一种工程化实现自然语义处理的方法、装置、设备及系统与流程
1.本发明涉及语音技术领域,尤其涉及一种工程化实现自然语义处理的方法、装置、终端设备及系统。
背景技术:
2.随着汽车技术的快速发展,用户与汽车之间基于自然语音进行对话的人机交互方式也得到了不断发展,这种人机语音交互方式使得用户在无需手动操作的情况下,就能够轻松完成各种控制和操作,从而提高了驾驶安全性及驾驶乐趣。
3.在人机语音交互过程中,对用户向车上的语音助手或者人工智能助手发出的语音指令进行语音识别,是其中的重要一环,因为语音识别结果关系到语音指令是否能够准确执行。但是,现有的语音识别方案一般仅能适用于特定车型或特定引擎,当应用于其他车型或其他引擎时,可能无法保证语音指令执行结果的准确性。
技术实现要素:
4.本发明实施例的目的在于,提供一种工程化实现自然语义处理的方法、装置、终端设备及系统,能够适用于不同车型、不同引擎,提高方案的自适应性,保证语音指令执行结果的准确性。
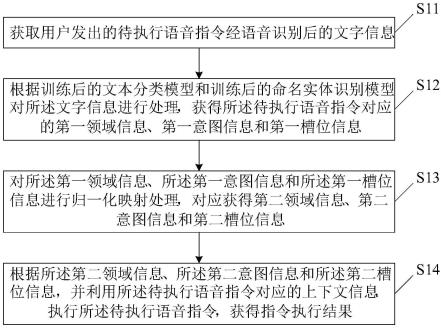
5.为了实现上述目的,本发明实施例提供了一种工程化实现自然语义处理的方法,包括:
6.获取用户发出的待执行语音指令经语音识别后的文字信息;
7.根据训练后的文本分类模型和训练后的命名实体识别模型对所述文字信息进行处理,获得所述待执行语音指令对应的第一领域信息、第一意图信息和第一槽位信息;
8.对所述第一领域信息、所述第一意图信息和所述第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息;
9.根据所述第二领域信息、所述第二意图信息和所述第二槽位信息,并利用所述待执行语音指令对应的上下文信息,执行所述待执行语音指令,获得指令执行结果。
10.进一步地,所述方法通过以下步骤获得所述训练后的文本分类模型和所述训练后的命名实体识别模型:
11.生成文本分类语料、命名实体识别语料、词向量文件、目标向量文件和停用词文件;
12.根据所述文本分类语料、所述词向量文件和所述停用词文件,对预设的文本分类模型进行训练,获得所述训练后的文本分类模型;
13.根据所述命名实体识别语料、所述目标向量文件和所述停用词文件,对预设的命名实体识别模型进行训练,获得训练后的命名实体识别模型。
14.进一步地,所述方法通过以下步骤生成所述文本分类语料和所述命名实体识别语料:
15.基于jsgf规则,增加rule引用、grammar引用和若干个基础规则,形成 hgf规则;
16.对基于hgf规则的hgf语法表达式进行语法解析,获得所述文本分类语料和所述命名实体识别语料;其中,所述文本分类语料中包括至少一个hgf语法表达式所对应的至少一条指令,所述命名实体识别语料中包括至少一个hgf 语法表达式所对应的至少一条指令。
17.进一步地,所述方法还包括:
18.对于每一个hgf语法表达式,当同一个hgf语法表达式所对应的指令的数量大于预设数量阈值时,将同一个hgf语法表达式所对应的指令按照8:1:1 的比例添加到模型训练的训练集、测试集和开发集中;
19.对于每一个hgf语法表达式,当同一个hgf语法表达式所对应的指令的数量不大于预设数量阈值时,将同一个hgf语法表达式所对应的指令全部添加到模型训练的训练集中。
20.进一步地,所述根据所述文本分类语料、所述词向量文件和所述停用词文件,对预设的文本分类模型进行训练,获得所述训练后的文本分类模型,具体包括:
21.将所述文本分类语料、所述词向量文件和所述停用词文件划分为训练集、开发集和测试集;
22.根据所述训练集、所述开发集和所述测试集对所述预设的文本分类模型进行训练,获得第一文本分类模型;
23.获取训练过程中生成的模型文件,并根据所述模型文件进行模型预测,获得预测结果;
24.当所述预测结果中存在异常预测结果时,将所述异常预测结果添加到所述训练集中,获得添加后的训练集;
25.根据所述添加后的训练集、所述开发集和所述测试集对所述第一文本分类模型进行训练及迭代,获得所述训练后的文本分类模型。
26.进一步地,每一个语料集中均包括至少一条基于预设的向量映射规则进行映射获得的固定格式指令;其中,所述语料集包括所述训练集、所述开发集和所述测试集;每一条固定格式指令均由目标部分和内容部分组成,所述目标部分包含用户语音指令的领域信息、意图信息和置信度,所述内容部分包含用户语音指令的指令信息。
