电子设备、方法和计算机程序与流程
1.本公开总体上涉及音频处理领域,尤其涉及用于音频回放的设备、方法和计算机程序。
背景技术:
2.有许多音频内容是可用的,例如,以光盘(cd)、磁带、可以从因特网下载的音频数据文件的形式,但是也可以以例如存储在数字视频盘等上的视频的音轨的形式。
3.当音乐播放器正在播放现有音乐数据库中的歌曲时,听众可能想要跟着唱。自然地,听众的声音会添加到录音中出现的原始艺术家的声音中,并且可能干扰该声音。这可能会妨碍或扭曲听众自己对歌曲的理解。在某些情况下,经验不足或不知道歌词的听众可能仍然想跟着唱,并且可以从某种引导中受益,以支持和改进他自己的演奏。
4.尽管通常存在用于音频回放的技术,但是通常期望改进用于回放音频内容的方法和装置。
技术实现要素:
5.根据第一方面,本公开提供了一种电子设备,该电子设备包括电路,该电路被配置为对音频输入信号执行音频源分离,以获得人声信号和伴奏信号,并基于该人声信号对用户的语音信号执行置信度分析,以向用户提供引导。
6.根据第二方面,本公开提供了一种方法,包括:对音频输入信号执行音频源分离,以获得人声信号和伴奏信号;以及基于该人声信号对基于分离源的用户的语音信号执行置信度分析,以向用户提供引导。
7.根据第三方面,本公开提供了一种包括指令的计算机程序,当在处理器上执行时,该指令使处理器对音频输入信号执行音频源分离,以获得人声信号和伴奏信号,并基于该人声信号对用户的语音信号执行置信度分析,以向用户提供引导。
8.在从属权利要求、以下描述和附图中阐述了进一步的方面。
附图说明
9.参考附图通过示例的方式解释实施例,其中:
10.图1示意性地示出了基于音频源分离和置信度分析的音频信号的音频调整过程;
11.图2示意性地示出了通过盲源分离(bss)(例如,音乐源分离(mss))进行音频上混合/再混合的一般方法;
12.图3示意性地更详细地描述了在如图1所述的音频信号调整过程中执行的置信度分析器的过程的实施例;
13.图4更详细地示出了在如图3所述的置信度分析器的过程中执行的置信度估计器的过程的实施例;
14.图5a更详细地示出了在如图3所述的置信度分析器的过程中执行的音高分析过程
的实施例;
15.图5b更详细地示出了在如图4所述的置信度估计器的过程中执行的人声音高比较器的过程的实施例;
16.图6更详细地示出了在如图3所述的置信度分析器的过程中执行的节奏分析过程的实施例;
17.图7示意性地示出了在如图1所述的音频信号调整过程中执行的声学回声消除过程;
18.图8示出了基于在如图3所述的置信度分析器的过程中执行的置信度值而可视化示出置信度到增益的映射过程的流程图;
19.图9示意性地示出了基于置信度分析的基于对象的音频信号的音频调整过程;
20.图10示意性地示出了如图1所述的音频信号的音频调整过程的实施例;
21.图11示意性地更详细地描述了在如图1所述的音频信号调整过程中执行的置信度分析器的过程的另一实施例;
22.图12示出了可视化用于基于置信度分析器过程和基于分离源的信号混合方法的流程图;以及
23.图13示意性地描述了可以实现基于置信度分析和音乐源分离的音频混合过程的电子设备的实施例。
具体实施方式
24.在参考图1至图13详细描述实施例之前,先进行一些总体说明。
25.通常,音频内容已经从原始音频源信号混合,例如,用于单声道或立体声设置,而不保留来自已经用于制作音频内容的原始音频源的原始音频源信号。
26.然而,存在期望音频内容的再混合或上混合的情况或应用。例如,在将在具有比该音频内容所提供的更多可用音频信道的设备上播放音频内容的情况下,例如,将在立体声设备上播放的单声道音频内容、将在具有六个音频信道的环绕声设备上播放的立体声音频内容等。在其他情况下,应当修正音频源的感知空间位置,或者应当修正音频源的感知水平。
27.盲源分离(bss)又称盲信号分离,是从一组混合信号中分离出一组源信号。盲源分离(bss)的一个应用是将音乐分离成单独的乐器音轨,使得原始内容的上混合或再混合成为可能。
28.在下文中,术语再混合、上混合和下混合可以指基于源自混合的输入音频内容的分离的音频源信号生成输出音频内容的整个过程,而术语“混合”可以指分离的音频源信号的混合。因此,分离的音频源信号的“混合”会导致输入音频内容的混合音频源的“再混合”、“上混合”或“下混合”。
29.实施例公开了一种包括电路的电子设备,该电路被配置为对音频输入信号执行音频源分离,以获得人声信号和伴奏信号,并基于人声信号对用户的语音信号执行置信度分析,以向用户提供引导。
30.电子设备例如可以是任何音乐或电影再现设备,例如,智能手机、耳机、电视机、蓝光播放器等。
31.电子设备的电路可以包括处理器,例如,可以是cpu、存储器(ram、rom等)、存储器和/或存储设备、接口等。电路可以包括输入设备(鼠标、键盘、相机等)、输出设备(显示器(例如,液晶、(有机)发光二极管等))、扬声器等、众所周知用于电子设备(计算机、智能手机等)的(无线)接口等或者可以与其连接。此外,电路可以包括用于感测静止图像或视频图像数据、用于感测环境参数(例如,雷达、湿度、光线、温度)等的传感器(图像传感器、相机传感器、视频传感器等)或者可以与其连接。
32.在音频源分离中,包括多个源(例如,乐器、声音等)的输入信号被分解成分离(separation)。音频源分离可以是无监督的(称为“盲源分离”bss)或部分监督的。“盲”意味着盲源分离不一定具有关于原始源的信息。例如,可能不一定知道原始信号包含多少个源,或者输入信号的哪些声音信息属于哪个原始源。盲源分离的目的是在事先不知道原始信号分离的情况下分解原始信号分离。盲源分离单元可以使用技术人员已知的任何盲源分离技术。在(盲)源分离中,可以搜索在概率或信息论意义上或基于非负矩阵分解最小相关或最大独立的源信号,可以找到对音频源信号的结构约束。执行(盲)源分离的方法是技术人员已知的,并且基于例如主分量分析、奇异值分解、(独立)相关分量分析、非负矩阵分解、人工神经网络等。
33.尽管一些实施例使用盲源分离来生成分离的音频源信号,但是本公开不限于不使用更多信息来分离音频源信号的实施例,而是在一些实施例中,使用更多信息来生成分离的音频源信号。这种进一步的信息可以是例如关于混合过程的信息、关于包括在输入音频内容中的音频源的类型的信息、关于包括在输入音频内容中的音频源的空间位置的信息等。
34.输入信号可以是任何类型的音频信号。可以是模拟信号、数字信号的形式,可以源自光盘、数字视频盘等,可以是数据文件(例如,波形文件、mp3文件等)并且本公开不限于特定格式的输入音频内容。输入音频内容例如可以是具有第一信道输入音频信号和第二信道输入音频信号的立体声音频信号,而本公开不限于具有两个音频信道的输入音频内容。在其他实施例中,输入音频内容可以包括任意数量的信道,例如,5.1音频信号的再混合等。
