一种鼾声分类方法及装置
1.本技术请求保护一种声音分类技术,尤其涉及一种鼾声分类方法。本技术还涉及一种鼾声分类装置。
背景技术:
2.阻塞性睡眠呼吸暂停低通气综合征(osahs)严重危害患者身体健康,鼾声的检测与分类作为诊断osahs的重要标志,已成为现阶段的研究热点。
3.现阶段常采用人工切割标注,即分别通过人耳和psg数据对齐的方式对整夜录音进行切割标注。在鼾声分类方法的研究中,主要采用两步分类实现:鼾声/非鼾声分类、osahs患者鼾声/正常鼾声分类。具体的,首先基于图谱特征和神经网络的方法应用于鼾声和非鼾声的分类;其次基于声学特征和机器学习分类器的方法,对osahs患者鼾声和正常鼾声进行分类。
4.医院通过多导睡眠图(psg)对osahs进行诊断,但psg法成本较高,不具备普适性。因此,提出一种简洁、高效的鼾声分类算法应用于临床诊断迫在眉睫。
技术实现要素:
5.为了解决上述背景技术中提出的一个或者多个问题,本技术提出一种鼾声分类方法。本技术还涉及一种鼾声分类装置。
6.本技术提出的一种鼾声分类方法,包括:
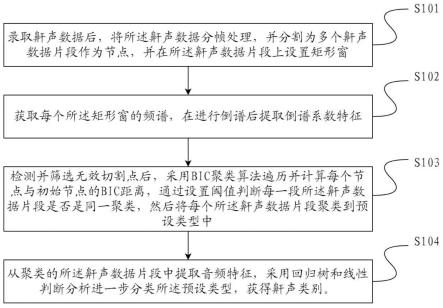
7.录取鼾声数据后,将所述鼾声数据分帧处理,并分割为多个鼾声数据片段作为节点,并在所述鼾声数据片段上设置矩形窗;
8.获取每个所述矩形窗的频谱,在进行倒谱后提取倒谱系数特征;
9.检测并筛选无效切割点后,采用bic聚类算法遍历并计算每个节点与初始节点的bic距离,通过设置阈值判断每一段所述鼾声数据片段是否是同一聚类,然后将每个所述鼾声数据片段聚类到预设类型中;
10.从聚类的所述鼾声数据片段中提取音频特征,采用回归树和线性判断分析进一步分类所述预设类型,获得鼾声类别。
11.可选的,所述预设类型包括:患者鼾声、正常鼾声和非鼾声。
12.可选的,所述提取倒谱系数特征,包括:
13.针对每个所述矩形框,采用傅里叶变化得到频谱;
14.将所述频谱通过梅尔滤波器组得到mel频谱,并进行倒谱后提取倒谱系数特征。
15.可选的,所述筛选无效切割点包括:利用语音端点检测算法进行筛选。
16.可选的,所述音频特征包括:mfcc、频谱带宽和色度频率。
17.本技术还提出一种鼾声分类装置,包括:
18.处理模块,用于录取鼾声数据后,将所述鼾声数据分帧处理,并分割为多个鼾声数据片段作为节点,并在所述鼾声数据片段上设置矩形窗;
19.倒谱模块,用于获取每个所述矩形窗的频谱,在进行倒谱后提取倒谱系数特征;
20.聚类模块,用于检测并筛选无效切割点后,采用bic聚类算法遍历并计算每个节点与初始节点的bic距离,通过设置阈值判断每一段所述鼾声数据片段是否是同一聚类,然后将每个所述鼾声数据片段聚类到预设类型中;
21.分类模块,用于从聚类的所述鼾声数据片段中提取音频特征,采用回归树和线性判断分析进一步分类所述预设类型,获得鼾声类别。
22.可选的,所述预设类型包括:患者鼾声、正常鼾声和非鼾声。
23.可选的,所述提取倒谱系数特征,包括:
24.针对每个所述矩形框,采用傅里叶变化得到频谱;
25.将所述频谱通过梅尔滤波器组得到mel频谱,并进行倒谱后提取倒谱系数特征。
26.可选的,所述筛选无效切割点包括:利用语音端点检测算法进行筛选。
27.可选的,所述音频特征包括:mfcc、频谱带宽和色度频率。
28.本技术相较于现有技术的优点是:
