基于attention的主旋律提取方法、系统及计算机存储介质
1.本发明涉及音频信号处理领域,具体涉及一种基于attention的主旋律提取方法、系统及计算机存储介质。
背景技术:
2.主旋律提取是音乐信号处理领域的重要研究任务,具体内容是给定一段音乐,计算机自动分析音乐内容,并提取出该段音乐的主旋律。主旋律提取在音乐结构分析、音乐检索、音乐风格分类、翻唱识别等领域具有广泛应用。
3.传统的主旋律提取方法主要分为三类:基于音高显著性的主旋律提取、基于源分离的主旋律提取以及基于机器学习的方法。而随着深度学习的发展以及其在语音信号处理领域已经取得的巨大成就,许多人使用深度学习去提取音乐主旋律并且已经获得了很好的效果。
技术实现要素:
4.为了克服上述现有技术中存在的缺陷,本发明的目的是提供一种基于attention的主旋律提取方法、系统及计算机存储介质。
5.为了实现本发明的上述目的,本发明提供了一种基于attention的主旋律提取方法,包括以下步骤:
6.将待提取主旋律的音频信号进行处理形成语谱图;
7.将所述语谱图进行多次tattention操作,至少对一次tattention的输出进行下采样,然后至少对一次tattention的输出进行上采样,上采样次数与下采样次数一致,每次tattention均以上一次tattention的输出或采样结果为输入,根据最后一个tattention的输出于所述语谱图中查找对应的频点及时间,提取到音频信号的主旋律;
8.所述tattention将输入信息的频域信息融合通过时域attention,然后对时域信息融合通过通道域attention后输出。
9.该主旋律提取方法通过两种attention结合提高了主旋律提取的准确率。
10.该主旋律提取方法的优选方案:通过时域attention时,将频域的信息融合得到f*t的时域attention,f为频率,t为时间,此时,f=1。
11.该主旋律提取方法的优选方案:通过通道域attention时,将时域融合得到c*t通道域的attention,t为时间,c为通道,此时,t=1。
12.该主旋律提取方法的优选方案:
13.所述tattention的步骤为:
14.对所述语谱图或输入信息x∈r
c*f*t
先进行二维卷积f1操作得到s1,然后对s1的f维取均值,记作u∈r
c*t
,c为通道,f为频率,t为时间,其中s
1ij
代表s1中第i行和第j列的元素;
15.对u作一维卷积,结果记作v∈r
c*t
,v=f(u),同时对s1做二维卷积f2得到s2;
16.以v作为attention map和s2相乘,结果记作z,z=s2*softmax(v);
17.对v的t维取平均值,结果记作d,对s2做二维卷积f3得到s3,然后对d进行的两个全连接层,得到d',d'=σ(w2φ(w1d));
18.将d'与s3相乘输出,得到通道域attention的结果,d'与s3相乘的公式为s3*softmax(d')。
19.该主旋律提取方法的优选方案:所述tattention将通道域attention的输出加上skip-connections的输出shortcut作为tattention的输出,即output=s3*softmax(d')+shortcut。
20.该主旋律提取方法的优选方案:对提取到音频信号的主旋律记为o∈r
f*t
,对o进行一维卷积将f降为1,得到的结果记作m∈r
t
,在将o和m结合得到最终的结果output'∈r
(f+1)*t
。
21.该优选方案通过在整个网络的最后添加一个专门用来检测无旋律部分的尾部,这样在结果上就不用区分有旋律部分和无旋律部分,全部统一处理即可。
22.该主旋律提取方法的优选方案:将待提取主旋律的音频信号进行处理形成语谱图时,通过combining spectral and temporal representations处理成包括the power-scaled spectrogram,generalized cepstrum和generalized cepstrum of spectrum三部分组成的三通道的矩阵。
23.本发明还提出了一种主旋律提取系统,包括处理器和存储器,所述处理器和存储器之间通信连接,所述存储器用于存放至少一条可执行指令,所述可执行指令使所述处理器执行如上述的主旋律提取方法对应的操作。
24.本发明还提出了一种计算机存储介质,所述计算机存储介质存储有至少一条可执行指令,所述可执行指令使处理器执行如上述的主旋律提取方法对应的操作。
25.本发明的有益效果是:本发明通过下采样和上采样使得整体结构呈u形结构,通过时域attention以及通道域attention来对主旋律进行提取,提取结果有效且准确率高。
26.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
27.本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
28.图1是主旋律提取方法的网络结构示意图;
29.图2是tattention的网络结构示意图。
具体实施方式
30.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