35.输入信号可以包括一个或多个源信号。具体地,输入信号可以包括几个音频源。音频源可以是产生声波的任何实体,例如,乐器、语音、人声、人工生成的声音(例如,源自合成器)等。
36.输入音频内容可以表示或包括混合的音频源,这意味着声音信息不能单独用于输入音频内容的所有音频源,但是不同音频源的声音信息例如至少部分重叠或混合。此外,输入音频内容可以是未混合的基于对象的音频,具有包含混合指令的元数据。
37.该电路可以被配置为基于至少一个滤波后的分离源和基于通过盲源分离获得的其他分离源来执行再混合或上混合,以获得再混合或上混合的信号。再混合或上混合可以被配置为执行分离源(此处是“人声”和“伴奏”)的再混合或上混合,以产生再混合或上混合的信号,该信号可以被发送到扬声器系统。再混合或上混合还可以被配置为执行一个或多个分离源的歌词替换,以产生再混合或上混合的信号,该信号可以被发送到扬声器系统的一个或多个输出信道。
38.伴奏可以是将人声信号与音频输入信号分离而产生的残余信号。例如,音频输入信号可以是包括人声、吉他、键盘和鼓的一段音乐,伴奏信号可以是包括吉他、键盘和鼓的
信号,作为将人声与音频输入信号分离之后的残余。
39.例如,置信度分析可以是用户的置信度的实时(在线)估计。可以基于一些因素来计算置信度,例如,与原始人声的相似性、音高质量、定时或节奏感觉、专业性(即颤音、音域等)、唱的歌词或者只是哼唱之类的。置信度分析可以例如包括实时分析和比较用户的语音信号和原始人声信号,以计算置信度分析结果。原始人声信号是在执行音频源分离之后从音频输入信号获得的人声信号。
40.对用户的引导可以是例如通过减少原始录音的人声、完全去除原始录音的人声、保持原始录音的人声不变等来调整上混合/再混合中原始录音的人声的水平。人声减少的量(在从“无减少”到“完全去除”的连续范围内)可以基于用户的置信度进行自适应调整。用户的置信度越高,播放者就越能有效地给他们人声舞台。对用户的引导也可以是音频引导、视觉引导等。
41.该电子设备例如可以处理多种场景,并且可以是在线反应式和实时自适应设备。
42.电子设备的电路可以例如被配置为从人声信号中获得调整后的人声信号,并且执行调整后的人声信号与伴奏信号的混合,以获得调整后的音频信号,用于向用户提供引导。该混合可以是调整后的人声信号与伴奏信号的反应式实时混合,以获得用于向用户提供引导的调整后的音频信号。
43.电子设备的电路可以例如被配置为回放调整后的音频信号,以向用户提供引导。音频信号可以在线调整,并且可以实时回放。例如,作为专业歌手的用户可能缺少音频输入的歌词,或者可能具有弱的音高感知,可以用降低的原始人声和关于如何校正音高等的视觉引导的混合来引导和支持。此外,可以提供对演奏的反馈,即音高质量、时机和专业性(通过颤音、音域等反映出来),作为给用户的引导。此外,在歌曲的一小部分期间,可能需要引导,因此系统的快速和单独优化的反应性可能是必要的。
44.电子设备的电路可以例如被配置为基于置信度分析对人声信号执行增益控制,以获得调整后的人声信号。
45.实时置信度结果可以例如用于控制增益阶段,该增益阶段确定在每个时刻可以向用户呈现多少原始录音的人声。增益可以控制原始人声对混合的分布,即,原始人声可以静音,原始人声在混合中可以不变,诸如此类。增益控制可以不是二进制系统,即,根据置信度分析的在线结果,原始人声可以降低,而不完全去除。原始人声的水平可以完全由置信度分析结果控制,即置信度值。低置信度可能导致未被改变的回放,而高置信度可能导致完全去除原始人声。例如,当音调误差和/或节奏误差较小时,置信度值可以被选择为高,反之亦然。或者,当音调误差和/或节奏误差较小时,置信度值可以被选择为较小。
46.电子设备的电路可以例如被配置为基于置信度分析生成引导控制信号,并基于引导控制信号执行视觉或音频引导,以向用户提供引导。对用户的引导可以是显示在显示单元上的视觉引导。视觉引导可以是显示存储在容易获得的数据库中的歌词,或者离线执行歌词提取,显示语调校正信息,即“唱得更尖(sharp)”、“唱得更平(flat)”或使用标尺,显示音调校正指示符(箭头等),显示节奏校正指示符(闪烁等),显示演奏的反馈,即音调质量、定时和专业性(通过颤音、音域等反映),诸如此类。
47.此外,对用户的引导可以是输出到扬声器系统的音频引导。音频引导可以是通过语音反馈的下一行的预先呈现(类似于剧院中的suffleur模式)。在声学引导中,歌词可以
用口头语音合成,并且可以提前输出给用户等。
48.音频引导和视觉引导可以是活动的,直到用户的置信度值增加,例如,当用户的歌唱演奏提高时,或者直到用户停止歌唱,此时系统恢复正常回放。
49.电子设备的电路可以例如被配置为对人声信号执行音高分析,以获得人声音高分析结果,对用户的语音执行音高分析,以获得用户的音高分析结果,以及基于人声音高分析结果和用户的音高分析结果执行人声音高比较,以获得音高误差。
50.音高分析可以基于频谱中的基频和谐波频率。人声音高比较可以包括用户的声音音高与原始人声音高的比较。可以基于时间、频率或时间-频率分析来实现音高分析。
51.电子设备的电路可以例如被配置为对人声信号执行节奏分析,以获得人声节奏分析结果,对用户的声音执行节奏分析,以获得用户的节奏分析结果,以及基于人声节奏分析结果和用户的节奏分析结果执行人声节奏比较,以获得节奏误差。可以基于时间、频率或时间-频率分析来实现节奏分析,并且可以包括能量起始点检测。
52.电子设备的电路可以例如被配置为基于音高分析结果和节奏分析结果来执行置信度估计,以获得置信度值。
53.置信度值可以是实时估计的置信度分析结果,并且可以用于控制增益阶段,该增益阶段确定在每个时刻可以向用户呈现多少原始录音的人声。置信度值可以表示用户的演奏与原始艺术家的演奏的相似性,然而,也可以用不同的权重来配置。
54.电子设备的电路可以例如被配置为基于置信度值执行置信度到增益的映射,以获得增益控制信号。
55.电子设备的电路可以例如被配置为基于置信度值执行引导逻辑,以获得引导控制信号。引导逻辑可以控制音频引导和视觉引导。如果置信度值与音高和节奏分析结果的任一组合为高,或者另外配置引导逻辑,则引导逻辑也可以决定不提供任何引导。引导逻辑可以控制视觉引导的显示或声学引导的输出。
56.电子设备的电路可以例如被配置为对用户的语音信号执行语音活动检测,以获得触发置信度分析的触发信号。
57.语音活动检测器(vad)可以通过麦克风监测用户周围的音频环境。语音活动检测器可充当全局处理打开/关闭开关,例如,基于如果用户开始唱得足够大声(即,高于内部参考阈值),则语音活动检测器可将触发器发送到置信度分析器,以供进一步处理,并且基于如果用户停止唱歌或将其语音降低到语音活动检测器阈值以下,则语音活动检测器可将另一触发器发送到置信度分析器,以调整增益,来采取普通回放。
