婴儿啼哭识别的大数据算法、系统、装置及存储介质的制作方法
1.本发明涉及语音识别领域,特别涉及婴儿啼哭识别的大数据算法、系统、装置及存储介质。
背景技术:
2.随着人工智能的反正,让婴儿哭声意图识别成为了可能,目前的语音分类算法,大多数要用gpu,至少也是pc端类cpu(八核2.0g以上主频),无法在嵌入式系统内运行,且传统的网络为vgg、resnet等,gg、resnet等传统网络耗费资源非常大,比如resnet50需要3.53g的浮点乘法,参数为25.56m个,因此无法在单片机上运行的。
技术实现要素:
3.本发明解决的技术问题是提供一种可降低大量运算的婴儿啼哭识别的大数据算法。
4.本发明解决其技术问题所采用的技术方案是:一种婴儿啼哭识别的大数据算法,
5.步骤一:获取婴儿啼哭大数据库中的婴儿啼哭数据;
6.步骤二:建立卷积神经网络识别模型并对其进行训练;
7.步骤三:根据训练好的模型对婴儿啼哭音频数据进行意图识别;
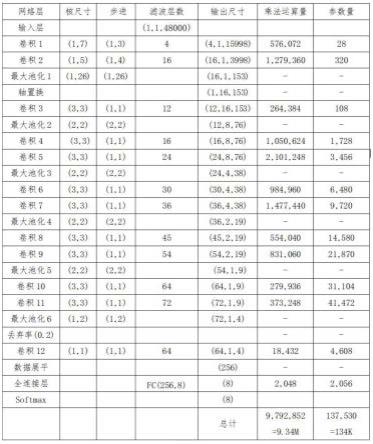
8.其中,神经网络识别模型包括依次连接的输入层、第一卷积层、第二卷积层、第一最大池化层、轴置换层、第三卷积层、第二最大池化层、第四卷积层、第五卷积层、第三最大池化层、第六卷积层、第七卷积层、第四最大池化层、第八卷积层、第九卷积层、第五最大池化层、第十卷积层、第十一卷积层、第六最大池化层、第十二卷积层、数据展平层、全连接层和输出层。
9.进一步的是:所述输入层用于接收经过lpc线性预测编码后的婴儿啼哭数据。
10.进一步的是:所述第一卷积层的核尺寸为1*7,步进为1*3,过滤层数为4层;
11.所述第二卷积层的核尺寸为1*5,步进为1*4,过滤层数为16层;
12.所述第一最大池化层的核尺寸为1*26,步进为1*26;
13.所述第三卷积层的核尺寸为3*3,步进为1*1,过滤层数为12层;
14.所述第二最大池化层的核尺寸为2*2,步进为2*2;
15.所述第四卷积层的核尺寸为3*3,步进为1*1,过滤层数为16层;
16.所述第五卷积层的核尺寸为3*3,步进为1*1,过滤层数为24层;
17.所述第三最大池化层的核尺寸为2*2,步进为2*2;
18.所述第六卷积层的核尺寸为3*3,步进为1*1,过滤层数为30层;
19.所述第七卷积层的核尺寸为3*3,步进为1*1,过滤层数为36层;
20.所述第四最大池化层的核尺寸为2*2,步进为2*2;
21.所述第八卷积层的核尺寸为3*3,步进为1*1,过滤层数为45层;
22.所述第九卷积层的核尺寸为3*3,步进为1*1,过滤层数为54层;
23.所述第五最大池化层的核尺寸为2*2,步进为2*2;
24.所述第十卷积层的核尺寸为3*3,步进为1*1,过滤层数为64层;
25.所述第十一卷积层的核尺寸为3*3,步进为1*1,过滤层数为72层;
26.所述第六最大池化层的核尺寸为1*2,步进为1*2;
27.所述第十二卷积层的核尺寸为1*1,步进为1*1,过滤层数为64层;
28.各卷积层完成卷积操作后,进行batch normal和relu操作。
29.进一步的是:所述输出层的激活函数为softmax函数。
30.进一步的是:在经过第六最大池化层的最大池化操作后,对数据进行随机丢弃,丢弃率为20%,并将丢弃后的数据传入第十二卷积层。
31.本发明还公开了可进行边缘运算的婴儿啼哭大数据计算系统,包括上述所述的婴儿啼哭识别的大数据算法,包括:
32.数据获取单元,所述数据获取单元用于获取婴儿啼哭数据;
33.数据处理单元,所述数据处理单元用于根据婴儿啼哭数据建立卷积神经网络识别模型。
34.本发明还公开了一种计算机装置,包括:处理器、存储器、通信接口和通信总线,所述处理器、存储器和通信接口通过所述通信总线完成相互间的通信,所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述所述的婴儿啼哭识别的大数据算法对应的操作。
