短时语音识别性能提升方法与流程
1.本发明涉及语音识别技术领域,特别是一种短时语音识别性能提升方法。
背景技术:
2.短时语音广泛存在于各种行业应用,例如电力作业现场、车载系统、智能家居和飞行训练等场景的语音指令。这些场景中的短时语音存在这样的特点:语音简短,语音内容可预知。
3.基于深度学习方法的语音识别技术在近十年内得到了快速发展,但该类方法的性能依赖数据、算力和模型。训练语音识别模型需要语音数据,以及对语音数据进行标注。标注语音数据的工作量也不小,往往需要两小时甚至更长时间才能完成一小时语音的标注。训练语音识别模型,还需要强大的算力支撑。这些最终都成了实现高性能语音识别应用的成本。若语音识别模型的性能不佳,通常需要增加数据,并重新训练模型。这进一步推高了语音识别应用的成本。
技术实现要素:
4.鉴于此,本发明提供一种短时语音识别性能提升方法,不必重新训练语音识别模型,针对短时语音的特点,对输入语音识别模型的语音进行预处理,对语音识别模型输出的结果进行后处理,提升短时语音识别的性能。
5.本发明公开了一种短时语音识别性能提升方法,包括以下步骤:
6.步骤1:对待识别短时语音进行预处理;
7.步骤2:将预处理后的结果输入已训练好的语音识别模型进行识别处理;
8.步骤3:对步骤2中的语音识别模型的输出结果进行后处理。
9.进一步地,所述预处理包括依次进行语音提取和语音延拓处理。
10.进一步地,所述语音提取包括:将待识别短时语音转化成若干个仅包含说话声音的语音,以去除待识别短时语音中不包含说话声音的部分。
11.进一步地,对所述待识别短时语音进行语音提取,具体包括:
12.步骤4-1:将时长为la的待识别短时语音a以ls为单位时长进行分割,a末尾时长不足ls的部分直接忽略,每个分割后的语音称为切片,得到切片列表
13.步骤4-2:计算每个切片在a中对应的时间点,得到时间点列表计算公式如下:
14.ti=(i-1)*ls15.步骤4-3:将s中的切片从s1开始入队列至总容量为n的队列q中,每次入队列一个切片,如队列q已满,则先出队列一个切片;每个切片入队列成功后,使用语音活动检测算法判断该切片是否包含说话声音,如是则将该切片标记为voiced,反之标记为unvoiced;标记
完后计算队列q中voiced切片的占比rv和unvoiced切片的占比ru,计算公式如下:
[0016][0017][0018]
步骤4-4:重复步骤4-3,直至rv大于等于设定的阈值hs时,将队列q中离队首最远的切片si对应的时间点ti作为一个说话声音起始时间点v;清空队列后继续重复步骤4-3,直至ru大于等于设定的阈值he或最后一个切片进入队列时,将队列q中离队首最近的切片sj对应的时间点tj加上ls作为说话声音结束时间点u,并清空队列;v和u构成一个起始结束时间点对p=(v,u),对应a中一段仅包含说话声音的语音;
[0019]
步骤4-5:重复步骤4-4直至最后一个切片进入队列,得到一系列的起始结束时间点对p={(v1,u1),(v2,u2),(v3,u3)
…
(vm,um)},m为正整数;
[0020]
步骤4-6:按照p中的起始结束时间点对从a中提取出对应的仅包含说话声音的语音作为语音提取的结果{a1,a2,a3…am
},am为a中一段仅包含说话声音的语音。
[0021]
进一步地,所述语音延拓是对语音提取后的结果进行动态批量填充操作,即将提取后的语音按照语音时长聚类分组,并在每一组语音的首尾填充人造数据,使得同一组中语音在填充后的长度都相同,同时将多个语音的时长填充至统一长度后,能够利用所述步骤2中的已训练好的语音识别模型的批处理能力同时对多个语音进行识别。
[0022]
进一步地,所述语音延拓的具体实现步骤包括:
[0023]