29.本技术提出的一种鼾声分类方法,包括:录取鼾声数据后,将所述鼾声数据分帧处理,并分割为多个鼾声数据片段作为节点,并在所述鼾声数据片段上设置矩形窗;获取每个所述矩形窗的频谱,在进行倒谱后提取倒谱系数特征;检测并筛选无效切割点后,采用bic聚类算法遍历并计算每个节点与初始节点的bic距离,通过设置阈值判断每一段所述鼾声数据片段是否是同一聚类,然后将每个所述鼾声数据片段聚类到预设类型中;从聚类的所述鼾声数据片段中提取音频特征,采用回归树和线性判断分析进一步分类所述预设类型,获得鼾声类别。本技术通过切割聚类,切割后的片段无需进行二次划分,在此基础上利用cl算法将鼾声的两步分类过程优化为一步,简化过程并提高分类准确率,便于快速实现osahs患者的辅助筛查。
附图说明
30.图1是本技术中鼾声分类流程示意图。
31.图2是本技术中鼾声分类步骤示意图。
32.图3是本技术中鼾声分类装置结构示意图。
具体实施方式
33.以下内容均是为了详细说明本技术要保护的技术方案所提供的具体实施过程的示例,但是本技术还可以采用不同于此的描述的其他方式实施,本领域技术人员可以在本技术构思的指引下,采用不同的技术手段实现本技术,因此本技术不受下面具体实施例的限制。
34.本技术提出的一种鼾声分类方法,包括:录取鼾声数据后,将所述鼾声数据分帧处理,并分割为多个鼾声数据片段作为节点,并在所述鼾声数据片段上设置矩形窗;获取每个所述矩形窗的频谱,在进行倒谱后提取倒谱系数特征;检测并筛选无效切割点后,采用bic聚类算法遍历并计算每个节点与初始节点的bic距离,通过设置阈值判断每一段所述鼾声数据片段是否是同一聚类,然后将每个所述鼾声数据片段聚类到预设类型中;从聚类的所述鼾声数据片段中提取音频特征,采用回归树和线性判断分析进一步分类所述预设类型,
获得鼾声类别。本技术通过切割聚类,切割后的片段无需进行二次划分,在此基础上利用cl算法将鼾声的两步分类过程优化为一步,简化过程并提高分类准确率,便于快速实现osahs患者的辅助筛查。
35.图1是本技术中鼾声分类方法流程示意图,图2是本技术中鼾声分类步骤示意图。
36.请参照图1以及图2所示,s101录取鼾声数据后,将所述鼾声数据分帧处理,并分割为多个鼾声数据片段作为节点,并在所述鼾声数据片段上设置矩形窗。
37.将夜间实录鼾声作为输入的录取的鼾声数据,对整个鼾声数据的信号进行分帧处理(帧长为25ms,帧移为10ms),分割成多个片段后加矩形窗。
38.请参照图1以及图2所示,s102获取每个所述矩形窗的频谱,在进行倒谱后提取倒谱系数特征。
39.对每个短时分析窗(矩形窗),通过快速傅里叶变换得到对应的频谱,将频谱通过梅尔(mel)滤波器组得到mel频谱,对其进行倒谱分析,即可从音频信息中提取出梅尔频率倒谱系数(mfcc)特征。
40.请参照图1以及图2所示,s103检测并筛选无效切割点后,采用bic聚类算法遍历并计算每个节点与初始节点的bic距离,通过设置阈值判断每一段所述鼾声数据片段是否是同一聚类,然后将每个所述鼾声数据片段聚类到预设类型中。
41.通过贝叶斯信息准则(bayesian information criterion,bic)检测算法,利用bic值来判断在当前窗口范围内是否存在切割点,通过移动检测窗口和调整窗口大小来实现多切割点检测。