58.另外,例如,当语音活动检测器识别出用户的演奏时,即当语音活动检测器输出触发信号时,可在显示单元上显示播放器的图形用户界面(gui)中的麦克风或类似可识别符号等。
59.根据一个实施例,置信度分析器可以进一步被配置为基于置信度值向用户提供引导。置信度分析器也可以被配置为基于音高误差、节奏误差和置信度值来提供引导。
60.根据一个实施例,置信度到增益的映射可以被配置为以使得如果用户以完美的音高唱歌,则用户不会接收到引导的方式设置增益控制信号。
61.根据一个实施例,音频输入信号包括单声道和/或立体声音频输入信号,或者音频输入信号包括基于对象的音频输入信号。音频输入信号可以是多信道音频输入信号。基于
对象的音频输入信号可以是三维(3d)音频格式信号。
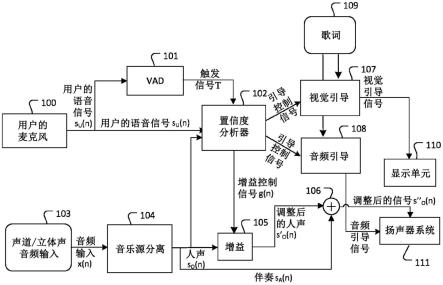
62.电子设备的电路可以例如被配置为对用户的语音执行回声消除,以获得无回声的用户语音。
63.电子设备的电路可以例如被配置为对人声信号执行专业分析,以获得人声专业分析结果,对用户的语音执行专业分析,以获得用户的专业分析结果。专业分析可以是对颤音的分析,即能量调制频谱、音域等。
64.根据一个实施例,电路包括被配置为捕捉用户的人声信号的麦克风。例如,当语音活动检测器识别出用户的演奏时,可以在显示单元上显示播放器的图形用户界面(gui)中的麦克风或类似可识别符号等。
65.实施例还公开了一种方法,包括对音频输入信号执行音频源分离,以获得人声信号和伴奏信号,并且基于人声信号对用户的语音执行置信度分析,以向用户提供引导。
66.实施例还公开了一种包括指令的计算机程序,当在处理器上执行指令时,该指令使处理器执行本文公开的过程。
67.现在参考附图描述实施例。
68.基于音频源分离和置信度分析的单声道/立体声音频信号调整
69.图1示意性地示出了基于音频源分离和置信度分析的音频信号的音频调整过程。
70.包含多个源(参见图2中的1,2,
…
,k)的音频输入信号x(n)(例如,单声道或立体声音频输入103信号x(n),例如,一段音乐)被输入到音乐源分离过程104,并被分解成分离(参见图2中的分离源2和残余信号3),在此处分解成分离源2(即“人声”so(n))和残余信号3,即“伴奏”sa(n)。下面在图2中描述了音乐源分离过程104的示例性实施例。将人声so(n)传输到置信度分析器102和增益105。用户的麦克风100获取用户的语音s(n),并将用户的语音信号sv(n)传输到语音活动检测器(vad)101和置信度分析器102。语音活动检测器101对用户的语音信号su(n)进行语音活动检测,以获得触发信号。触发信号基于检测到的用户语音信号su(n)触发置信度分析器102的过程。基于从音频输入信号x(n)获得的人声so(n),对用户的语音信号su(n)执行置信度分析102的过程,以获得增益控制信号g(n)和引导控制信号311。在下面的图3中描述置信度分析器102的示例性实施例。基于增益控制信号g(n),将增益105应用于人声so(n),以获得调整后的人声s
′o(n)。混合器106将由增益105获得的调整后的人声s
′o(n)与由音乐源分离104获得的伴奏sa(n)混合,以获得调整后的音频信号s
″o(n)。置信度分析器102基于引导控制信号311控制视觉引导107和音频引导108,以分别获得视觉引导信号和音频引导信号。基于从置信度分析器102获得的引导控制信号311并且基于从容易获得的数据库获得的一段音乐的歌词109(此处是单声道或立体声音频输入103信号x(n))来执行视觉引导107和音频引导108。或者,如果歌曲的元数据没有导致匹配,则首先离线执行歌词109提取。基于视觉引导信号,在显示单元110上显示视觉引导。基于音频引导信号,由扬声器系统111输出声学引导。视觉引导107可以是歌词、音调校正指示、节奏定向等。音频引导108可以是“suffleur系统”,其中,该系统在歌词在这段音乐中的时间位置之前说出歌词(像在剧院中一样)。在这种情况下,歌词109以口头语音合成,并提前以音频方式传递给用户。
71.在增益105处,将增益控制信号g(n)(增益)应用于人声信号so(n),以获得调整后的人声信号s
′o(n),其中,s
′o(n)=g(n)
×
so(n)。
augmentation and network blending”2017 ieee international conference on acoustics,speech and signal processing(icassp),ieee,2017中更详细描述的。
79.由于音频源信号的分离可能是不完美的,例如,由于音频源的混合,除了分离的音频源信号2a至2d之外,还生成残余信号3(r(n))。残余信号可以例如表示输入音频内容和所有分离的音频源信号之和之间的差异。由每个音频源发出的音频信号在输入音频内容1中由其相应记录的声波来表示。对于具有多于一个音频信道的输入音频内容,例如,立体声或环绕声输入音频内容,音频源的空间信息通常也由输入音频内容包括或表示,例如,由不同音频信道中包括的音频源信号的比例表示。基于盲源分离或能够分离音频源的其他技术来执行将输入音频内容1分离成分离的音频源信号2a至2d和残余3。
80.在第二步骤中,分离2a至2d和可能的残余3再混合并呈现为新的扬声器信号4,此处是包括五个信道4a至4e的信号,即5.0信道系统。基于分离的音频源信号和残余信号,通过考虑空间信息混合分离的音频源信号和残余信号,来生成输出音频内容。输出音频内容在图2中用附图标记4示例性地示出和表示。
81.在第二步骤中,分离和可能的残余再混合并呈现为新的扬声器信号4,此处是包括五个信道4a至4e的信号,即5.0信道系统。基于分离的音频源信号和残余信号,通过基于空间信息混合分离的音频源信号和残余信号来生成输出音频内容。输出音频内容在图2中用附图标记4示例性地示出和表示。
82.基于源分离的置信度分析过程
83.图3示意性地更详细地描述了在如上图1所述的音频信号调整过程中执行的置信度分析器的过程的实施例。对用户的语音301进行音高分析303,以获得用户的音高分析结果ω
fu
(n),并对用户的语音301进行节奏分析304,以获得用户的节奏分析结果对原始人声302进行节奏分析305,以获得原始人声节奏分析结果并对原始人声302进行音高分析306,以获得原始人声音高分析结果ω
fo
(n)。对用户语音301和人声302的音高分析结果ω
fo
(n)、ω
fu
(n)和节奏分析结果执行置信度估计器307的过程,以获得置信度值e
tot