步骤6-1:对待识别短时语音的语音提取结果进行标记,标记内容共四项:1)原先待识别短时语音的编号;2)原先待识别短时语音提取后的语音数量;3)该提取后语音在原先待识别短时语音所有提取后语音中的时间顺序;4)该提取后语音的时长;
[0024]
步骤6-2:将标记后的语音入队列至一个总容量为m的队列中,每次入队列一条语音;只要当队列一满或者距上一次队列为空超过t时间时,将队列中所有的语音一次性出队列,并按步骤6-1中标记的时长信息用聚类算法将这些语音分为时长相近的k组;
[0025]
步骤6-3:在每一组中,先获取该组中最长语音的时长,记为lg,然后在其余语音的首尾均匀的填充零值,直至时长为lg;
[0026]
步骤6-4:将每一组填充好的语音作为一个批次输入语音识别模型进行识别;当该批次的语音数量超过语音识别模型的批处理上限时,则将该批次按照上限数量分为若干个小的批次输入语音识别模型。
[0027]
进一步地,所述后处理包括依次进行识别结果重组和发音相似度匹配处理。
[0028]
进一步地,所述识别结果重组具体包括:
[0029]
每一条识别结果都与语音延拓中的一条语音唯一对应,也唯一对应一条标记信息,将对应标记信息中具有相同原先待识别语音的编号的识别结果分为一组,当同一组中的识别结果数量等于标记信息中的原先待识别语音提取后的语音数量后,按照标记信息中的该提取后语音在原先待识别语音所有提取后语音中的时间顺序进行排序,合并排序后的结果完成重组。
[0030]
进一步地,所述发音相似度匹配是利用“语音内容可预知”的特点,将识别结果重组后的结果与所有可预知的语音内容进行发音相似度的比较,若存在一可预知的语音内容
与其之间的相似度达到一定值,则将该可预知的语音内容作为最终结果输出,否则将其自身作为最终结果输出;
[0031]
其中,围绕声母、韵母和声调设计的相似距离d以衡量两个任意长度文本之间的发音相似度,d越小表示越相似,具体公式为:
[0032][0033]
其中:
[0034]
d(w,w
′
)表示识别结果重组后的结果与任何一可预知的语音内容之间的相似距离;
[0035]
w表示识别结果重组后的结果,lw表示其所含字符个数;
[0036]w′
表示任何一可预知的语音内容,lw′
表示其所含字符个数;
[0037]
{ci|1≤i≤lw}表示组成w的所有字符;
[0038]
{c
′i|1≤i≤lw′
}表示组成w
′
的所有字符;
[0039]
为字符ci的拼音格式,分别表示声母,韵母和声调部分;
[0040]
为字符c
′i的拼音格式,分别表示声母,韵母和声调部分;
[0041]
z表示w中每个字符的拼音格式都按m
p
进行编码后的结果;
[0042]z′
表示w
′
中每个字符的拼音格式都按m
p
进行编码后的结果;
[0043]sp
表示声母之间和韵母之间的相似距离;
[0044]st
表示声调之间的相似距离;
[0045]
α,β,γ为权重系数;
[0046]
e表示z和z
′
的最小加权编辑距离。
[0047]
进一步地,所述发音相似度匹配的具体实现过程为:
[0048]
步骤10-1:穷举所有可预知的语音内容,建立目标结果集w
′
;
[0049]
步骤10-2:依次用{"e01","e02"
…
"e52"}中的值作为23个声母,24个韵母和5种声调的编码值,建立拼音编码表m
p
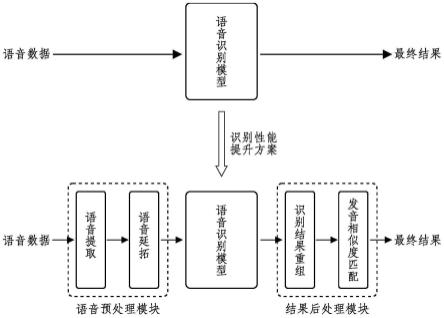
;
[0050]
步骤10-3:设置基准权重δ,并根据步骤10-2中的拼音编码表m
p