27.进一步地,所述方法还包括:
28.基于里程碑管理不同模型的不同版本;
29.当在里程碑中构建新模型版本时,设置所述新模型版本对应的领域和意图;
30.当用户语音指令中包含版本信息时,查找所述版本信息对应的模型,并根据找到的模型对用户语音指令进行预测,获得指令预测结果。
31.为了实现上述目的,本发明实施例还提供了一种工程化实现自然语义处理的装置,用于实现上述任一项所述的工程化实现自然语义处理的方法,所述装置包括:
32.文字信息获取模块,用于获取用户发出的待执行语音指令经语音识别后的文字信息;
33.文字语义理解模块,用于根据训练后的文本分类模型和训练后的命名实体识别模型对所述文字信息进行处理,获得所述待执行语音指令对应的第一领域信息、第一意图信息和第一槽位信息;
34.归一化处理模块,用于对所述第一领域信息、所述第一意图信息和所述第一槽位
信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息;
35.语音指令执行模块,用于根据所述第二领域信息、所述第二意图信息和所述第二槽位信息,并利用所述待执行语音指令对应的上下文信息,执行所述待执行语音指令,获得指令执行结果。
36.本发明实施例还提供了一种终端设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现上述任一项所述的工程化实现自然语义处理的方法。
37.本发明实施例还提供了一种工程化实现自然语义处理的系统,所述系统包括车端和云端;其中,
38.所述车端,用于接收用户发出的待执行语音指令,对所述待执行语音指令进行语音识别,获得文字信息,并将所述文字信息上传到所述云端;
39.所述云端,用于根据所述文字信息实现上述任一项所述的工程化实现自然语义处理的方法,获得指令执行结果,并将所述指令执行结果发送至所述车端;
40.所述车端,还用于根据所述指令执行结果形成语音信息,并播报所述语音信息。
41.与现有技术相比,本发明实施例提供了一种工程化实现自然语义处理的方法、装置、终端设备及系统,通过获取用户发出的待执行语音指令经语音识别后的文字信息,并根据训练后的文本分类模型和训练后的命名实体识别模型对所述文字信息进行处理,获得所述待执行语音指令对应的第一领域信息、第一意图信息和第一槽位信息,对所述第一领域信息、所述第一意图信息和所述第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息,以及根据所述第二领域信息、所述第二意图信息和所述第二槽位信息,并利用所述待执行语音指令对应的上下文信息,执行所述待执行语音指令,获得指令执行结果,从而能够适用于不同车型、不同引擎的自然语义处理,提高方案的自适应性,保证语音指令执行结果的准确性。
附图说明
42.图1是本发明提供的一种工程化实现自然语义处理的方法的一个优选实施例的流程图;
43.图2是本发明实施例提供的一种生成文本分类语料和命名实体识别语料的示例图;
44.图3是本发明实施例提供的一种语料分片的示例图;
45.图4是本发明实施例提供的一种对语料进行向量映射的示例图;
46.图5是本发明提供的一种工程化实现自然语义处理的装置的一个优选实施例的结构框图;
47.图6是本发明提供的一种终端设备的一个优选实施例的结构框图;
48.图7是本发明提供的一种工程化实现自然语义处理的系统的一个优选实施例的结构框图。
具体实施方式
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本技术领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
50.本发明实施例提供了一种工程化实现自然语义处理的方法,参见图1所示,是本发明提供的一种工程化实现自然语义处理的方法的一个优选实施例的流程图,所述方法包括步骤s11至步骤s14:
51.步骤s11、获取用户发出的待执行语音指令经语音识别后的文字信息;
52.步骤s12、根据训练后的文本分类模型和训练后的命名实体识别模型对所述文字信息进行处理,获得所述待执行语音指令对应的第一领域信息、第一意图信息和第一槽位信息;
53.步骤s13、对所述第一领域信息、所述第一意图信息和所述第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息;
