号码状态识别方法及装置、计算机可读存储介质、终端与流程
1.本发明实施例涉及号码状态识别技术领域,尤其涉及一种号码状态识别方法及装置、计算机可读存储介质、终端。
背景技术:
2.在一些场景中,有时需要对电话号码状态进行识别,以确认电话号码的号码状态是否处于正常状态。其中,电话号码的号码状态通常包括空号、停机、关机、正常接通等。
3.在一些应用场景中,需要在用户无感知的情况下判断号码状态。也即在拨打用户电话之后,应该在获取到接通前音频(早期媒体音)的信息之后立马能准确判断出号码状态并立即挂断,避免打扰到用户。
4.然而各个运营商对不同号码状态的音频提示音有所不同,如文字提示、音乐提示,响铃声等。不同运营商早期媒体音的形式也有所不同,且不是所有的运营商都能给到一些额外的号码状态信息。因此,目前号码状态识别的有效性及时效性较低。
技术实现要素:
5.本发明实施例解决的技术问题是号码状态识别的有效性和时效性较低。
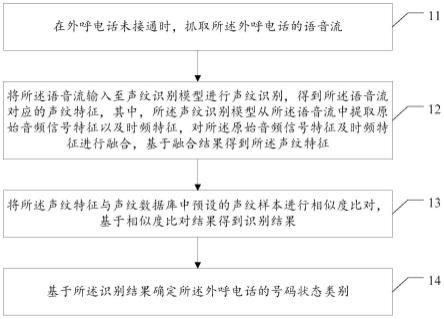
6.为解决上述技术问题,本发明实施例提供一种号码状态识别方法,包括:在外呼电话未接通时,抓取所述外呼电话的语音流;将所述语音流输入至声纹识别模型进行声纹识别,得到所述语音流对应的声纹特征,其中,所述声纹识别模型从所述语音流中提取原始音频信号特征以及时频特征,对所述原始音频信号特征及时频特征进行融合,基于融合结果得到所述声纹特征;将所述声纹特征与声纹数据库中预设的声纹样本进行相似度比对,基于相似度比对结果得到识别结果;基于所述识别结果确定所述外呼电话的号码状态类别。
7.可选的,所述时频特征包括:采用时延神经网络提取的时延特征及基于因果膨胀卷积提取的局部特征,所述对所述原始音频信号特征及时频特征进行融合,包括:获取所述原始音频信号特征对应的第一权重、所述时延特征对应的第二权重以及所述局部特征对应的第三权重;采用所述第一权重、所述第二权重及所述第三权重对所述原始音频信号特征、所述时延特征以及所述局部特征进行融合,得到所述融合结果。
8.可选的,将所述语音流输入至声纹识别模型进行声纹识别之前,还包括:对所述语音流进行语音活动检测,根据语音活动检测结果判断所述外呼电话的当前状态是否为静音;若所述语音活动检测结果指示所述外呼电话的当前状态不为静音,则将所述语音流输入至所述声纹识别模型进行声纹识别。
9.可选的,所述号码状态识别方法还包括:若所述语音活动检测结果指示所述外呼电话的当前状态为静音,则继续抓取语音流,并基于继续抓取的语音流进行号码状态识别,直至识别结果指示所述外呼电话的当前状态不为静音,将所述语音流输入至所述声纹识别模型进行声纹识别;或者,若所述语音活动检测结果指示所述外呼电话的当前状态为静音,则继续抓取语音流,并基于继续抓取的语音流进行语音活动检测,直至所述语音活动检测
结果指示所述外呼电话的当前状态为静音且抓取的语音流的累计语音时长达到第一设定时长,确定所述外呼电话的号码处于正常状态,并结束对所述外呼电话的号码状态识别。
10.可选的,所述基于所述识别结果确定所述外呼电话的号码状态类别,包括:若所述识别结果确定所述外呼电话的号码状态类别为响铃,则继续抓取语音流,并基于继续抓取的语音流进行号码状态识别,直至所述识别结果确定所述外呼电话的号码状态类别为设定类别或者抓取的语音流的累计语音时长达到第二设定时长,结束对所述外呼电话的号码状态识别,所述设定类别选自以下任一种:暂时无法接通、空号、停机、关机、用户忙。
11.可选的,在抓取所述外呼电话的语音流之后,还包括:对所述语音流进行音频格式处理,所述音频格式处理选自以下至少一种:采样率处理、样本宽度处理。
12.可选的,所述号码状态识别方法还包括:在基于所述识别结果确定所述外呼电话的号码状态类别之后,根据号码状态类别对所述外呼电话进行分类。