35.本发明还公开了一种计算机存储介质,所述计算机存储介质中存储有至少一个可执行指令,所述可执行指令使处理器执行如上述所述的婴儿啼哭识别的大数据算法对应的操作。
36.本发明的有益效果是:此架框与传统vgg、resnet等网络相比,少了99%以上的浮点运算,99%的参数。综合认为以cortex-m4架构为例,只需要80~120mhz的主频即可满足运算(不同的rtos系统消耗部分资源)。
37.1、此处输入层没有进行fft的预处理,直接用实域值进行计算1d卷积(见卷积1和2),降低了大量的运算压力;
38.2、多头的卷积也提取了相当的特征参数,所以最大池化1此处用了大胆的26步进值,大大减少了数据的冗余度;
39.3、利用轴置换,将1d卷积变为2d卷积,将语音特征上升到图形特征,通过升维更好的提取特异性特征,并减少参数。
附图说明
40.图1为本技术实施例的婴儿啼哭识别的大数据算法的网络框架实例图。
具体实施方式
41.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明。但是本发明能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似改进,因此本发明不受下面公开的具体实施例的限制。
42.需要说明的是,当元件被称为“固定于”另一个元件,它可以直接在另一个元件上或者也可以存在居中的元件。当一个元件被认为是“连接”另一个元件,它可以是直接连接到另一个元件或者可能同时存在居中元件。
43.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“及/或”包括一个或多个相关的所列项目的任意的和所有的组合。
44.如图1所示,本技术的实施例工开了一种婴儿啼哭识别的大数据算法,
45.步骤一:获取婴儿啼哭大数据库中的婴儿啼哭数据;
46.步骤二:建立卷积神经网络识别模型并对其进行训练;
47.步骤三:根据训练好的模型对婴儿啼哭音频数据进行意图识别;
48.其中,神经网络识别模型包括依次连接的输入层、第一卷积层、第二卷积层、第一最大池化层、轴置换层、第三卷积层、第二最大池化层、第四卷积层、第五卷积层、第三最大池化层、第六卷积层、第七卷积层、第四最大池化层、第八卷积层、第九卷积层、第五最大池化层、第十卷积层、第十一卷积层、第六最大池化层、第十二卷积层、数据展平层、全连接层和输出层。
49.其中,所述第一卷积层的核尺寸为1*7,步进为1*3,过滤层数为4层;
50.所述第二卷积层的核尺寸为1*5,步进为1*4,过滤层数为16层;
51.所述第一最大池化层的核尺寸为1*26,步进为1*26;
52.所述第三卷积层的核尺寸为3*3,步进为1*1,过滤层数为12层;
53.所述第二最大池化层的核尺寸为2*2,步进为2*2;
54.所述第四卷积层的核尺寸为3*3,步进为1*1,过滤层数为16层;
55.所述第五卷积层的核尺寸为3*3,步进为1*1,过滤层数为24层;
56.所述第三最大池化层的核尺寸为2*2,步进为2*2;
57.所述第六卷积层的核尺寸为3*3,步进为1*1,过滤层数为30层;
58.所述第七卷积层的核尺寸为3*3,步进为1*1,过滤层数为36层;
59.所述第四最大池化层的核尺寸为2*2,步进为2*2;
60.所述第八卷积层的核尺寸为3*3,步进为1*1,过滤层数为45层;
61.所述第九卷积层的核尺寸为3*3,步进为1*1,过滤层数为54层;
62.所述第五最大池化层的核尺寸为2*2,步进为2*2;
63.所述第十卷积层的核尺寸为3*3,步进为1*1,过滤层数为64层;
64.所述第十一卷积层的核尺寸为3*3,步进为1*1,过滤层数为72层;
65.所述第六最大池化层的核尺寸为1*2,步进为1*2;
66.所述第十二卷积层的核尺寸为1*1,步进为1*1,过滤层数为64层;
