一种适用于实际通信条件下的语音增强与检测方法
1.本发明涉及语音增强和语音端点检测处理领域,具体涉及一种适用于实际通信条件下的语音增强与检测方法。
背景技术:
2.语音增强的历史最早起源于上世纪初的贝尔实验室,研究人员为了改善电话的通信质量,在信号的增强方向进行了大量研究,随后的几十年中,更多研究者对语音增强技术进行了更深入的研究,根据增强模式的不同将语音增强大概分为两个阶段:无监督增强阶段和有监督增强阶段。
3.无监督增强阶段,通常也称为传统语音增强阶段,所谓无监督是指处理过程无需使用大数据预先进行有监督的离线训练。1979年boll提出谱减法(spectral subtraction,ss),通过假设语音与噪声相互独立,在频域减去噪声频谱实现增强。虽然谱减法的增强效果明显,但需以平稳噪声为条件,若噪声估计不准确,则会出现明显的失真或产生容易引起听觉疲劳的“音乐噪声”。同年lim等提出维纳滤波法(weiner filter,wf),以波形在统计意义上的最优线性估计为基本思想设计滤波器。维纳滤波法相比谱减法将“音乐噪声”转化为听者更容易接受的类似于白噪声的残留噪声,但其依然存在与谱减法相同的缺点,即仅对平稳噪声效果较好,在非平稳噪声条件下失真严重。1984年ephraim等提出短时幅度谱估计法,其基本思想是以最小均方误差(minimum mean square error,mmse)准则对信号的幅度谱进行非线性估计,次年ephraim等又提出短时对数幅度谱估计法,使用更符合人耳听觉特性的对数幅度谱替代短时幅度谱进行估计。虽然这两种方法在增强效果方面均相比维纳滤波法有一定提升,但始终未克服处理非平稳噪声效果不理想这个缺陷。1994年donoho等提出小波变换法(wavelet transform,wt)将小波变换的思想引入语音增强研究中,其增强原理是利用小波系数在不同尺度空间表现不同特征实现语音和噪声的分离。得益于小波变换的多分辨率特性,其在非平稳噪声条件下的增强效果有显著提升。
4.虽然无监督增强方法在广大研究人员的努力下已获得不错的增强效果,但这类方法通常需在语音和噪声信号之间进行某些不合理假设导致增强效果会受到影响,难以获得更优的增强效果。伴随着计算机技术的飞速发展,计算机硬件水平和计算能力都有了质的飞跃,基于深度学习的有监督增强方法逐渐成为语音增强研究的主流。所谓有监督增强是指通过建立关于语音信号自身特性和模型参数的优化函数,通过对优化函数进行有监督学习训练以实现增强的一类方法,这类方法打破了传统无监督语音增强方法始终依赖数字信号处理技术的局限,从全新的角度对语音增强进行研究。2014年徐勇提出一种基于深度神经网络(deep neural network,dnn)的语音增强方法,通过训练使网络模型学习语音与噪音之间的非线性关系,相比传统无监督增强方法,处理非平稳噪声信号效果更好,同时也具有更强的系统鲁棒性和噪声适应性。后续研究中也有研究者将无监督和有监督两类方法结合使用以达到更好的增强效果,2015年韩伟等提出一种将维纳滤波和深度神经网络相结合的语音增强方法,将维纳滤波器添加在神经网络的输出层用于生成增强语音幅度谱,这种
model,hmm)能够较好表示语音信号特征的特点,提出基于hmm的语音检测方法;2003年董恩清等人利用支持向量机(support vector machine,svm)对语音进行检测,虽然该方法检测效果不错,但计算量相对较大,且实时性欠佳。随着神经网络技术的逐渐成熟,不少研究者将神经网络技术运用到语音检测领域,1991年ghiselli-crippa等人首次提出基于人工神经网络(artificial neural network,ann)的语音检测方法,通过前馈神经网络区分语音段和噪声段。2016年tong等人针对基于深度学习的语音检测方法进行研究,通过对比分析深度神经网络(dnn)、长短期记忆网络(long short-term memory,lstm)以及卷积神经网络(convolutional neural networks,cnn)三种模型的语音检测性能,提出一种噪声感知训练(noise-aware training,nat)方法,有效改善低信噪比条件下语音检测的准确度。两类语音端点检测方法各有优缺点,其中基于统计模型的检测方法主要以深度学习和神经网络为基础,虽然准确度较高,但由于需要进行建模和大量的数据训练,通常该类方法计算量大且复杂,无法满足需要实时检测的实际需求。而基于语音特征参数的检测方法算法复杂度低、实时性高,能够满足实时性的检测需求,但在低信噪比条件下,现有的检测方法检测的准确率和稳定性有待提高。