13.可选的,所述声纹数据库中的声纹样本采用所述声纹识别模型进行声纹识别得到。
14.可选的,采用如下方式训练得到所述声纹识别模型:获取训练样本集,所述训练样本集包括多个训练样本;针对每个训练样本输入至待训练模型,采用所述待训练模型分别进行原始音频信号特征提取以及时频特征提取,得到每个训练样本的原始音频信号特征及时频特征;将每个训练样本的原始音频信号特征及时频特征进行融合,并基于融合结果预测得到每个训练样本的声纹特征;基于每个训练样本预测得到的声纹特征进行每个训练样本的号码状态类别预测,得到号码状态类别的预测结果;针对各个训练样本,根据所述预测结果与真实结果的相似度,对所述声纹识别模型进行训练,直至所述预测结果与真实结果的相似度达到相似度阈值,训练得到所述声纹识别模型。
15.可选的,所述号码状态识别方法还包括:从所述训练样本集中选取部分训练样本;对选取的训练样本进行加噪处理,并将加噪处理后的训练样本加入所述训练样本集。
16.本发明实施例还提供一种号码状态识别装置,包括:抓取单元,用于在外呼电话未接通时,抓取所述外呼电话的语音流;声纹识别单元,用于将所述语音流输入至声纹识别模型进行声纹识别,得到所述语音流对应的声纹特征,其中,所述声纹识别模型从所述语音流中提取原始音频信号特征以及频域特征,对所述原始音频信号特征及所述频域特征进行融合,基于融合结果得到所述声纹特征;比对单元,用于将所述声纹特征与声纹数据库中预设的声纹样本进行相似度比对,基于相似度比对结果得到识别结果;确定单元,用于基于所述识别结果确定所述外呼电话的号码状态类别。
17.本发明实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器运行时执行上述任一种号码状态识别方法的步骤。
18.本发明实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述任一种号码状态识别方法的步骤。
19.与现有技术相比,本发明实施例的技术方案具有以下有益效果:
20.本发明实施例中,基于外呼电话未接通时所抓取外呼电话的语音流,将语音流输入至声纹识别模型进行声纹识别,得到语音流对应的声纹特征。将声纹特征与声纹数据库中预设的声纹样本进行相似度比对,基于相似度比对结果得到识别结果。进而基于识别结
果确定外呼电话的号码状态类别。声纹识别模型通过对外呼电话未接通时抓取的语音流进行声纹识别,从语音流中提取原始音频信号特征以及时频特征,对原始音频信号特征与时频特征进行融合,得到声纹特征。基于声纹特征与预设的声纹样本的相似度来确定外呼电话的号码状态类别。由此仅从早期媒体音所提供的音频信息上通过声纹特征,即可快速、有效、实时地识别出号码状态,且能够适应各种类型的早期媒体音,无论早期媒体音中是否包含文本内容,兼具鲁棒性、实时性、准确性。还可以提高电话号码识别的有效性及时效性,此外,在电话接通前即可完成号码状态识别,实现用户无感知,避免打扰到用户。
附图说明
21.图1是本发明实施例中的一种号码状态识别方法的流程图;
22.图2是本发明实施例中的一种声纹识别模型的训练流程图;
23.图3是本发明实施例中的一种号码状态识别装置的结构示意图。
具体实施方式
24.如上所述,在一些应用场景中,需要在用户无感知的情况下判断号码状态。也即在拨打用户电话之后,应该在获取到接通前音频(早期媒体音)的信息之后立马能准确判断出号码状态并立即挂断,避免打扰到用户。
25.然而各个运营商对不同号码状态的音频提示音有所不同,如文字提示、音乐提示,响铃声等。不同运营商早期媒体音的形式也有所不同,且不是所有的运营商都能给到一些额外的号码状态信息。
