用文本和言语自动生成面部动作单元的面部动画控制的制作方法
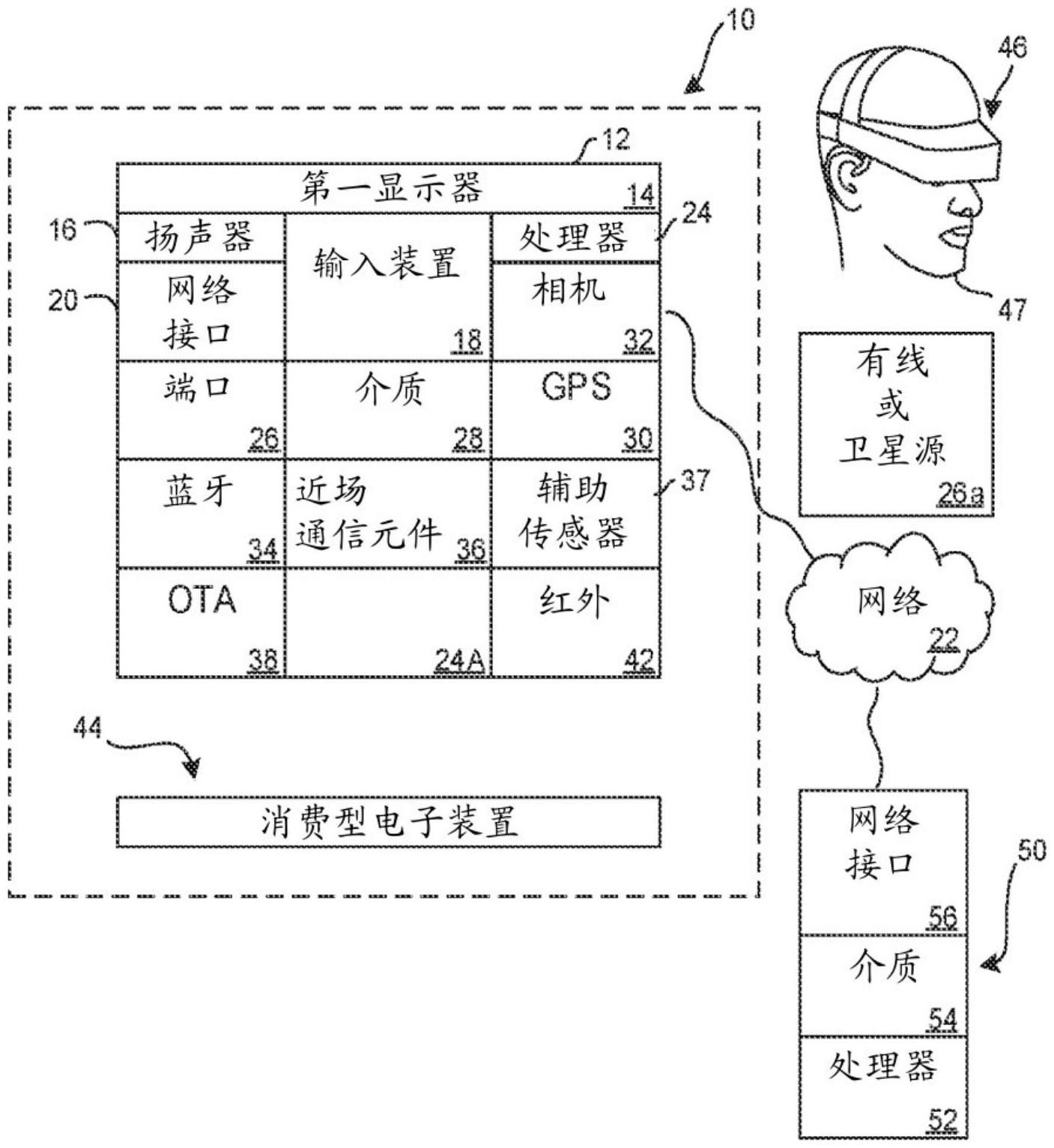
本申请总体上涉及计算机模拟和其他应用中的用文本和言语自动生成面部动作单元(fau)的面部动画控制。
背景技术:
1、例如计算机游戏化身的计算机化的图像的面部在模拟播放期间被动画化以提供真实效果。如本文所理解,美术师一般必须精心创建面部动作单元(fau),所述fau用于通过评估人类面部上的相应肌肉点的收缩或放松来在逐帧的基础上使面部的相应部分动画化。
技术实现思路
1、一种设备包括:至少一个处理器,所述至少一个处理器配置有用于识别计算机化的化身的面部的图像的指令。所述指令能够执行以向机器学习(ml)引擎输入与所述化身相关的第一模态数据,向所述ml引擎输入与所述化身相关的第二模态数据,并且从所述ml引擎接收对使所述化身的面部的所述图像动画化有用的输出。所述指令能够执行以根据所述输出来使所述化身的所述面部动画化。
2、在一些实施方案中,所述输出包括面部动作单元(fau),其中每个fau涉及所述面部的所述图像的相应部分。在非限制性示例中,所述第一模态数据包括文本并且所述第二模态数据包括言语。
3、在非限制性示例中,所述指令可能够执行以使用所述ml引擎从所述第一模态数据和所述第二模态数据导出情感动作信息。所述输出可至少部分地基于根据所述情感动作信息产生的时间对齐的字词级别情感概率。
4、在另一方面,一种方法包括:使用说出已知字词的动画化的面部的训练集来训练机器学习(ml)模型。所述方法还包括:生成要动画化以根据第一文本说出字词的第一面部的图像。所述方法还包括:向所述ml模型输入所述第一文本;以及根据所述ml模型的输出使所述第一面部的所述图像动画化以说出由所述第一文本指示的第一字词。
5、在示例性实施方案中,所述方法可包括:从所述第一文本检测情感和情绪;将所述第一文本与表示所述第一文本的言语对齐以渲染对齐的文本/言语;以及向所述ml模型输入所述情感、所述情绪和所述对齐的文本/言语。所述方法还可包括:向所述ml模块输入目标情感。所述方法的示例性实现方式可包括:从所述ml模态接收表示面部动作的第一概率;从所述ml模型接收表示情感的第二概率;以及使用所述第一概率和所述第二概率来建立面部动作单元(fau)。所述方法然后可包括:根据所述fau来使所述第一面部的所述图像动画化。