54.步骤s14、根据所述第二领域信息、所述第二意图信息和所述第二槽位信息,并利用所述待执行语音指令对应的上下文信息,执行所述待执行语音指令,获得指令执行结果。
55.在用户发出待执行语音指令之后,通过对待执行语音指令进行语音识别处理,可以将待执行语音指令识别成具体的文字信息,因此,本发明实施例在具体实施时,首先,获取用户发出的待执行语音指令所对应的文字信息,以便于后续直接对文字信息进行处理;接着,将获得的文字信息作为模型输入以进行语义识别,相应的,可以根据训练后的文本分类模型对获得的文字信息进行识别处理,相应获得待执行语音指令所对应的第一领域信息和第一意图信息,以及,根据训练后的命名实体识别模型对获得的文字信息进行名称实体抽取处理,相应获得待执行语音指令所对应的第一槽位信息;然后,对获得的待执行语音指令所对应的第一领域信息、第一意图信息和第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息,以通过归一化 mapping脚本处理,将第一领域信息、第一意图信息和第一槽位信息对应映射成统一定义的第二领域信息、第二意图信息和第二槽位信息,从而达到适配多车型、多引擎的目的;最后,根据映射获得的第二领域信息、第二意图信息和第二槽位信息,并利用待执行语音指令及其对应的上下文信息,执行待执行语音指令,相应获得指令执行结果。
56.需要说明的是,语义识别结果一般包括领域(domain)、意图(intent)和槽位(slot)等信息,通过对用户语音指令进行语义识别,能够基于领域、意图和槽位等信息准确分析用户意图,以便更好地控制用户语音指令的执行,并且通过利用文本分类模型和命名实体识别模型实现语义识别,能够使预测响应更快并优化槽位抽取。
57.本发明实施例所提供的一种工程化实现自然语义处理的方法,通过获取用户发出的待执行语音指令经语音识别后的文字信息,并根据训练后的文本分类模型和训练后的命名实体识别模型对文字信息进行处理,获得待执行语音指令对应的第一领域信息、第一意图信息和第一槽位信息,对第一领域信息、第一意图信息和第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息,以及根据第二领域信息、第二意图信息和第二槽位信息,并利用待执行语音指令对应的上下文信息,执行待执行语音指令,获得指令执行结果,从而能够适用于不同车型、不同引擎的自然语义处理,提高方案的自适应性,保证语音指令执行结果的准确性。
58.在另一个优选实施例中,所述方法通过以下步骤获得所述训练后的文本分类模型和所述训练后的命名实体识别模型:
59.生成文本分类语料、命名实体识别语料、词向量文件、目标向量文件和停用词文件;
60.根据所述文本分类语料、所述词向量文件和所述停用词文件,对预设的文本分类模型进行训练,获得所述训练后的文本分类模型;
61.根据所述命名实体识别语料、所述目标向量文件和所述停用词文件,对预设的命名实体识别模型进行训练,获得训练后的命名实体识别模型。
62.具体的,结合上述实施例,在根据文本分类模型和命名实体识别模型对获得的文字信息进行语义识别处理时,所使用的模型为预先训练好的模型,而在获取训练后的文本分类模型和训练后的命名实体识别模型时,先生成文本分类语料、命名实体识别语料(即ner语料)、词向量文件、目标向量文件和停用词文件;再根据生成的文本分类语料、词向量文件和停用词文件,对预设的文本分类模型(即未训练的文本分类模型)进行训练,相应获得训练后的文本分类模型,以及,根据生成的命名实体识别语料、目标向量文件和停用词文件,对预设的命名实体识别模型(即未训练的命名实体识别模型)进行训练,相应获得训练后的命名实体识别模型。
63.需要说明的是,词向量文件和目标向量文件可以利用向量文件生成器进行生成,将预先准备好的词向量和目标向量输入向量文件生成器,即可由向量文件生成器对应生成词向量文件和目标向量文件;停用词文件可以利用停用词文件生成器进行生成,将预先准备好的停用词输入停用词文件生成器,即可由停用词文件生成器对应生成停用词文件。
64.作为上述方案的改进,所述方法通过以下步骤生成所述文本分类语料和所述命名实体识别语料:
65.基于jsgf规则,增加rule引用、grammar引用和若干个基础规则,形成 hgf规则;