26.目前,本领域常用的一种号码状态识别方式为通过获取外呼号码的反馈音频(接通前以及接通后的音频),接通前先判断是否为铃声,是铃声则使用铃声匹配规则。接通前为非铃声及接通后音频,采用自动语音识别(automatic speech recognition,asr)将音频信息转化为文本,然后通过文本来匹配号码的状态。上述技术的号码状态判断依赖于铃声的匹配以及asr的转写结果。因此,该方案的匹配结果首先依赖于是否是铃声的判断的准确性,若铃声判断出错,走了asr的步骤,则无转写结果,从而无法得到准确的结果。其次,不同运营商的铃声形式多种多样,且在不断更新,无法适用于新增的铃声及训练样本中未覆盖的铃声。而针对新增的铃声不断重新训练模型又过于繁琐。
27.本领域常用的另一种号码状态识别方式为在电话结束拨打后,对未接通用户,根据运营商返回的回铃提示及校验编码到预设的两个库中进行比对。该方案是针对已经确定是未接通的用户,再进行号码状态判断,无法实时确认号码的状态类别,无法应用于实时场景。此外该方式依赖运营商返回的校验编码,但并不是所有运营商都会有对应的校验编码提供给使用方,解决问题的场景也受限且并不能做到用户无感知的验证号码状态。
28.综上,目前号码状态识别的有效性及时效性较低。
29.为解决上述问题,基于外呼电话未接通时所抓取外呼电话的语音流,将语音流输入至声纹识别模型进行声纹识别,得到语音流对应的声纹特征。将声纹特征与声纹数据库中预设的声纹样本进行相似度比对,基于相似度比对结果得到识别结果。进而基于识别结果确定外呼电话的号码状态类别。声纹识别模型通过对外呼电话未接通时抓取的语音流进行声纹识别,从语音流中提取原始音频信号特征以及时频特征,对原始音频信号特征与时
频特征进行融合,得到声纹特征。基于声纹特征与预设的声纹样本的相似度来确定外呼电话的号码状态类别。由此仅从早期媒体音所提供的音频信息上通过声纹特征,即可快速、有效、实时地识别出号码状态,且能够适应各种类型的早期媒体音,无论早期媒体音中是否包含文本内容,兼具鲁棒性、实时性、准确性。还可以提高电话号码识别的有效性及时效性,此外,本发明实施例可以实时识别号码状态,在电话接通前即可完成号码状态识别,实现用户无感知,避免打扰到用户。
30.为使本发明实施例的上述目的、特征和有益效果能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
31.参照图1,给出本发明实施例中的一种号码状态识别方法的流程图,具体可以包括如下步骤:
32.步骤11,在外呼电话未接通时,抓取所述外呼电话的语音流;
33.步骤12,将所述语音流输入至声纹识别模型进行声纹识别,得到所述语音流对应的声纹特征,其中,所述声纹识别模型从所述语音流中提取原始音频信号特征以及时频特征,对所述原始音频信号特征及时频特征进行融合,基于融合结果得到所述声纹特征;
34.步骤13,将所述声纹特征与声纹数据库中预设的声纹样本进行相似度比对,基于相似度比对结果得到识别结果;
35.步骤14,基于所述识别结果确定所述外呼电话的号码状态类别。
36.在具体实施中,步骤11中,在外呼电话未接通时,可以对未接通时播放的音频(早期媒体)进行抓包。
37.早期媒体(也可以成为早期媒体音)是拨打电话时,在等待接通时电话里的声音,如嘟嘟嘟的声音,关机时提示“当前号码已关机,请稍后再拨”等。所谓早期媒体是与用户媒体相对而言的。无论是在公共交换电话网络 (public switched telephone network,pstn)还是在基于ip的语音传输(voiceover internet protocol,voip)网络中,一个呼叫的最终目的让两个用户进行交谈。用户之间交谈时产生的媒体可以称为用户媒体(regular media)。显然,用户交谈不会从主叫发起呼叫时就立即开始(甚至可能不会开始),实际上它们之间通常会有几秒到几十秒的间隔,这完全取决于被叫用户的何时应答。
38.在此期间,虽然被叫没有摘机,但在主叫与网络之间也可以有媒体流产生,与用户媒体相区别,这种媒体被称为早期媒体。最典型的早期媒体就是回铃音。其他形式的早期媒体还有排队提示等。