(n)407。由语音活动检测器101(参见图1)获得的触发信号t 300触发将基于置信度值e
tot
(n)执行置信度到增益映射(308),以获得增益控制信号(407)。置信度到增益的映射308将置信度值e
tot
(n)407映射到增益值。即,基于置信度估计器307的结果,例如,置信度值e
tot
(n)407,置信度分析器102确定置信度到增益的映射308上的增益g(n)。基于置信度值e
tot
(n)407并基于音高误差e
p
(n)和节奏误差er(n)(参见图4)执行引导逻辑309的过程,以获得引导控制信号311。引导逻辑309基于其设置控制引导特征,例如,视觉引导107(参见图1)和音频引导108(参见图1)。引导逻辑309基于置信度值e
tot
(n)407、音调误差e
p
(n)和节奏误差er(n)使用视觉引导107和音频引导108向用户提供引导。例如,如果音高误差e
p
(n)高,则向用户提供视觉引导,例如,在显示单元110上显示关于显示语调校正信息的消息,例如,“唱得更尖”、“唱得更平”或使用标尺等。此外,可以在显示单元110上显示关于用户演奏的音高质量、定时和专业性的用户演奏反馈,这可以通过颤音、音域等来反映。
84.如在图3的实施例中所描述的,引导逻辑309基于置信度值e
tot
(n)407、音高误差e
p
(n)和节奏误差er(n),在不将本实施例限制于此的情况下使用视觉引导107和音频引导108向用户提供引导。
85.或者,引导逻辑309可以基于用户的设置向用户提供必要的引导,例如,用户可能需要关于歌词的引导、或者音高引导、或者节奏引导、或者上述的任何组合。例如,可能选择改变旋律的有经验的歌手可以从置信度分析器102中移除关于音高分析、节奏分析等的设置,从而不会被错误地识别为糟糕的演奏。此外,没有经验的歌手可以使用视觉引导107和音频引导108,或者通过激活希望的引导来训练他们歌唱的不同方面。
86.又或者,如果置信度值e
tot
(n)407与音高和节奏数据(例如,音高误差e
p
(n)和节奏误差er(n))的任一组合足够高,或者另外配置引导逻辑309,则引导逻辑309也可以决定不提供任何引导。
87.触发置信度分析器用于进一步处理的触发信号t 300被实现为标志(flag),即用作全局处理打开/关闭开关的二进制开/关信号。在触发信号t 300打开的情况下,触发信号t触发引导逻辑309来控制在用户的图形用户界面(gui)中显示麦克风或类似的可识别符号,例如,显示单元110(参见图1)。在触发信号t 300关闭的情况下,触发信号t触发置信度到增益的映射308以设置g(n)=1。换言之,没有检测到用户的语音,并且原始人声so(n)在调整后的音频信号s
″o(n)中保持不变,即采取普通回放。
88.在图3的实施例中,提供了与用户的反应式交互,因为引导逻辑309基于在其分析阶段计算的特征子集,控制系统的引导特征,例如,视觉引导107和音频引导108。因此,引导逻辑309分别控制视觉或音频引导特征的显示或回放。例如,视觉引导特征可以是歌词(参见图1中的109)、音调校正指示符(箭头等)、节奏校正指示符(闪烁等)等。声学引导特征可以例如在剧院或类似场所以“souffleur”的方式传递。歌词(参见图1中的109)可以用口头的语音合成并提前以音频方式传递给用户。如果歌曲的元数据没有导致存储的匹配,则可以从容易获得的数据库中获取歌词,或者可以首先离线执行歌词提取。
89.如上所述,置信度分析器102实时分析和比较用户的信号su(n)和原始人声so(n),以创建置信度值e
tot
(n)407。瞬时置信度结果然后用于控制增益105阶段,这些阶段确定在该时刻有多少原始录音的声音被呈现给用户。该系统的可配置性使得该系统适用于所有水平的歌手。例如,可能选择改变旋律的有经验的歌手可以从置信度分析中移除音高分析等,使得系统不会错误地识别出糟糕的演奏并重新引入原始语音。同时,初学者可以在引导特征上全力以赴,或者通过只激活特征的某些部分,来简单地训练不同的方面。
90.图4更详细地示出了在如上图3所述的置信度分析器的过程中执行的置信度估计器的过程的实施例。对通过音高分析303(参见图3)获得的用户音高分析结果ω
fu
(n)400和通过音高分析306(参见图3)获得的原始人声音高分析结果ω
fo
(n)401执行人声音调比较器404过程,以获得音调误差e
p
(n)。同时,对通过节奏分析304(参见图3)获得的用户节奏分析结果和通过节奏分析305(参见图3)获得的原始人声节奏分析结果执行人声节奏比较器405过程,以获得节奏误差er(n)。对音高误差e
p
(n)和节奏误差er(n)执行置信度值计算器406过程,以获得置信度值e
tot
(n)407。随后,置信度值计算器406将音高误差e
p
(n)和节奏误差er(n)合并成一个值,此处是置信度值e
tot
(n)407。音高误差e
p
(n)和节奏误差er(n)应该被转换成具有彼此可比较的单位的值,以便置信值计算器406将其合并成一个值,例如,置信值e
tot
(n)407。
91.置信度值计算器406将音高误差e
p
(n)和节奏误差er(n)合并成一个值,此处是置信度值e
tot
(n)407。置信度值计算器406分别根据音高误差e
p
(n)和节奏误差er(n)对整个音频
信号的重要性,使用不同的权重对音高误差e
p
(n)和节奏误差er(n)加权,以获得置信度值e
tot
(n)407。可以使用加权函数来计算置信度值e
tot
(n):
92.e
tot
(n)=ae
p
(n)+ber(n)
93.其中,e
p
(n)是音高误差,er(n)是节奏误差,a、b是权重,其中,a、b可以是相等的权重,或者可以不是相等的权重。例如,a,b是独立的,可以是零,也可以是正实数。
94.与原始人声的比较最终导致置信度值,其计算可以通过组合各种分析结果的置信度估计器307来配置。在不在这方面限制本公开的情况下,置信度值表示用户的演奏与原始艺术家的演奏的相似性。或者,也可以使用不同的权重来计算置信度值。
95.在本实施例中,在不在这方面限制本实施例的情况下,当误差小时,反映误差(即音调误差e
p
(n)和节奏误差er(n))水平的置信值e
tot
(n)的水平被选择为小,反之亦然。或者,当音调误差e
p
(n)、节奏误差er(n)小时,置信度值e
tot
(n)可以被选择为高。
96.音高分析
97.图5a更详细地示出了在如上图3所述的置信度分析器过程中执行的音高分析过程的实施例。如图3中所述,分别对用户的语音301和原始人声302执行音高分析303和305,以获得音高分析结果ωf。具体地,对人声500,即人声信号s(n),执行信号成帧501的过程,以获得成帧的人声sn(i)。对成帧的人声sn(i)执行快速傅立叶变换(fft)频谱分析502的过程,以获得fft频谱s