技术实现要素:
9.本发明提供了一种适用于实际通信条件下的语音增强与检测方法,针对实际通信条件下部分语音信号质量差,可读懂度低,噪声冗余大等问题,使用语音增强与语音端点检测技术进行处理。
10.一种适用于实际通信条件下的语音增强与检测方法,包括如下步骤:
11.步骤1:将实际通信信号经过预处理后输入已完成训练的sedwgan-div模型中进行语音增强处理,输出增强的实际通信信号;
12.步骤2:将增强的实际通信信号使用参数自适应的多窗谱估计谱减法进行二次降噪后提取信号的自适应子带对数能熵积特征参数,并以该语音特征参数为阈值,使用动态阈值双门限检测法进行语音检测,输出语音端点信息;
13.步骤3:将步骤1获得的增强后的实际通信信号按照步骤2输出的语音端点信息进行筛选分段,保留携带语音信息的语音段,除去频道空闲状态下的无语音冗余段,最终输出增强后的实际通话语音段。
14.优选的是,本发明的步骤1包括如下具体过程:
15.步骤11:增强前预处理:所有语音数据使用前均进行相应的预处理,分别是对语音信号进行重采样、分帧和预加重;
16.步骤12:构建训练集:训练集用于sewdgan-div增强模型的训练,测试集用于验证sewdgan-div增强模型的实际增强效果,所述训练集分别来自valentini2016数据集、noisex-92数据集以及100 nonspeech sounds数据集;
17.步骤13:生成器模型构建:生成器结构采用u-net网络的全卷积网络,分为编码和解码两个部分,加入跳跃链接;
18.步骤24:判别器模型构建:判别器结构采用生成器的编码部分,除最后输出层为全连接层以外,其他各层均为卷积层或卷积池化层;
19.步骤15:构建基于wasserstein divergence的深度生成对抗网络模型:网络的总
体结构由n生成器和1个判别器组成,其中n个生成器分别以“串联”的方式进行连接,每个生成器输出的生成信号一方面作为输入信号输入下个生成器,另一方面输入判别器中进行判别;
20.步骤16:模型训练:基于wasserstein divergence的深度生成对抗网络模型的训练采用分批次训练,使用双时间尺度更新规则的训练方法,通过将判别器的学习率设置高于生成器的学习率,以达到判别器的判别能力领先生成器的生成能力的效果;
21.步骤17:使用训练好的模型进行语音增强处理:将带噪语音信号输入第一个生成器g1中,通过整个已训练完毕的深度生成对抗网络模型处理,最终由最后一个生成器gn输出增强语音信号。
22.优选的是,本发明的步骤11中重采样是指以16khz的采样率对所有语音信号进行重新采样;语音信号无论是训练阶段还是测试阶段均以语音帧为单位进行处理,将所有语音信号按照每帧长度为8192个采样点进行分帧,并将训练阶段的帧移设置为50%,而测试阶段帧移则设置为100%;由于语音信号的功率谱会随频率的增加而减小,能量大部分集中在低频部分,而能量在高频部分相对较小,为了提高语音信号高频部分的分辨率,在输入端加入预加重处理,并在输出端进行对输出语音数据进行相对应的去加重处理,预加重和去加重系数均为0.95。
23.优选的是,本发明的步骤13中编码部分由卷积层和卷积池化层构成,为了保留更多信号的细节信息,使用卷积池化层替代传统池化层;解码部分则是与编码部分相对应的反卷积和反卷积池化层;为增强模型鲁棒性,将感知向量c添加随机噪声z后输入解码部分,生成器各层卷积核个数分别为16,32,32,64,128,128,256,512,512,1024,512,512,256,128,128,64,32,32,16,1,激活函数除最后一层使用tanh函数外,其他各层均使用prelu函数。