31.在本发明的描述中,除非另有规定和限定,需要说明的是,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,也可以通过中间媒介间接相连,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
32.注意力机制(attention mechanism)是机器学习中一种数据处理的方法。attention机制模仿人类观察事物的机制,着重注意某些重要的局部信息,然后将它们组合起来形成对观察事物的整体印象。
33.如图1所示,本发明提供了一种基于attention的主旋律提取方法的实施例。
34.该方法采用的整体的网络结构如图1所示,是一个u形结构,主体为tattention结构,有下采样和上采样。
35.该方法包括以下步骤:
36.将待提取主旋律的音频信号进行预处理形成语谱图。本实施例中,首先将待提取主旋律的音频信号处理形成c
×f×
t(即通道域、频域和时域)的语谱图,本实施例中,语谱图的c为3,在预处理形成语谱图时,可得到待提取主旋律的音频信号的频率数组。
37.可优选但不限于采用su l,yang y h.combining spectral and temporal representations for multipitch estimation of polyphonic music[j].ieee/acm transactions on audio speech&language processing,2015,23(10):1600-1612.所提出的方法将待提取主旋律的音频信号通过combining spectral and temporal representations(cfp)处理成包括the power-scaled spectrogram,generalized cepstrum(gc)和generalized cepstrum of spectrum(gcos)三部分组成的三通道的矩阵,即三个通道为the power-scaled spectrogram,generalized cepstrum和generalized cepstrum of spectrum。处理过程中,使用44100hz的采样频率,2048窗口尺寸以及256(标注间隔6ms时)/441(标注间隔为10ms时)的帧移来进行其中的短时傅里叶变换(stft)。
[0038]
然后将处理得到的语谱图进行多次tattention操作,至少对一次tattention的输出进行下采样,然后至少对一次tattention的输出进行上采样,上采样次数与下采样次数一致,每次tattention均以上一次tattention的输出或采样结果为输入,最后一个tattention的输出即为音频信号的主旋律。本实施例中,将语谱图进行6次tattention操作,分别对前两次tattention的输出进行下采样,分别对倒数第二、三次tattention的输出进行上采样,每次采样结果作为下一tattention的输入。
[0039]
具体介绍一下tattention:
[0040]
tattention结构如图2所示,从上到下第一个
×
号上面整个过程是时域attetnion,第一个
×
号和第二个
×
号之间是通道attetnion,即前半部分是一个时域的attention结构,后半部分是对通道域的attention结构,整个tattention结构还使用skip-connections来解决梯度消失等问题。
[0041]
tattention操作即是将输入信息的频域信息融合通过时域attention,然后对时域信息融合通过通道域attention后输出与skip-connections的输出shortcut相加作为tattention的输出,即output=s3*softmax(d')+shortcut。
[0042]
在通过时域attention时,将频域的信息融合得到的时域attention,f为频率,t为时间,此时,f=1。通过通道域attention时,将时域融合得到通道域的attention,t为时间,
c为通道,此时,t=1。
[0043]
本实施例中,设语谱图或输入信息为x∈r
c*f*t
,其中,c为通道,f为频率,t为时间。
[0044]
对语谱图x∈r
c*f*t
先进行二维卷积f1操作得到s1,然后对s1的f维取均值,记作u∈r
c*t
,其中s
1ij
代表s1中第i行和第j列的元素。
[0045]
接下来对u作一维卷积,结果记作v∈r
c*t
,v=f(u),同时对s1做二维卷积f2得到s2。
[0046]
然后以v作为attention map和s2相乘,结果记作z,z=s2*softmax(v)。
[0047]
下半部分首先对v的t维取平均值,结果记作d,对s2做二维卷积f3得到s3,然后对d进行的两个全连接层,得到d',d'=σ(w2φ(w1d)),w1代表两个全连接层中的全连接层一,w2代表两个全连接层中的全连接层二,σ代表全连接层一的激活函数,φ代表全连接层二的激活函数。
[0048]
最后将d'与s3相乘,再加上skip-connections的输出,记为output,output=s3*softmax(d')+shortcut,其中shortcut为skip-connections的输出,即attention的原始输入。
