一种基于声音强度的音频高潮检测算法、存储介质及装置的制作方法
1.本发明涉及音频处理技术领域,特别涉及一种基于声音强度的音频高潮检测算法、存储介质及装置。
背景技术:
2.用户进行音频剪辑时,往往伴随视频或者图片的混合制作,因此更倾向于获取音频高潮部分,用于表达某种特定场景。但是不同音频数据高潮的时间跨度和出现次数都不相同,导致用户需要花较长的时间,反复听辨才可以找到准确的音频高潮。因此音频高潮检测算法的目的就是通过计算声学特征来帮助用户挑选合适的音频高潮时间段。
3.目前在比较主流的音乐播放器都有音频高潮检测这一功能。这些音频高潮检测所采用的主流算法都是基于频谱和高频词的检测方法,对大量的歌词进行词频和较远距离重复段落的进行统计,与频谱上的高低频率交替点进行同一时刻的确认,从而确定音频高潮部分。
4.现有音频高潮检测算法虽然可以准确检验一部分音频的高潮段落,但仍存在诸多难点:1.一般认为音频高潮检测部分是副歌部分,目前主流高潮检测算法也对应了这一原则,但是在实际的检测中存在着音频高潮检测时间点不准确,并且给音频高潮时间段进行了固定截取长度的设置,导致往往算法只能提供一个很粗略的位置。2.对于没有歌词的音乐,往往效果较差,无法借助高频词进行频谱图的辅助,而单纯的基于频谱的音频高潮检测,容易检测因为乐器的快速打击而误认为的高潮点,导致音频高潮部分无法被准确识别。3.对于音频高潮检测没有参考乐理特性,导致现有算法无法给予音频高潮起始、高潮、回落的音乐过程,导致算法出现音频截取后歌词从中间首个位置开始唱或者唱到一半戛然而止的情况。
技术实现要素:
5.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种基于声音强度的音频高潮检测算法、存储介质及装置,旨在解决现有音频高潮检测不够准确的问题。
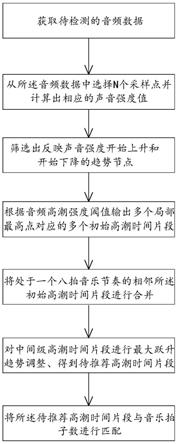
6.根据本发明第一方面实施例的一种基于声音强度的音频高潮检测算法,包括以下步骤:s100、获取待检测的音频数据;s200、从所述音频数据中选择n个采样点并计算出相应的声音强度值,所述n个采样点在所述音频数据的时间长度上均匀分布;s300、从所述n个采样点的时间及其声音强度值筛选出反映声音强度开始上升和开始下降的趋势节点;s400、从所述趋势节点中选择出多个局部最高点,根据设定的音频高潮强度阈值输出多个所述局部最高点所对应的多个初始高潮时间片段;s500、检测所有所述初始高潮时间片段,将处于一个八拍音乐节奏的相邻所述初始高潮时间片段进行合并,得到含有单个或合并多个初始高潮时间片段的中间级高潮时间片段;s600、对所述中间级高潮时间片段进行最大跃升趋势调整从而得到待推荐高潮时间片段;s700、将所述待推荐高潮时间片段与音乐拍子数进
行匹配,使待推荐高潮时间片段的起始点和终止点落在对应的节拍时间点上。
7.根据本发明第一方面实施例的一种基于声音强度的音频高潮检测算法,至少具有如下技术效果:本发明通过音频信号的声音强度变化特性,动态截取了音频高潮部分,使用拍子数和声学特性进行高潮部分的同一时刻确认,可有效的简化用户的操作步骤,达到一键完成准确的音频高潮检测功能,帮助用户进行音频的剪辑和音视频软件的智能辅助剪辑模式。
8.根据本发明第一方面的一些实施例,所述s200包括:s210、对所述音频数据时域信号的实际长度进行的补0或切片操作,使得所述音频数据可以被等分为n帧数据;s220、将所述音频数据的每一帧作为一个采样点,从而得到n个采样点;s230、对所述n个采样点的数据进行iir高低通滤波,再提取每一帧的声音强度值,直到提取完n个声音强度值。
9.根据本发明第一方面的一些实施例,所述s300还包括对所述趋势节点进行平滑处理:将第一、第二以及倒数第一、第二趋势节点的声音强度值以相邻三个声音强度值取平均得到,其余中间的趋势节点声音强度值以相邻两个声音强度值取平均得到。
10.根据本发明第一方面的一些实施例,所述s400包括以下步骤:s410、识别出局部最高点;s420、输出与所述局部最高点所对应的初始高潮时间片段。