24.优选的是,本发明的步骤14中使用层批量化(layer normalization,ln)替代bn,以加快网络模型收敛;判别器各层卷积核个数分别为16,32,32,64,128,128,256,512,512,1024,1,激活函数均使用leakyrelu函数。同时为防止训练出现过拟合,在输入端添加高斯白噪声,在输出端设置一个dropout层。
25.优选的是,本发明的步骤16中基于wasserstein divergence的深度生成对抗网络模型的训练采用分批次训练的方法,单个批次大小为50,总计训练200轮;使用双时间尺度更新规则的训练方法,通过将判别器的学习率设置高于生成器的学习率,以达到判别器的判别能力领先生成器的生成能力的效果。分别将生成器和判别器的学习率设置为0.0001和0.0005,生成器与判别器更新比设置为1,使用参数为β1=0,β2=0.9的adam优化器进行网络参数更新。
26.优选的是,本发明的步骤2包括如下具体过程:
27.步骤21:对增强语音信号进行检测前的预处理:包括分帧,归一化处理,并设置一个频率门限;
28.步骤22:2次降噪处理:使用自适应参数的多窗谱估计谱减法对增强语音信号进行2次降噪处理;
29.步骤23:计算语音特征参数:计算获得增强语音信号的子带能量,通过子带能量获得每帧信号的归一化最小带能量参数;根据改进后的有效子带个数与归一化最小带能量参
数的关系计算出对应信号帧的有效子带个数;根据每帧信号的有效子带个数,计算增强语音信号的自适应子带对数能量和自适应子带谱熵;计算获得待测增强语音信号的自适应子带对数能熵积,并将自适应子带对数能熵积进行中值平滑处理;
30.步骤24:双门限检测:以经过中值平滑处理后的自适应子带对数能熵积作为检测特征参数,设定动态阈值门限,使用单参数动态阈值的双门限检测方法进行语音检测;
31.步骤25:输出端输出:最后利用检测得到的语音端点信息划分增强语音信号,输出检测完成的各个语音片段。
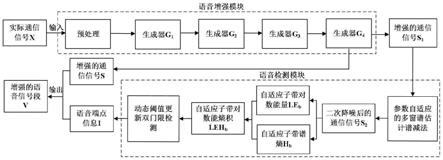
32.本发明提出一种能够适用于实际通信条件下的语音增强与检测方法。本方法由语音增强模块和语音检测模块构成,其中语音增强模块使用基于wasserstein divergence的深度生成对抗网络语音增强方法,语音检测模块使用基于谱减与自适应子带对数能熵积的语音检测方法。实际通信信号先后通过语音增强模块和语音检测模块处理,输出增强的通信语音段,相比原始的语音信号,系统处理后的信号质量更高,噪声干扰程度更小,冗余部分更少,同时也更有利于信号的后续处理。
附图说明
33.图1是本发明语音增强与检测系统的结构示意图。
34.图2是语音增强与检测系统的实际仿真效果。
具体实施方式
35.一种适用于实际通信条件下的语音增强与检测方法,包括如下步骤:
36.步骤1:增强前预处理:所有语音数据使用前均需要进行相应的预处理,分别是对语音信号进行重采样、分帧和预加重。其中重采样是指以16khz的采样率对所有语音信号进行重新采样。语音信号无论是训练阶段还是测试阶段均以语音帧为单位进行处理,因此将所有语音信号按照每帧长度为8192个采样点进行分帧,并将训练阶段的帧移设置为50%,而测试阶段帧移则设置为100%。由于语音信号的功率谱会随频率的增加而减小,能量大部分集中在低频部分,而能量在高频部分相对较小,为了提高语音信号高频部分的分辨率,在输入端加入预加重处理,并在输出端进行对输出语音数据进行相对应的去加重处理,预加重和去加重系数均为0.95。
37.步骤2:构建训练集:训练集用于sewdgan-div增强模型的训练,测试集用于验证sewdgan-div增强模型的实际增强效果。实验训练集分别来自valentini2016数据集、noisex-92数据集以及100 nonspeech sounds数据集。valentini2016数据集是爱丁堡大学语音技术研究中心的公开语料库,由valentini等人创建,采样频率为48khz,包含30位男女志愿者的声音,其中28位作为训练数据,共计11572条语音,noisex-92数据集是由英国荷兰感知研究所语音研究部门创建,采样频率为19.98khz,包含白噪声、粉红噪声、工厂噪声等15种噪声。100 nonspeech sounds数据集是由hu等人创建的非语言环境噪声集,采样频率为16khz,包含机器噪声、水声、风声等100种不同类型的环境噪声。