ω
(n)。对fft频谱s
ω
(n)执行音高测量分析503,以获得音高测量结果r
p
(ωf)。
98.在信号成帧501中,可以通过下式获得窗口化帧(例如,成帧人声sn(i))
99.sn(i)=s(n+i)h(i)
100.其中,s(n+i)表示偏移了n个样本的离散音频信号(i表示样本数,因此表示时间),h(i)是时间n(分别为样本n)附近的成帧函数,例如,本领域技术人员公知的汉明函数(hamming function)。
101.在fft频谱分析502中,每个成帧的人声被转换成相应的短期功率谱。可以通过下式获得在离散傅里叶变换中获得的短期功率谱s(ω),也称为短期fft的幅度
[0102][0103]
其中,sn(i)是窗口化帧中的信号,例如,上面定义的成帧人声sn(i),ω是频域中的频率,|s
ω
(n)|是短期功率谱s(ω)的分量,n是窗口化帧中的样本数量,例如,每个成帧人声中的样本数量。
[0104]
可以例如实现音高测量分析503,如在der-jenq liu和chin-teng lin在2001年9月在ieee transactions on speech and audio processing第9卷第6期第609至621页公开的论文“fundamental frequency estimation based on the joint time-frequency analysis of harmonic spectral structure”中所述。
[0105]
通过下式从帧窗口sn的功率谱密度s
ω
(n)中获得每个基频候选ωf的基音量度r
p
(ωf)
[0106]rp
(ωf)=re(ωf)ri(ωf)
[0107]
其中,re(ωf)是基频候选ωf的能量度量,ri(ωf)是基频候选ωf的脉冲度量。
transactions on speech and audio processing第9卷,第6期,第609至621页,2001年9月公开的论文“fundamental frequency estimation based on the joint time-frequency analysis of harmonic spectral structure”、alain de cheveigne和hideki kawahara在j.acoust.soc.am.、111(4)(2002)公开的论文“yin,a fundamental frequency estimator for speech and music”、lane和john e.在computer music journal 14.3(1990):第46至59公开的论文“pitch detection using a tunable iir filter”以及cecilia jarne在methodsx第6卷,第124至131页,2019年公开的论文“a method for estimation of fundamental frequency for tonal sounds inspired on bird song studies”中所述。
[0127]
图5b更详细地示出了在如上图4所述的置信度估计器的过程中执行的人声音高比较器的过程的实施例。基于原始人声音高分析结果ω
fo
(n)和用户音高分析结果ω
fu
(n),执行人声音高比较器404过程,如图4所示。
[0128]
具体地,人声音高比较器404将音高误差e
p
(n)(参见图4和5a)转换成误差值,例如,分(cent),其是用于音程的对数测量单位。音程是两个声音信号之间的音高差,在此处,音程等于音高误差e
p
(n)。例如,为了比较不同的频率,即用户的音高分析结果ω
fu
(n)与原始人声音高分析结果ω
fo
(n),可以将两个频率ω
fu
(n)、ω
fo
(n)之间的比率计算为频率比r:
[0129][0130]
频率比的确定506以测量单位“分”表示两个频率之间的差。本领域技术人员已知“分”是两个频率之比的测量单位。根据定义,同等调和的半音(两个相邻钢琴键之间的音程)跨度为100分。八度音阶(频率比为2:1的两个音符)跨越12个半音,因此是1200分。
[0131]
音程和频率比(单位为分)之间的关系如下表所示:
[0132][0133][0134]
例如,在原始人声音高与用户语音音高之间的差异(例如,中心为r=300)的情况下,两个语音之间的音程为小三度。即,在原始人声音高和用户语音音高相差300美分的情况下,其差异是三个半音。在原始人声音高和用户语音音高相差r=100的情况下,其差异是一个半音。在原始人声音高和用户语音音高相差r=1200的情况下,其差异是12个半音,即一个八度音阶。换言之,频率之间的差异越大,音程大小就越高。因此,如上所述以分表示的频率比r是用户做出的与原始人声相比的音高误差e
p
(n)的适当度量。
[0135]
使用上面的等式,当ω
fu
(n)《ω
fo
(n)时,即当用户符号(user sign)低于原始人声时,两个频率ω
fu
(n)、ω
fo
(n)之间的比率为负(-),并且当ω
fu
(n)》ω
fo
(n)时,即当用户符号高于原始人声时,频率比为正(+)。
[0136]
随后,对频率比执行模-600运算507,以获得更低的频率比整数600表示六个半音的音程。模运算找出一个数(此处是频率比)除以另一个数(此处是
mathematical society.56中所述。
[0147]
如同在图5b的音高分析过程中,在用户的语音节奏分析303和原始人声节奏分析305中使用的低通滤波器601可以是由下式给出的低通有限脉冲响应(fir)滤波器
[0148][0149]
其中,d(n)是起始点检测信号,ai是0≤i≤m时第m阶fir滤波器在第i个瞬间的脉冲响应值。可以根据技术人员的设计选择来选择滤波器参数m和ai。例如,为了标准化,a0=1,0.1秒≤m≤0.3秒。
[0150]
随后,基于原始人声节奏分析结果和用户节奏分析结果执行人声节奏比较器405过程,如图4所示。具体而言,混合器604整合两个信号,即原始人声信号do(n)和反转的用户语音信号du(n),以获得表示其差异的混合信号d(n)。然后,对混合信号d(n)执行绝对605运算,以获得绝对值|d(n)|。然后,对绝对值|d(n)|执行第二低通滤波器606,以获得节奏误差er(n)607。第二低通滤波器606与上述低通fir滤波器601相同。
[0151]
