一种语音交互方法及终端与流程
本技术涉及人机交互领域,尤其涉及一种语音交互方法及终端。
背景技术:
1、在语音交互过程中,终端拾取用户的语音,采用自动语音识别(automatic speechrecognition,asr)技术将用户的语音转换为文字,然后采用自然语言理解(naturallanguage understanding,nlu)技术对转换后的文字进行意图识别,再执行该意图对应的技能,并向用户回复执行结果。
2、可以理解的是,在终端真实的处理过程中,可能存在多种情况造成终端最终没有执行相应的技能。例如:终端未识别出用户的意图;或者,终端已识别出用户的意图,但终端并不支持执行该意图对应的技能等。然而,针对终端最终没有执行用户的意图对应的技能的情况,目前终端全部给出统一的“听不懂”回复,会给用户造成语音回复不准确、不自然、不智能的感受,造成用户的语音交互体验不佳。
技术实现思路
1、本技术提供的一种语音交互方法及终端,可以区分更多的场景,并基于不同的场景给出不同的响应方式,提升受话人识别结果的准确性,以及使得语音系统回复更加自然和智能。
2、为了实现上述目的,本技术实施例提供了以下技术方案:
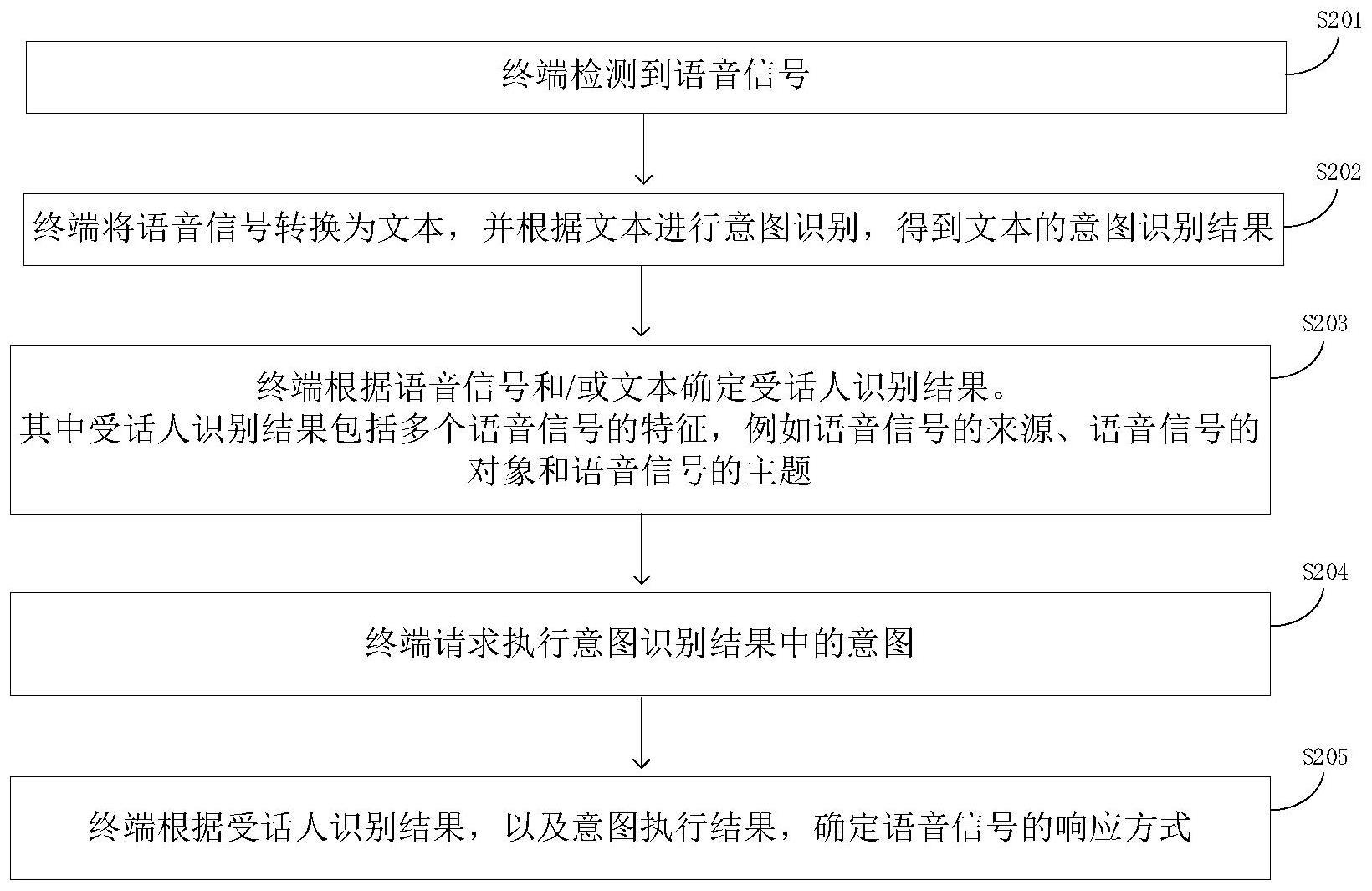
3、第一方面、提供一种语音交互方法,该方法包括:检测到语音信号;将语音信号转换为文本,并对文本进行意图识别,得到意图识别结果;根据语音信号、文本、意图识别结果中的一项或多项,确定受话人识别结果,受话人识别结果包括语音信号的来源、对象和主题;根据受话人识别结果,以及意图执行结果,确定语音信号的响应方式。
4、其中,语音信号的来源包括用户、扬声器或电子设备、环境中一项;语音信号的对象包括语音系统、用户、环境中一项;语音信号的主题包括任务或无意义。可选的,任务还包括:执行类任务、闲聊任务、百科类任务、方言类任务中一项或多项。
5、可选的,任务还可以包括方言类任务。另一些示例中,还可以根据用户的情感将任务划分为不同情感对应的任务,例如,兴奋的情感对应的播放欢快类音乐的任务;紧张的情感对应播放舒缓类的轻音乐的任务等。
6、其中,意图执行结果包括成功执行意图和未成功执行意图。需要说明的是,一些示例中,这里的意图执行结果可以是终端请求执行意图识别结果中的意图后,终端自身已执行该意图的结果;或者,终端请求其他设备执行该意图后,其他设备向该终端反馈的执行结果。也就是说,在终端确定语音信号的响应方式之前,该意图已经执行。另一些示例中,这里的意图执行结果也可以终端根据意图判断自身或者其他设备(如服务器)是否支持执行该意图对应的技能,该判断结果即为意图执行结果。也就是说,在终端确定语音信号的响应方式之前,该意图没有被执行。
7、由此可见,受话人识别结果(语音的来源,对象和主题)有利于区分语音的不同场景,有利于提升拒绝识别场景(例如人人对话,电子设备播放声音、用户的自言自语等场景)的识别率。另外,基于不同场景,语音系统可以提供不同的响应方式,按照不同的播放模板播放不同的内容。例如,针对未成功执行意图的情况,语音系统可以通过受话人识别结果区分具体的情况,通过不同的播放内容向用户提供更多的信息,提升语音系统的交互的智能化,使得人机交互更加自然。