38.步骤3:生成器模型构建:生成器结构类似u-net网络的全卷积网络,分为编码和解码两个部分。为保留更多语音特征信息,提升模型增强效果,加入跳跃链接(skip connection)。编码部分由卷积层和卷积池化层构成,为了保留更多信号的细节信息,使用
卷积池化层替代传统池化层;解码部分则是与编码部分相对应的反卷积和反卷积池化层;为增强模型鲁棒性,将感知向量c添加随机噪声z后输入解码部分。生成器各层卷积核个数分别为16,32,32,64,128,128,256,512,512,1024,512,512,256,128,128,64,32,32,16,1,激活函数除最后一层使用tanh函数外,其他各层均使用prelu函数。
39.步骤4:判别器模型构建:判别器结构类似生成器的编码部分,除最后输出层为全连接层以外,其他各层均为卷积层或卷积池化层。使用层批量化(layer normalization,ln)替代bn,以加快网络模型收敛。判别器各层卷积核个数分别为16,32,32,64,128,128,256,512,512,1024,1,激活函数均使用leakyrelu函数。同时为防止训练出现过拟合,在输入端添加高斯白噪声,在输出端设置一个dropout层。
40.步骤5:构建基于wasserstein divergence的深度生成对抗网络模型:网络的总体结构由n生成器和1个判别器组成,其中n个生成器分别以“串联”的方式进行连接,每个生成器输出的生成信号一方面作为输入信号输入下个生成器,另一方面输入判别器中进行判别。为保证各个判别器之间的参数相互独立互不影响,不同于生成器之间以“串联”的方式进行数据流动,各生成器的生成信号是以“并联”的方式输入判别器,同时反馈信息同样以“并联”的方式返回各生成器中。
41.步骤6:模型训练:基于wasserstein divergence的深度生成对抗网络模型的训练采用分批次训练的方法,单个批次大小为50,总计训练200轮。使用双时间尺度更新规则(two time-scale update rule,ttur)的训练方法,通过将判别器的学习率设置高于生成器的学习率,以达到判别器的判别能力领先生成器的生成能力的效果。分别将生成器和判别器的学习率设置为0.0001和0.0005,生成器与判别器更新比设置为1,使用参数为β1=0,β2=0.9的adam优化器进行网络参数更新。
42.步骤7:使用训练好的模型进行语音增强处理:只需要将带噪语音信号输入第一个生成器g1中,通过整个已训练完毕的深度生成对抗网络模型处理,最终由最后一个生成器gn输出增强语音信号。
43.步骤8:对增强语音信号进行检测前的预处理:其中包括分帧,归一化等处理。同时设置一个频率门限,仅保留频率在100hz~3500hz范围内的部分。
44.步骤9:2次降噪处理:使用自适应参数的多窗谱估计谱减法对增强语音信号进行2次降噪处理。
45.步骤10:计算语音特征参数:计算获得增强语音信号的子带能量eb。通过子带能量eb计算获得每帧信号的归一化最小带能量参数nminbe。根据改进后的有效子带个数与归一化最小带能量参数的关系计算出对应信号帧的有效子带个数nub。根据每帧信号的有效子带个数nub,计算增强语音信号的自适应子带对数能量leb和自适应子带谱熵hb。计算得到的自适应子带对数能量leb和自适应子带谱熵hb,计算获得待测增强语音信号的自适应子带对数能熵积lehb,并将自适应子带对数能熵积lehb进行中值平滑处理。
46.步骤11:双门限检测:以经过中值平滑处理后的自适应子带对数能熵积lehb作为检测特征参数,设定动态阈值门限,使用单参数动态阈值的双门限检测方法进行语音检测。
47.步骤12:输出端输出:最后利用检测得到的语音端点信息划分增强语音信号,输出检测完成的各个语音片段。
