语音分类模型的训练方法,语音分类方法及装置与流程
本技术涉及人工智能,尤其涉及一种语音分类模型的训练方法,语音分类方法及装置。
背景技术:
1、随着语音分类技术的发展,语音分类已经被广泛地应用于生活的各个领域,如多说话人语音分割聚类、从混合语音中提取目标语音等等,其中,多说话人语音分割聚类技术在音频自动转录、音频检索等领域应用十分广泛。
2、目前,相关技术中的多说话人语音分割聚类系统仅能够通过利用语音端点检测算法筛选出语音流中的有效语音片段,然后对有效语音片段进行说话人转折点检测,使得每个语音片段只包含一个单独的说话人。提取完语音片段后,对其进行说话人特征提取,并通过对特征打分对语音片段进行分类。
3、但是,相关技术中的说话人分类仅能够基于离线后的说话人日志系统,即整体会话全部结束后才能够对语音流中多个语音片段对应的说话人进行分类,无法实时完成语音流中多个语音片段对应的说话人的聚类,造成说话人日志系统冗余。
技术实现思路
1、本技术实施例提供了一种语音分类模型的训练方法,语音分类方法及装置,能够实时完成说话人的聚类,从而无需说话人日志系统保存大量的语音流,节省说话人日志系统的存储空间。
2、第一方面,本技术实施例提供了语音分类模型的训练方法,该方法包括:
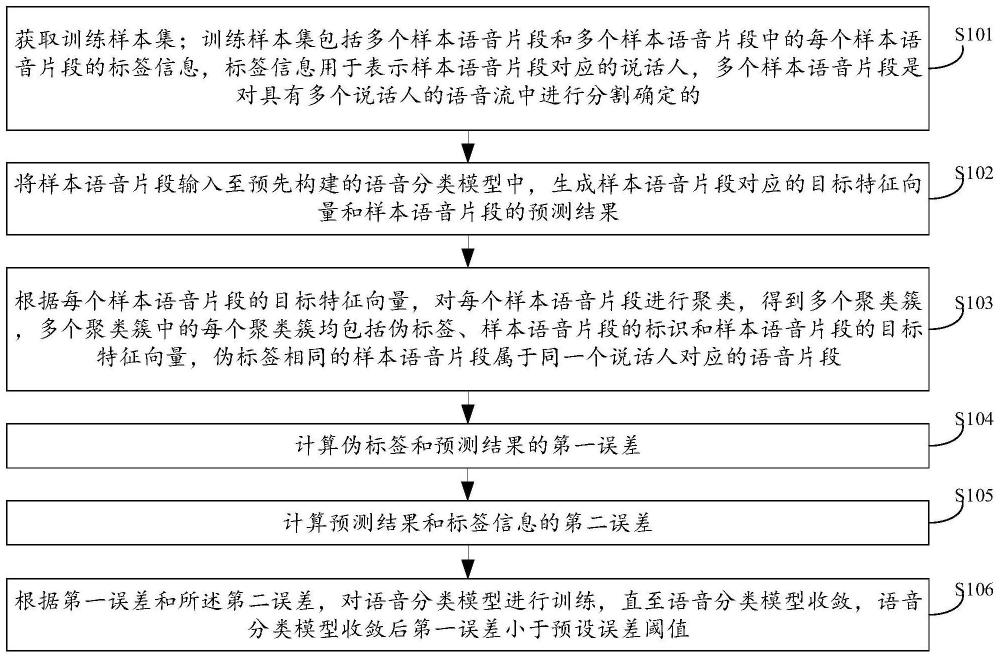
3、获取训练样本集;所述训练样本集包括多个样本语音片段和所述多个样本语音片段中的每个样本语音片段的标签信息,所述标签信息用于表示所述样本语音片段对应的说话人,所述多个样本语音片段是对具有多个说话人的语音流中进行分割确定的;
4、将所述每个样本语音片段输入至预先构建的语音分类模型中,生成所述每个样本语音片段对应的目标特征向量、所述样本语音片段的第一预测结果和所述样本语音片段的第二预测结果;
5、根据所述每个样本语音片段的目标特征向量,对所述每个样本语音片段进行聚类,得到多个聚类簇,所述多个聚类簇中的每个聚类簇均包括伪标签、样本语音片段的标识和所述样本语音片段的目标特征向量,所述伪标签相同的样本语音片段属于同一个说话人对应的语音片段;
6、计算所述伪标签和所述第一预测结果的第一误差;
7、计算所述第二预测结果和所述标签信息的第二误差;
8、根据所述第一误差和所述第二误差,对所述语音分类模型进行训练,直至所述语音分类模型收敛,所述语音分类模型收敛后所述第一误差小于预设误差阈值。
9、在一种可能的实现方式中,所述根据所述第一误差和所述第二误差,对所述语音分类模型进行训练,直至所述语音分类模型收敛:
10、对所述第一误差和所述第二误差进行加权求和,得到训练误差;
11、根据所述训练误差对所述语音分类模型进行训练,直至所述语音分类模型收敛。
12、在一种可能的实现方式中,根据所述每个样本语音片段的目标特征向量,对每个所述样本语音片段进行聚类,得到多个聚类簇,包括:
13、分别计算所述样本语音片段的目标特征向量和每个历史聚类簇对应的音频质心之间的相似度;其中,所述音频质心用于表示所述历史聚类簇中所有的目标特征向量的中心;
14、将所述样本语音片段分类至目标历史聚类簇中,所述目标历史聚类簇对应的音频质心与所述样本语音片段的目标特征向量之间的相似度大于预设阈值;