8、一种可能的实现方式中,根据受话人识别结果,以及意图执行结果,确定语音信号的响应方式,包括:当语音信号的来源为用户,语音信号的对象为语音系统,语音信号的主题为任务,意图识别执行结果为未成功执行意图时,发出第一提示,第一提示用于提示语音系统不支持执行语音信号的主题;第一提示包括语音信号的来源、语音信号的对象、以及语音信号的主题;或者,当语音信号的来源为用户,语音信号的对象为语音系统,语音信号的主题为无意义,意图识别执行结果为未成功执行意图时,发出第二提示;第二提示用于请求用户澄清,第一提示包括语音信号的来源、语音信号的对象、以及语音信号的主题;或者,当语音信号的来源为非用户,或者,语音信号的对象为非语音系统,确定不响应语音信号。
9、由此可见,提供几种不同场景下不同响应方式的具体实现。
10、一种可能的实现方式中,根据受话人识别结果,以及意图执行结果,确定语音信号的响应方式,包括:当语音信号的来源为用户,且语音信号的对象为另一个用户,语音信号的主题为闲聊任务时,发出第三提示,第三提示用于询问是否执行与语音信号关联的第一技能;或者,当语音信号的来源为用户,且语音信号的对象为空气,语音信号的主题为闲聊任务时,发出第四提示,第四提示用于询问是否执行与语音信号关联的第二技能;第二技能与第一技能相同或不同。
11、也就是说,语音系统可以加入两个用户的对话,实现人(用户1)-人(用户2)-机(语音系统)的智能交互,提升用户的语音交互。或者,语音系统还可以根据用户1和用户2的交谈内容,执行相关的技能。比如,用户1和用户2商量去某个旅游景点游玩,则语音系统可以询问是否需要查询该旅游景点的天气、车票、旅游攻略等信息。
12、语音系统还可以在用户的自言自语的场景中进行插话。例如,当语音系统接收到的语音来自用户1,但语音的对象为空气,语音信号的主题为闲聊任务,意图执行结果为未成功执行意图,则语音系统也可以进行插话。或者,语音系统还可以根据用户1闲聊的内容,询问是否执行相关的技能。
13、由此可见,当基于受话人识别结果(语音的来源,对象和主题)区分出细分的场景后,语音系统可以提供更加丰富的功能,提升了语音系统的人机交互的智能化。
14、一种可能的实现方式中,根据受话人识别结果,以及意图执行结果,确定语音信号的响应方式,包括:基于预设规则,查询受话人识别结果以及意图执行结果对应的响应方式;规则中受话人识别结果或意图执行结果不同时,对应的响应方式不同;或者,将受话人识别结果以及意图执行结果输入到预先训练好的响应模型中进行推理,得到语音信号的响应方式。
15、由此提供了两种实现基于不同受话人结果和意图执行结果,实现不同响应方式的具体方法。
