一种基于视听觉融合的多人对话点餐方法及系统
1.本发明属于点餐技术领域,具体涉及一种基于视听觉融合的多人对话点餐方法及系统。
背景技术:
2.人工智能与人机交互技术快速发展,基于人机交互的智能机器人在提高工作效率、优化产业结构、保障社会生产力和改善人们生活质量等方面发挥着重要作用,在服务、教育、医疗和科研等领域得到广泛应用,有力地推动着高新技术产业的发展。语音作为一种高效的人机交互方式,使得人们可更加便捷地获取机器人提供的各种服务,并被应用于餐厅服务等多人语音场景。然而,当前这些场景的语音对话系统更多的是一种纯语音单模态的单人与机器人语音对话模式,当受到复杂环境中的多人说话的干扰时,它的性能难以满足人机对话需求。因此,在有噪声干扰的多人与机器人对话场景中,构建多人与机器人对话完成点餐任务的方法,使其能够在复杂场景中稳定分离说话人语音、跟踪并识别多人说话语音,是进行准确、高效、实时人机交互点餐的关键。
3.对话系统作为人机交互的一个重要的应用领域,是人和机器以对话的方式进行双向信息交互的系统。20世纪60年代,对话系统开始出现,此时多数对话系统基于人工模板的方式进行对话,对话自由度受限,如麻省理工学院weizenbaum等人针对心理治疗而开发的eliza系统。20世纪80和90年代,对话系统的实用价值增加,并开始步入商业化,如zue等人针对航空服务开发的飞机订票系统pegasus。到21世纪,计算机性能不断提升,对话系统的对话质量有了显著提升,如2008年德国慕尼黑工业大学设计的用于人机交互的口语对话系统mudis。近十年来,伴随着深度神经网络的进一步发展,各种基于深度学习的智能对话系统开始普及。众多科技公司相继推出自己的智能单人对话产品,如苹果公司用于娱乐和通话的语音助手siri、微软的聊天机器人小冰、谷歌的语音助手assistant和cortana、百度的语音助手小度、亚马逊的语音助手alexa等。然而,现阶段对话系统普遍应用于纯语音模态下单一用户的对话场景,不具备对多人混合语音进行稳定分离的能力,使得对话系统并不能分别针对多人对话语音中的每一个人进行对话。因此,在有噪声的多人对话场景中,如何使对话系统将对话时每个人的语音从混合语音中稳定分离出来,是提高对话系统多人对话能力的关键。
4.自20世纪中叶,人们的目光就开始探索在多人说话环境中进行语音分离。经过了几十年的发展,语音分离技术已经有了巨大的进步,语音分离从传统模型发展为深度模型,性能有了很大的提升,也应用到了人类生活起居的各个方面。但是现在大多数的语音分离模型仅适用于环境噪声较弱的对话场景。当说话人处在例如餐厅点餐等嘈杂且多人说话场景,分离模型分离多说话人语音的稳定性就会受到挑战,出现长时分离语音帧的标签排列的问题(长时间跨度语音分离时,分离的语音片段会错误的匹配到其他目标说话人)。这些问题都极大限制了对话机器人在餐厅点餐场景中的应用。
技术实现要素:
5.本发明的目的在于:为了解决上述方案存在的问题,提供一种基于视听融合的多人对话点餐方法,持续采集多人点餐的对话视频,提取对话视频中每个点餐人的嘴部图像,结合嘴部图像将对话视频中的混合语音分离开,在对分离开的语音片段进行点餐人身份匹配,对进行了身份匹配的每个语音片段进行点餐关键词识别,若语音片段中包括菜名关键词,则对提取到的关键词进行文本转换,得到文本信息;若不包括,则不做处理。将输出的文本信息与包括点餐开始关键词和点餐结束关键词的知识库进行对比,若同时存在点餐开始关键词和点餐结束关键词,则点餐结束,将点餐信息转换成语音输出,由点餐人再次确认,将确认后的点餐信息传输到后厨,完成点餐。
6.本发明目的通过下述技术方案来实现:一种基于视听觉融合的多人对话点餐方法,包括以下步骤:
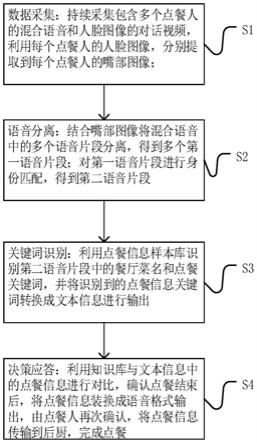
7.s1、数据采集:持续采集包含多个点餐人的混合语音和人脸图像的对话视频,利用每个点餐人的人脸图像,分别提取每个点餐人的嘴部图像;