48.本发明的语音增强与检测系统由语音增强模块和语音检测模块组成,两个模块的
主要工作步骤如图2所示。其中语音增强模块以基于wasserstein divergence的深度生成对抗网络的语音增强方法为基础,使用提前训练好的sedwgan-div模型对实际通信信号进行语音增强处理,降低噪声带来的影响,提升语音信号质量和可懂度,改善侦听效果。语音检测模块以基于谱减与自适应子带对数能熵积的语音检测方法为基础,对增强后的通信信号进行二次降噪后提取自适应子带对数能熵积特征参数,利用动态阈值更新双门限法进行语音检测,输出语音端点信息。
49.图2为语音增强与检测系统在实际应用仿真各模块的输出结果图,实际通话段的通联间隔均存在着噪声强度由弱到强噪声干扰并伴随着通话段出现脉冲噪声干扰。通过增强模块输出的时域波形图和语谱图可以看到增强模块增强处理后基本将噪声干扰消除。通过语音检测模块输出的语音端点信息可以发现使用语音检测模块对增强模块的输出信号进行检测准确率较高,能够准确的检测到语音信息。整个语音增强与检测系统最终输出的增强语音段的时域波形图中仅保留了语音信息部分,去除噪声干扰的部分。
[0050][0051]
表1 nisqa模型对不同类型信号的平均评价分数
[0052]
表1中为nisqa模型对不同类型信号的平均评价分数,与实际通信信号的平均评价分数相比,语音增强与检测系统的增强处理后增强信号的4个方面的评价分数均有较大的提升,其中语音质量评分和噪度评分分别提升0.839分和1.922分。相比于实际通信信号的整体质量接近-5db实验室噪声干扰条件下的信号质量,增强模型输出语音信号的整体质量已经优于0db实验室噪声干扰条件下的信号质量。
[0053][0054]
表2 针对不同类型语音库的平均加权错误测度
[0055]
表2为语音检测模块对4种不同类型的语音库检测的平均加权错误测度,相比于使用语音检测模块直接对实际侦察通信信号进行检测的平均加权错误测度为18.7%,按照本发明提出的语音增强与检测系统流程对增强模块输出语音进行检测的平均加权错误测度
降低为10.3%,准确率提高了8.4%。
[0056]
语音增强与检测系统的基本思想是利用语音增强和语音检测技术对实际通信信号进行处理,提升语音通信信号的质量,降低噪声的影响,自动筛选出通信信号中的实际包含语音的片段,去除多余的冗余部分。语音增强与检测系统的主要工作流程可以大致分为以下3个步骤:
[0057]
步骤1:将实际通信信号经过预处理后输入已完成训练的sedwgan-div模型中进行语音增强处理,输出增强的实际通信信号。
[0058]
步骤2:将增强的实际通信信号使用参数自适应的多窗谱估计谱减法进行二次降噪后提取信号的自适应子带对数能熵积特征参数,并以该语音特征参数为阈值,使用动态阈值双门限检测法进行语音检测,输出语音端点信息。
[0059]
步骤3:将步骤1获得的增强后的实际通信信号按照步骤2输出的语音端点信息进行筛选分段,保留携带语音信息的语音段,除去频道空闲状态下的无语音冗余段,最终输出增强后的实际通话语音段。特别说明,将步骤1输出的增强信号结合步骤2的语音端点信息作为最终输出而非直接使用语音检测模块输出最终语音的原因是由于使用参数自适应的多窗谱估计谱减法进行2次降噪时可能导致语音质量降低,因此语音检测模块仅输出语音端点信息。
[0060]
1、基于wasserstein divergence的深度生成对抗网络的语音增强方法的工作过程分为两个阶段:训练阶段和增强阶段。
[0061]
训练阶段将带噪语音信号输入生成器g1中输出生成语音信号1,而后将生成语音信号1作为输入信号输入到生成器g2中,同时将生成语音信号1连同原始带噪语音信号一起输入判别器中,以此类推,最后一个生成器gn输出最终的生成语音信号n,并也连同原始带噪语音信号一起输入判别器中。判别器d分别对各个生成器的生成语音信号进行判别,并将反馈信息分别返回各自生成器中,各个生成器根据反馈信息向生成纯净语音信号的方向独立调整网络参数。经过反复迭代训练,最终判别器d无法准确分辨最后一个生成器gn输出的生成语音信号n和纯净语音信号,即整个深度生成对抗网络获得具有增强能力。
