一种基于深度学习的语义端点检测系统的制作方法
1.本发明属于语义端点检测领域,具体是一种基于深度学习的语义端点检测系统。
背景技术:
2.语音端点检测指的是在有环境噪声的情况下,从语音信号中确定语音的起始点和结束点的位置的操作。语音端点检测是语音识别领域中一个重要内容,是语音信号处理的第一步。
3.目前,语音端点检测的研究方法主要有三类:基于声学特征的方法、无监督方法和有监督方法。这三类方法,都是基于语音的端点检测,通过对语音的能量以及有效音频的建模,检测出有效语音片段的起始点,通过静音时长判断有效语音片段的停止点。
4.但是,人机交互场景中,不同用户说话断句习惯的不同会导致不同对话的后端点静音时延不一致,对于语速慢、停顿多的用户可能会导致语音片段不完整的问题;对于用户明确表达“等等”、“我看一下”、“稍等一下”的情况,依靠语音端点检测无法理解用户需要等待的需求;对于单号收集、地址收集等场景,用户常常在回复的时候,需要思考或者是查询相关信息才能继续回复,如果这个时候依靠语音端点检测结果将用户打断,会导致信息片段收集不完整、人机交互体验差等问题。
5.因此,本发明提出了一种基于深度学习的语义端点检测系统,在语音端点检测的基础上引入语义端点检测技术。
技术实现要素:
6.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种基于深度学习的语义端点检测系统,该基于深度学习的语义端点检测系统解决了现有技术中语音端点检测不准的问题。
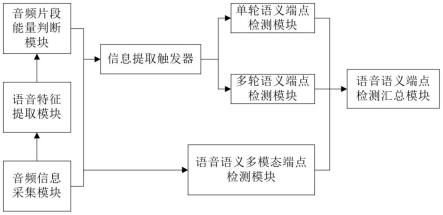
7.为实现上述目的,根据本发明的第一方面的实施例提出一种基于深度学习的语义端点检测系统,包括:音频信息采集模块、语音特征提取模块、音频片段能量判断模块、信息提取触发器、单轮语义端点检测模块、多轮语义端点检测模块、语音语义多模态端点检测模块以及语音语义端点检测汇总模块;
8.所述音频信息采集模块用于从语音对话中采集音频信息,并将音频信息发送至所述语音特征提取模块和所述语音语义多模态端点检测模块;
9.所述语音特征提取模块用于对接收的音频信息中的语音特征进行提取;所述语音特征提取模块将提取的语音特征发送至所述音频片段能量判断模块;
10.所述音频片段能量判断模块用于对接收到的语音特征的有效音频段进行检测获取,所述音频片段能量判断模块还将检测获取到的有效音频段进行实时声学模型解码获得解码文本,所述音频片段能量判断模块将获得的解码文本发送至所述信息提取触发器和所述语音语义多模态端点检测模块;
11.所述信息提取触发器用于对接收到的解码文本的语义端点场景类型进行判断,其
中语义端点场景类型分为单轮语义端点场景和多轮语义端点场景;所述信息提取触发器根据解码文本的语义端点场景类型的判断结果将解码文本发送至单轮语义端点检测模块或多轮语义端点检测模块;
12.所述单轮语义端点检测模块用于对单轮语义端点场景的解码文本进行检测并获取基于文本的单轮语义端点检测结果,所述单轮语义端点检测模块将获取的基于文本的单轮语义端点检测结果发送至语音语义端点检测汇总模块;
13.所述多轮语义端点检测模块用于对多轮语义端点场景的解码文本进行检测并获取基于文本的多轮语义端点检测结果,所述多轮语义端点检测模块将获取的基于文本的多轮语义端点检测结果发送至语音语义端点检测汇总模块;
14.所述语音语义多模态端点检测模块用于对接收到的音频信息和解码文本进行检测并获取基于多模态的语音语义端点检测结果,并发送至所述语音语义端点检测汇总模块;
15.所述语音语义端点检测汇总模块用于对获取的基于文本的单轮语义端点检测结果、基于文本的多轮语义端点检测结果以及基于多模态的语音语义端点检测结果进行融合得到最终的端点检测结果。
16.进一步地,所述单轮语义端点检测模块或所述多轮语义端点检测模块包括语义匹配端点检测子模块和基于预训练的深度学习语义端点分类子模块;
17.语义匹配端点检测子模块包括关键字树模糊匹配单元、正则匹配单元以及句子困惑度单元。
18.进一步地,采用句子困惑度单元对句子的完整性进行检测,具体步骤如下:
19.步骤a1:收集大量的对话文本,包括开源的对话数据集合和从业务获取并清洗的对话数据;使用对话文本对n-gram语言模型进行训练;
20.步骤a2:使用n-gram语言模型对句子进行困惑度进行计算,设定阈值t,当句子困惑度小于t时,判定该句子为完整的;反之,当句子困惑度大于t时,判定该句子为不完整的。