8.s2、语音分离:结合多个点餐人的所述嘴部图像分离所述混合语音,得到多个第一语音片段;再识别出同一个点餐人对应的多个所述第一语音片段,并进行身份匹配,得到确认身份的第二语音片段;
9.s3、关键词识别:将所述第二语音片段进行特征提取后,输入到包括餐厅菜名和点餐关键词的声学模型和语音模型样本库的语音识别网络中进行关键词识别;若所述第二语音片段中包括菜名关键词,则将所述第二语音片段中提取到的点餐信息关键词转换为文本信息;若所述语音片段中未包括菜名关键词,则所述第二语音片段为点餐人的闲聊语音,不做处理;
10.s4、决策应答:利用知识库与所述文本信息中的点餐信息进行对比,对比确认结束点餐后,由点餐人再次确认,将确认后的点餐信息传输给后厨,将点餐信息转换为语音格式并输出,完成点餐;
11.重复步骤s1~s4,直到多个点餐人均完成点餐;
12.其中,所述知识库包括所述点餐关键词,所述点餐关键词包括点餐开始关键词和点餐结束关键词,当所述文本信息中同时包括所述点餐开始关键词和所述点餐结束关键词时,该点餐人结束点餐;否则,点餐未结束,继续接收该点餐人的点餐信息。
13.本发明的方法,持续采集多人点餐的对话视频,可以在长时间内持续接收多个点餐人的点餐信息,提高点餐服务的舒适性和便捷性。结合嘴部图像对对话视频中的混合语音进行分离,能够更准确的分离每个语音片段。利用先验特征集合对每段第一语音片段进行身份匹配,可实现长时间点餐的语音区分,将同一个点餐人不同时刻的语音片段分类到一起,实现长时间点餐识别。构建包括餐厅菜名和点餐关键词的点餐信息样本库,其中,点餐关键词包括点餐开始关键词和点餐结束关键词等与点餐有点的关键词,当第二语音片段中存在菜名关键词时,才对该第二语音片段进行处理;若第二语音片段中未包括菜名关键词,则默认该片段为点餐人的闲聊片段,与点餐无关,不对该片段进行处理,保证了点餐人的隐私同时提高了语音关键词识别的精度。
14.优选地,步骤s1包括:
15.s11、对所述对话视频进行下采样;
16.s12、下采样的所述对话视频经过事先训练好的人脸检测模型和脸部分类器,得到每个点餐人的脸部图像;
17.s13、根据每个点餐人的所述脸部图像,利用事先训练好的嘴部检测模型采集每个点餐人的嘴部图像。
18.优选地,步骤s2包括:
19.s21、分别利用语音解码器和图像解码器对所述混合语音和所述嘴部图像进行处理,得到混合语音特征和嘴部图像特征;
20.s22、将所述混合语音特征和所述嘴部图像特征输入事先训练好的融合网络中,进行视听特征序列融合,得到融合特征序列;
21.s23、将所述融合特征序列和所述混合语音输入事先训练好的分离网络中,将所述混合语音中的多个语音片段分离,得到所述第一语音片段;
22.s24、将所述第一语音片段与点餐人进行身份匹配,得到所述第二语音片段。
23.结合嘴部图像特征和混合语音特征,将视觉和听觉特征融合后再进行语音分离,能更加准确的分离混合语音中的各个语音片段。
24.优选地,步骤s24包括:
25.s241、提取所述第一语音片段的声学特征;
26.s242、计算所述第一语音片段的声学特征与先验特征集合中不同声学特征之间的相似度;
27.s243、通过判决逻辑判断所述第一语音片段的声学特征与所述先验特征集合中不同声学特征的最大相似度与阈值之间的关系,确定所述第一语音片段对应的点餐人是所述先验特征集合中已有点餐人还是新点餐人,得到所述第二语音片段;
28.其中,所述先验特征集合初始为空集合,随着新的点餐人的所述声学特征不断出现,先验特征集合会不断添加点餐人的所述声学特征。
29.提取第一语音片段的声学特征,利用已有点餐人的声学特征组成的先验特征集合对每个第一语音片段进行身份匹配;当出现新点餐人时,将其声学特征添加到先验特征集合中,今后后续的身份匹配。能够在长时间的点餐对话中,将准确地将属于同一点餐人的多个语音片段分类在一起,提升语音分离的可靠性和稳定性。