39.当采用话务系统拨打电话时,话务系统可以对运营商未接通时播放的音频(早期媒体音)进行抓包。话务系统可以是freeswitch平台等。freeswitch 一个开源的电话软交换框架,可以处理来自ip网络和普通固定电话的语音、视频、文本通信。freeswitch包括一个软电话和软交换机用以提供语音和聊天的产品驱动。freeswitch可以用作交换机引擎、用户级交换机(private branch exchange,pbx)、多媒体网关以及多媒体服务器等。
40.在一些非限制性实施例中,在抓取到外呼电话的语音流之后,对所述语音流进行音频格式处理。所述音频格式处理选自以下至少一种:采样率处理、样本宽度处理。对语音流进行音频格式处理之后,得到的处理后的语音流与声纹识别模型所支持的音频格式相一致。
41.采样频率,也称为采样速度或者采样率,定义了单位时间内从连续信号中提取并
组成离散信号的采样个数,它用赫兹(hz)来表示。
42.样本宽度即采样位数,是用来衡量声音波动变化的一个参数。数值越大,分辨率越高,发出声音的能力越强。通常采样宽度可以为8比特(bit)、16bit、 32bit等。
43.在一些非限制性实施例中,可以通过socket接口获取语音流。可以理解的是,还可以通过其他合适的接口获取到语音流。
44.在一些非限制性实施例中,在话务系统与声纹识别模型之间设置有中间连接处,中间连接层从话务系统获取语音流,并将语音流发送至声纹识别模型。
45.在一些实施例中,可以累计获取到的语音流,当获取到的语音流的时长达到设定时长之后,再将累计达到设定时长的语音流输入至声纹识别模型。设定时长可以为3秒、4秒或者其他合适的时间长度,具体可以根据实际需求进行配置。
46.在步骤12的一种具体实施中,所述声纹识别模型从所述语音流中提取原始音频信号特征以及时频特征,对所述原始音频信号特征及时频特征进行融合,基于融合结果得到所述声纹特征。
47.在具体实施中,可以通过一维卷积从语音流中提取原始音频信号特征。
48.在具体实施中,时频特征可以包括时延特征以及局部特征。时延特征可以采用时延神经网络(tdnn)提取得到。局部特征可以采用因果膨胀卷积提取得到。
49.进一步,可以采用梅尔频率倒谱系数(mel-frequency cepstral coefficients,mfcc)进行语音特征提取得到语音信号。基于语音信号,采用时延神经网络 (tdnn)提取得到时延特征。基于语音信号,采用因果膨胀卷积提取得到局部特征。
50.在具体实施中,可以获取所述原始音频信号特征对应的第一权重、所述时延特征对应的第二权重以及所述局部特征对应的第三权重。采用所述第一权重、所述第二权重及所述第三权重对所述原始音频信号特征、所述时延特征以及所述局部特征进行融合,得到所述融合结果。
51.采用所述第一权重、所述第二权重及所述第三权重对所述原始音频信号特征、所述时延特征以及所述局部特征进行融合,具体而言,将第一权重与原始音频信号特征进行加权得到第一结果,将第二权重与时延特征进行加权得到第二结果,将第三权重与局部特征进行加权得到第三结果,根据第一结果、第二结果及第三结果得到融合结果。在得到融合结果时,基于时延特征可以考虑到语音流中多帧语音的语音信号之间的关系,基于局部特征可以取得较大的感受野,以更关注语音信号特有的一些特征。从而,通过综合考虑原始音频信号特征、时延特征以及局部特征并融合得到的声纹特征,可以综合考虑多个角度的特征,使得融合得到的声纹特征能够较好的体现语音流的特征,后续基于声纹特征进行号码状态识别时,有助于提高识别结果的准确度。此外,还能够有效的应对通信语音流的丢包和扰动,即使在早期媒体音质量不佳时,仍能够正确进行号码状态识别。
