一种用于声纹安全认证系统的重放语音攻击检测方法
1.本发明属于声纹识别技术领域,具体涉及一种用于声纹安全认证系统的重放语音攻击检测方法。
背景技术:
2.声纹识别技术在我们日常生活的许多场景中已经得到了广泛的应用,作为当前最热门的生物特征识别技术之一,在远程认证等领域有着独特的优势,受到了越来越多的关注。声纹认证是指从说话人的话语短句中提取所需特征,然后根据该特征判决接受或拒绝用户。目前,声纹认证系统容易受到伪装语音(包括合成语音、转换语音、重放语音、模仿语音)的攻击,而重放语音是通过使用录音设备记录的语音片段,并使用不同的扬声器设备播放,不需要像合成、转换语音需要大量的音频领域知识。因此,声纹认证系统很容易受到重放语音的攻击。在目前常用的反重放攻击方法中,使用的特征向量有梅尔频率倒谱系数、常数q倒谱系数、线性预测倒谱系数、修正群延迟、瞬时频率倒谱系数等。然而这些特征向量在攻击检测中的准确性还有待提高,无法很好地满足重放语音检测系统的安全性要求。
技术实现要素:
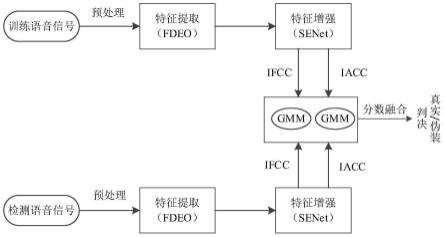
3.本发明提出了利用频域能量算子(frequency-domain energy operator,fdeo)与挤压激励网络(squeeze-and-excitation networks,senet)相结合,用来提取含注意力机制的瞬时幅度特征(instantaneous amplitude cosine coefficients,iacc)和瞬时频率特征(instantaneous frequency cosine coefficients,ifcc),然后以这两种特征参数作为特征矢量、高斯混合模型作为后端分类器来构建重放语音检测系统,鉴别真伪语音。
4.首先将语音信号经过预处理,然后通过线性等宽的gabor滤波器获得若干子带信号,将每个子带信号通过fdeo来获得瞬时幅度和瞬时频率,然后分别作为senet的输入,得到增强后的iacc和ifcc特征,并且分别经过加窗取平均和离散余弦变换处理获得各自的低维特征向量。然后将提取的iacc和ifcc特征向量分别用来训练各自的高斯混合模型(gaussian mixture model,gmm)分类器,得到各自的分类器模型参数。在检测时,将待测语音的iacc和ifcc特征向量分别输入到各自的gmm分类器并进行可信度打分,最后进行分数级融合,以此实现真伪语音的判别。
5.一种用于声纹安全认证系统的重放语音攻击检测方法,包括以下步骤:
6.步骤1,对训练用语音进行预处理;
7.步骤2,将经过预处理的语音信号通过gabor滤波器组,得到n个子带信号;
8.步骤3,利用频域能量算子fdeo对子带信号进行am-fm分析,得到语音信号的能量估计,并得到瞬时幅度iacc和瞬时频率ifcc;
9.步骤4,将语音信号的瞬时幅度和瞬时频率通过挤压激励网络senet得到特征增强后的特征向量;
10.步骤5,对步骤4的特征向量通过取平均以及dct获得低维特征向量表示;
11.步骤6,进行一阶二阶差分运算以及串联特征得到iacc+
△
+
△△
和ifcc+
△
+
△△
12.特征向量;
13.步骤7,利用训练集特征向量构造高斯混合模型参数,将待测语音输入到分类器进行判别。
14.作为优选,所述的步骤2包括:
15.设采样频率为fs,则采样信号最高频率为fs/2,将它分为200hz等宽,滤波器个数为
[0016]16.表示向上取整符号,则中心频率为fi=200i-100(hz),i∈[1,n],因此需要由n个gabor滤波器组成的滤波器组,第i个滤波器的单位脉冲响应表示为:
[0017]gi
(n)=exp(-b2n2)cos(ωin)
ꢀꢀꢀ
(1)
[0018]
ωi=2πfit
ꢀꢀꢀꢀꢀꢀ
(2)
[0019]
其中,ωi表示为中心频率,t为采样周期,b用于控制带宽;经过第i个gabor子带滤
[0020]
波器后的语音信号表达式可以表示为:
[0021]
γi(n)=s(n)*gi(n)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0022]
其中,符号*表示卷积运算,s(n)为语音信号,gi(n)为第i个gabor滤波器的脉冲响应。
[0023]
作为优选,所述的步骤3包括:
[0024]
将γi(n)经过n:1降采样得到xi(n),然后xi(n)通过fdeo来获得语音信号的能量估计;对于离散信号xi(n),采用三点对称差分,其定义为:
[0025][0026]
则其频域加权能量算子离散表达式为:
[0027][0028]
其中hi(n)是信号xi(n)希尔伯特变换,定义为hi(n)=h[xi(n)];
[0029]
完成语音信号的能量估计后,利用能量分离算法得到每个子带信号的瞬时幅度和瞬时频
[0030]
率,表达式为:
[0031][0032][0033]
其中,ai[n]和ωi[n]分别为第i个子带信号的瞬时幅度和瞬时频率。
[0034]
作为优选,所述的步骤4的senet体系结构中,主要由挤压层和激励层组成;
[0035]
通过对每一帧语音进行特征提取然后得到上述的瞬时幅度特征向量a[n]={a1[n],a2[n],
……
,an[n]}和瞬时频率特征向量ω[n]={ω1[n],ω2[n],
……
,ωn[n]},这样对于一段帧数为τ的语音信号就可以得到两
[0036]
个特征矢量序列,记为a和ω;
[0037]
a和ω作为挤压层的输入,统称为u={u1,u2,
…
,uc,
…
,un}
t
,t表示矩阵转置运算符;
[0038]
当输入为a时,u=a,当输入为ω时,u=ω;而c是频率指数且c∈[1,n],uc={uc(1),uc(2),
……
,uc(τ)},然后经过全局平均池化得到挤压描述符z={z1,z2,
…
,zc,
…
,zn},其中挤压描述符zc表达式为:
[0039][0040]
得到挤压描述符后,在激励层通过矩阵运算获取每个特征维度的权重,权重参数表示为s={s1,s2,
…
,sc,
…
,sn},其表达式为:
[0041]
s=σ(w2*δ(w1*z))
ꢀꢀꢀꢀꢀꢀꢀ
(9)
[0042]
其中,δ(
·
)表示修正线性单元(rectified linear unit,relu)函数,w1和w2分别表示维数为a
×
n的降维矩阵和维数为n
×
a的升维矩阵,主要用于减少参数计算,σ(
·
)表示sigmoid函数;
[0043]
将得到的权重参数向量与原来的输入向量序列通道相乘,得到加权后的输出xc,表达式为:
[0044]
xc=f
scale
(uc,sc)
ꢀꢀꢀꢀꢀꢀꢀ
(10)
[0045]
其中,f
scale
(
·
,
·
)表示通道乘法,则语音的隐层表示为x={x1,x2,
…
,xc,
…
,xn}
t
;
[0046]
将语音的隐层表示x接入一个线性层作为训练的分类器,该线性层输出结果为真伪语音的概率,用于计算交叉熵损失,从而更新模块内参数;测试时则取消该线性层,直接将x按照时间维度分割每一帧的特征向量,并对每一帧作平均运算,得到语音的向量级表示,即增强后的瞬时幅度特征向量和瞬时频率特征向量,它们分别表示为
[0047]a′
={a1′
,a2′
,
…
,ai′
,
…
,a
′n}和ω
′
={ω1′
,ω2′
,
…
,ωi′
,
…
,ω
′n}。
[0048]
作为优选,所述的步骤5中:
[0049]
dct表达式为:
[0050][0051][0052]
其中,f(i)为原始的信号,即分别为上述的ai′
和ωi′
,f(u)是dct变换后的系数;其中f(u)取前13个系数,即f(u),u=1,2,
…
13;n为特征向量的维数;ρ(u)是一个补偿系数,使dct变换矩阵为正交矩阵。
[0053]
作为优选,所述的步骤7中:
[0054]
对于特征向量x∈rd×1,其混合密度的似然函数表达式为:
[0055][0056]
其中,ωi为第i个高斯分量的权重,且有高斯概率密度分布函数pi(x)由d
×
1维的均值向量μi和d
×
d的方差矩阵σi参数化,表达式为:
[0057][0058]
模型参数的估计采用均值最大化算法来迭代求解,其表达式如下:
[0059]
θ
(i+1)
=arg max
θ
e[logp(x,γ|θ)|x,θ(i)]
ꢀꢀꢀꢀꢀꢀꢀ
(15)
[0060]
其中,θ(i)表示第i次得到的θ值,θ表示参数集γ表示为不同高斯函数对输入样本x的响应度。
[0061]
本发明的实质性特点在于:根据真伪语音的频谱包络及谐波结构差异,利用fdeo提取语音信号的iacc和ifcc特征向量,解决了传统语音信号am-fm分析复杂的相位展开任务的问题。利用的频域能量算子使用了希尔伯特变换,相较于teager能量算子,不会出现能量为负的情况,更加符合实际意义,同时抗噪能力也更强。利用senet对提取特征进行特征增强,使原有特征更加具有指向性,增大了特征向量对真伪语音的差异性。通过分数融合兼顾语音信号的幅度信息和频率信息,使得整个系统对重放语音具有更强的鲁棒性。
附图说明
[0062]
图1利用fdeo的重放语音检测流程图;
[0063]
图2senet结构图。
具体实施方式