建立替换权重矩阵ms;基准权重δ表示在计算最小加权编辑距离过程中删除或添加一个拼音编码的权重;替换权重矩阵ms中的值表示在计算最小加权编辑距离过程中替换对应两个拼音编码的权重;ms中值的设置以δ为基准,如果两个声母、两个韵母或两个声调之间的发音相似,则其对应拼音编码的替换权重小于δ,反之则大于δ,并且声母和韵母之间,声母和音调之间,韵母和音调之间的替换权重远大于δ;
[0051]
步骤10-4:首先在w
′
中匹配是否存在与w完全一致的w
′
,如存在则直接输出w作为最终结果,并停止匹配过程,否则进入步骤10-5;
[0052]
步骤10-5:将w依次与w
′
中含有字符个数相同的w
′
计算d(w,w
′
):使用现有的编码模型将和分别编码为两个m维的向量和同样的,将和也分别编码为两个m维的向量也分别编码为两个m维的向量和
将和按1、2、3、4和5分别表示轻声、第一声、第二声、第三声和第四声的方式进行编码得到和分别计算x
ii
与y
ii
,x
fi
与y
fi
之间的欧式距离作为和计算和的绝对差作为分别乘以对应的权重系数得到字符ci和c
′i的语音距离d(ci,c
′i),累加所有字符的语音距离得到d(w,w
′
),具体计算公式为:
[0053][0054][0055][0056][0057]
其中,为向量中的第j个元素,为向量中的第j个元素,为向量中的第j个元素,为向量中的第j个元素;
[0058]
如d(w,w
′
)小于设定的阈值则直接输出w
′
作为最终结果,并停止匹配过程,否则进入步骤10-6;
[0059]
步骤10-6:将w依次与w
′
中剩余的含有字符个数不同的w
′
计算d(w,w
′
):将w和w
′
中每个字符的拼音都按m
p
进行编码,得到两个编码字符串z=e1e2e3…ei
,ei∈{"e01","e02"
…
"e52"}和z
′
=e
′1e
′2e
′3…e′j,e
′j∈{"e01","e02"
…
"e52"},以mi,md和ms为权重矩阵计算z和z
′
的最小加权编辑距离e(ei,e
′j),具体计算公式为:
[0060]
e(0,0)=0
[0061]
e(em,0)=e(e
m-1
,0)+δ1<m≤i
[0062]
e(0,e
′n)=e(0,e
′
n-1
)+δ1<n≤j
[0063][0064]
其中,e(0,0)表示两个空编码字符串之间的最小加权编辑距离,e(em,0)表示编码字符串e1e2e3…em
和空编码字符串之间的最小加权编辑距离,em是z中的第m个编码字符,e(e
m-1
,0)表示编码字符串e1e2e3…em-1
和空编码字符串之间的最小加权编辑距离,e
m-1
是z中的第m-1个编码字符,e(0,e
′n)表示空编码字符串和编码字符串e
′1e
′2e
′3…e′n之间的最小加权编辑距离,e
′n是z
′
中的第n个编码字符,e(0,e
′
n-1
)表示空编码字符串和编码字符串e
′
1e′2e
′3…e′
n-1
之间的最小加权编辑距离,e
′
n-1
是z
′
中的第n-1个编码字符,e(ei,e
′j)表示编码字符串e1e2e3…ei
和e
′1e
′2e
′3…e′j的最小加权编辑距离,e(e
i-1
,e
′j)表示编码字符串e1e2e3…ei-1
和e
′1e
′2e
′3…e′j的最小加权编辑距离,e(ei,e
′
j-1
)表示编码字符串e1e2e3…ei
和e
′1e
′2e
′3…e′
j-1
的最小加权编辑距离,e(e
i-1
,e
′
j-1
)表示编码字符串e1e2e3…ei-1
和e
′1e
′2e
′3…e′
j-1
的最小加权编辑距离,ms[ei,e
′j]表示取替换权重矩阵中对应拼音编码ei和e
′j的替换权重;
[0065]
如d(w,w
′
)小于设定的阈值则直接输出w
′
作为最终结果,并停止匹配过程,否则以w作为最终结果输出。
[0066]
