价指标
[0078]
使用dns3(deep noise suppression 3)语音数据作为模型训练的清晰语音,其中含有约60000个音频(总时长约500小时),而且本次dns3的数据包含了更多种类的语言,且含有情感丰富的语音类型,更贴近日常的交流情景。本实施例使用其中90%为训练集(training set),10%为检验集(validation set)。噪声数据集来自于audioset、demand,产生混响所需的房间冲激响应(room impulse response,rir)来自于openslr26,将清晰语音随机地与rir进行卷积并与噪声相加得到含噪混响信号,信噪比在[-5db,5db]范围内随机选取。
[0079]
为了评价模型的泛化能力,使用新的数据集对模型的增强效果进行测试。数据集选择dns3中的盲数据集(blind set),该数据集的语音采集环境更加复杂,增加了语音增强的难度。采用的主观指标为dnsmos。本实施例进行对比的传统方法为先利用基于mmse噪声功率谱估计的谱减法,紧接着采用wpe去混响算法,记为mmse+wpe。
[0080]
4、实验结果
[0081]
结合典型实例,如图7,可见基于规则的传统方法(mmse+wpe)在处理信噪比较低、噪声类型较为复杂的语音信号时取得的效果并不好,很难通过一套参数的设置适应多种语音环境。而本发明方法采用dpcarn-wpe模型则较为准确地识别出了语音中的噪声成分并进行抑制,混响得到了一定程度上的消除,实际听感也更为良好。
[0082]
两个模型对dns3的blind test set的测试结果如表1,其中数值越高代表语音质量越好。
[0083]
表1测试结果
[0084][0085]
为了更具体展示模型对不同噪声类型的处理效果,表中列出了哭泣声(cry)、音乐声(music)两类非稳态噪声,白噪声(white)、色彩噪声(color)两类稳态噪声的处理结果。可见传统的mmse+wpe方法对于含有稳态噪声的语音是有改善的,但对于含有非稳态噪声的语音,其处理效果并不理想,而本发明方法采用神经网络模型dpcarn-wpe对于各类噪声都能有显著的抑制效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1