66.对基于hgf规则的hgf语法表达式进行语法解析,获得所述文本分类语料和所述命名实体识别语料;其中,所述文本分类语料中包括至少一个hgf语法表达式所对应的至少一条指令,所述命名实体识别语料中包括至少一个hgf 语法表达式所对应的至少一条指令。
67.具体的,结合上述实施例,在获取文本分类语料和命名实体识别语料时,可以先在jsgf(java speech grammar format,java语音语法格式)规则的基础上进行优化及扩展,增加自定义的rule引用、递归的grammar引用和若干个基础规则(例如,[]可选,()必选,{@}标注等基础规则),相应形成hgf语法规则;再基于hgf语法规则准备各领域所对应的hgf语法表达式,通过对hgf 语法表达式进行语法解析,相应获得文本分类语料和命名实体识别语料;其中,每一个领域下的每一个意图均包含至少一个hgf语法表达式,获得的文本分类语料中包括至少一个hgf语法表达式所对应的至少一条指令,获得的命名实体识别语料中包括至少一个hgf语法表达式所对应的至少一条指令。
[0068]
需要说明的是,文本分类语料和命名实体识别语料可以利用hgf语法解析器进行生成,将预先准备好的hgf语法表达式输入hgf语法解析器,即可由hgf语法解析器对应生成文本分类语料和命名实体识别语料;其中,hgf语法表达式经过hgf语法解析器后,会全量枚举出hgf语法表达式所对应的所有指令,生成语料文件并绑定hgf语法表达式后,存储在文件系统中。
[0069]
此外,还可以通过反向语料查询器通过查询任一指令所对应的hgf语法表达式,从而定位到该指令所对应的领域、意图以及里程碑信息,用于排查模型训练时语料集的问题。
[0070]
示例性的,参见图2所示,是本发明实施例提供的一种生成文本分类语料和命名实体识别语料的示例图,图2左边所示为一个hgf语法表达式,经过 hgf语法解析器进行解析后,枚举出该hgf语法表达式所对应的所有指令(所有组合方式),对应生成图2右边所示的该hgf语法表达式所对应的文本分类语料和ner语料。
[0071]
本发明实施例所提供的一种工程化实现自然语义处理的方法,基于hgf规则批量生成文本分类语料和命名实体识别语料,能够自动化生成语料,并且更好地训练模型的泛化能力。
[0072]
作为上述方案的改进,所述方法还包括:
[0073]
对于每一个hgf语法表达式,当同一个hgf语法表达式所对应的指令的数量大于预设数量阈值时,将同一个hgf语法表达式所对应的指令按照8:1:1 的比例添加到模型训练的训练集、测试集和开发集中;
[0074]
对于每一个hgf语法表达式,当同一个hgf语法表达式所对应的指令的数量不大于预设数量阈值时,将同一个hgf语法表达式所对应的指令全部添加到模型训练的训练集中。
[0075]
具体的,结合上述实施例,每一个hgf语法表达式在经过语法解析生成语料时,同一个hgf语法表达式所对应的指令的数量为至少一条,而在利用生成的语料进行模型训练时,需要提供模型训练的训练集、测试集和开发集,这三个语料集内的语料数量的比例一般为8:1:1,因此,针对每一个hgf语法表达式,如果同一个hgf语法表达式所对应的指令的数量大于预设数量阈值,则将同一个hgf语法表达式所对应的指令按照8:1:1的比例对应添加到模型训练的训练集、测试集和开发集中;如果同一个hgf语法表达式所对应的指令的数量不大于预设数量阈值,则将同一个hgf语法表达式所对应的指令全部添加到模型训练的训练集中。
[0076]
示例性的,参见图3所示,是本发明实施例提供的一种语料分片的示例图,假设hgf表达式a所对应的指令条数足够多,具体包括指令n+1、指令n+2、指令n+3、指令n+4、指令n+5、指令n+6、指令n+7、指令n+8、指令n+9和指令n+10,则按照8:1:1的比例进行语料分片,将指令n+1、指令n+2、指令n+3、指令n+4、指令n+5、指令n+6、指令n+7和指令n+8对应添加到训练集中,将指令n+9对应添加到测试集中,将指令n+10对应添加到开发集中;假设hgf 表达式b所对应的指令条数较少,具体包括指令n+1、指令n+2、指令n+3、指令n+4、指令n+5、指令n+6、指令n+7、指令n+8和指令n+9,则直接将指令 n+1、指令n+2、指令n+3、指令n+4、指令n+5、指令n+6、指令n+7、指令n+8 和指令n+9全部优先添加到训练集中。
[0077]