21.进一步地,基于预训练的深度学习语义端点分类子模块对对话文本进行检测,即使用基于预训练的bert模型进行语义端点分类,将语义端点检测任务转化为语义分类的任务,语义分类的任务包括语义端点和语义非端点两类;具体方法步骤如下:
22.步骤b1:从网络中获取开源的对话数据集,对获取的对话数据集进行清洗融合,对bert模型进行预训练;
23.步骤b2:将语义端点的数据作为正例,将非语义端点的数据作为负例,根据正例和负例对对话数据集进行划分,从而进行分类任务的微调;使用同义词替换、回译、词向量替换以及句向量替换方式进行数据增强,并且使用对抗训练和对比学习方式隐式增加正样本的数量;使用分类和ner联合学习的方式对对话中命名实体识别的任务进行处理;
24.步骤b3:将训练好的bert模型作为老师模型,通过不断学习教会一个学生模型,对该学生模型进行训练;根据老师模型计算处理的logits和学生模型计算处理的logits计算蒸馏损失,以及真实label产生的损失,最后将这两种损失作加权求和,得到总的损失。
25.进一步地,基于单轮语义端点检测模块根据用户表达的内在意思理解用户当前的话是否结束,判断为语义端点;对于特定的信息收集场景,信息没有收集全的情况下,判断为非语义端点,继续等待说话者,当收集完信息之后判断为语义端点。
26.进一步地,当检测到需要收集特定信息,直接进入多轮语义端点检测模块;当单轮语义端点检测模块已经判定当前对话为语义端点时,无论信息收集是否完毕都会判定当前对话为语义端点;当单轮语义端点检测模块检测到当前对话不是语义端点,但多轮语义端点检测模块没有收集到所有需要的信息时判定该轮为语义端点;当单轮语义端点检测模块检测到当前对话不是语义端点并且多轮语义端点检测模块已经收集到所有信息时判定当前对话为语义端点。
27.进一步地,单轮语义端点检测模块将单轮对话分别进行模糊查找树匹配、正则匹配、语句困惑度计算和基于预训练的bert模型预测,对于任何一项匹配到了就认为是语义端点,其他项查找停止。
28.进一步地,多轮语义端点检测模块具体检测步骤如下:
29.步骤c1:通过使用关键字树模糊匹配单元和正则匹配单元,从对话中提取关键字或信息,当出现关键词的时候,进入相应的信息收集场景,并且开始缓存对话,选取n轮对话,n大于等于1,作为后续模型的输入;
30.步骤c2:同步骤b1中收集相关语料,分别对bert模型和gpt2模型进行预训练;
31.步骤c3:将多轮语义端点检测模块分为encoding子模块和decoding子模块,其中encoding子模块为bert模型,将对话标记为dt,其中t表示对话轮数,将槽位的槽名称标记为[slot]i,其中i表示槽位的序号;输入前n轮对话d
t-n
…
dt,输入所有槽位的槽名称[slot]1…
[slot]i…
[slot]j,其中j表示槽位的总数;输出为单轮语义端点检测的结果和各个槽位的状态,其中各个槽位的状态为hold delete update dontcare;decoding子模块为gpt2模型,输入前n轮对话d
t-n
…
dt,输入需要update的槽名称,输出为update后的槽位值;分别对encoding子模块和decoding子模块进行训练,其中,encoding子模块对语义端点分类和槽值状态进行联合训练,decoding子模块对gpt2模型进行槽位值生成进行训练;
[0032]
步骤c4:同步骤b3对encoding子模块和decoding子模块进行模型蒸馏。
[0033]
进一步地,语音语义多模态端点检测模块采用encoder-decoder结构,编码端引入声学特征解码文本和语音特征编码,解码端输入融合上下文和语义完整性先验知识,获得语音端点词序列。
[0034]
与现有技术相比,本发明的有益效果是:
[0035]