由于采用了上述技术方案,本发明具有如下的优点:本发明为已训练好的语音识别模型增加语音预处理和结果后处理,无需重新训练,即可提升语音识别的性能。
附图说明
[0067]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明实施例中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
[0068]
图1为本发明实施例的语音识别性能提升方案示意图;
[0069]
图2为本发明实施例的待识别语音分割示意图;
[0070]
图3为本发明实施例的切片入队列示意图;
[0071]
图4为本发明实施例的拼音编码表m
p
;
[0072]
图5为本发明实施例的替换权重矩阵ms。
具体实施方式
[0073]
结合附图和实施例对本发明作进一步说明,显然,所描述的实施例仅是本发明实施例一部分实施例,而不是全部的实施例。本领域普通技术人员所获得的所有其他实施例,都应当属于本发明实施例保护的范围。
[0074]
本实施例的短时语音识别性能提升方法,主要包括语音预处理模块和结果后处理模块,同时需要已训练好的语音识别模型。本实施例就是为已训练好的语音识别模型增加语音预处理模块和结果后处理模块,无需重新训练,即可提升短时语音识别的性能。
[0075]
语音预处理和结果后处理模块是本实施例的核心:语音预处理模块是在将待识别语音送入语音识别模型前对待识别语音进行处理,包括语音提取和语音延拓两部分;结果后处理模块是对语音识别模型的输出结果进行处理,包括识别结果重组和发音相似度匹配两部分。两者不涉及对语音识别模型的改动,分别置于语音识别模型的前后,提升语音识别的性能。
[0076]
参见图1,本发明提供了一种短时语音识别性能提升方法及系统的实施例,其包括语音预处理模块、识别模型、结果后处理模块三大部分,分别具体为:
[0077]
(一)语音预处理模块
[0078]
语音预处理模块,首先对待识别语音进行语音提取操作,去除其中不包含说话的声音部分,以此减少不必要的识别时间;对提取后的语音,进行语音延拓操作,在减少识别结果首尾出现漏字情况的同时,提高语音识别的性能。
[0079]
(1)语音提取
[0080]
语音提取将待识别语音转化成若干个仅包含说话声音的语音,其目的是去除待识别语音中不包含说话声音的部分,以此减少不必要的识别时间,提升识别效率;而且转化后的若干个语音,也为后续的语音延拓做了准备。
[0081]
本发明实施过程中,语音提取的具体方法如下:
[0082]
1)参见图2,将时长为la的待识别语音a以ls为单位时长进行分割,a末尾时长不足ls的部分直接忽略,每个分割后的语音称为切片,得到切片列表
[0083]
2)计算每个切片在a中对应的时间点,得到时间点列表计算公式如下:
[0084]
ti=(i-1)*ls[0085]
3)参见图3,将s中的切片从s1开始入队列至总容量为n的队列q中,每次入队列一个切片,如队列q已满,则先出队列一个切片。每个切片入队列成功后,使用语音活动检测(voice activity detection)算法判断该切片是否包含说话声音,如是则将该切片标记为voiced,反之标记为unvoiced。标记完后计算队列q中voiced切片的占比rv和unvoiced切片的占比ru,计算公式如下:
[0086][0087][0088]
4)重复步骤3),直至rv大于等于设定的阈值hs(例如大于等于0.3)时,将队列q中离队首最远的切片si对应的时间点ti作为一个说话声音起始时间点v;清空队列后继续重复步骤3),直至ru大于等于设定的阈值he(例如大于等于0.7)或最后一个切片进入队列时,将队列q中离队首最近的切片sj对应的时间点tj加上ls作为说话声音结束时间点u,并清空队列。v和u构成一个起始结束时间点对p=(v,u),对应着a中一段仅包含说话声音的语音;