11.根据本发明第一方面的一些实施例,所述s410包括:s411、将趋势节点按时间分为两个部分,计算前半部分趋势节点和后半部分趋势节点的平均声音强度,如果两者的平均声音强度差距小于半个声压级以内,则认为局部最高点只存在一个,反之则认为局部最高点在两个以上;s412、对于s411中声音强度较低的部分,继续按时间分为两部分,按s411的方式继续计算平均声音强度,即计算局部最高点的个数;s413、累加每一次判断的局部最高点个数。
12.根据本发明第一方面的一些实施例,所述s420包括:s421、设定音频高潮强度阈值;s422、计算音频数据的拍子数;s423、检测出与局部最高点的强度差在所述音频高潮强度阈值内的时间片段;s424、判断所述s423检测出的时间片段是否有一半以上满足8个节拍长度,若不满足则调整所述音频高潮强度阈值,返回所述s423直到满足一半以上的时间片段满足8个节拍长度并作为初始高潮时间片段。
13.根据本发明第一方面的一些实施例,所述s500中将处于一个八拍音乐节奏的相邻所述初始高潮时间片段进行合并包括:将两个相邻的初始高潮时间片段进行比较,如果第一个初始高潮时间片段的结束点和第二个初始高潮时间片段的起始点相隔的时间点小于一个八拍音节,即表示两段初始高潮时间片段实际上属于同一段,则保留第一个初始高潮时间片段的起始点和第二个初始高潮时间片段的终止点进行高潮段的合并。
14.根据本发明第一方面的一些实施例,所述s600中最大跃升趋势调整包括:将所述中间级高潮时间片段进行前后趋势时间点的平移,找到在一定时间范围内的前后趋势节点对应声音强度的差值最大的时间点,并且保证后点的声音强度大于前点,最前端的趋势节点作为待推荐高潮时间片段的起始点,待推荐高潮时间片段的结束点声音强度要小于前点。
15.根据本发明第二方面实施例的一种存储介质,所述存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如上述的一种基于声音强度的音频高潮检测算法。
16.根据本发明第三方面实施例的一种基于声音强度的音频高潮检测装置,至少一个控制处理器和用于与所述至少一个控制处理器通信连接的存储器;所述存储器存储有可被所述至少一个控制处理器执行的指令,所述指令被所述至少一个控制处理器执行,以使所述至少一个控制处理器能够执行如所述的一种基于声音强度的音频高潮检测算法。
17.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
18.本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
19.图1是本发明第一方面实施例的方法流程图;
20.图2是本发明第一方面实施例的步骤s200流程图;
21.图3是本发明第一方面实施例的采样点声音强度曲线图;
22.图4是本发明第一方面实施例的步骤s300流程图;
23.图5是本发明第一方面实施例平滑处理后的采样点声音强度曲线图;
24.图6是本发明第一方面实施例的步骤s400流程图;
25.图7是本发明第一方面实施例的步骤s410流程图;
26.图8是本发明第一方面实施例的步骤s420流程图;
27.图9是本发明第一方面实施例的初始高潮时间片段示意图;
28.图10是本发明第一方面实施例的步骤s500流程图。
具体实施方式
29.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
30.如图1所示,为本发明第一方面实施例的一种基于声音强度的音频高潮检测算法,包括以下步骤:
31.s100、获取待检测的音频数据,音频数据包括音频时域振幅和采样率;
32.s200、从所述音频数据中选择n个采样点并计算出相应的声音强度值,所述n个采样点在所述音频数据的时间长度上均匀分布;
33.s300、从所述n个采样点的时间及其声音强度值筛选出反映声音强度开始上升和开始下降的趋势节点;具体为:由于声音强度的向上向下趋势时间点代表着音频在这一趋势时间内处于同一种表达效果,如局部的高点和落点会有明显的上升和下降线(例如一组声音强度的大小为
‑
70.9794、
‑
65.7129、
‑
64.4217
‑
63.4322、
‑