本发明通过音频信息采集模块从语音对话中采集音频信息,语音特征提取模块从音频信息中提取语音特征,音频片段能量判断模块对语音特征中的有效音频段进行实时声学模型解码从而获得解码文本,信息提取触发器对解码文本的语义端点场景类型进行判断,根据义端点场景类型的判断结果将解码文本发送至单轮语义端点检测模块或多轮语义端点检测模块进行检测从而获取基于文本的语义端点检测结果,其中语音语义多模态端点检测模块对音频信息和解码文本进行检测并获取基于多模态的语音语义端点检测结果,最终语音语义端点检测汇总模块将基于文本的单轮语义端点检测结果、基于文本的多轮语义端点检测结果以及基于多模态的语音语义端点检测结果进行融合得到最终的端点检测结果。本发明在语音端点检测的基础上引入语义端点检测技术,解决现有语音端点检测不准的问题,提升人机交互体验;本发明在端点检测中,分别对单轮、多轮和序列化的对话进行语义分析,使端点检测不仅有语音的声学特征还同时具有语义特征,真正做到了智能化、拟人化的端点检测,极大提升了人机对话的流畅度和智能度。
附图说明
[0036]
图1为本发明的模块结构示意图。
具体实施方式
[0037]
下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0038]
如图1所示,一种基于深度学习的语义端点检测系统,包括:音频信息采集模块、语音特征提取模块、音频片段能量判断模块、信息提取触发器、单轮语义端点检测模块、多轮语义端点检测模块、语音语义多模态端点检测模块以及语音语义端点检测汇总模块;
[0039]
所述音频信息采集模块用于从语音对话中采集音频信息,所述音频信息采集模块将采集到的音频信息发送至所述语音特征提取模块和所述语音语义多模态端点检测模块;
[0040]
所述语音特征提取模块用于对接收的音频信息中的语音特征进行提取;所述语音特征提取模块将提取的语音特征发送至所述音频片段能量判断模块;
[0041]
所述音频片段能量判断模块用于对接收到的语音特征的有效音频段进行检测获取,所述音频片段能量判断模块还将检测获取到的有效音频段进行实时声学模型解码获得解码文本,所述音频片段能量判断模块将获得的解码文本发送至所述信息提取触发器和所述语音语义多模态端点检测模块;
[0042]
所述信息提取触发器用于对接收到的解码文本的语义端点场景类型进行判断,其中语义端点场景类型分为单轮语义端点场景和多轮语义端点场景;所述信息提取触发器根据解码文本的语义端点场景类型的判断结果将解码文本发送至单轮语义端点检测模块或多轮语义端点检测模块;
[0043]
所述单轮语义端点检测模块用于对单轮语义端点场景的解码文本进行检测并获取基于文本的单轮语义端点检测结果,所述单轮语义端点检测模块将获取的基于文本的单轮语义端点检测结果发送至语音语义端点检测汇总模块;
[0044]
所述多轮语义端点检测模块用于对多轮语义端点场景的解码文本进行检测并获取基于文本的多轮语义端点检测结果,所述多轮语义端点检测模块将获取的基于文本的多轮语义端点检测结果发送至语音语义端点检测汇总模块;
[0045]
所述单轮语义端点检测模块或所述多轮语义端点检测模块包括语义匹配端点检测子模块和基于预训练的深度学习语义端点分类子模块;
[0046]
所述语音语义多模态端点检测模块用于对接收到的音频信息和解码文本进行检测并获取基于多模态的语音语义端点检测结果,并发送至所述语音语义端点检测汇总模块;
[0047]
所述语音语义端点检测汇总模块用于对获取的基于文本的单轮语义端点检测结果、基于文本的多轮语义端点检测结果以及基于多模态的语音语义端点检测结果进行融合得到最终的端点检测结果。
[0048]
基于以上技术特征,本发明的一个实施例中,一种基于深度学习的语义端点检测系统的语义端点检测方法如下:
[0049]
步骤一:所述音频信息采集模块从语音对话中获取音频信息,所述音频信息采集模块将采集到的音频信息发送至所述语音特征提取模块和语音语义多模态端点检测模块;
[0050]
步骤二:所述语音特征提取模块对接收到的音频信息进行语音特征提取,并将提取到的语音特征发送至所述音频片段能量判断模块;
[0051]
步骤三:所述音频片段能量判断模块对接收到的语音特征的有效音频段进行检测获取,所述音频片段能量判断模块还将检测获取到的有效音频段进行实时声学模型解码获得解码文本,所述音频片段能量判断模块将获得的解码文本发送至所述信息提取触发器和语音语义多模态端点检测模块;
[0052]
步骤四:所述信息提取触发器对接收到的解码文本的语义端点场景类型进行判断;
[0053]
若信息提取触发器判断出解码文本为单轮语义端点场景,则信息提取触发器将解码文本发送至单轮语义端点检测模块;单轮语义端点检测模块对解码文本进行检测并获取基于文本的单轮语义端点检测结果,所述单轮语义端点检测模块将获取的基于文本的单轮语义端点检测结果发送至语音语义端点检测汇总模块;
