用于语音识别的系统和方法与流程
本文中说明的实施例涉及用于语音识别的系统和方法。
背景技术:
1、语音识别方法和系统接收语音音频并识别此类语音音频的内容,例如此类语音音频的文本内容。语音识别系统包括混合系统,并且可以包括声学模型(acoustic model,am)、发音词典(pronunciation lexicon)和语言模型(language model,lm)来确定语音音频的内容,例如解码语音。早期的混合系统对于声学模型和/或语言模型利用了隐式马尔可夫模型(hidden markov model,hmm)或类似的统计方法。后来的混合系统对于声学模型和/或语言模型中的至少一个利用了神经网络。这些系统可以称为深度语音识别系统。
2、还引入了具有端到端架构的语音识别系统。在这些系统中,可以使用其中可以认为隐含地集成了声学模型、发音词典和语言模型的单个神经网络。单个神经网络可以是递归神经网络。最近,对于语音识别系统使用了变换器(transformer)模型。变换器模型可以使用自注意力(self-attention)机制来进行语音识别,通过这种机制捕获依赖关系,而不管它们的距离如何。变换器模型可以采用编码器-解码器框架。
技术实现思路
技术特征:
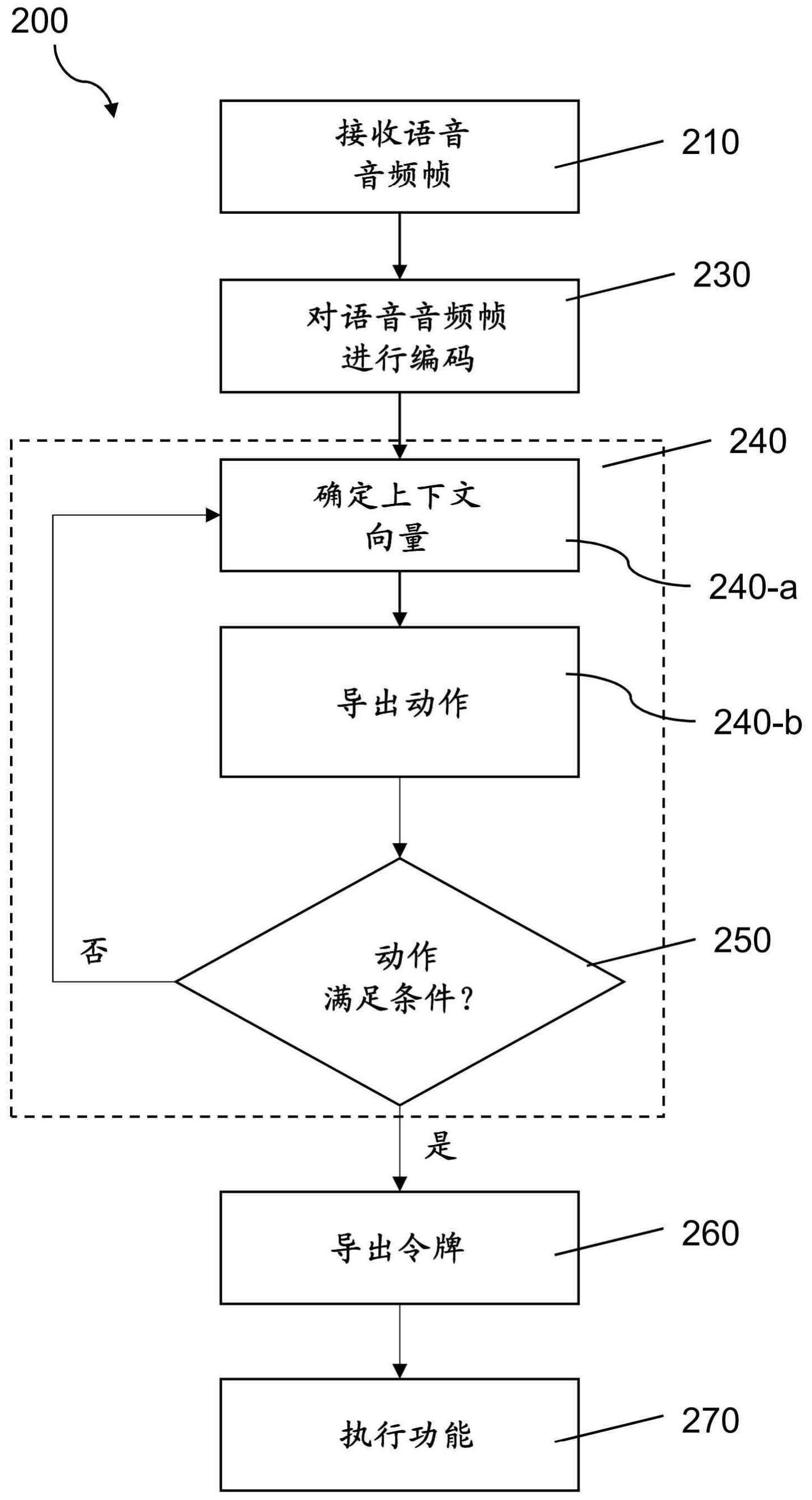
1.一种计算机实现的用于语音识别的方法,所述方法包括:
2.按照权利要求1所述的方法,其中通过代理导出所述动作,其中所述代理包括经训练的模型,并且其中导出所述动作包括:
3.按照权利要求2所述的方法,其中从所述经训练的模型确定第一概率包括:
4.按照权利要求2或3所述的方法,其中所述代理包括深度神经网络。
5.按照任意前述权利要求所述的方法,其中使用解码器神经网络的自注意力解码器层计算第一概率。
6.按照权利要求5所述的方法,其中确定所述上下文向量包括使用从之前的语音音频帧确定的上下文向量。
7.按照权利要求5或6所述的方法,其中确定所述上下文向量包括:
8.按照权利要求7所述的方法,其中确定所述上下文向量包括:
9.按照权利要求5至8中的任意一项所述的方法,其中所述自注意力解码器层是包括多个注意力头的多头自注意力解码器层,并且其中使用所述多个注意力头中的注意力头计算停止概率。
10.按照权利要求9所述的方法,其中确定所述上下文向量包括从所述多个注意力头中的每一个确定第一上下文向量,并且连结所确定的第一上下文向量以获得所述上下文向量。
11.按照权利要求5至10中的任意一项所述的方法,包括将所确定的第二概率相加到累加器变量,并且其中
12.按照权利要求1所述的方法,其中所述动作对应于第三概率,其中所述动作是通过停止选择器导出的,所述停止选择器被配置为生成第三概率,其中第三概率表示应从所述上下文向量导出令牌的概率。
13.一种计算机实现的用于训练语音识别系统的方法,所述方法包括:对于包括语音音频帧和训练令牌的训练数据,
14.按照权利要求13所述的方法,其中确定所述奖励包括:
15.按照权利要求14所述的方法,其中:
16.按照权利要求15所述的方法,其中第一值为零,第二值和第三值为负值。
17.按照权利要求13至16中的任意一项所述的方法,其中确定所述上下文向量包括:
18.按照权利要求17所述的方法,其中当所述累加器变量小于所述预定阈值时,满足所述预定条件。
19.一种包括计算机可读代码的载体介质,所述计算机可读代码被配置为使计算机执行按照前述权利要求中的任意一项所述的方法。
20.一种用于语音识别的系统,所述系统包括处理器,所述处理器被配置为:
技术总结
用于语音识别的系统和方法。一种计算机实现的用于语音识别的方法,所述方法包括:接收语音音频帧;对接收的帧进行编码;从接收的帧的编码确定上下文向量;从所述上下文向量导出动作;响应于所述动作满足预定条件,从所述上下文向量导出令牌;以及基于所述令牌执行功能,其中所述功能包括文本输出或命令执行中的至少一个。
技术研发人员:李沫含,R·S·多迪帕特拉
受保护的技术使用者:株式会社东芝
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!