[0089]
5)重复步骤4)直至最后一个切片进入队列,得到一系列的起始结束时间点对p={(v1,u1),(v2,u2),(v3,u3)
…
(vm,um)};m为正整数;
[0090]
6)按照p中的起始结束时间点对从a中提取出对应的仅包含说话声音的语音作为语音提取的结果{a1,a2,a3…am
},am为a中一段仅包含说话声音的语音。
[0091]
(2)语音延拓
[0092]
语音延拓是对语音提取后的结果进行动态批量填充(dynamicbatchpadding)操作,即将提取后的语音按照语音时长聚类分组,并在每一组语音的首尾填充人造数据,使得同一组中语音在填充后的长度都相同,其目的是减少识别结果首尾出现漏字的情况,同时将多个语音的时长填充至统一长度后,可利用语音识别模型的批处理能力同时对多个语音进行识别,以此提高语音识别的性能。
[0093]
本发明实施过程中,语音延拓的具体方法如下:
[0094]
1)对待识别语音的语音提取结果进行标记,标记内容为下列四项:
[0095]
①
原先待识别语音的编号(唯一标识该待识别语音的uuid);
[0096]
②
原先待识别语音提取后的语音数量;
[0097]
③
该提取后语音在原先待识别语音所有提取后语音中的时间顺序(以正整数表示,数值越小表示时间顺序越前);
[0098]
④
该提取后语音的时长;
[0099]
2)将标记后的语音入队列至一个总容量为m的队列中,每次入队列一条语音。只要当队列一满或者距上一次队列为空超过t时间时,将队列中所有的语音一次性出队列,并按1)中标记的时长信息用聚类算法将这些语音分为时长相近的k组;
[0100]
3)在每一组中,先获取该组中最长语音的时长,记为lg,然后在其余语音的首尾均匀的填充零值,直至时长为lg;
[0101]
4)将每一组填充好的语音作为一个批次输入语音识别模型进行识别(如该批次的语音数量超过语音识别模型的批处理上限,则将该批次按照上限数量分为若干个小的批次输入语音识别模型,例如批次大小为50,批处理上限为20,则将原批次拆分成大小分别为20,20,10的三个小批次输入语音识别模型)。
[0102]
(二)识别模型
[0103]
本发明实施过程中使用的语音识别模型,是一类端到端的语音识别模型。该类模型不同于传统语音识别系统中的发音字典、声学模型和语言模型,它只有输入端的语音特征和输出端的文本信息,能直接实现输入语音到输出文本的转化。语音识别模型从语音预处理模块接受语音进行识别,其识别结果是结果后处理模块的输入。
[0104]
其中,本实施例中,已训练好的语音识别模型指的是在开源语音数据集free st chinese mandarin corpus上训练的deepspeech2模型。
[0105]
(三)结果后处理模块
[0106]
结果后处理模块是对语音识别模型的输出结果进行处理,首先因为语音识别模型的输出是混乱的,因此需要对识别结果进行重组,然后利用“语音内容可预知”的特点,将重组后的结果修正为最相似的正确结果,以提高语音识别的性能。
[0107]
(1)识别结果重组
[0108]
语音识别模型的输入是待识别语音经过语音提取和语音延拓后的结果,一条待识别语音不再只对应一条识别结果,而是对应多条识别结果,因此需要对识别结果进行重组。
[0109]
本发明实施过程中,识别结果重组的具体方法如下:
[0110]
每一条识别结果都与语音延拓中的一条语音唯一对应,也唯一对应了一条标记信息,将对应标记信息中具有相同“原先待识别语音的编号”的识别结果分为一组,当同一组中的识别结果数量等于标记信息中的“原先待识别语音提取后的语音数量”后,按照标记信息中的“该提取后语音在原先待识别语音所有提取后语音中的时间顺序”进行排序,合并排序后的结果完成重组。