[0054]
若信息提取触发器判断出解码文件为多轮语义端点场景,则信息提取触发器将解码文本发送至多轮语义端点检测模块;多轮语义端点检测模块对解码文本进行检测并获取基于文本的多轮语义端点检测结果,所述多轮语义端点检测模块将获取的基于文本的多轮语义端点检测结果发送至语音语义端点检测汇总模块;
[0055]
步骤五:所述语音语义多模态端点检测模块对接收到的音频信息和解码文本进行检测并获取基于多模态的语音语义端点检测结果,并发送至所述语音语义端点检测汇总模块;
[0056]
步骤六:所述语音语义端点检测汇总模块对获取的基于文本的单轮语义端点检测结果、基于文本的多轮语义端点检测结果以及基于多模态的语音语义端点检测结果进行融合得到最终的端点检测结果。
[0057]
需要说明的是,传统的端点检测只是基于语音层面的语音端点检测,虽然模型层面由基于特征提取发展到无监督端点检测,再发展到有监督语音端点检测,使得语音端点检测在有噪声的情况下识别率大大提高;特征层面对一系列特征进行融合,如:能量、谱熵、多谱带、倒谱距离、mfcc特征、长时特征ltsv、teager能量算子等,进一步提升了在有噪状态下的识别准确率和鲁棒性,并且具有了对清辅音和浊辅音的追踪能力;但是,终归到底这些方法都是基于语音层面的,提取语音相关特征,对端点进行检测;可是对于
“…
请等一下”、
“…
我看一下”、
“…
我想想”、
“…
我正在停车”等这些对话,语音端点检测是没有办法理解说话人的意思,会将该类对话判定为端点,但实际情况下,这种情况需要等待说话者;所以基于上述情况,本实施例中使用基于单轮语义端点检测模块对解码文本进行端点检测。
[0058]
需要说明的是,所述单轮语义端点检测模块或所述多轮语义端点检测模块包括语义匹配端点检测子模块和基于预训练的深度学习语义端点分类子模块;
[0059]
在本实施例中,语义匹配端点检测子模块主要包括关键字树模糊匹配单元、正则匹配单元以及句子困惑度单元;
[0060]
由语音对话转写为解码文本时会产生转写错误的情况,如发音不清楚、方言较重以及说话环境嘈杂;本实施例采用基于拼音和方言的模糊匹配,构建基于关键词、拼音和方
言的混合查询树,即关键字树模糊匹配单元,大大改善匹配的准确率和鲁棒性;
[0061]
针对语义不完整的情况,如
“……
我的地址是武”,采用句子困惑度单元对句子的完整性进行检测,句子困惑度是衡量语言模型好坏的一个指标,语言模型比较擅长根据句子的前一个词计算出下一个词在词表上的分布,句子的困惑度表示句子的混乱度,它表征了一个句子符合语法的程度,困惑度越小句子完整性越好,在本实施例中可以用于快速的检测语句的完整性;具体步骤如下:
[0062]
步骤a1:收集大量的对话文本,包括开源的对话数据集合和从业务获取并清洗的对话数据;使用对话文本对n-gram语言模型进行训练;
[0063]
步骤a2:使用n-gram语言模型对句子进行困惑度进行计算,设定阈值t,当句子困惑度小于t时,判定该句子为完整的,即该点是语义端点;反之,当句子困惑度大于t时,判定该句子为不完整的,即该点不是语义端点。
[0064]
针对一些没有明显关键词并且比较通顺的对话,语义匹配端点检测子模块并不适用,则选择基于预训练的深度学习语义端点分类子模块对其进行检测,在本实施例中,使用基于预训练的bert模型进行语义端点分类,将语义端点检测任务转化为语义分类的任务,语义分类的任务包括语义端点和语义非端点两类;具体方法步骤如下:
[0065]
步骤b1:从网络中获取开源的对话数据集,例如豆瓣多轮对话数据集、京东对话挑战赛数据集、淘宝客服对话数据集、ubuntu对话语料库等;对获取的对话数据集进行清洗融合,对bert模型进行预训练;
[0066]
步骤b2:将语义端点的数据作为正例,将非语义端点的数据作为负例,根据正例和负例对对话数据集进行划分,从而进行分类任务的微调;使用同义词替换、回译、词向量替换、句向量替换等方式进行数据增强,并且使用对抗训练、对比学习等方式隐式增加正样本的数量,提高分类的鲁棒性;同时,使用分类和ner联合学习的方式对客服对话中大量的命名实体识别的任务进行处理,充分利用已有先验知识,提高语义端点检测的准确率和鲁棒性;
[0067]