在又一个优选实施例中,所述根据所述文本分类语料、所述词向量文件和所述停用词文件,对预设的文本分类模型进行训练,获得所述训练后的文本分类模型,具体包括:
[0078]
将所述文本分类语料、所述词向量文件和所述停用词文件划分为训练集、开发集和测试集;
[0079]
根据所述训练集、所述开发集和所述测试集对所述预设的文本分类模型进行训练,获得第一文本分类模型;
[0080]
获取训练过程中生成的模型文件,并根据所述模型文件进行模型预测,获得预测结果;
[0081]
当所述预测结果中存在异常预测结果时,将所述异常预测结果添加到所述训练集中,获得添加后的训练集;
[0082]
根据所述添加后的训练集、所述开发集和所述测试集对所述第一文本分类模型进行训练及迭代,获得所述训练后的文本分类模型。
[0083]
具体的,结合上述实施例,在根据生成的文本分类语料、词向量文件和停用词文件,对预设的文本分类模型(即未训练的文本分类模型)进行训练时,可以先将生成的文本分类语料、词向量文件和停用词文件划分为训练集、开发集和测试集,并根据训练集、开发集和测试集对预设的文本分类模型进行训练,相应获得第一文本分类模型;再获取模型训练过程中生成的模型文件,并加载模型文件,以根据模型文件进行模型预测,相应获得预测结果,当获得的预测结果中存在异常预测结果(例如识别错误的语音指令)时,将异常预测结果添加到训练集中作为训练语料,相应获得添加后的训练集,以根据添加后的训练集、开发集和测试集再次对获得的第一文本分类模型进行训练及迭代,相应获得训练后的文本分类模型。
[0084]
可以理解的,在根据生成的命名实体识别语料、目标向量文件和停用词文件,对预设的命名实体识别模型(即未训练的命名实体识别模型)进行训练,相应获得训练后的命名实体识别模型时,具体的训练过程与文本分类模型的训练过程原理相同,这里不再赘述。
[0085]
本发明实施例所提供的一种工程化实现自然语义处理的方法,通过提供异常处理逻辑,将识别错误的质量自动进入模型训练并迭代,从而能够优化模型,提高模型预测的准确率。
[0086]
作为上述方案的改进,每一个语料集中均包括至少一条基于预设的向量映射规则进行映射获得的固定格式指令;其中,所述语料集包括所述训练集、所述开发集和所述测试集;每一条固定格式指令均由目标部分和内容部分组成,所述目标部分包含用户语音指令的领域信息、意图信息和置信度,所述内容部分包含用户语音指令的指令信息。
[0087]
具体的,结合上述实施例,在利用生成的语料集(即训练集、开发集和测试集)进行文本分类模型训练时,每一个语料集中的每一条语料(即每一条指令)均为基于预设的向量映射规则进行映射获得的固定格式指令,也就是说,每一个语料集中包含多条固定格式指令,并且固定格式指令与固定格式指令之间通过回车键进行分割。
[0088]
针对每一条固定格式指令,均由目标部分和内容部分这两部分组成,并且目标target和内容contents之间通过空格进行间隔,目标target中包含用户语音指令的领域信息、意图信息和置信度,内容contents中包含用户语音指令的指令信息。
[0089]
需要说明的是,目标target的长度为13byte,分别由6byte的领域编码、 6byte的意图编码以及1byte的置信度标识组成;针对置信度标识,当固定格式指令所属的语料集为训练集或测试集时,由于训练集和测试集中的指令为人工确认的领域和意图,因此,该固定格式指令的置信度标识可以设置为1,表示可信;当固定格式指令所属的语料集为预测集时,该固定格式指令的置信度标识默认为0,表示不可信,并且在经过模型预测之后返回相应的结果可信度,如果可信度达到一定的可信阈值,则将该固定格式指令的置信度标识修改为1。
[0090]
示例性的,参见图4所示,是本发明实施例提供的一种对语料进行向量映射的示例图,目标target的长度为13byte,包括6byte的领域domain(例如, 000001:多媒体域)、
6byte的意图intent(例如000001:播放歌手歌曲)以及 1byte的置信度(1:可信,0:不可信),内容contents的长度不固定,可以根据用户语音指令的实际内容进行设置,则,经过向量映射获得的固定格式指令示例可以为:
[0091]
0000010000010播放周某某的歌曲
[0092]
0000010000020播放周某某的专辑
[0093]
本发明实施例所提供的一种工程化实现自然语义处理的方法,通过对语料集中的语料进行自定义向量映射,能够在模型训练过程中便于模型训练以及对模型预测结果进行解析。