15、或基于所述样本语音片段的标识、所述样本语音片段的特征向量生成新的聚类簇,并生成所述新的聚类簇对应的伪标签,其中,所述样本语音片段的目标特征向量和每个历史聚类簇对应的音频质心之间的相似度均小于预设阈值。
16、在一种可能的实现方式中,在所述获取训练样本集之前,所述方法还包括:
17、获取具有多个说话人之间对话的语音流;
18、根据语音端点检测算法对所述语音流进行降噪处理,得到样本语音;
19、根据滑动窗对所述样本语音进行分割,得到所述多个样本语音片段。
20、在一种可能的实现方式中,所述方法还包括:
21、提取所述多个样本语音片段的梅尔频率倒谱系数(mel frequency cepstrumcoefficient,mfcc)特征向量;
22、所述将所述每个样本语音片段输入至预先构建的语音分类模型中,生成所述每个样本语音片段对应的目标特征向量、所述样本语音片段的第一预测结果和所述样本语音片段的第二预测结果,包括:
23、将所述每个样本语音片段的mfcc特征向量输入至所述语音分类模型中,得到所述每个样本语音片段对应的目标特征向量、所述样本语音片段的第一预测结果和所述样本语音片段的第二预测结果。
24、在一种可能的实现方式中,所述语音分类模型包括依次连接的多个时延神经网络层、多个长短期记忆人工神经网络层、统计层、句子全连接层和第一全连接层,所述语音分类模型中的句子全连接层还连接有第二全连接层;
25、所述将所述每个样本语音片段输入至预先构建的语音分类模型中,生成所述每个样本语音片段对应的特征向量、所述每个样本语音片段的第一预测结果和所述每个样本语音片段的第二预测结果,包括:
26、所述多个时延神经网络层基于所述每个样本语音片段,生成所述每个样本语音片段的第一特征向量,所述第一特征向量包括所述每个样本语音片段之间的上下文关系特征;
27、所述多个长短期记忆人工神经网络层基于所述每个样本语音片段的第一特征向量,所述每个样本语音片段的第二特征向量,所述第二特征向量包括所述每个样本语音片段之间的说话人转移关系特征;
28、所述统计层对所述每个样本语音片段的第二特征向量进行归一化处理,得到所述每个样本语音片段的第三特征向量;
29、所述句子全连接层对所述每个样本语音片段的第三特征向量降维处理,得到所述每个样本语音片段的第四特征向量;
30、所述第一全连接层根据所述每个样本语音片段的第四特征向量,生成所述每个样本语音片段的目标特征向量和所述每个样本语音片段的第一预测结果;
31、所述第二全连接层根据所述每个样本语音片段的第四特征向量,生成所述每个样本语音片段的第二预测结果。
32、第二方面,本技术实施例提供了一种语音分类方法,包括:
33、实时获取目标语音流,其中,所述目标语音流是由多个说话人对话形成的;
34、对所述目标语音流进行语音分割,得到多个语音片段;
35、将所述多个语音片段中的每个语音片段输入至如权利要求1-6中任一项权利要求中所述的语音分类模型中,生成所述多个语音片段的分类结果。
36、在一种可能的实现方式中,所述对所述目标语音流进行语音分割,得到多个语音片段,包括:
37、根据语音端点检测算法对所述目标语音流进行降噪处理,得到降噪后的目标语音流;
38、根据滑动窗对所述降噪后的目标语音流进行分割,得到所述多个样本语音片段。
39、在一种可能的实现方式中,在所述对所述目标语音流进行语音分割,得到多个语音片段之后,所述方法还包括:
40、提取所述多个语音片段的mfcc特征向量;
