基于语音识别技术的119报警系统的制作方法
1.本技术涉及一种艾灸装置,更具体地说,是涉及一种基于语音识别技术的119报警系统。
背景技术:
2.近年来随着社会经济的不断发展,人民生活水平不断提高,引发火灾的因素明显增多,各种火灾事故频繁发生,危害着人民群众的生命财产安全。
3.然而,公众的消防安全素质不高,对火灾常识、火灾隐患没有清楚的认识,不能在发生火灾报警时,有效的提供消防员有用的报警信息。
技术实现要素:
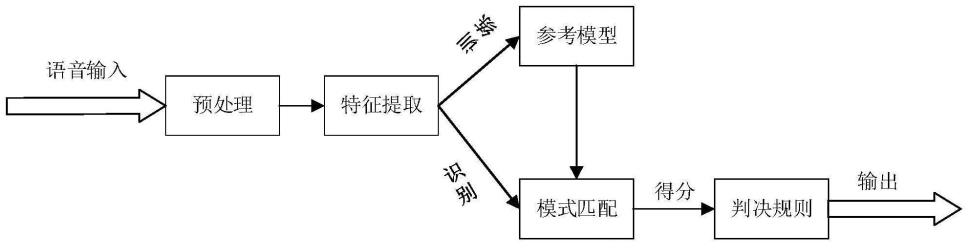
4.为解决上述问题,本技术采用的技术方案是:提供一种基于语音识别技术的119报警系统,包括语音识别系统,语音识别系统包括语音信号采集模块、特征提取模块、模型训练模块和模式匹配模块;
5.语音信号采集模块,用于采集语音信号并将信号传输给特征提取模块;
6.特征提取模块,用于接收语音信号采集模块的信息,并从语音信号采集模块提取出能够反映语言特征的参数。
7.模拟训练模块,用于在训练阶段用合适的模型来表征这些特征参数,使得模型能够代表该语言的语音特性。
8.模式匹配模块,在识别阶段,用训练阶段建立的语言模型对测试语音的特征参数进行某种形式的匹配,从而得出相似性得分,根据打分得到判决结果。
9.优选地,特征提取模块的功能设计有以下步骤:
10.(1)设置特征参数;
11.(2)提取mfcc特征参数;
12.(3)存储特征文件。
13.优选地,步骤(1)包括,
14.需要设置的参数主要有分帧个数m、特征维度n,即输出特征矩阵的大小[m,n]、滤波器的阶数、采样频率、dct变换系数、fft变化长度等参数。
[0015]
优选地,步骤(2)包括,
[0016]
a.对语音信号提取特征参数的具体步骤为:
[0017]
b.对一帧语音信号x(n)进行适当的预加重、分帧、加窗预处理;
[0018]
c.对其做傅里叶变换(fft),把语音信号变换到频域,得到信号幅度谱;
[0019]
d.将幅度谱通过mel滤波器组,三角滤波器输出mel频谱;
[0020]
e.对所有的滤波器输出系数做对数运算;
[0021]
f.再进一步做离散余弦变换(dct)得到频率倒谱系数mfcc,这个mfcc就是这帧语音的特征。
[0022]
优选地,步骤(3)包括,
[0023]
将提取的特征参数按34维的特征矢量序列保存在磁盘文件中,由于语音片段大小并不一样,所以得到的特征文件大小也是不同的。
[0024]
本发明的有益效果,通过设置语音信号采集模块、特征提取模块、模型训练模块和模式匹配模块,能更快更准确对使用者的报警情况进行模拟,从而锻炼使用者的应变能力,让使用者了解报警程序中所要提供的求助内容,熟悉报警问答流程,尽可能的为救援争取更多的时间。
附图说明
[0025]
为了更清楚地说明本技术实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0026]
图1为本发明的语音识别系统流程图。
[0027]
图中符号说明:
具体实施方式
[0028]
为了使本技术所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
[0029]
需要说明的是,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本技术的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
[0030]
现对本技术实施例提供的基于语音识别技术的119报警系统进行说明。
[0031]
请参阅图1,为本发明的语音识别系统流程图。所述基于语音识别技术的119报警系统,包括语音识别系统,所述语音识别系统包括语音信号采集模块、特征提取模块、模型训练模块和模式匹配模块;
[0032]
所述语音信号采集模块,用于采集语音信号并将信号传输给特征提取模块;
[0033]
所述特征提取模块,用于接收所述语音信号采集模块的信息,并从所述语音信号采集模块提取出能够反映语言特征的参数。
[0034]
所述模拟训练模块,用于在训练阶段用合适的模型来表征这些特征参数,使得模型能够代表该语言的语音特性。
[0035]
所述模式匹配模块,在识别阶段,用训练阶段建立的语言模型对测试语音的特征参数进行某种形式的匹配,从而得出相似性得分,根据打分得到判决结果。
[0036]
本系统选择卷积神经网络进行训练,卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。
[0037]
卷积神经网络是一种特殊的深层的神经网络模型,它的特殊性体现在两个方面,一方面它的神经元间的连接是非全连接的,另一方面同一层中某些神经元之间的连接的权重是共享的(即相同的)。它的非全连接和权值共享的网络结构使之更类似于生物神经网络,降低了网络模型的复杂度(对于很难学习的深层结构来说,这是非常重要的),减少了权值的数量。
[0038]
训练模块的功能是调节神经网络的参数,建立合适的神经网络,然后将处理过的语音特征参数作为神经网络数据的输入,根据神经网络的学习算法,分类对数据进行训练,最终分别得到语音模型。
[0039]
神经网络参数的设置是非常关键的,调参是训练神经网络重要部分,设置的训练参数主要包括设置输入数据的矩阵大小即神经网络的高度与宽度、数据分类的类别数、神经网络的通道数channels、随机数seed、批处理量bitchsize参数、训练迭代次数等。
[0040]
更进一步地,在本实施例中,所述特征提取模块的功能设计有以下几步:
[0041]
(1)设置特征参数
[0042]
需要设置的参数主要有分帧个数m、特征维度n,即输出特征矩阵的大小[m,n]、滤波器的阶数、采样频率、dct变换系数、fft变化长度等参数;
[0043]
(2)提取mfcc特征参数
[0044]
a.对语音信号提取特征参数的具体步骤为:
[0045]
b.对一帧语音信号x(n)进行适当的预加重、分帧、加窗预处理;
[0046]
c.对其做傅里叶变换(fft),把语音信号变换到频域,得到信号幅度谱;
[0047]
d.将幅度谱通过mel滤波器组,三角滤波器输出mel频谱;
[0048]
e.对所有的滤波器输出系数做对数运算;
[0049]
f.再进一步做离散余弦变换(dct)得到频率倒谱系数mfcc,这个mfcc就是这帧语音的特征。
[0050]
(3)存储特征文件
[0051]
将提取的特征参数按34维的特征矢量序列保存在磁盘文件中,由于语音片段大小并不一样,所以得到的特征文件大小也是不同的。
[0052]
本发明通过设置语音信号采集模块、特征提取模块、模型训练模块和模式匹配模块,能更快更准确对使用者的报警情况进行模拟,从而锻炼使用者的应变能力,让使用者了解报警程序中所要提供的求助内容,熟悉报警问答流程,尽可能的为救援争取更多的时间。
[0053]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围,均应包含在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1