30.优选地,步骤s241中,通过mfcc特征提取参数方法,提取所述第一语音片段的声学特征;点餐人j的声学特征c
j
为:
[0031][0032]
其中,n表示倒谱系数的阶数,m代表三角滤波器组第m个滤波器通道,y(m)表示第m个三角带通滤波器的输出,m表示共有m个通道数。
[0033]
优选地,步骤s242中,利用标准化欧式距离来计算第i个所述第一语音片段的所述声学特征c
i
与所述先验特征集合中第j个声学特征c
j
的相似度:
[0034][0035]
其中,c
iu
表示第i个语音片段的第u维空间特征向量,c
ju
表示第j个点餐人的先验特征的第u维空间特征向量,表示第i个语音片段特征与第j个先验特征的方差。
[0036]
利用标准欧氏距离公式计算第i个第一语音片段的声学特征c
i
与第j个点餐人的声学特征c
j
特征之间的相似度,dist(c
i
,c
j
)的值越小,两者之间的相似度越大。
[0037]
优选地,步骤s243中,所述判断逻辑为:
[0038][0039][0040]
其中,s表示第i个所述第一语音片段特征与所述先验特征集合中的不同点餐人的先验特征c
j
计算得到的最小的标准化欧氏距离,其中j=1,2,3,...n,n为先验特征集合中声学特征的总数量;当s大于设定的阈值θ时,认为分离第i个语音片段属于一个新的说话人语音,将第i个所述第一语音片段的所述声学特征添加到所述先验特征集合中;当s小于等于设定的阈值θ时,第i个语音片段与身份为j的说话人匹配,确定第i个所述第一语音片段的点餐人身份。
[0041]
本发明还提供一种基于视听觉融合的多人对话点餐系统,包括:
[0042]
数据采集模块,所述数据采集模块用于持续采集包括多个点餐人的混合语音和人脸图像的对话视频,并对所述对话视频进行处理,得到每个点餐人的嘴部图像;
[0043]
语音分离模块,所述语音分离模块连接所述数据采集模块,用于根据所述嘴部图像和所述混合语音,将所述混合语音中的多个第一语音片段分离开;再将每个所述第一语音片段与其对应的点餐人进行匹配,得到确认了点餐人身份的第二语音片段;
[0044]
关键词识别模块,所述关键词识别模块连接所述点餐人匹配模块;所述关键词识别模块用于根据包括餐厅菜名和点餐关键词的点餐信息样本库进行关键词识别,识别所述第二语音片段中是否包括餐厅菜名关键词;若包括,则将所述第二语音片段中提取到的点餐关键词转换成文本信息;若不包括,则不输出文本信息;
[0045]
决策应答模块,所述决策应答模块连接所述关键词识别模块,用于将所述关键词识别模块输出的文本信息与包括点餐关键词的知识库进行对比,判断所述文本信息对应的点餐人是否点餐结束;若点餐结束,则将所述文本信息合成语音,向点餐人播放;否则,该点餐人点餐未结束,继续接收该点餐人的文本信息。
[0046]
优选地,所述决策应答模块还包括扬声器,用于将所述文本信息中的点餐信息转换成语音向点餐人播放。
[0047]
本发明还提供一种电子设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述方法。
[0048]
前述本发明主方案及其各进一步选择方案可以自由组合以形成多个方案,均为本发明可采用并要求保护的方案;且本发明,(各非冲突选择)选择之间以及和其他选择之间也可以自由组合。本领域技术人员在了解本发明方案后根据现有技术和公知常识可明了有多种组合,均为本发明所要保护的技术方案,在此不做穷举。
[0049]
本发明的有益效果:
[0050]
1、本发明的方法同时采集多个点餐人的语音和图像数据,结合图像数据对混合语音进行分离,提高了混合语音分离在餐厅点餐等嘈杂且多人说话场景的稳定性,改善传统
单一点餐服务,提高点餐服务的舒适性和便捷性。
[0051]
2、本发明将传统视听语音分离模块和点餐人匹配模块相结合,先结合嘴部图像特征将混合语音中的语音片段分离开,再利用先验特征集合,计算语音片段的声学特征与先验特征集合中各个声学特征的相似度,使得长时间的语音点餐时,同一个点餐人语音片段能够被准确地分类到一起,解决分离长时间说话人语音片段出现分类混乱的问题,提升语音分离的可靠性和稳定性。
