一种基于端到端模型的语音识别纠错方法与流程
1.本发明公开一种方法,涉及数据分析技术领域,具体地说是一种基于端到端模型的语音识别纠错方法。
背景技术:
2.近来,语音系统,比如语音协助和口语翻译系统的应用越来越广泛。此类系统通常使用asr系统将音频转换为文本,然后将其送至下游nlp任务。因此,下游的nlp任务极易受到上游asr系统的错误输出影响。如asr系统典型的错误有:字与字之间边界的错误分割,同音字、拼写错误等。但目前还没有快速有效方法对asr系统进行纠错,以便能输出正确语音识别文本。
技术实现要素:
3.本发明针对现有技术的问题,提供一种基于端到端模型的语音识别纠错方法,具有通用性强、实施简便等特点,具有广阔的应用前景。
4.本发明提出的具体方案是:
5.本发明提供一种基于端到端模型的语音识别纠错方法,建立预训练模型,其中分别通过asr模型和wav2vec2模型在人类语音数据集commonvoice上进行预测,生成含有错误的识别结果,并利用合成数据的方式,生成含有错误的数据结果,将含有错误的识别结果和含有错误的数据结果合成获得增强数据集,利用增强数据集和音素序列训练预训练模型,使预训练模型学习增强数据集和音素之间的对应关系,用于纠正词级别的错误和纠正音素级别的错误,
6.利用预训练模型对asr系统的语音去噪及纠错。
7.进一步,所述的一种基于端到端模型的语音识别纠错方法中采用ctc-attention混合结构,使用espnet工具箱获得所述asr模型。
8.进一步,所述的一种基于端到端模型的语音识别纠错方法中获得所述asr模型,包括:
9.bilstm层组成所述asr模型,所述asr模型包含vgg卷积层、编码器层、解码器层和相应通道。
10.进一步,所述的一种基于端到端模型的语音识别纠错方法中基于cmudict和音效工具包利用合成数据的方式根据自定义合成策略进行同音字词替换,生成含有错误的数据结果。
11.进一步,所述的一种基于端到端模型的语音识别纠错方法中使用音素转换工具g2p根据字素到音素生成所述音素序列。
12.本发明还提供一种基于端到端模型的语音识别纠错系统:模型训练模块和纠错模块,
13.模型训练模块建立预训练模型,其中分别通过asr模型和wav2vec2模型在人类语
音数据集commonvoice上进行预测,生成含有错误的识别结果,并利用合成数据的方式,生成含有错误的数据结果,将含有错误的识别结果和含有错误的数据结果合成获得增强数据集,利用增强数据集和音素序列训练预训练模型,使预训练模型学习增强数据集和音素之间的对应关系,用于纠正词级别的错误和纠正音素级别的错误,
14.纠错模块利用预训练模型对asr系统的语音去噪及纠错。
15.进一步,所述的一种基于端到端模型的语音识别纠错系统中模型训练模块采用ctc-attention混合结构,使用espnet工具箱获得所述asr模型。
16.进一步,所述的一种基于端到端模型的语音识别纠错系统中模型训练模块获得所述asr模型,包括:
17.bilstm层组成所述asr模型,所述asr模型包含vgg卷积层、编码器层、解码器层和相应通道。
18.进一步,所述的一种基于端到端模型的语音识别纠错系统中模型训练模块基于cmudict和音效工具包利用合成数据的方式根据自定义合成策略进行同音字词替换,生成含有错误的数据结果。
19.进一步,所述的一种基于端到端模型的语音识别纠错系统中模型训练模块使用音素转换工具g2p根据字素到音素生成所述音素序列。
20.本发明的有益之处是:
21.本发明提供一种基于端到端模型的语音识别纠错方法,通过可端到端的预训练模型对asr系统的语音去噪及纠错,不仅能够快速便捷的进行词级别的错误纠正,同时能够纠正音素级别的错误,有助于asr系统将音频转换为正确文本,输送给下游nlp任务。
附图说明
22.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
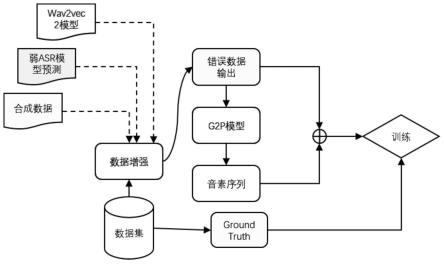
23.图1是本发明方法中预训练模型训练流程示意图。
具体实施方式