73.7131、
‑
61.2458、
‑
60.3439、
‑
57.5192,对应的时间点0.5、1、1.5、2、2.5、3、3.5、4,则可以筛选出以下声音强度的值
‑
70.9794、
‑
63.4322、
‑
73.7131、
‑
57.5192),统计趋势时间点可以统计出高潮的起始点到高潮真正爆发的一瞬间的趋势节点,同样也可以得到高潮削减到高潮低谷的趋势节点;
34.s400、从所述趋势节点中选择出多个局部最高点,根据设定的音频高潮强度阈值输出多个所述局部最高点所对应的多个初始高潮时间片段;
35.s500、检测所有所述初始高潮时间片段,将处于一个八拍音乐节奏的相邻所述初始高潮时间片段进行合并,得到含有单个或合并多个初始高潮时间片段的中间级高潮时间片段;
36.s600、对所述中间级高潮时间片段进行最大跃升趋势调整从而得到待推荐高潮时间片段;
37.s700、将所述待推荐高潮时间片段与音乐拍子数进行匹配,使待推荐高潮时间片段的起始点和终止点落在对应的节拍时间点上。
38.本发明通过音频信号的声音强度变化特性,动态截取了音频高潮部分,使用拍子数和声学特性进行高潮部分的同一时刻确认,可有效的简化用户的操作步骤,达到一键完成准确的音频高潮检测功能,帮助用户进行音频的剪辑和音视频软件的智能辅助剪辑模式。
39.如图2所示,在本发明第一方面的一些实施例中,所述s200包括:
40.s210、对所述音频数据时域信号的实际长度进行的补0或切片操作,使得所述音频数据可以被等分为n帧数据;其中,本实施例以500ms为一帧数据;
41.s220、将所述音频数据的每一帧作为一个采样点,从而得到n个采样点;
42.s230、为了保证信号的频率可以被人耳所获取,对所述n个采样点的数据进行iir高低通滤波,再提取每一帧的声音强度值,直到提取完n个声音强度值,如图3所示。
43.具体的计算方法如下:
44.首先进行低通滤波
45.iir_out=b1(1)*iir_in+b1(2)*x_1+b1(3)*x_2)
‑
(a1(2)*y_1+a1(3)*y_2)
46.x_2=x_1
47.x_1=iir_in
48.y_2=y_1
49.y_1=iir_out
50.再进行高通滤波,其中,上述低通滤波的输出值作为高通滤波的输入值
51.iir_out=(b2(1)*iir_in+b2(2)*x_1+b2(3)*x_2)
‑
(a2(2)*y_1+a2(3)*y_2)
52.x_2=x_1
53.x_1=iir_in
54.y_2=y_1
55.y_1=iir_out
56.再计算声音强度:
57.pp=iir_out
58.lonud=20*log10(pp)
59.其中
60.a1=[1
ꢀ‑
1.989169673629796 0.989199035787039]
[0061]
b1=[1
ꢀ‑
2 1]
[0062]
a2=[1
ꢀ‑
1.663655113256020 0.712595428073225]
[0063]
b2=[1.530841230050348
ꢀ‑
2.650979995154730 1.169079079921587]
[0064]
a1,b1为iir低通滤波器参数,a2,b2为iir高通滤波器参数;
[0065]
x_1,x_2,y_1,y_2为滤波器数值迭代参数,初始值皆为0。
[0066]
以上公式仅表示计算一次声音强度的计算流程,由于本实施例采用500ms为一帧,采样率44100,那么一帧数据会有22050个点,每个点一个数据,那么上述irr滤波器循环就会有22050次,从而得到每一个点的数据。
[0067]
如图4、图5所示,因为高潮内部的趋势节点会存在小幅度的高低落差,为了平滑这一小幅度落差,在本发明第一方面的一些实施例中,所述s300还包括对所述趋势节点进行平滑处理:将第一、第二以及倒数第一、第二趋势节点的声音强度值以相邻三个声音强度值取平均得到,其余中间的趋势节点声音强度值以相邻两个声音强度值取平均得到。比如,对于第一个趋势节点的声音强度和第二个趋势节点的声音强度,分别使用第一二三个的声音强度和第二三四的声音强度进行计算;倒数第一个和倒数第二个趋势节点的声音强度分别使用倒数一二三的声音强度和倒数二三四的声音强度进行计算。