[0052]
3、本发明利用包括餐厅菜名的语音识别模型来识别每个人的长时间点餐信息,只有在语音片段的点餐信息中包括菜名关键词时,才对语音片段进行处理。保护点餐人隐私的同时,提高了多人语音点餐功能的实时性和精确性。
附图说明
[0053]
图1是本发明的方法流程图。
[0054]
图2是本发明实施例的方法流程示意图。
[0055]
图3是本发明实施例的数据采集流程示意图。
[0056]
图4是本发明实施例的语音分离流程示意图。
[0057]
图5是本发明实施例的关键词识别流程示意图。
[0058]
图6是本发明实施例的决策应答流程示意图。
[0059]
图7是本发明实施例的电子设备结构示意图。
具体实施方式
[0060]
下列非限制性实施例用于说明本发明。
[0061]
实施例
[0062]
参照图1和图2,一种基于视听融合的多人对话点餐方法,具体包括以下步骤:
[0063]
s1、数据采集:持续采集包含多个点餐人的混合语音和人脸图像的对话视频,利用每个点餐人的人脸图像,分别提取到每个点餐人的嘴部图像;
[0064]
s11、对所述对话视频进行下采样;
[0065]
s12、下采样的所述对话视频经过事先训练好的人脸检测模型和脸部分类器,得到每个点餐人的脸部图像;
[0066]
s13、根据每个点餐人的所述脸部图像,利用事先训练好的嘴部检测模型采集每个点餐人的嘴部图像。
[0067]
参照图3,本实施例的点餐人有两名,持续采集两位点餐人的对话视频,首先将多人对话视频流下采样到25fps,再利用事先训练好的人脸检测模型,进行人脸检测,得到两个点餐人的脸部图像帧,再利用脸部分类器,将每个点餐人对应的脸部图像帧分类在一起,最后采用事先训练好的嘴部检测模型采集每个点餐人的嘴部图像帧,并提取嘴部图像特征。
[0068]
s2、语音分离:结合多个点餐人的所述嘴部图像分离所述混合语音,得到多个第一语音片段;再识别出同一个点餐人对应的多个所述第一语音片段,并进行身份匹配,得到确认身份的第二语音片段;
[0069]
s21、分别利用语音解码器和图像解码器对所述混合语音和所述嘴部图像进行处
理,得到混合语音特征和嘴部图像特征;
[0070]
s22、将所述混合语音特征和所述嘴部图像特征输入事先训练好的融合网络中,进行视听特征序列融合,得到融合特征序列;
[0071]
s23、将所述融合特征序列和所述混合语音输入事先训练好的分离网络中,将所述混合语音中的多个语音片段分离,得到所述第一语音片段;
[0072]
s24、将所述第一语音片段与点餐人进行身份匹配,得到所述第二语音片段。
[0073]
s241、提取所述第一语音片段的声学特征;
[0074]
s342、计算所述第一语音片段的声学特征与先验特征集合中不同声学特征之间的相似度;
[0075]
s423、通过判决逻辑判断所述第一语音片段的声学特征与所述先验特征集合中不同声学特征的最大相似度与阈值之间的关系,确定所述第一语音片段对应的点餐人是所述先验特征集合中已有点餐人还是新点餐人,得到所述第二语音片段;
[0076]
其中,所述先验特征集合初始为空集合,随着新的点餐人的所述声学特征不断出现,先验特征集合会不断添加点餐人的所述声学特征。
[0077]
参照图4,分别利用图像编码器和语音编码器对嘴部图像和混合语音进行特征提取,再利用融合网络将提取的嘴部图像特征和混合语音特征进行融合,融合后的特征输入到分离网络对混合语音进行分离,得到多个第一语音片段,即混合语音中不同点餐人的语音片段实现分离。
[0078]
将分离的第一语音片段与先验特征集合进行匹配,利用相似度大小和判决逻辑来确定每个第一语音片段对应的点餐人身份。其中先验特征集合初始为空集合,随着新的点餐人的声学特征不断出现,先验特征集合添加这些点餐人的声学特征。被添加的点餐人j的声学特征是通过mfcc特征提取参数方法得到,将其记为c