在图6的实施例中,基于低通滤波来执行节奏分析,也如bello,j.p.,daudet,l.,abdallah,s.,duxbury,c.,davies,m.,&sandler,m.b.(2005)公开的论文“a tutorial on onset detection in music signals”ieee transactions on speech and audio processing,13(5),1035
–
1047.https://doi.org/10.1109/tsa.2005.851998中所述。
[0152]
声学回声消除
[0153]
声学回声消除(aec)过程从通过声学空间的信号中去除回声、混响。来自用户讲话的声音(称为far end in)被并行发送到数字信号处理器(dsp)路径和声学路径。声学路径由放大器(此处是放大器704)和扬声器(此处是扬声器系统111)、声学环境和麦克风(此处是用户的麦克风100)组成,将信号返回到dsp。aec过程基于自适应有限脉冲响应(fir)滤波器。
[0154]
图7示意性地示出了在如上图1所述的音频信号调整过程中执行的声学回声消除过程。用户的麦克风100获取用户的语音,并且为了防止潜在回声信号的产生,用户的语音信号s(n)被传输到混合器700和回声路径估计器701。回声路径估计器701估计声学路径,以获得声学回声路径信号,该信号被传输到自适应有限脉冲响应(fir)滤波器h^(t)。自适应fir滤波器h^(t)使用一种算法对回声路径信号执行滤波,该算法连续地使fir滤波器h^(t)适应于对声学路径进行建模,以获得估计的回声信号。从声学回声路径信号中减去估计的回声信号,以产生“干净的”信号输出,其中,大幅去除声学回声的线性部分。调整自适应fir滤波器h^(t),直到误差被最小化,该误差是估计的回波信号和期望信号(例如,没有回声的信号)之间的差。误差可以是估计的误差信号。回声消除过程包括识别在发送或接收的信号中以一定延迟重新出现的原始发送的信号。一旦识别出回声,就可以通过从发送的信号(此处是用户的麦克风信号su(n))或接收的信号(此处是调整后的音频信号s
″o(n))中减去回声来消除回声。随后,用户的语音信号su(n)被传输到语音活动检测器(vad)101。
[0155]
增益调整
[0156]
图8示出了基于在图3中描述的置信度分析器的过程中执行的置信度值来可视化置信度到增益的映射过程的流程图。置信度到增益的映射308接收由图3中的置信度估计器
308获得的置信度值e
tot
(n)。通过下式获得增益控制信号g(n)(gain)
[0157]
g(n)=d
×etot
(n)
[0158]
其中,d是预定的常数。例如,其中,e是lp 606的脉冲响应的能量。
[0159]
在801,如果d
×etot
(n)≤,则在802,置信度到增益的映射308设置增益g(n)=d
×etot
(n)。如果在801,d
×etot
(n)>1,则在803,置信度到增益的映射308设置增益g(n)=1。在804,获得增益控制信号g(n)。
[0160]
增益105将原始人声so(n)的分布应用于混合,例如,调整后的音频信号s
″o(n),其范围从“0=无分布”到“1=未改变的分布”,前者当然将“阶段”完全交给用户,而后者实现正常回放。即,置信度到增益的映射308可以以这样的方式设置增益控制信号407,使得如果用户以完美的音高唱歌,则用户不会接收到任何引导。
[0161]
然而,这不是二进制系统,即,根据置信度度量的瞬时值,置信度分析器102也可以只是降低原始人声,而不是完全去除。原始人声so(n)的水平完全由置信度分析器102控制,因此置信度值e
tot
(n)也是如此。低置信度可能导致不变的回放,而高置信度可能导致完全移除原始人声so(n)。
[0162]
在图8的实施例中,通过线性函数g(n)=d
×etot
(n)获得增益控制信号g(n),在这方面不限制本实施例。或者,可以通过技术人员已知的任何非线性函数获得增益控制信号g(n),并且可以根据技术人员的设计选择来选择。
[0163]
基于置信度分析的基于对象的音频信号调整
[0164]
图9示意性地示出了基于置信度分析的基于对象的音频信号的音频调整过程。基于对象的音频信号是包含基于对象的人声和基于对象的伴奏的音频输入信号x(n)。基于对象的人声是原始人声信号so(n),基于对象的伴奏是伴奏信号sa(n)。原始人声so(n)被传输到置信度分析器102和增益105。用户的麦克风100获取用户的语音,并将用户的语音信号su(n)传输到语音活动检测器(vad)101和置信度分析器102。对用户的语音信号sv(n)执行语音活动检测器101的过程,以获得触发信号。触发信号基于检测到的用户语音信号su(n)触发置信度分析器102的过程。基于从音频输入信号x(n)获得的人声so(n),对用户的语音信号su(n)执行置信度分析102的过程,以获得增益控制信号g(n)和引导控制信号。基于增益控制信号g(n),增益105被应用于人声so(n),以获得调整后的人声s
′o(n)。混合器106将由增益105获得的调整后的人声s
′o(n)与伴奏sa(n)混合,以获得调整后的音频信号s
″o(n)。置信度分析器102基于引导控制信号311控制视觉引导107和音频引导108,以分别获得视觉引导信号和音频引导信号。基于从容易获得的数据库中获取的一段音乐的歌词109来执行视觉引导107和音频引导108。或者,如果歌曲的元数据没有导致匹配,则首先离线执行歌词109提取。基于视觉引导信号,在显示单元110上显示视觉引导。基于音频引导信号,由扬声器系统111输出声学引导。视觉引导107可以是歌词、音调校正指示、节奏定向等。音频引导108可以是“suffleur系统”,其中,该系统在歌词在这段音乐中的时间位置之前说出歌词(像在剧院中一样)。在这种情况下,歌词109以口头语音合成,并提前以音频方式传递给用户。
[0165]
使用声学回声消除的音频信号调整
[0166]
图10示意性地示出了如以上图1中所述的音频信号的音频调整过程的实施例,其中,如以上图7中所述执行回声消除。包含多个源(参见图1中的1,2,
…
,k)的音频输入信号x
(n)(例如,单声道或立体声音频输入103信号x(n),例如,一段音乐)被输入到音乐源分离过程104,并被分解成分离(参见图2中的分离源2和残余信号3),在此处分解成分离源2(即“人声”so(n))和残余信号3,即“伴奏”sa(n)。将人声so(n)传输到置信度分析器102和增益105。用户的麦克风100获取用户的语音s(n),并且为了防止产生潜在的回声信号,将该语音传输到混合器700和回声路径估计器701。回声路径估计器701估计声学路径,以获得声学回声路径信号,该信号被传输到自适应有限脉冲响应(fir)滤波器h^(t)。
[0167]