52.步骤13中,可以将声纹特征与声纹数据库中的预设的声纹样本分别进行相似度比对,基于相似度比对结果得到识别结果。
53.识别结果可以为声纹特征与声纹数据库中的声纹样本的相似度比对结果的最大相似度对应的声纹样本。也即,识别结果可以为声纹数据库中与声纹特征相匹配的声纹样本。
54.其中,声纹数据库中可以包括多种号码状态类别分别对应的声纹样本。也即,每个
号码状态类别分别具有对应的声纹样本。一个号码状态类别可以对应一个声纹样本,也可以对应对个声纹样本。声纹样本可以采用向量的方式进行表征。从而步骤13中,可以将声纹特征对应的向量与声纹样本对应的向量进行相似度比对。
55.在一些非限制性实施例中,所述声纹数据库中的声纹样本采用所述声纹识别模型进行声纹识别得到。当有新的早期媒体音时,采用声纹识别模型对新的早期媒体音进行识别,得到对应的声纹样本,加入声纹数据库,以实现对声纹数据库内的声纹样本进行更新,有助于声纹样本的扩充,确保号码状态识别的可靠性及准确性。
56.步骤14中,可以根据识别结果确定外呼电话的号码状态类别。
57.例如,当识别结果为声纹特征与声纹数据库中的声纹样本的相似度比对结果的最大相似度对应的声纹样本时,则最大相似度对应的声纹样本对应的号码状态类别作为该通外呼电话的号码状态类别。
58.号码状态类别可以包括以下任一种:响铃、暂时无法接通、空号、停机、关机、用户忙、正常等。
59.由上述方案可知,基于外呼电话未接通时所抓取外呼电话的语音流,将语音流输入至声纹识别模型进行声纹识别,得到语音流对应的声纹特征。将声纹特征与声纹数据库中预设的声纹样本进行相似度比对,基于相似度比对结果得到识别结果。进而基于识别结果确定外呼电话的号码状态类别。声纹识别模型通过对外呼电话未接通时抓取的语音流进行声纹识别,从语音流中提取原始音频信号特征以及时频特征,对原始音频信号特征与时频特征进行融合,得到声纹特征。基于声纹特征与预设的声纹样本的相似度来确定外呼电话的号码状态类别。由此仅从早期媒体音所提供的音频信息上通过声纹特征,即可快速、有效、实时地识别出号码状态,且能够适应各种类型的早期媒体音,无论早期媒体音中是否包含文本内容,兼具鲁棒性、实时性、准确性。还可以提高电话号码识别的有效性及时效性,此外,在电话接通前即可完成号码状态识别,实现用户无感知,避免打扰到用户。
60.此外,本发明基于语音流的声纹特征进行号码状态识别,仅依赖语音本身特征,对于各类形式的语音均适用,无论是文本相关及文本无关的场景,声纹识别模型均可以覆盖。不依赖语音流对应的文本的训练方式,并且可以不受语言的限制,能够适用于不同的国家,并且均具有较好的号码状态识别效果。
61.在具体实施中,可能存在外呼电话未接通时处于静音状态的情况,为了提高处于静音状态时的号码状态类别的识别结果的准确性,在步骤12之前,还可以对所述语音流进行语音活动检测(voice activity detection,vad),根据语音活动检测结果判断所述外呼电话的当前状态是否为静音;若所述语音活动检测结果指示所述外呼电话的当前状态不为静音,则将所述语音流输入至所述声纹识别模型进行声纹识别。
62.在一些实施例中,若所述语音活动检测结果指示所述外呼电话的当前状态为静音,则继续抓取语音流,并基于继续抓取的语音流进行号码状态识别,直至识别结果指示所述外呼电话的当前状态不为静音,将所述语音流输入至所述声纹识别模型进行声纹识别。
63.在另一些实施例中,若所述语音活动检测结果指示所述外呼电话的当前状态为静音,则继续抓取语音流,并基于继续抓取的语音流进行语音活动检测,直至所述语音活动检测结果指示所述外呼电话的当前状态为静音且抓取的语音流的累计语音时长达到第一设定时长,确定所述外呼电话的号码处于正常状态,并结束对所述外呼电话的号码状态识别。