41、所述将所述多个语音片段中的每个语音片段输入第一方面或第一方面中任一种可能的实现方式中所述的语音分类模型中,生成所述多个语音片段的分类结果,包括:
42、将所述多个语音片段的mfcc特征向量输入至所述语音分类模型中,生成所述多个语音片段的分类结果。
43、第三方面,本技术实施例提供了一种语音分类模型的训练装置,包括:
44、获取模块,用于获取训练样本集;所述训练样本集包括多个样本语音片段和所述多个样本语音片段中的每个样本语音片段的标签信息,所述标签信息用于表示所述样本语音片段对应的说话人,所述多个样本语音片段是对具有多个说话人的语音流中进行分割确定的;
45、生成模块,用于将所述每个样本语音片段输入至预先构建的语音分类模型中,生成所述每个样本语音片段对应的目标特征向量、所述样本语音片段的第一预测结果和所述样本语音片段的第二预测结果;
46、聚类模块,用于根据每个所述样本语音片段的目标特征向量,对每个所述样本语音片段进行聚类,得到多个聚类簇,所述多个聚类簇中的每个聚类簇均包括伪标签、样本语音片段的标识和所述样本语音片段的目标特征向量;
47、计算模块,用于计算所述伪标签和所述第一预测结果的第一误差,以及计算所述第二预测结果和所述标签信息的第二误差;
48、训练模块,用于根据所述第一误差和所述第二误差,对所述语音分类模型进行训练,直至所述语音分类模型收敛,所述语音分类模型收敛后所述第一误差小于预设误差阈值。
49、在一种可能的实现方式中,聚类模块用于:
50、分别计算所述样本语音片段的目标特征向量和每个历史聚类簇对应的音频质心之间的相似度;其中,所述音频质心用于表示所述历史聚类簇中所有的目标特征向量的中心;
51、将所述样本语音片段分类至目标历史聚类簇中,所述目标历史聚类簇对应的音频质心与所述样本语音片段的目标特征向量之间的相似度大于预设阈值;
52、或基于所述样本语音片段的标识、所述样本语音片段的特征向量生成新的聚类簇,并生成所述新的聚类簇对应的伪标签,其中,所述样本语音片段的目标特征向量和每个历史聚类簇对应的音频质心之间的相似度均小于预设阈值。
53、在一种可能的实现方式中,所述获取模块还用于获取具有多个说话人之间对话的语音流;
54、所述装置还包括:
55、降噪模块,用于根据语音端点检测算法对所述语音流进行降噪处理,得到样本语音;
56、分割模块,用于根据滑动窗对所述样本语音进行分割,得到所述多个样本语音片段。
57、在一种可能的实现方式中,所述装置还包括:
58、提取模块,用于提取所述多个样本语音片段的梅尔频率倒谱系数mfcc特征向量;
59、所述生成模块用于将所述每个样本语音片段的mfcc特征向量输入至所述语音分类模型中,得到所述每个样本语音片段对应的目标特征向量、所述样本语音片段的第一预测结果和所述样本语音片段的第二预测结果。
60、在一种可能的实现方式中,所述生成包括语音分类模型和第二全连接层,所述语音分类模型包括依次连接的多个时延神经网络层、多个长短期记忆人工神经网络层、统计层、句子全连接层和第一全连接层,所述语音分类模型中的句子全连接层还连接有第二全连接层;
61、所述多个时延神经网络层基于所述每个样本语音片段,生成所述每个样本语音片段的第一特征向量,所述第一特征向量包括所述每个样本语音片段之间的上下文关系特征;