6、在另一方面,一种组件包括:至少一个显示器,所述至少一个显示器被配置来呈现动画化的计算机化身;以及至少一个处理器,所述至少一个处理器配置有用于执行机器学习(ml)模型的指令。所述指令能够执行以:接收指示所述化身要说出的言语的文本;使用所述ml模型处理所述文本以生成面部动作单元(fau);并且根据所述fau来使所述计算机化身动画化。
7、本申请的关于其结构和操作两者的细节可参考附图得到最好的理解,在附图中相同的附图标记指代相同的部分,并且在附图中:
技术特征:
1.一种设备,其包括:
2.如权利要求1所述的设备,其中所述输出包括面部动作单元(fau),每个fau涉及所述面部的所述图像的相应部分。
3.如权利要求1所述的设备,其中所述第一模态数据包括文本。
4.如权利要求1所述的设备,其中所述第二模态数据包括言语。
5.如权利要求3所述的设备,其中所述第二模态数据包括言语。
6.如权利要求3所述的设备,其中所述指令能够执行以使用所述ml引擎从所述第一模态数据和所述第二模态数据导出情感动作信息。
7.如权利要求6所述的设备,其中所述输出至少部分地基于根据所述情感动作信息产生的时间对齐的字词级别情感概率。
8.一种方法,其包括:
9.如权利要求8所述的方法,其包括:
10.如权利要求9所述的方法,其包括:
11.如权利要求9所述的方法,其包括:
12.如权利要求11所述的方法,其包括:
13.如权利要求12所述的方法,其包括:
14.如权利要求13所述的方法,其包括:
15.一种组件,其包括:
16.根据权利要求15所述的组件,其中所述指令能够执行以:
17.如权利要求16所述的组件,其中所述指令能够执行以:
18.如权利要求15所述的组件,其中所述指令能够执行以:
19.如权利要求18所述的组件,其中所述指令能够执行以:
20.如权利要求19所述的组件,其中所述指令能够执行以:
技术总结
由机器学习引擎处理来自计算机模拟的文本和言语以使计算机化身的面部(202)动画化(306)。
技术研发人员:L·考希克,S·库马尔
受保护的技术使用者:索尼互动娱乐股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!