[0062]
增强阶段则只需要将带噪语音信号输入第一个生成器g1中,通过整个已训练完毕的深度生成对抗网络模型处理,最终由最后一个生成器gn输出增强语音信号。
[0063]
综上所述,sewdgan-div判别器和生成器的损失函数可以表示为:
[0064][0065][0066]
式中,gn(
·
)表示第n个生成器,n为生成器总个数,x
n-1
为g
n-1
的输出,当n=1时,第1个生成器g1输入为原始带噪语音信号z,pz和pr分别表示带噪语音信号分布和纯净语音信号分布,p
rz
为真假数据之间随机插值所得到的分布,e[]表示求均值,表示对生成器gn(
·
)的判别梯度。由于判别器d需要处理不平衡的数据,即相对于每个真实数据,会生成n个生成数据,因此在每个生成器部分除以n,以抵消数据不平衡带来的惩罚。同时在生成器损失函数中加入纯净语音信号与各生成语音信号差值的l1范数作为正则项,防止训练过拟合,提升生成器性能,λ为正则项影响因子,系数k和p为常数。为了保证整个深度生成对
抗网络的连续学习性,使整个网络各个生成器的效果逐渐上升,需控制前面的生成器的效果不需要达到最好,后续生成器对前面进行改进,以达到连续学习的效果,因此设置正则项权重系数ωn=2
n-n
,深度生成对抗网络中位置越靠前的生成器权重越小,正则项对其影响越小。
[0067]
训练集的构造均采用将纯净语音按照设定信噪比叠加噪声生成带噪语音的方法。其中训练集的纯净语音使用valentini2016数据集的训练数据集语音,包含不同性别的28位说话人共计11572条语音。训练噪声使用100 nonspeech sounds数据集的100种非语言环境噪声,同时为了提高sewdgan-div模型在实际通信侦察环境下的工作能力,截取实际通信通信信号中的10种背景噪声,连同100种非语言环境噪声,组成110种噪声集。为了模拟各种噪声的不同信噪比条件,按照5种不同信噪比(-10db、-5db、0db、5db、10db)叠加噪声,构建一个550种不同噪声条件的训练集。
[0068]
sewdgan-div模型的训练采用分批次训练的方法,单个批次大小为50,总计训练200轮。生成对抗网络常规的训练方法使用单时间尺度更新规则,即生成器与判别器的学习率相同,但实际训练中需要判别器的判别能力领先生成器的生成能力,因此每训练1次生成器,判别器通常需要训练2次以上,而在传统wgan的训练中判别器和生成器的更新比通常设置为5,导致整个网络训练会耗费大量的时间。针对上述问题,使用一种双时间尺度更新规则(two time-scale update rule,ttur)的训练方法,通过将判别器的学习率设置高于生成器的学习率,以达到判别器的判别能力领先生成器的生成能力的效果。通过实验证明使用ttur方法能够大幅减少网络训练时间,并且训练效果也优于常规单时间尺度更新的训练方法。本发明借鉴ttur方法的思想,分别将生成器和判别器的学习率设置为0.0001和0.0005,生成器与判别器更新比设置为1,使用参数为β1=0,β2=0.9的adam优化器进行网络参数更新。
[0069]
其他的参数具体设置如下:除了判别器的输出层使用的宽度为1,步长为1的卷积核以外,其他所有卷积核宽度均为13,步长为2。生成器总共20层,各层卷积核个数分别为16,32,32,64,128,128,256,512,512,1024,512,512,256,128,128,64,32,32,16,1,激活函数除最后一层使用tanh函数外,其他各层均使用prelu函数,生成器编码部分和解码部分中间添加的随机噪声z的均值为0方差为1。判别器总共11层,各层卷积核个数分别为16,32,32,64,128,128,256,512,512,1024,1,激活函数均使用斜率为0.3的leakyrelu函数,判别器输入端添加的高斯白噪声方差为0.5,输出端的dropout层的保留率设置为0.5。通过实验证明wasserstein divergence的两个系数分别设置为k=2,p=6时效果最好,正则项影响因子为λ=100。网络其余参数均使用方差为0.02,均值为0的截断正态分布进行初始化。