j
:
[0079][0080]
其中,n表示倒谱系数的阶数,m代表三角滤波器组第m个滤波器通道,y(m)表示第m个三角带通滤波器的输出,m表示共有m个通道数。
[0081]
第i个第一语音片段通过上述的mfcc方法提取声学特征,记为c
i
,为了将先验特征集合中的先验特征c
j
和第i个第一语音片段的声学特征进行匹配,需要计算特征向量c
j
与c
i
的相似度。本方法采用标准化欧式距离来计算它们的相似度:
[0082][0083]
其中,c
iu
表示第i个语音片段的第u维空间特征向量,c
ju
表示第j个先验特征的第u维空间特征向量,表示第i个语音片段特征与第j个先验特征的方差。
[0084]
第i个第一语音片段的特征分别与先验特征集合中的不同先验特征进行相似度计算得到最大的相似度(即最小标准化欧氏距离dist(c
i
,c
j
)),即可确定此第一语音片段的点餐人身份,其判定逻辑的公式如下所示:
[0085]
[0086][0087]
其中,s表示第i个所述第一语音片段特征与所述先验特征集合中的不同点餐人的先验特征c
j
计算得到的最小的标准化欧氏距离,其中j=1,2,3,...n,n为先验特征集合中声学特征的总数量;当s大于设定的阈值θ时,认为分离第i个语音片段属于一个新的说话人语音,将第i个所述第一语音片段的所述声学特征添加到所述先验特征集合中;当s小于等于设定的阈值θ时,第i个语音片段与身份为j的说话人匹配,确定第i个所述第一语音片段的点餐人身份。
[0088]
分别计算第i个第一语音片段的声学特征与先验特征集合中的不同先验特征间的欧氏距离,其中最小的标准化欧氏距离若小于等于阈值θ,则第i个第一语音片段与最小的标准化欧式距离对应的先验特征为同一点餐人语音片段;若最小的标准化欧氏距离若大于阈值θ,则第i个第一语音片段对应的点餐人为一个新的点餐人,先验特征集合中没有能够与之匹配的声学特征,将该新点餐人的声学特征添加到先验特征集合中。
[0089]
s3、关键词识别:将所述第二语音片段进行特征提取后,输入到包括餐厅菜名和点餐关键词的声学模型和语音模型样本库的语音识别网络中进行关键词识别;若所述第二语音片段中包括菜名关键词,则将所述第二语音片段中提取到的点餐信息关键词转换为文本信息;若所述语音片段中未包括菜名关键词,则所述第二语音片段为点餐人的闲聊语音,不做处理;
[0090]
参照图5,首先将将匹配了点餐人的所述第二语音片段进行特征提取,本实施例先对所述第二语音片段进行预加重、分帧;然后通过fft,即通过傅里叶变换得到对应的频谱,将频谱通过mel滤波器组得到mel频谱,经dct(离散余弦变换)获得语音特征向量。
[0091]
利用包括餐厅菜名和点餐关键词的声学模型和语音模型样本库的语音识别网络识别点餐语音关键词,识别到的关键词为样本库中包括的餐厅菜名和/或点餐关键词;若该第二语音片段识别到的关键词包括菜名关键词,则从该语音片段提取到的关键词会被转为文本格式输出文本信息。若不包括菜名关键词,则不输出文本信息。此语音识别网络的目标是利用声学与语言学信息,把输入的语音特征序列转化成词序列并以文本格式输出,由于使用专用样本库的语音识别网络,只有语音片段包含菜名关键词时才对将该语音片段转换成文本信息,在保护点餐人的隐私的同时提高语音关键词识别精度。
[0092]
即当第二语音片段中包括菜名关键词时,才对该语音片段进行处理;否则默认该语音片段为点餐人的闲聊语音,为了保护点餐人的隐私,不对该语音片段进行处理。
[0093]
s4、决策应答:利用知识库与所述文本信息中的点餐信息进行对比,对比确认结束点餐后,由点餐人再次确认,将确认后的点餐信息传输给后厨,将点餐信息转换为语音格式并输出,完成点餐;
[0094]
重复步骤s1~s4,直到多个点餐人均完成点餐;
[0095]