24.下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
25.本发明提供一种基于端到端模型的语音识别纠错方法,建立预训练模型,其中分别通过asr模型和wav2vec2模型在人类语音数据集commonvoice上进行预测,生成含有错误的识别结果,并利用合成数据的方式,生成含有错误的数据结果,将含有错误的识别结果和含有错误的数据结果合成获得增强数据集,利用增强数据集和音素序列训练预训练模型,使预训练模型学习增强数据集和音素之间的对应关系,用于纠正词级别的错误和纠正音素级别的错误,
26.利用预训练模型对asr系统的语音去噪及纠错。
27.本发明方法提出了一个端到端的预训练模型,既能去噪,又用来纠正语音和拼写
错误,保证下游nlp任务的顺利进行。
28.具体应用中,在本发明的一些实施例中,建立预训练模型时,分别通过asr模型和wav2vec2模型在人类语音数据集commonvoice上进行预测,生成含有错误的识别结果,
29.进一步地,所述的一种基于端到端模型的语音识别纠错方法中采用ctc-attention混合结构,使用espnet工具箱获得所述asr模型,bilstm层组成所述asr模型,所述asr模型包含包含2个vgg卷积层、3个编码器层(每层有1024个单元)、2个解码器层(每层有1024个单元)和基于位置的10通道等,通过asr模型在commonvoice数据上进行预测,生成有错的识别结果,这些包含错误的预测,作为增强数据集,将被用于微调端到端预训练模型。
30.并且为了识别一般asr模型可能会出现的潜在常见错误,可以利用wav2vec2模型对commonvoice进行预测,生成有错的识别结果,作为增强数据集,同样用于微调端到端预训练模型。
31.进一步,所述的一种基于端到端模型的语音识别纠错方法中基于cmudict和音效工具包利用合成数据的方式根据自定义合成策略进行同音字词替换,生成含有错误的数据结果,其中根据自定义合成策略进行同音字词替换,包括:对于每个字或词汇,获得同音字列表,并随机选择一个作为替换,生成含有错误的数据结果,将上述含有错误的识别结果和含有错误的数据结果合成获得增强数据集。
32.进一步,所述的一种基于端到端模型的语音识别纠错方法中使用音素转换工具g2p根据字素到音素生成所述音素序列,利用增强数据集和音素序列训练预训练模型,使预训练模型学习增强数据集和音素之间的对应关系,用于纠正词级别的错误和纠正音素级别的错误。
33.本发明还提供一种基于端到端模型的语音识别纠错系统:模型训练模块和纠错模块,
34.模型训练模块建立预训练模型,其中分别通过asr模型和wav2vec2模型在人类语音数据集commonvoice上进行预测,生成含有错误的识别结果,并利用合成数据的方式,生成含有错误的数据结果,将含有错误的识别结果和含有错误的数据结果合成获得增强数据集,利用增强数据集和音素序列训练预训练模型,使预训练模型学习增强数据集和音素之间的对应关系,用于纠正词级别的错误和纠正音素级别的错误,
35.纠错模块利用预训练模型对asr系统的语音去噪及纠错。
36.上述系统内的各模块之间的信息交互、执行过程等内容,由于与本发明方法实施例基于同一构思,具体内容可参见本发明方法实施例中的叙述,此处不再赘述。
37.同样地,本发明系统可以通过可端到端的预训练模型对asr系统的语音去噪及纠错,不仅能够快速便捷的进行词级别的错误纠正,同时能够纠正音素级别的错误,有助于asr系统将音频转换为正确文本,输送给下游nlp任务。
38.需要说明的是,上述各流程和各系统结构中不是所有的步骤和模块都是必须的,可以根据实际的需要忽略某些步骤或模块。各步骤的执行顺序不是固定的,可以根据需要进行调整。上述各实施例中描述的系统结构可以是物理结构,也可以是逻辑结构,即,有些模块可能由同一物理实体实现,或者,有些模块可能分由多个物理实体实现,或者,可以由多个独立设备中的某些部件共同实现。
39.以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1