62、所述多个长短期记忆人工神经网络层基于所述每个样本语音片段的第一特征向量,所述每个样本语音片段的第二特征向量,所述第二特征向量包括所述每个样本语音片段之间的说话人转移关系特征;
63、所述统计层对所述每个样本语音片段的第二特征向量进行归一化处理,得到所述每个样本语音片段的第三特征向量;
64、所述句子全连接层对所述每个样本语音片段的第三特征向量降维处理,得到所述每个样本语音片段的第四特征向量;
65、所述第一全连接层根据所述每个样本语音片段的第四特征向量,生成所述每个样本语音片段的目标特征向量和所述每个样本语音片段的第一预测结果;
66、所述第二全连接层根据所述每个样本语音片段的第四特征向量,生成所述每个样本语音片段的第二预测结果。
67、第四方面,本技术实施例提供了一种语音分类装置,包括:
68、获取模块,用于实时获取目标语音流,其中,所述目标语音流是由多个说话人对话形成的;
69、分割模块,用于对所述目标语音流进行语音分割,得到多个语音片段;
70、分类模块,用于将所述多个语音片段中的每个语音片段输入至第一方面或第一方面中任一种可能的实现方式中所述的语音分类模型中,生成所述多个语音片段的分类结果。
71、在一种可能的实现方式中,所述分割模块用于:
72、根据语音端点检测算法对所述目标语音流进行降噪处理,得到降噪后的目标语音流;
73、根据滑动窗对所述降噪后的目标语音流进行分割,得到所述多个样本语音片段。
74、在一种可能的实现方式中,所述装置还包括提取模块,用于提取所述多个语音片段的mfcc特征向量;
75、所述生成模块用于将所述多个语音片段的mfcc特征向量输入至所述语音分类模型中,生成所述多个语音片段的分类结果。
76、第五方面,本技术实施例提供了一种计算机设备,包括处理器、存储器及存储在存储器上并可在处理器上运行的计算机程序,计算机程序被处理器执行时实现如上述第一方面或第一方面中任一种可能的实现方式中所提供的方法,或实现如上述第二方面所提供的方法。
77、第六方面,本技术实施例提供了一种计算机存储介质,计算机存储介质中存储有指令,当指令在计算机上运行时,使得计算机执行上述第一方面或第一方面中任一种可能的实现方式中所提供的方法,或实现如上述第二方面所提供的方法。
78、本技术实施例提供的语音分类模型的训练方法,语音分类方法及装置,通过具有多个说话人语音流获得的样本语音片段,并在训练过程中提取样本语音片段的目标特征向量,从而根据每个样本语音片段的目标特征向量对每个样本语音片段进行聚类,从而得到多个聚类簇,每个聚类簇均包括伪标签、样本语音片段的标识和所述样本语音片段的目标特征向量。每个聚类簇中的样本语音片段均属于同一个人说话时的语音片段。通过伪标签和预测结果之间的第一误差、标签信息和预测结果之间的第二误差对语音分类模型进行训练,从而得到训练好的语音分类模型。如此,在训练过程中基于预先构建的语音分类模型提取的样本语音片段的目标特征向量进行聚类,使得训练好的语音分类模型具备聚类的功能,从而能够提高分类的精准度,从而无需后续在对语音分类模型生成的分类结果进行聚类,也无需在整体会话全部结束后才能够对语音流中多个语音片段对应的说话人进行聚类,本技术实施例提供的语音分类模型能够实时完成语音流中多个语音片段对应的说话人的聚类,避免说话人日志系统冗余。
- 还没有人留言评论。精彩留言会获得点赞!