进一步,在结束对外呼电话的号码状态识别的同时,还可以挂断该通外呼电话,以提高用户无感效果,避免干扰到用户。对于一些国外号码在拔打时,开始容易出现长时间的静音,而静音时无法准确的识别号码状态。若外呼电话的当前状态为静音,通过继续抓取语音流进行号码状态识别,有助于提高对于外呼电话号码状态识别的准确性。
64.第一设定时长可以为30秒、40秒或者60秒,可以理解的是,第一设定时长还可以为其他取值,具体可以根据运营商对早期媒体的时长或者对静音的最大时长的要求等进行设置。
65.在实际中,根据运营商对早期媒体的配置不同,有些是配置为先响铃,响铃时长持续一定时长之后,再输出一些提示音等。因此,仅根据响铃可能无法准确的判断号码状态类别。为了提高号码状态类别判断的准确性,在本发明一些非限制性实施例中,若所述识别结果确定所述外呼电话的号码状态类别为响铃,则继续抓取语音流,并基于继续抓取的语音流进行号码状态识别,直至所述识别结果确定所述外呼电话的号码状态类别为设定类别或者抓取的语音流的累计语音时长达到第二设定时长,结束对所述外呼电话的号码状态识别,所述设定类别选自以下任一种:暂时无法接通、空号、停机、关机、用户忙。其中,用户忙可以多种提示方式,如拔打的电话正在通话中、用户忙、用户正忙等。可以理解的是,提示音的语言可以为中文、英文,还可以为其他语种,此处不作限定。
66.进一步,判断外呼电话所属运营商是否为指定运营商,若外呼电话所属运营商为指定运营商,且所述识别结果确定所述外呼电话的号码状态类别为响铃,则继续抓取语音流,并基于继续抓取的语音流进行号码状态识别,直至所述识别结果确定所述外呼电话的号码状态类别为设定类别或者抓取的语音流的累计语音时长达到第二设定时长,结束对所述外呼电话的号码状态识别。其中,对于需要输出提示音的一些类别(如暂时无法接通、用户忙、正在通话中),指定运营商对应的早期媒体音配置习惯为先响铃后输出提示音。如此,当外呼电话所属运营商为指定运营商,且所述识别结果确定所述外呼电话的号码状态类别为响铃,则继续抓取语音流进行号码状态识别,可以提高对号码状态判断的准确性。
67.第二设定时长可以为30秒、40秒或者60秒,可以理解的是,第二设定时长还可以为其他取值,具体可以根据运营商对早期媒体的时长或者对静音的最大时长的配置等进性设置。
68.在具体实施中,在基于所述识别结果确定所述外呼电话的号码状态类别之后,根据号码状态类别对所述外呼电话进行分类。通过外呼电话进行状态分类,进行有效的处于正常状态的号码进行分类。其中处于正常状态的号码可以包括暂时无法接通、停机、关机、用户忙、响铃等。通过对电话的号码状态类别识别或者分类,可以有助于对电话号码对应用户的风险等级进行评估。比如,电话号码的号码状态处于空号的用户的风险等级高于处于正常状态的用户。
69.关于声纹识别模型的训练过程,下面结合图2给出的本发明实施例中的一种声纹识别模型的训练方法的流程图,对声纹识别模型的训练过程进行说明,具体可以包括如下步骤:
70.步骤21,获取训练样本集,所述训练样本集包括多个训练样本;
71.步骤22,针对每个训练样本输入至待训练模型,采用所述待训练模型分别进行原始音频信号特征提取以及时频特征提取,得到每个训练样本的原始音频信号特征及时频特
eprom,简称eeprom)或闪存。易失性存储器可以是随机存取存储器(random accessmemory,简称ram),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的随机存取存储器(random access memory,简称ram)可用,例如静态随机存取存储器(static ram,简称sram)、动态随机存取存储器 (dram)、同步动态随机存取存储器(synchronous dram,简称sdram)、双倍数据速率同步动态随机存取存储器(double data rate sdram,简称ddrsdram)、增强型同步动态随机存取存储器(enhanced sdram,简称esdram)、同步连接动态随机存取存储器(synchlink dram,简称sldram) 和直接内存总线随机存取存储器(direct rambus ram,简称dr ram)。