[0094]
在又一个优选实施例中,所述方法还包括:
[0095]
基于里程碑管理不同模型的不同版本;
[0096]
当在里程碑中构建新模型版本时,设置所述新模型版本对应的领域和意图;
[0097]
当用户语音指令中包含版本信息时,查找所述版本信息对应的模型,并根据找到的模型对用户语音指令进行预测,获得指令预测结果。
[0098]
具体的,结合上述实施例,本发明实施例还采用里程碑管理不同模型的不同版本,每一个模型均具有对应的领域和意图(例如,领域:车空域,意图:打开车门、打开车窗、
······
;领域:多媒体域,意图:播放歌曲名、播放歌手名、
······
;);当在里程碑中构建新模型版本时,可以指定该新模型版本所对应的领域和意图,相应的,在对新模型版本进行训练时,可以先获取新模型版本对应的领域、意图下的所有的hgf语法表达式,并根据这些hgf语法表达式生成训练集、测试集等语料集,再根据语料集对新模型版本进行训练;当根据模型对用户语音指令进行预测时,如果用户语音指令中包含版本信息,则可以根据版本信息查找相对应的模型,找到版本信息相对应的模型后,加载该模型,以根据该模型对用户语音指令进行预测,相应获得指令预测结果并输出。
[0099]
本发明实施例所提供的一种工程化实现自然语义处理的方法,基于里程碑管理多版本模型,可以实现快速迭代以及快速验证模型。
[0100]
本发明实施例还提供了一种工程化实现自然语义处理的装置,用于实现上述任一实施例所述的工程化实现自然语义处理的方法,参见图5所示,是本发明提供的一种工程化实现自然语义处理的装置的一个优选实施例的结构框图,所述装置包括:
[0101]
文字信息获取模块11,用于获取用户发出的待执行语音指令经语音识别后的文字信息;
[0102]
文字语义理解模块12,用于根据训练后的文本分类模型和训练后的命名实体识别模型对所述文字信息进行处理,获得所述待执行语音指令对应的第一领域信息、第一意图信息和第一槽位信息;
[0103]
归一化处理模块13,用于对所述第一领域信息、所述第一意图信息和所述第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息;
[0104]
语音指令执行模块14,用于根据所述第二领域信息、所述第二意图信息和所述第二槽位信息,并利用所述待执行语音指令对应的上下文信息,执行所述待执行语音指令,获得指令执行结果。
[0105]
优选地,所述装置还包括模型获取模块,用于通过以下步骤获得所述训练后的文本分类模型和所述训练后的命名实体识别模型:
[0106]
生成文本分类语料、命名实体识别语料、词向量文件、目标向量文件和停用词文件;
[0107]
根据所述文本分类语料、所述词向量文件和所述停用词文件,对预设的文本分类模型进行训练,获得所述训练后的文本分类模型;
[0108]
根据所述命名实体识别语料、所述目标向量文件和所述停用词文件,对预设的命名实体识别模型进行训练,获得训练后的命名实体识别模型。
[0109]
优选地,所述模型获取模块用于通过以下步骤生成所述文本分类语料和所述命名实体识别语料:
[0110]
基于jsgf规则,增加rule引用、grammar引用和若干个基础规则,形成 hgf规则;
[0111]
对基于hgf规则的hgf语法表达式进行语法解析,获得所述文本分类语料和所述命名实体识别语料;其中,所述文本分类语料中包括至少一个hgf语法表达式所对应的至少一条指令,所述命名实体识别语料中包括至少一个hgf 语法表达式所对应的至少一条指令。
[0112]
优选地,所述装置还包括语料分片模块,用于:
[0113]
对于每一个hgf语法表达式,当同一个hgf语法表达式所对应的指令的数量大于预设数量阈值时,将同一个hgf语法表达式所对应的指令按照8:1:1 的比例添加到模型训练的训练集、测试集和开发集中;
[0114]
对于每一个hgf语法表达式,当同一个hgf语法表达式所对应的指令的数量不大于预设数量阈值时,将同一个hgf语法表达式所对应的指令全部添加到模型训练的训练集中。
[0115]
优选地,所述模型获取模块根据所述文本分类语料、所述词向量文件和所述停用词文件,对预设的文本分类模型进行训练,获得所述训练后的文本分类模型,具体包括:
[0116]