[0070]
2、基于谱减与自适应子带对数能熵积的语音端点检测方法步骤如下:
[0071]
首先假设噪声为加性噪声,对于第i帧带噪信号yi(m)首先求出其平均幅度谱
[0072][0073]
其中,平均幅度谱表示以第i帧信号为中心前后各取j帧,这里前后帧数设置
为m即总共2m+1帧进行平滑求平均。
[0074]
然后对信号yi(m)进行多窗谱估计,求得其多窗谱功率谱为:
[0075]
p(k,i)=pmtm[yi(m)]
[0076]
式中,pmtm多窗谱估计函数,i和k分别表示第i帧信号和第k条谱线。
[0077]
使用计算信号平均幅度谱的方法求得信号yi(m)的平均多窗谱功率谱为:
[0078][0079]
通过平均多窗谱功率谱可以计算得到多窗谱估计的谱减增益值g(k,i)为:
[0080][0081][0082][0083]
式中,n表示帧长,yi(k)为第i帧信号的幅度谱,而为前nis帧无话语音段的幅度谱的均值。表示噪声的平均多窗谱功率谱,即通过选取前nis帧信号求其平均获得。α和β分别为过减因子以及增益补偿因子。
[0084]
最后通过多窗谱估计的谱减增益值g(k,i)计算谱减后的幅度谱并结合原始信号相位谱θi(k)重构得到增强信号
[0085][0086]
设将长度为n的第i帧的信号划分为nb个子带,每个子带长度为n,计算出第i帧信号的第m个子带的子带能量为eb(i,m):
[0087][0088]
根据求得的子带能量为eb(i,m),求出第i帧信号的归一化最小带能量参数nminbe
(i):
[0089][0090]
计算得出第i帧信号的有效子带个数nub(i):
[0091][0092]
第i帧信号第m个子带的自适应子带归一化谱概率密度可以定义为第m个子带的功率谱与第i帧所有有效子带功率谱之和的比值,即为:
[0093][0094]
根据计算得到的子带能量为eb(i,m)和自适应子带归一化谱概率密度pb(i,m),计算得到自适应子带对数能量和自适应子带谱熵:
[0095][0096][0097]
式中,snr
cor
(i)表示第i帧信号的实时修正信噪比,通过公式求得,segsnr
cor
表示信号的修正分段信噪比,具体定义为:
[0098][0099]
计算得到待测增强语音信号的自适应子带对数能熵积lehb:
[0100][0101]
设置单参数的动态阈值双门限,首先将两个初始阈值门限t1,t2分别定义为:
[0102][0103]
式中,max(lehb)表示待测语音信号自适应子带对数能熵积的最大值,lehb(nis)为前nis帧噪声段的平均自适子带对数能熵积,δ为前nis帧信号自适应子带对数能熵积的标准差,p为常数,a和b分别为上下限系数,决定检测门限的高低,而p为标准差的权重因子,决
定标准差对于阈值门限的影响程度。
[0104]
根据每帧信号的实时修正信噪比的大小,自适应的调整上下限系数a和b的取值,使其能够随着信噪比的变化而调整门限高低,本发明通过多次实验测试后将具体的上下限系数a和b的取值定义如下:
[0105][0106]
其他参数设置如下:
[0107]
仿真实验所有语音数据再使用前均需要进行相应的预处理,分别是对语音信号进行重采样、分帧、预加重以及频率筛选,其中重采样和预加重系数为0.95,使用hamming窗对语音信号进行分帧处理,帧长设置为200ms,帧移为80ms,前导噪声段帧数nis设置为18帧(10ms)。
[0108]
计算子带能量eb时的初始子带个数nb设置为25,即将每帧信号预划分成25个子带,每个子带的长度n为8。中值平滑处理的滑动窗口长度设置为5,即每次选取5帧数据进行中值平滑处理。最小有话段门限设置为5帧,最长静音长度门限设置为10帧。)改进的自适应子带归一化谱概率密度定义式中的常数k设置为0.5,初始阈值门限的标准差权重因子p设置为3,动态阈值门限的动态更新系数c设置为0.9。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1