[0064]
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体说明。
[0065]
实施例1
[0066]
图1为本发明的重放伪装语音检测的系统结构,接下来介绍系统中各模块的工作原理。
[0067]
本发明提出的重放语音检测系统由特征提取、特征增强和后端分类三部分组成。该系统利用fdeo对检测语音进行am-fm分析,获得语音信号的瞬时频率和瞬时幅度,由于重放语音的谐波结构与频谱包络和真实语音存在差异,因此通过提取iacc和ifcc特征向量来区分差异性。将该特征向量输入到高斯混合模型进行训练得到真伪分类模型,然后将检测语音的特征向量输入到分类模型中即可鉴别真伪。整个过程可以对真实语音和重放语音鉴别真伪,实现了重放语音检测。
[0068]
详细的算法过程如下:
[0069]
(1)将经过预处理的语音信号经过gabor滤波器组,得到n个子带信号。
[0070]
(2)利用fdeo对子带信号进行am-fm分析,得到语音信号的能量估计,并得到瞬时幅度和瞬时频率。
[0071]
(3)将语音信号的瞬时幅度和瞬时频率通过senet得到特征增强后的特征向量。
[0072]
(4)通过取平均以及dct获得低维特征向量表示。
[0073]
(5)进行一阶二阶差分运算以及串联特征得到iacc+
△
+
△△
和ifcc+
△
+
△△
特征向量。
[0074]
(6)利用训练集特征向量构造高斯混合模型参数,将待测语音输入到分类器进行判别。
[0075]
特征提取模块利用fdeo来提取iacc和ifcc。与真实语音相比,重放语音由于回放设备和信道特性,频谱能量变得扭曲,使得重放语音的频谱包络存在明显的谐波失真,因此可以通过提取瞬时频率特征和瞬时幅度特征实现语音真伪的判别。利用频域能量算子来估计真实信号的能量,并通过能量分离算法保留振幅和频率信息,不仅降低了计算复杂度,而且提高了时间和频率分辨率。
[0076]
提取iacc和ifcc需要先将待测语音信号经过采样、预加重等预处理,然后通过带通滤波器获得子带信号。这里采用了线性等宽的gabor滤波器,若采样频率为fs,则采样信号最高频率为fs/2,将它分为200hz等宽,滤波器个数为/2,将它分为200hz等宽,滤波器个数为表示向上取整符号,则中心频率为fi=200i-100(hz),i∈[1,n],因此需要由n个gabor滤波器组成的滤波器组,第i个滤波器的单位脉冲响应表示为:
[0077]gi
(n)=exp(-b2n2)cos(ωin)
ꢀꢀꢀꢀꢀꢀꢀ
(1)
[0078]
ωi=2πfit
ꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0079]
其中,ωi表示为中心频率,t为采样周期,b用于控制带宽。经过第i个gabor子带滤波器后的语音信号表达式可以表示为:
[0080]
γi(n)=s(n)*gi(n)
ꢀꢀꢀ
(3)
[0081]
其中,符号*表示卷积运算,s(n)为语音信号,gi(n)为第i个gabor滤波器的脉冲响应。
[0082]
将γi(n)经过n:1降采样得到xi(n),然后xi(n)通过fdeo来获得语音信号的能量估计。对于离散信号xi(n),采用三点对称差分,其定义为:
[0083][0084]
则其频域加权能量算子离散表达式为:
[0085][0086]
其中hi(n)是信号xi(n)希尔伯特变换,定义为hi(n)=h[xi(n)]。
[0087]
完成语音信号的能量估计后,利用能量分离算法得到每个子带信号的瞬时幅度和瞬时频率,表达式为:
[0088][0089]
[0090]
其中,ai[n]和ωi[n]分别为第i个子带信号的瞬时幅度和瞬时频率。
[0091]
特征增强由senet来实现,原理是通过计算由输入特征向量得到的加权因子,然后控制每个滤波器通道的尺度大小,即每个维度的输出权重,使得重要的特征增强,不重要的特征减弱,从而让特征的指向性更强。在senet体系结构中,主要由挤压层和激励层组成,其结构图如图2所示。
[0092]
挤压层是为了解决信道依赖性问题,将全局空间信息压缩到一个信道描述符。通过对每一帧语音进行特征提取然后得到上述的瞬时幅度特征向量a[n]={a1[n],a2[n],
……
,an[n]}和瞬时频率特征向量ω[n]={ω1[n],ω2[n],
……
,ωn[n]},这样对于一段帧数为τ的语音信号就可以得到两个特征矢量序列,记为a和ω。a和ω作为挤压层的输入,统称为u={u1,u2,
…
,uc,
…
,un}
t