其中,所述知识库包括所述点餐关键词,所述点餐关键词包括点餐开始关键词和点餐结束关键词,当所述文本信息中同时包括所述点餐开始关键词和所述点餐结束关键词时,该点餐人结束点餐;否则,点餐未结束,继续接收该点餐人的点餐信息。
[0096]
参照图6,利用知识库对文本信息中的点餐信息进行确认,确认点餐结束后,再由点餐人进行确认,将确认后的点餐信息传输到后厨。同时将确认后的文本信息作为应答文
本,将应答文本合成语音并向点餐人输出,完成点餐。
[0097]
综上所述,本发明的方法,可以将多个点餐人长时间的混合语音分离开来,并能准确的将分离开的语音与对应的点餐人进行匹配,将同一个点餐人的每个语音片段都进行身份匹配,再对每个语音片段进行关键词识别,只有语音片段中包括餐厅菜名时,才对语音片段进行处理,保护了点餐人的隐私。可以实现在多人对话场景中,为多个点餐人进行点餐。
[0098]
本实施例还提供一种基于视听觉融合的多人对话点餐系统,包括:
[0099]
数据采集模块,所述数据采集模块用于持续采集包括多个点餐人的混合语音和人脸图像的对话视频,并对所述对话视频进行处理,得到每个点餐人的嘴部图像;
[0100]
本发明的数据采集模块可以持续采集多个点餐人的对话视频,同时采集多个点餐人的混合语音和人脸图像,并对采集到的人脸图像进行处理,得到每个点餐人的嘴部图像。
[0101]
语音分离模块,所述语音分离模块连接所述数据采集模块,用于根据所述嘴部图像和所述混合语音,将所述混合语音中的多个第一语音片段分离开;再将每个所述第一语音片段与其对应的点餐人进行匹配,得到确认了点餐人身份的第二语音片段;
[0102]
关键词识别模块,所述关键词识别模块连接所述点餐人匹配模块;所述关键词识别模块用于根据包括餐厅菜名和点餐关键词的点餐信息样本库进行关键词识别,识别所述第二语音片段中是否包括餐厅菜名关键词;若包括,则将所述第二语音片段中提取到的点餐关键词转换成文本信息;若不包括,则不输出文本信息;
[0103]
决策应答模块,所述决策应答模块连接所述关键词识别模块,用于将所述关键词识别模块输出的文本信息与包括点餐关键词的知识库进行对比,确认文本信息中是否同时包括点餐开始关键词和点餐结束关键词;若包括,则点餐结束;否则,点餐人点餐未结束,继续接收该点餐人的文本信息;确认点餐结束后,将确认的文本信息合成语音,向点餐人播放。
[0104]
本实施例所述的决策应答模块包括扬声器,用于将点餐信息转换成语音向点餐人播放。
[0105]
参照图7,为本发明提供的电子设备结构示意图,本实施例公开了一种电子设备,包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行前述实施例所述的方法。输入输出接口可以包括显示器、键盘、鼠标、以及usb接口,用于输入输出数据;电源用于为电子设备提供电能。
[0106]
本领域技术人员可以理解为:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:移动存储设备、只读存储器(read only memory,rom)、磁碟或者光盘等可以存储程序代码的介质。
[0107]
当本发明上述集成的单元以软件功能单元的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明实施例的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机、服务器、或者网络设备等)执行本发明各个实施例所述方法的全部或部分。而前述的存储介质包括:移动存储设备、rom、磁碟或者光盘等各种可以存储程序代码的介质。
[0108]
前述本发明基本例及其各进一步选择例可以自由组合以形成多个实施例,均为本发明可采用并要求保护的实施例。本发明方案中,各选择例,与其他任何基本例和选择例都可以进行任意组合。在此不做穷举,本领域技术人员可知有众多组合。
[0109]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1