[0111]
(2)发音相似度匹配
[0112]
发音相似度匹配是利用“语音内容可预知”的特点,将识别结果重组后的结果与所有可预知的语音内容进行发音相似度的比较,若存在某一可预知的语音内容与其之间的相似度达到一定值,则将该可预知的语音内容作为最终结果输出,否则将其自身作为最终结果输出。
[0113]
发音相似度匹配的核心是计算两个文本之间的发音相似度。因为每个中文字符的
发音由声母、韵母和声调三部分组成,故本发明围绕声母、韵母和声调设计了一种相似距离d以衡量两个任意长度文本之间的发音相似度,d越小表示越相似,具体公式如下:
[0114][0115]
其中:
[0116]
d(w,w
′
)表示识别结果重组后的结果与任何一可预知的语音内容之间的相似距离;
[0117]
w表示识别结果重组后的结果,lw表示其所含字符个数;
[0118]w′
表示任何一可预知的语音内容,lw′
表示其所含字符个数;
[0119]
{ci|1≤i≤lw}表示组成w的所有字符;
[0120]
{c
′i|1≤i≤lw′
}表示组成w
′
的所有字符;
[0121]
为字符ci的拼音格式,分别表示声母,韵母和声调部分;
[0122]
为字符c
′i的拼音格式,分别表示声母,韵母和声调部分;
[0123]
z表示w中每个字符的拼音格式都按m
p
进行编码后的结果;
[0124]z′
表示w
′
中每个字符的拼音格式都按m
p
进行编码后的结果;
[0125]sp
表示声母之间和韵母之间的相似距离;
[0126]st
表示声调之间的相似距离;
[0127]
α,β,γ为权重系数;
[0128]
e表示z和z
′
的最小加权编辑距离;
[0129]
w,ci,和z的的一个示例如下:
[0130]
w:飞机;
[0131]
c1:飞,c2:机;
[0132]fē
i,j
ī
;
[0133]
f,j;
[0134]
ei,i;
[0135]
第一声,第二声;
[0136]
z:e04e31e49e12e27e49;
[0137]
本发明实施过程中,发音相似度匹配的具体方法如下:
[0138]
1)穷举所有可预知的语音内容,建立目标结果集w
′
;
[0139]
2)参见图4,依次用{"e01","e02"
…
"e52"}中的值作为23个声母,24个韵母和5种声调的编码值,建立拼音编码表m
p
;
[0140]
3)参见图5,设置基准权重δ,并根据2)中的拼音编码表m
p
建立替换权重矩阵ms。基准权重δ表示在计算最小加权编辑距离过程中删除或添加一个拼音编码的权重。替换权重矩阵ms中的值表示在计算最小加权编辑距离过程中替换对应两个拼音编码的权重。ms中值的设置以δ为基准,如果两个声母、两个韵母或两个声调之间的发音相似,则其对应拼音编
码的替换权重小于δ,反之则大于δ,并且声母和韵母之间,声母和音调之间,韵母和音调之间的替换权重远大于δ。例如,δ设置为50,声母“f”和“h”的发音相似,其对应拼音编码的替换权重设为20,小于50;声母“f”和“zh”的发音不相似,其对应拼音编码的替换权重设为80,大于50;“f”和“轻声”之间的替换权重设为300,远大于50;
[0141]
4)首先在w
′
中匹配是否存在与w完全一致的w
′
,如存在则直接输出w作为最终结果,并停止匹配过程,否则进入下一环节;
[0142]
5)将w依次与w
′
中含有字符个数相同的w
′
计算d(w,w
′