将所述文本分类语料、所述词向量文件和所述停用词文件划分为训练集、开发集和测试集;
[0117]
根据所述训练集、所述开发集和所述测试集对所述预设的文本分类模型进行训练,获得第一文本分类模型;
[0118]
获取训练过程中生成的模型文件,并根据所述模型文件进行模型预测,获得预测结果;
[0119]
当所述预测结果中存在异常预测结果时,将所述异常预测结果添加到所述训练集中,获得添加后的训练集;
[0120]
根据所述添加后的训练集、所述开发集和所述测试集对所述第一文本分类模型进行训练及迭代,获得所述训练后的文本分类模型。
[0121]
优选地,每一个语料集中均包括至少一条基于预设的向量映射规则进行映射获得的固定格式指令;其中,所述语料集包括所述训练集、所述开发集和所述测试集;每一条固定格式指令均由目标部分和内容部分组成,所述目标部分包含用户语音指令的领域信息、意图信息和置信度,所述内容部分包含用户语音指令的指令信息。
[0122]
优选地,所述装置还包括里程碑管理模块,用于:
[0123]
基于里程碑管理不同模型的不同版本;
[0124]
当在里程碑中构建新模型版本时,设置所述新模型版本对应的领域和意图;
[0125]
当用户语音指令中包含版本信息时,查找所述版本信息对应的模型,并根据找到的模型对用户语音指令进行预测,获得指令预测结果。
[0126]
需要说明的是,本发明实施例所提供的一种工程化实现自然语义处理的装置,能够实现上述任一实施例所述的工程化实现自然语义处理的方法的所有流程,装置中的各个模块的作用以及实现的技术效果分别与上述实施例所述的工程化实现自然语义处理的方法的作用以及实现的技术效果对应相同,这里不再赘述。
[0127]
本发明实施例还提供了一种终端设备,参见图6所示,是本发明提供的一种终端设备的一个优选实施例的结构框图,所述终端设备包括处理器10、存储器20以及存储在所述存储器20中且被配置为由所述处理器10执行的计算机程序,所述处理器10在执行所述计算机程序时实现上述任一实施例所述的工程化实现自然语义处理的方法。
[0128]
优选地,所述计算机程序可以被分割成一个或多个模块/单元(如计算机程序1、计算机程序2、
······
),所述一个或者多个模块/单元被存储在所述存储器 20中,并由所述处理器10执行,以完成本发明。所述一个或多个模块/单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述所述计算机程序在所述终端设备中的执行过程。
[0129]
所述处理器10可以是中央处理单元(central processing unit,cpu),还可以是其他通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application specific integrated circuit,asic)、现场可编程门阵列 (field-programmable gate array,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,通用处理器可以是微处理器,或者所述处理器10也可以是任何常规的处理器,所述处理器10是所述终端设备的控制中心,利用各种接口和线路连接所述终端设备的各个部分。
[0130]
所述存储器20主要包括程序存储区和数据存储区,其中,程序存储区可存储操作系统、至少一个功能所需的应用程序等,数据存储区可存储相关数据等。此外,所述存储器20可以是高速随机存取存储器,还可以是非易失性存储器,例如插接式硬盘,智能存储卡(smart media card,smc)、安全数字(secure digital, sd)卡和闪存卡(flash card)等,或所述存储器20也可以是其他易失性固态存储器件。
[0131]
需要说明的是,上述终端设备可包括,但不仅限于,处理器、存储器,本领域技术人员可以理解,图6结构框图仅仅是上述终端设备的示例,并不构成对终端设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件。
[0132]
本发明实施例还提供了一种工程化实现自然语义处理的系统,参见图7所示,是本发明提供的一种工程化实现自然语义处理的系统的一个优选实施例的结构框图,所述系统包括车端和云端;其中,
[0133]
所述车端,用于接收用户发出的待执行语音指令,对所述待执行语音指令进行语音识别,获得文字信息,并将所述文字信息上传到所述云端;