自适应fir滤波器h^(t)使用一种算法对回声路径信号执行滤波,该算法连续地使fir滤波器h^(t)适应于对声学路径进行建模,以获得估计的回声信号。从声学回声路径信号中减去估计的回声信号,以产生“干净的”信号输出,其中,大幅去除声学回声的线性部分。调整自适应fir滤波器h^(t),直到误差最小化,该误差是估计的回波信号和期望信号之间的差。误差可以是估计的误差信号。回声消除包括首先识别在传输或接收的信号中以一定延迟重新出现的原始传输的信号。一旦识别出回声,就可以通过从传输的信号(此处是用户的麦克风信号su(n))或接收的信号(此处是调整后的音频信号s
″o(n))中减去回声来消除回声,以获得回声消除的用户语音信号e(n)。
[0168]
随后,用户的语音信号su(n)被传输到语音活动检测器(vad)101和置信度分析器102。对用户的语音信号su(n)执行语音活动检测器101的过程,以获得触发信号。触发信号基于检测到的用户语音信号su(n)触发置信度分析器102的过程。基于从音频输入信号x(n)获得的人声so(n),对用户的语音信号su(n)执行置信度分析102的过程,以获得增益控制信号g(n)和引导控制信号。基于增益控制信号g(n),增益105被应用于人声so(n),以获得调整后的人声s
′o(n)。混合器106将由增益105获得的调整后的人声s
′o(n)与由音乐源分离104获得的伴奏sa(n)混合,以获得调整后的音频信号s
″o(n)。置信度分析器102基于引导控制信号311控制视觉引导107和音频引导108,以分别获得视觉引导信号和音频引导信号。基于一段音乐的歌词109来执行视觉引导107和音频引导108,此处是从容易获得的数据库获取的单声道或立体声音频输入103信号x(n)。或者,如果歌曲的元数据没有导致匹配,则首先离线执行歌词109提取。基于视觉引导信号,在显示单元110上显示视觉引导。基于音频引导信号,由扬声器系统111输出声学引导。视觉引导107可以是歌词、音调校正指示、节奏定向等。音频引导108可以是“suffleur系统”,其中,该系统在歌词在这段音乐中的时间位置之前说出歌词(像在剧院中一样)。在这种情况下,歌词109以口头语音合成,并提前以音频方式传递给用户。
[0169]
在图10的实施例中,在不在这方面限制本公开的情况下,描述了如上图1所述的音频信号的音频调整过程,其中,执行回声消除。或者,也可以在基于对象的音频信号的音频调整过程中执行回声消除,如上面图9中所述。
[0170]
图11示意性地更详细地描述了在如上图1所述的音频信号调整过程中执行的置信度分析器的过程的另一实施例。置信度分析器102基于由语音活动检测器101获得的触发信号300来分析由用户麦克风100获取的用户语音301和由音乐源分离104(参见图1)获得的音频输入信号x(n)的人声302。
[0171]
具体地,对用户的语音301执行音高分析303,以获得音高分析结果ωf,对用户的语音301执行专业分析1000,以获得专业分析结果,并且对用户的语音301执行节奏分析304,以获得节奏分析结果。与用户语音301同时,对原始人声302执行节奏分析305,以获得
节奏分析结果,对原始人声302执行专业分析1001,以获得专业分析结果,对原始人声302执行音高分析306,以获得音高分析结果ωf。对音高分析结果ωf.执行置信度估计器307的过程,以获得专业分析结果,例如,颤音(能量调制频谱)、音域等,并且对用户语音301和人声302的节奏分析结果执行置信度估计器307的过程,以获得置信度值407。基于置信度值(e
tot
(n))执行置信度到增益的映射(308),以获得增益控制信号(407)。置信度到增益的映射308将置信度值407与增益值进行映射。即,基于置信度估计器307的结果,例如,置信度值407,置信度分析器确定来自置信度到增益的映射308阶段的增益。与置信度到增益的映射308同时,基于置信度值执行引导逻辑309的过程,以获得引导控制信号(参见图3中的311)。引导逻辑309基于其设置控制引导特征,例如,视觉引导107(参见图1)和音频引导108(参见图1)。
[0172]
方法和实施方式
[0173]
图12示出了可视化基于置信度分析器过程和基于分离源的信号混合方法的流程图。在1100,音乐源分离(参见图1中的104)接收音频输入信号(参见图1中的x(n))。在1101,基于接收的音频输入信号执行音乐源分离(参见图1的104),以获得人声和伴奏(参见图1)。在1102,基于原始人声对用户的语音执行置信度分析(参见图1中的102),以获得置信度值(参见图1、图3、图4、图9和图10)。在1103,基于置信度值调整人声的增益(参见图1中的105),以获得调整后的人声(参见图8)。在1104,将调整后的人声与伴奏混合(参见图1、图9和图10中的106),以获得调整后的音频信号。在1105,将调整后的音频信号输出到扬声器系统(参见图1、图9和图10中的111)。在1106,基于置信度值执行视觉引导(参见图1、图9和图10中的107)和音频引导(参见图1、图9和图10中的108),以分别获得视觉引导信号和音频引导信号。在1107,将视觉引导输出到显示单元(参见图1、图9和图10中的110),并且将音频引导输出到扬声器系统(参见图1、图9和图10中的111)。
[0174]
在图12的实施例中,描述了可视化基于音乐源分离的信号混合方法的流程图,然而,本公开不限于上述方法步骤。例如,可以输入分离的基于对象的音频信号,作为音频输入信号(参见图9),而不是单声道/立体声音频输入信号等。此外,由于上述方法是实时过程的方法,所以视觉和音频引导的步骤可以与将调整后的音频输出到扬声器系统的步骤同时执行。即,执行上述过程的系统是一个交互式和自适应的系统,该系统实时处理例如来自流或任何其他本地媒体的音频材料。
[0175]
图13示意性地描述了电子设备的实施例,该电子设备可以实现如上所述的基于置信度分析和音乐源分离的音频混合过程。电子设备1200包括作为处理器的cpu 1201。电子设备1200还包括连接到处理器1201的麦克风阵列1210、扬声器阵列1211和卷积神经网络单元1220。处理器1201可以例如实现置信度分析器102、增益105、视觉引导107和音频引导108,其实现了关于图1、图3、图4、图5、图6、图9和图10更详细描述的过程。cnn 1220例如可以是硬件中的人工神经网络,例如,gpu上的神经网络或专用于实现人工神经网络的任何其他硬件。cnn 1220可以例如实现源分离104和/或回声消除,其实现了关于图1、图7和图10更详细描述的过程。扬声器阵列1211(例如,关于图1、图7和图10描述的扬声器系统111)由分布在预定空间上的一个或多个扬声器组成,并且被配置为呈现任何种类的音频,例如,3d音频。电子设备1200还包括连接到处理器1201的用户界面1212。该用户界面1212充当人机接口,并实现管理员和电子系统之间的对话。例如,管理员可以使用该用户界面1212对系统进