步骤b3:将训练好的bert模型作为老师模型,通过不断学习教会一个学生模型,其中学生模型通常为结构简单、参数少、推理速度快的模型;对该学生模型进行训练;根据老师模型计算处理的logits和学生模型计算处理的logits计算蒸馏损失,以及真实label产生的损失,最后将这两种损失作加权求和,得到总的损失;通过模型蒸馏获得的小模型,虽然在性能上有一些下降,但是推理速度大大提升;
[0068]
单轮语义端点检测模块将单轮对话分别进行模糊查找树匹配、正则匹配、语句困惑度计算和基于预训练的bert模型预测,对于任何一项匹配到了就认为是语义端点,其他项查找停止,从而节省计算资源。
[0069]
基于单轮语义端点检测模块可以根据用户表达的内在意思理解用户当前的话是否结束,判断为语义端点;对于特定的信息收集场景,如手机号收集、订单号收集、地址收集等,信息没有收集全的情况下,判断为非语义端点,继续等待说话者,当收集完信息之后判断为语义端点;如当客服询问“请问您的订单号是多少呢?(10位)”,用户回答“我的订单号是12345678”,从客服的询问中可以通过信息提取触发器提取出该对话进入了订单收集场景,即多轮语义完整性或称为多轮语义端点场景;开始进入多轮语义完整性端点检测,即进入多轮语义端点检测模块进行检测;用户的订单号显然还没有报完整,缺少两位,语义不完
整,所以这时判定为单轮语义端点,多轮语义完整性非端点,所以需要等待用户继续播报;具体方法步骤如下:
[0070]
步骤c1:通过使用关键字树模糊匹配单元和正则匹配单元,从对话中提取关键字或信息,如订单号、地址、手机号等,当出现关键词的时候,进入相应的信息收集场景,并且开始缓存对话,选取n轮对话,n大于等于1,作为后续模型的输入;
[0071]
步骤c2:同步骤b1中收集相关语料,分别对bert模型和gpt2模型进行预训练;
[0072]
步骤c3:将多轮语义端点检测模块分为encoding子模块和decoding子模块,其中encoding子模块为bert模型,将对话标记为dt,其中t表示对话轮数,将槽位的槽名称标记为[slot]i,其中i表示槽位的序号;输入前n轮对话d
t-n
…
dt,输入所有槽位的槽名称[slot]1…
[slot]i…
[slot]j,其中j表示槽位的总数;输出为单轮语义端点检测的结果和各个槽位的状态,其中各个槽位的状态为hold delete update dontcare;decoding子模块为gpt2模型,输入前n轮对话d
t-n
…
dt,输入需要update的槽名称,输出为update后的槽位值;分别对encoding子模块和decoding子模块进行训练,其中,encoding子模块对语义端点分类和槽值状态进行联合训练,decoding子模块对gpt2模型进行槽位值生成进行训练;
[0073]
步骤c4:同步骤b3对encoding子模块和decoding子模块进行模型蒸馏,以提升推理的速度;
[0074]
当检测到需要收集特定信息,直接进入多轮语义端点检测模块;当单轮语义端点检测模块已经判定该轮为语义端点时,无论信息收集是否完毕都会判定该轮为语义端点;当单轮语义端点检测模块检测到该轮不是语义端点,但多轮语义端点检测模块没有收集到所有需要的信息时判定该轮为语义端点;当单轮语义端点检测模块检测到该轮不是语义端点并且多轮语义端点检测模块已经收集到所有信息时判定该轮为语义端点。
[0075]
针对传统基于交叉熵建模端点检测的鲁棒性不足问题,本技术采用基于序列建模的语义端点检测技术,不再集中注意力于每一帧的语音/非语音段的有效性判断,而是基于整体文本序列来判断当前语音段的静音和语音段的区分,可以有效应对噪声干扰;本技术采用encoder-decoder结构,编码端引入声学特征解码文本和语音特征编码,解码端输入融合上下文和语义完整性先验知识,获得语音端点词序列;
[0076]
对于实时序列建模的语音信息,将语音作为原始输入,分别融合语音特征信息、语音转文字后的语义信息以及加入先验的知识特征信息,最终将融合多模态的特征实时传入decoding解码模块,然后输出实时的语音语义端点状态。
[0077]
最后应说明的是,以上实施例仅用以说明本发明的技术方法而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方法进行修改或等同替换,而不脱离本发明技术方法的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1