[0134]
所述云端,用于根据所述文字信息实现上述任一实施例所述的工程化实现自然语义处理的方法,获得指令执行结果,并将所述指令执行结果发送至所述车端;
[0135]
所述车端,还用于根据所述指令执行结果形成语音信息,并播报所述语音信息。
[0136]
具体的,车端用于接收用户发出待执行语音指令,并在接收到待执行语音指令之后,对待执行语音指令进行语音识别处理,相应获得待执行语音指令所对应的文字信息,并将待执行语音指令所对应的文字信息上传到云端;云端用于接收车端上传的待执行语音指
令所对应的文字信息,并在获得待执行语音指令所对应的文字信息之后,先根据训练后的文本分类模型对获得的文字信息进行识别处理,相应获得待执行语音指令所对应的第一领域信息和第一意图信息,以及,根据训练后的命名实体识别模型对获得的文字信息进行名称实体抽取处理,相应获得待执行语音指令所对应的第一槽位信息,并对获得的待执行语音指令所对应的第一领域信息、第一意图信息和第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息,再根据映射获得的第二领域信息、第二意图信息和第二槽位信息,结合待执行语音指令及其对应的上下文信息,执行待执行语音指令,相应获得指令执行结果,并将指令执行结果发送至车端;车端用于接收云端发送的指令执行结果,并在接收到指令执行结果之后,根据指令执行结果形成语音信息,并播报语音信息。
[0137]
需要说明的是,车端在接收到用户发出的待执行语音指令之后,可以通过 asr(automatic speech recognition,自动语音识别)模块对待执行语音指令进行语音识别处理,相应获得待执行语音指令所对应的文字信息,并将待执行语音指令所对应的文字信息通过云端的语音多引擎网关模块上传到云端;云端根据车型、版本信息等信息将文字信息路由到指定的nlu(natural languageunderstanding,自然语言理解)模块进行语义识别,相应获得待执行语音指令所对应的第一领域信息、第一意图信息和第一槽位信息,之后,通过归一化mapping 模块对第一领域信息、第一意图信息和第一槽位信息进行归一化映射处理,映射后的第二领域信息、第二意图信息和第二槽位信息进入dm(dialogmanagement,对话管理)模块,在dm模块中,包含用户对话的上下文信息,则根据待执行语音指令及上下文信息,执行待执行语音指令,相应获得指令执行结果,云端将指令执行结果通过语音多引擎网关模块发送至车端;车端在接收到云端发送的指令执行结果之后,通过tts(text to speech,从文本到语音) 模块将指令执行结果转换成语音信息并播报。
[0138]
综上,本发明实施例所提供的一种工程化实现自然语义处理的方法、装置、终端设备及系统,通过获取用户发出的待执行语音指令经语音识别后的文字信息,并根据训练后的文本分类模型和训练后的命名实体识别模型对文字信息进行处理,获得待执行语音指令对应的第一领域信息、第一意图信息和第一槽位信息,对第一领域信息、第一意图信息和第一槽位信息进行归一化映射处理,对应获得第二领域信息、第二意图信息和第二槽位信息,以及根据第二领域信息、第二意图信息和第二槽位信息,并利用待执行语音指令对应的上下文信息,执行待执行语音指令,获得指令执行结果,从而能够适用于不同车型、不同引擎的自然语义处理,提高方案的自适应性,保证语音指令执行结果的准确性。
[0139]
此外,本发明实施例以工程化的方向,基于hgf规则批量生成文本分类语料和命名实体识别语料,能够自动化生成语料,并且更好地训练模型的泛化能力;通过提供异常处理逻辑,将识别错误的质量自动进入模型训练并迭代,从而能够优化模型,提高模型预测的准确率;通过对语料集中的语料进行自定义向量映射,能够在模型训练过程中便于模型训练以及对模型预测结果进行解析;通过基于里程碑管理多版本模型,可以实现快速迭代以及快速验证模型;从而将复杂的模型算法以工程化的思想进行优化和解决,最终提供了由语义规则到指令预测的整体工程化的自然语义识别方案。
[0140]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形
也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1