[0068]
如图9所示,可以发现,声音强度可以很好的反映音频短时的声音起落,即在一定时间段中的局部最高点往往是音频的高潮部分,在本发明第一方面的一些实施例中,如图6所示,所述s400包括以下步骤:
[0069]
s410、识别出局部最高点;
[0070]
s420、输出与所述局部最高点所对应的初始高潮时间片段。
[0071]
如图7、图9所示,在本发明第一方面的一些实施例中,所述s410包括:
[0072]
s411、将趋势节点按时间分为两个部分,计算前半部分趋势节点和后半部分趋势节点的平均声音强度,如果两者的平均声音强度差距小于半个声压级(0.5db)以内,则认为局部最高点只存在一个,反之则认为局部最高点在两个以上;
[0073]
s412、对于s411中声音强度较低的部分,继续按时间分为两部分,按s411的方式继续计算平均声音强度,即计算局部最高点的个数;
[0074]
s413、累加每一次判断的局部最高点个数。
[0075]
如图8、图9所示,在本发明第一方面的一些实施例中,所述s420包括:
[0076]
s421、设定音频高潮强度阈值;
[0077]
s422、计算音频数据的拍子数;
[0078]
s423、检测出与局部最高点的强度差在所述音频高潮强度阈值内的时间片段;具体实施时,为了满足乐理条件,忽略前后的静音段产生的干扰声音强度,选择局部最高点的强度值(max_lound)作为参考值,并且计算音频的拍子数(beats per minute,bpm),音频高潮强度阈值music_threshold_lound_diff=2.5,寻找所有声音强度符合max_lound
‑
music_threshold_lound_diff~max_lound的时间片段;
[0079]
s424、判断所述s423检测出的时间片段是否有一半以上满足8个节拍长度,若不满足则调整所述音频高潮强度阈值,比如,music_threshold_lound_diff+=0.5,返回所述s423直到满足一半以上的时间片段满足8个节拍长度并作为初始高潮时间片段。
[0080]
如图10所示,在本发明第一方面的一些实施例中,所述s500中将处于一个八拍音乐节奏的相邻所述初始高潮时间片段进行合并包括:将两个相邻的初始高潮时间片段进行比较,如果第一个初始高潮时间片段的结束点和第二个初始高潮时间片段的起始点相隔的时间点小于一个八拍音节(一般在预先限缩音乐的速度范围是70
‑
130bpm,一个八拍的长度大约是3.7
‑
6.85sec),即表示两段初始高潮时间片段实际上属于同一段,则保留第一个初
始高潮时间片段的起始点和第二个初始高潮时间片段的终止点进行高潮段的合并。
[0081]
由于选取的高潮片段的起始点发现往往不是高潮起始的准确点,通常的时间差在1~2s之内,因此在本发明第一方面的一些实施例中,所述s600中最大跃升趋势调整包括:将所述中间级高潮时间片段进行前后趋势时间点的平移,找到在一定时间范围内的前后趋势节点对应声音强度的差值最大的时间点,并且保证后点的声音强度大于前点,最前端的趋势节点作为待推荐高潮时间片段的起始点,待推荐高潮时间片段的结束点声音强度要小于前点。
[0082]
根据本发明第二方面实施例的一种存储介质,所述存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如上述的一种基于声音强度的音频高潮检测算法。
[0083]
根据本发明第三方面实施例的一种基于声音强度的音频高潮检测装置,至少一个控制处理器和用于与所述至少一个控制处理器通信连接的存储器;所述存储器存储有可被所述至少一个控制处理器执行的指令,所述指令被所述至少一个控制处理器执行,以使所述至少一个控制处理器能够执行如所述的一种基于声音强度的音频高潮检测算法。
[0084]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0085]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1