16、一种可能的实现方式中,根据语音信号、文本、意图识别结果中的一项或多项,确定受话人识别结果,包括:将语音信号输入到语音识别模型中进行推理,得到语音信号对应的对话分类,对话分类包括人人对话、人机对话、电子音、噪声和未知声音中的一项;将文本输入到文本识别模型中进行推理,得到语音信号的来源初值、语音信号的对象初值、以及语音信号的主题初值;将语音信号对应的对话分类、语音信号的来源初值、语音信号的对象初值、以及语音信号的主题初值输入到第一集成学习模型中进行推理,得到语音信号的来源、语音信号的对象、以及语音信号的主题。由此提供了一种受话人识别方法的具体实现。
17、一种可能的实现方式中,根据语音信号、文本、意图识别结果中的一项或多项,确定受话人识别结果,还包括:将语音信号输入到语音识别模型中进行推理,得到语音信号对应的对话分类,对话分类包括人人对话、人机对话、电子音、噪声和未知声音中的多项;将文本输入到文本识别模型中进行推理,得到语音信号的来源初值、语音信号的对象初值、以及语音信号的主题初值;根据意图执行结果中文本对应的各个意图的概率分布,映射为文本的有意图的概率和无意图的概率;将文本的有意图的概率和无意图的概率,语音信号对应的对话分类、语音信号的来源初值、语音信号的对象初值、以及语音信号的主题初值输入到第二集成学习模型中进行推理,得到语音信号的来源、语音信号的对象、以及语音信号的主题。由此提供了又一种受话人识别方法的具体实现。
18、第二方面、提供一种终端,包括:处理器、存储器和触摸屏,所述存储器、所述触摸屏与所述处理器耦合,所述存储器用于存储计算机程序代码,所述计算机程序代码包括计算机指令,当所述处理器从所述存储器中读取所述计算机指令,使得终端执行如上述方面及其中任一种可能的实现方式中所述的方法。第三方面、提供一种装置,该装置包含在终端中,该装置具有实现上述方面及可能的实现方式中任一方法中终端行为的功能。该功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。硬件或软件包括至少一个与上述功能相对应的模块或单元。例如,接收模块或单元、显示模块或单元、以及处理模块或单元等。
19、第四方面、提供一种计算机可读存储介质,包括计算机指令,当计算机指令在终端上运行时,使得终端执行如上述方面及其中任一种可能的实现方式中所述的方法。
20、第五方面、提供一种语音交互系统,所述语音系统包括一个或多个处理单元,当所述一个或多个处理单元执行指令时,所述一个或多个处理单元执行如上述方面及其中任一种可能的实现方式中所述的方法。
21、第六方面、提供一种计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行如上述方面中及其中任一种可能的实现方式中所述的方法。
22、第七方面、提供一种芯片系统,包括处理器,当处理器执行指令时,处理器执行如上述方面中及其中任一种可能的实现方式中所述的方法。
23、上述第二方面提供的终端、第三方面提供的装置、第四方面提供的计算机可读存储介质、第五方面提供的语音交互系统、第六方面提供的计算机程序产品以及第七方面提供的芯片系统所能达到的技术效果可以参考第一方面以及其中任一种可能的实现方式中关于技术效果的描述,这里不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!