86.本发明实施例还提供一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行上述任一实施例提供的号码状态识别方法的步骤。
87.所述存储器和所述处理器耦合,存储器可以位于终端内,也可以位于终端外。所述存储器和所述处理器可以通过通信总线连接。
88.终端可以包括但不限于手机、计算机、平板电脑等终端设备,还可以为服务器、云平台等。
89.上述实施例,可以全部或部分地通过软件、硬件、固件或其他任意组合来实现。当使用软件实现时,上述实施例可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令或计算机程序。在计算机上加载或执行所述计算机指令或计算机程序时,全部或部分地产生按照本技术实施例所述的流程或功能。所述计算机可以为通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机程序可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机程序可以从一个网站站点、计算机、服务器或数据中心通过有线或无线方式向另一个网站站点、计算机、服务器或数据中心进行传输。
90.在本技术所提供的几个实施例中,应该理解到,所揭露的方法、装置和系统,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的;例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式;例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
91.另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理包括,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。例如,对于应用于或集成于芯片的各个装置、产品,其包含的各个模块/单元可以都采用电路等硬件的方式实现,或者,至少部分模块/单元可以采用软件程序的方式实现,该软件程序运行于芯片内部集成的处理器,剩余的(如果有)部分模块/单元可以采用电路等硬件方式实现;对于应用于或集成于芯片模组的各个装置、产品,其包含的各个模块/单元可以都采用电路等硬件的方式实现,不同的模块/单元可以位于芯片模组的同一组件(例如芯片、电路模块等)或者不同组件中,或者,至少部分模块/单元可以采用软件程序的方式实现,该软件程序运行于
芯片模组内部集成的处理器,剩余的(如果有)部分模块/单元可以采用电路等硬件方式实现;对于应用于或集成于终端的各个装置、产品,其包含的各个模块/单元可以都采用电路等硬件的方式实现,不同的模块/单元可以位于终端内同一组件(例如,芯片、电路模块等)或者不同组件中,或者,至少部分模块/单元可以采用软件程序的方式实现,该软件程序运行于终端内部集成的处理器,剩余的(如果有) 部分模块/单元可以采用电路等硬件方式实现。
92.本技术实施例中出现的“多个”是指两个或两个以上。
93.本技术实施例中出现的第一、第二、第三等描述,仅作示意与区分描述对象之用,没有次序之分,也不表示本技术实施例中对设备个数的特别限定,不能构成对本技术实施例的任何限制。
94.需要指出的是,本实施例中各个步骤的序号并不代表对各个步骤的执行顺序的限定。
95.虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1