[0049]
本实施例的一种优选方案,在整个u形网络的最后添加一个专门用来检测无旋律部分的尾部结构即图1中u形网络最右边的(1,1,t)的conve1d,这样在结果上就不用区分有旋律部分和无旋律部分,全部统一处理即可。具体实现:将u形结构得到的结构设为o∈r
f*t
,即最后一个tattention的输出设为o∈r
f*t
,对o进行一维卷积将f降为1,得到的结果记作m∈r
t
,在将o和m结合得到最终的结果output'∈r
(f+1)*t
,将此作为最终提取的主旋律。
[0050]
o和m结合:o的维度是(f,t),m的维度是(1,t),结合得到输出output'维度是(f+1,t)。这个output'的意义是音乐主旋律的时间对应的频率组数,output'的值和频率数组的值有一一对应的关系,即结合之前数据预处理得到的频率数组,通过这个频率组数查找到频率数组中对应的频率组,该频率组所对应的频率即为主频律所在的频率,最终就得到了时间和对应的频率即主旋律。
[0051]
说明:
[0052]
1、预处理得到的(3,f,t)的数据,即语谱图,是用来输入网络的,同时也能得到音乐的时间数组和频率数组。这个频率数组就是最后用来查的数组。
[0053]
2、这个最后的m是用来判断某个时间段有没有主旋律存在的。因为对于某个时间t可能出现多种情况:没有主旋律、有主旋律;如果t时间存在主旋律则还需要判断主旋律的频率是多少。因此为了最后判断的时候简单,专门使用了这个特定m来代表某个时间没有主旋律。具体使用:最终的结果output维度是(f+1,t),假设其中的第一行是m,如果神经网络在某个时间t预测到的主旋律频率位于第一行,则直接认为t处无主旋律,如果预测在其他行,则认为t时间存在主旋律,再去频率数组中查找相应的主旋律的频率。这样做的好处是神经网络的结果处理简单,只需要判断t处的主旋律的频率是多少,不再需要判断t处是否存在主旋律。
[0054]
具体实验介绍
[0055]
实验的训练集是从medley db数据集中选择的66个音乐片段,验证集也是从中选择的15个音乐片段。测试集有三个并且从三个数据集中选取分别是adc2004,mirex-05以及
medley db,数量分别是adc2004中12个,mirex-05中9个,medley db中12个。
[0056]
所有选取的数据集都是做同样的处理将每个片段都裁成t=256frames长度,方便神经网络处理。代码实现使用pytorch,损失函数为bceloss,adam优化,并且学习率为0.001。
[0057]
用来评价结果的指标分别是overall accuracy(oa),raw pitch accuracy(rpa),raw chroma accuracy(rca),voicing recall(vr)以及voicing false alarm(vfa)。使用的python包为mir-eval,来得到上述的各个值的结果。
[0058]
消融实验
[0059]
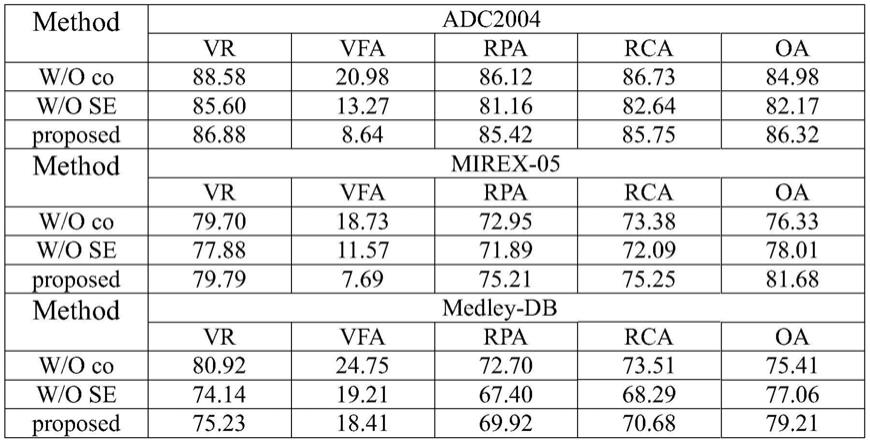
表1
[0060][0061]
表1:消融实验在adc2004和mirex-05两个测试集上对比结果,其中w/o co代表去除tattention中时域attention和通道attention后的结果,w/o se代表去除tattention后半部分的结果。
[0062]
消融实验的结果如表1所示,从整体上来看都是完整的网络效果要更好,对于去除attetnion后的结果,在adc2004以及medley-db测试集上vr会高一点,但总体上从oa以及vfa的角度上看结果稍差于完整的网络;其次是去除后半部分后的结果,总体上都要比完整的tattention结果要稍差。这也说明attention结构确实可以提高效果。
[0063]
实验结果对比
[0064]
本技术中提出的方法在测试集上的效果以及其他两种方法分别是segnet和ftanet在测试集上的效果如表2所示。三种方法都使用本文中的训练集在相同的条件下训练得到模型,再在相同的测试集上测试得到的结果。从表2中的数据比较可以看出确实有效并且结果是比较好的,对比其他网络在oa上本文提出的网络相较于其他网络都要高,在mirex-05和adc2004测试集上vr要稍低于segnet,但是vfa要优于它;对于medley-db测试集上vr要略低于ftanet但是同样vfa要优于ftanet。
[0065]
表2
[0066][0067][0068]
表2:本方法与其他方法在测试集adc2004、mirec-05以及medley-db测试集上的结果对比。
[0069]
本发明还提出了一种主旋律提取系统,其包括处理器和存储器,所述处理器和存储器之间通信连接,所述存储器用于存放至少一条可执行指令,所述可执行指令使所述处理器执行如上述的主旋律提取方法对应的操作。
[0070]
本发明还提出了一种计算机存储介质,该计算机存储介质存储有至少一条可执行指令,所述可执行指令使处理器执行如上述的主旋律提取方法对应的操作。
[0071]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0072]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1