):使用dimsim(an accurate chinese phonetic similarity algorithm based on learned high dimensional encoding)中介绍的编码模型将和分别编码为两个m维的向量和同样的,将和也分别编码为两个m维的向量和将和按1、2、3、4和5分别表示轻声、第一声、第二声、第三声和第四声的方式进行编码得到和分别计算x
ii
与y
ii
,x
fi
与y
fi
之间的欧式距离作为和计算和的绝对差作为分别乘以对应的权重系数得到字符ci和c
′i的语音距离d(ci,c
′i),累加所有字符的语音距离得到d(w,w
′
),具体计算公式如下:
[0143][0144][0145][0146][0147]
其中,为向量中的第j个元素,为向量中的第j个元素,为向量中的第j个元素,为向量中的第j个元素;
[0148]
如d(w,w
′
)小于设定的阈值则直接输出w
′
作为最终结果,并停止匹配过程,否则进入下一环节;
[0149]
6)将w依次与w
′
中剩余的含有字符个数不同的w
′
计算d(w,w
′
):将w和w
′
中每个字符的拼音都按m
p
进行编码,得到两个编码字符串z=e1e2e3…ei
,ei∈{"e01","e02"
…
"e52"}和z
′
=e
′1e
′2e
′3…e′j,e
′j∈{"e01","e02"
…
"e52"},以mi,md和ms为权重矩阵计算z和z
′
的最小加权编辑距离e(ei,e
′j),具体计算公式如下:
[0150]
e(0,0)=0
[0151]
e(em,0)=e(e
m-1
,0)+δ 1<m≤i
[0152]
e(0,e
′n)=e(0,e
′
n-1
)+δ 1<n≤j
[0153][0154]
其中,e(0,0)表示两个空编码字符串之间的最小加权编辑距离,e(em,0)表示编码字符串e1e2e3…em
和空编码字符串之间的最小加权编辑距离(em是z中的第m个编码字符),e(e
m-1
,0)表示编码字符串e1e2e3…em-1
和空编码字符串之间的最小加权编辑距离(e
m-1
是z中的第m-1个编码字符),e(0,e
′n)表示空编码字符串和编码字符串e
′1e
′2e
′3…e′n之间的最小加权编辑距离(e
′n是z
′
中的第n个编码字符),e(0,e
′
n-1
)表示空编码字符串和编码字符串e
′1e
′2e
′3…e′
n-1
之间的最小加权编辑距离(e
′
n-1
是z
′
中的第n-1个编码字符),e(ei,e
′j)表示编码字符串e1e2e3…ei
和e
′1e
′2e
′3…e′j的最小加权编辑距离,e(e
i-1
,e
′j)表示编码字符串e1e2e3…ei-1
和e
′1e
′2e
′3…e′j的最小加权编辑距离,e(ei,e
′
j-1
)表示编码字符串e1e2e3…ei
和e
′1e
′2e
′3…e′
j-1
的最小加权编辑距离,e(e
i-1
,e
′
j-1
)表示编码字符串e1e2e3…ei-1
和e
′1e
′2e
′3…e′
j-1
的最小加权编辑距离,ms[ei,e
′j]表示取替换权重矩阵中对应拼音编码ei和e
′j的替换权重;
[0155]
如d(w,w
′
)小于设定的阈值则直接输出w
′
作为最终结果,并停止匹配过程,否则以w作为最终结果输出。
[0156]
本发明不重新训练模型,通过预处理和后处理,提升语音识别的效果,对短时语音尤为合适;利用数据标记和聚类,在程序运行过程中完成了动态批量填充。
[0157]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,所述计算机可读记录介质包括用于以计算机(例如计算机)可读的形式存储或传送信息的任何机制。
[0158]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1