,t表示矩阵转置运算符。即当输入为a时,u=a,当输入为ω时,u=ω;而c是频率指数且c∈[1,n],uc={uc(1),uc(2),
……
,uc(τ)},然后经过全局平均池化得到挤压描述符z={z1,z2,
…
,zc,
…
,zn},其中挤压描述符zc表达式为:
[0093][0094]
得到挤压描述符后,在激励层通过矩阵运算获取每个特征维度的权重,权重参数表示为s={s1,s2,
…
,sc,
…
,sn},其表达式为:
[0095]
s=σ(w2*δ(w1*z))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0096]
其中,δ(
·
)表示修正线性单元(rectified linear unit,relu)函数,w1和w2分别表示维数为a
×
n的降维矩阵和维数为n
×
a的升维矩阵,主要用于减少参数计算,σ(
·
)表示sigmoid函数。
[0097]
最后将得到的权重参数向量与原来的输入向量序列通道相乘,得到加权后的输出xc,表达式为:
[0098]
xc=f
scale
(uc,sc)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0099]
其中,f
scale
(
·
,
·
)表示通道乘法,则语音的隐层表示为x={x1,x2,
…
,xc,
…
,xn}
t
。
[0100]
训练特征增强模块时,将语音的隐层表示x接入一个线性层作为训练的分类器,该线性层输出结果为真伪语音的概率,用于计算交叉熵损失,从而更新模块内参数。测试时则取消该线性层,直接将x按照时间维度分割每一帧的特征向量,并对每一帧作平均运算,得到语音的向量级表示,即增强后的瞬时幅度特征向量和瞬时频率特征向量,它们分别表示为a
′
={a
′1,a
′2,
…
,a
′i,
…
,a
′n}和ω
′
={ω
′1,ω
′2,
…
,ω
′i,
…
,ω
′n}。
[0101]
利用离散余弦变换(discrete cosine transform,dct)获得低维表示的ifcc和iacc,dct表达式为:
[0102][0103]
[0104]
其中,f(i)为原始的信号,即分别为上述的a
′i和ω
′i,f(u)是dct变换后的系数。本发明取f(u)前13个系数,即f(u),u=1,2,
…
13。n为特征向量的维数。ρ(u)是一个补偿系数,可以使dct变换矩阵为正交矩阵。
[0105]
将得到的13维的iacc和ifcc分别作一阶差分和二阶差分运算,然后串联拼接得到两个39维的iacc+
△
+
△△
和ifcc+
△
+
△△
矢量。
[0106]
高斯混合模型分类器:提取训练集中语音信号的iacc+
△
+
△△
和ifcc+
△
+
△△
特征向量后,分别利用这些特征向量训练生成各自的分类器模型参数,其中一类是真实语音,另一类是重放语音。高斯混合模型是语音处理中广泛使用的生成模型,它将每一类语音的特征参数空间表示为m个多元高斯函数的加权和。
[0107]
对于特征向量x∈rd×1,其混合密度的似然函数表达式为:
[0108][0109]
其中,ωi为第i个高斯分量的权重,且有高斯概率密度分布函数pi(x)由d
×
1维的均值向量μi和d
×
d的方差矩阵σi参数化,表达式为:
[0110][0111]
模型参数的估计采用均值最大化算法来迭代求解,其表达式如下:
[0112]
θ
(i+1)
=arg max
θ
e[logp(x,γ|θ)|x,θ(i)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0113]
其中,θ(i)表示第i次得到的θ值,θ表示参数集γ表示为不同高斯函数对输入样本x的响应度。
[0114]
迭代过程为先赋给高斯分布参数θ以初始值,θ包括高斯分布函数的权值、均值以及方差,然后计算在第0次迭代时该对数似然函数的均值,并以此求解均值最大情况下的θ值,将这个更新后的值作为第一次迭代的值送入下一次迭代,然后以此类推反复迭代,直至收敛。
[0115]
得到真实语音类和重放语音类的高斯混合模型后,将检测语音的iacc和ifcc特征向量分别送入各自的分类器,计算每一帧的对数似然比分数并在时间上取平均,用真实语音类的分数减去重放语音类的分数即为最终得分,并将由iacc和ifcc得到的两个分数等权重进行分数融合,并与设定的分数阈值进行比较,超过阈值则判别为真实语音,反之则认为是重放语音。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1