行配置。电子设备1200还包括以太网界面1221、蓝牙界面1204和wlan界面1205。这些单元1204、1205充当与外部设备进行数据通信的i/o界面。例如,具有以太网、wlan或蓝牙连接的附加扬声器、麦克风和摄像机可以经由这些界面1221、1204和1205耦合到处理器1201。电子设备1200还包括数据存储装置1202和数据存储器1203(此处是ram)。数据存储器1203被设置为临时存储或缓存数据或计算机指令,以供处理器1201处理。数据存储装置1202被设置为长期存储装置,例如,用于记录从麦克风阵列1210获得的并被提供给cnn 1220或从cnn 1220检索的传感器数据。
[0176]
应当注意,上面的描述仅仅是示例配置。可替换的配置可以用额外的或其他的传感器、存储设备、界面等来实现。
[0177]
应当认识到,实施例描述了具有方法步骤的示例性排序的方法。然而,仅仅是出于说明的目的而给出方法步骤的特定顺序,不应该被解释为具有约束力。
[0178]
还应注意,将图13的电子设备划分成单元仅出于说明目的,且本公开不限于特定单元中的任何特定功能划分。例如,至少部分电路可以由分别编程的处理器、现场可编程门阵列(fpga)、专用电路等来实现。
[0179]
如果没有另外说明,在本说明书中描述的和在所附权利要求中要求保护的所有单元和实体可以被实现为例如芯片上的集成电路逻辑,并且如果没有另外说明,由这样的单元和实体提供的功能可以由软件实现。
[0180]
就至少部分使用软件控制的数据处理设备来实现上述公开的实施例而言,将会理解,提供这种软件控制的计算机程序以及提供这种计算机程序的传输、存储或其他介质被设想为本公开的方面。
[0181]
注意,本技术也可以如下所述进行配置。
[0182]
(1)一种包括电路的电子设备,电路被配置为对音频输入信号(x(n))执行音频源分离(104),以获得人声信号(so(n))和伴奏信号(sa(n)),并基于人声信号(so(n))对用户的语音信号(su(n))执行置信度分析(102),以向用户提供引导。
[0183]
(2)根据(1)的电子设备,其中,电路还被配置为从人声信号(so(n))中获得调整后的人声信号(s
′o(n))并执行调整后的人声信号(s
′o(n))与伴奏信号(sa(n))的混合(106),以获得调整后的音频信号(s
″
o(n))用于向用户提供引导。
[0184]
(3)根据(2)的电子设备,其中,电路还被配置为回放调整后的音频信号(s
″o(n)),以向用户提供引导。
[0185]
(4)根据(2)的电子设备,其中,电路还被配置为基于置信度分析(102)对人声信号(so(n))执行增益控制(105),以获得调整后的人声信号(s
′o(n))。
[0186]
(5)根据(1)至(4)中任一项的电子设备,其中,电路还被配置为基于置信度分析(102)生成引导控制信号(311),并基于引导控制信号(311)执行视觉或音频引导(107),以向用户提供引导。
[0187]
(6)根据(1)至(5)中任一项的电子设备,其中,电路还被配置为对人声信号(so(n))执行音高分析(306),以获得人声音高分析结果(ω
fo
(n)),对用户的语音(su(n))执行音高分析(303),以获得用户的音高分析结果(ω
fu
(n)),并且基于人声音高分析结果(ω
fo
(n))和用户的音高分析结果(ω
fu
(n))执行人声音高比较(404),以获得音高误差(e
p
(n))。
[0188]
(7)根据(1)至(6)中任一项的电子设备,其中,电路还被配置为对人声信号(so(n))执行节奏分析(305),以获得人声节奏分析结果对用户的声音(su(n))执行节奏分析(304),以获得用户的节奏分析结果并且基于人声节奏分析结果和用户的节奏分析结果执行人声节奏比较(405),以获得节奏误差(er(n))。
[0189]
(8)根据(5)的电子设备,其中,电路还被配置为基于音高分析结果(ω
fo
(n)、ω
fu
(n))和基于节奏分析结果执行置信度估计(307),以获得置信度值(e
tot
(n))。
[0190]
(9)根据(8)的电子设备,其中,电路还被配置为基于置信度值(e
tot
(n))执行置信度到增益的映射(308),以获得增益控制信号(407)。
[0191]
(10)根据(8)的电子设备,其中,电路还被配置为基于置信度值(e
tot
(n))执行引导逻辑(309),以获得引导控制信号(311)。
[0192]
(11)根据(1)至(10)中任一项的电子设备,其中,电路还被配置为对用户的语音信号(su(n))执行语音活动检测(101),以获得触发置信度分析的触发信号(300)。
[0193]
(12)根据(8)的电子设备,其中,置信度分析器(102)还被配置为基于置信度值(e
tot
(n))向用户提供引导。
[0194]
(13)根据(9)的电子设备,其中,置信度到增益的映射(308)被配置为以使得如果用户以完美的音高唱歌,则用户不会接收到任何引导这样的方式设置增益控制信号(407),。
[0195]
(14)根据(1)至(13)中任一项的电子设备,其中,音频输入信号(x(n))包括单声道和/或立体声音频输入信号(x(n)),或者音频输入信号(x(n))包括基于对象的音频输入信号。
[0196]
(15)根据(1)至(14)中任一项的电子设备,其中,电路还被配置为对用户的语音(su(n))执行回声消除,以获得无回声的用户语音。
[0197]
(16)根据(1)至(15)中任一项的电子设备,其中,电路还被配置为对人声信号(so(n))执行专业分析(1001),以获得人声专业分析结果,对用户的语音(su(n))执行专业分析(1000),以获得用户的专业分析结果
[0198]
(17)根据(1)至(16)中任一项的电子设备,其中,电路包括麦克风,麦克风被配置为捕捉用户的人声信号(su(n))。
[0199]
(18)一种方法,包括:
[0200]
对音频输入信号(x(n))执行音频源分离(104),以获得人声信号(so(n))和伴奏信号(sa(n));以及
[0201]
基于人声信号(so(n))对用户的语音信号(su(n))执行置信度分析(102),以向用户提供引导。
[0202]
(19)一种包括指令的计算机程序,当在处理器上执行指令时,指令使处理器执行根据(18)的方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1