67.各卷积层完成卷积操作后,进行batch normal和relu操作,上述轴置换操作后使用的是cnn算法,轴置换操作前使用的是rnn算法。
68.具体的,所述输出层的激活函数为softmax函数,上述方法中,输入的为16khz 3秒的语音序列,输出层可输出八分类结果,例如:定义为:0、非啼哭;1、饥饿;2、难受不适;3、不安;4、受惊;5、疼痛;6、生气;7、生病;上述具体定义需根据具体实验结果得出。
69.具体的,采用上述方法进行计算,根据实验得出,每秒计算一次,用双字节精度计算,总乘法为9,792,852次,加上加法运算、数据转运等,以cortex-m4内核100mhz来算大概每次乘法占用5个机器周期,大概需要0.5秒的时间,加上其他还需要完成的传感器采集、系统程序、用户操作等应用,只需要80~120mhz的主频即可满足运算。且本方法中采用多头卷积可提取相当多的特征参数,且第一最大池化层采用了26步进值,大大减少了数据的冗余度。
70.且本方法中,增加了轴置换的步骤,具体采用的函数为permute函数(本技术使用的代码语句为x=x.permute((0,2,1,3)),即将矩阵第1,2轴交换,0,3轴不变,第0轴代表batch值,用于加速计算,比如(4,1,15998),4是滤波核的个数,也可以认为是多头;1相当这个维度没有,所以(1,15998)就相当于一维数据,有15998个数据),此处将一维卷积变换为二维卷积,将语音特征上升到图形特征,通过升维更好的提取特异性特征(声带节奏、音量等),且变为二维的cnn训练后,cnn参数共享次数更多,训练参数少,能考虑到更多的特征参数,计算时间也更快。
71.本实施例中,所述输入层用于接收经过lpc线性预测编码后的婴儿啼哭数据。
72.本方法中将婴儿啼哭数据经过lpc线性预测编码,此方法利用短时间人发出的声音频率基本不变的原因,找到频谱中有效的特征值,进行特征值采集,此种方式相比传统的fft预处理方式,降低了大量的运算压力,fft预处理需要大量计算时间,运算复杂度为o(n*logn),每次运算含两个乘法和四个加法。那么48014个数据,假设以256的窗口,64的步进值滑动,则需要乘法数为:[(48014-256)/64+1]*(256*log2256*2)=3,059,712,此为单头的参数。而同样到卷积3的输出时,本技术中12头(一个卷积层提取12种特征参数)只需2,119,816个乘法,因此大大降低了数据计算。
[0073]
本方法通过lpc线性预测编码和轴置换的结合,大大减小了计算数量,进而减少了对主频容量的要求。
[0074]
本实施例中,在经过第六最大池化层的最大池化操作后,使用丢弃法对数据进行随机丢弃,丢弃率为20%,并将丢弃后的数据传入第十二卷积层。
[0075]
本方法中,应用丢弃法之后,会将丢弃数据从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合,从而使得神经网络更稳定。
[0076]
本发明还公开了可进行边缘运算的婴儿啼哭大数据计算系统,包括上述所述的婴儿啼哭识别的大数据算法,包括:
[0077]
数据获取单元,所述数据获取单元用于获取婴儿啼哭数据;
[0078]
数据处理单元,所述数据处理单元用于根据婴儿啼哭数据建立卷积神经网络识别模型。
[0079]
本发明还公开了一种计算机装置,包括:处理器、存储器、通信接口和通信总线,所述处理器、存储器和通信接口通过所述通信总线完成相互间的通信,所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述所述的婴儿啼哭识别的大数据算法对应的操作。
[0080]
本发明还公开了一种计算机存储介质,所述计算机存储介质中存储有至少一个可执行指令,所述可执行指令使处理器执行如上述所述的婴儿啼哭识别的大数据算法对应的
操作。
[0081]
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1