42.其次利用语音端点检测(voice activity detection,vad)算法筛选无效切割点。
43.具体的,所示bic检测算法步骤如下:
44.实录鼾声信号包含osahs(阻塞性睡眠呼吸暂停低通气综合征)患者鼾声、正常鼾声和非鼾声,切割点的检测可视为统计学上的模型选择问题,通常以bic作为判定准则并选择bic值小的模型。为避免过拟合,bic中似然函数要加上与模型拟合参数相关的惩罚项。
45.将实录鼾声信号的特征序列建模成独立多元高斯过程:
[0046][0047]
其中,在提取实录鼾声的mfcc特征时,xi作为从实录鼾声音频流中提取的特征向量序列,其中d是特征向量维数,n是特征向量个数。μi和σi分别是xi的均值向量和协方差矩阵。
[0048]
例如:一段鼾声音频在第i时刻有一个跳变点,寻找跳变点的问题可看作对以下两个模型进行选择的问题,则:
[0049][0050][0051]
若存在跳变点,则模型h1的对数最大似然比为:
[0052]
r(i)=n ln|σ|-n
1 ln|σ1|-n
2 ln|σ2|
ꢀꢀꢀ
(4)
[0053]
其中:n=n1+n2,n1和∑1分别是{x1…
xi}的特征向量个数和协方差矩阵,n2和∑2分别是{x
i+1
…
xn}的特征向量个数和协方差矩阵,符号|∑|代表矩阵∑的行列式。
[0054]
因此,跳变点的最大似然估计如下:
[0055][0056]
比较两个模型:h1将xi建模为两个高斯过程,h0将xi建模为一个高斯过程。这两个模型的bic值之差可表示为:
[0057]
bic(i)=r(i)-λp
ꢀꢀꢀ
(6)
[0058]
其中,惩罚项权重λ一般取1,惩罚项p表示为:
[0059][0060]
因此,若式(6)为正,则采用两个高斯过程的模型h1,即存在一个跳变点。所以若则表示此时有两个独立的鼾声音频分段,存在一个切割点;反之若则表示此时只有一个独立的鼾声音频分段,没有切割点。
[0061]
但上述步骤中,仅对鼾声进行单切割点检测,因此提出一种多切割点bic检测算法。具体流程如下:
[0062]
首先设置一个检测窗口,通过bic检测算法判断在当前窗口范围内是否存在切割点;
[0063]
若存在切割点,则该窗口继续移动,且窗口大小不进行调整;
[0064]
反之,则调整窗口的上限。最后,重复上述过程直至检测窗口的上限超出整段音频的终点。
[0065]
进一步的,为解决起始带噪静音段终止点无效切割的问题,本技术还提出利用vad检测算法对切割点进行筛选,设计思路如下:
[0066]
利用多切割点检测算法对处理后的切割点进行音频分段和vad检测,若检测有语音端点,则不处理;反之,则剔除该切割点。
[0067]
具体的,vad算法常用短时能量(short time energy,ste)和短时过零率(zero cross counter,zcc)判别语音信号和非语音信号。信噪比较大时,ste》zcc,而非语音信号的ste《zcc。因此,可利用ste和zcc的大小直接判别语音信号和非语音信号。
[0068]
本技术中,切割后的实录鼾声数据片段还需进行标注,才能用于后续的分类训练。基于此,为提高标注效率提出实录鼾声的bic聚类算法。
[0069]
具体的,假设s={si:i=1,
…
,m}是切割后的实录鼾声音频片段的集合;是从第i段提取的mfcc特征向量;n=∑ini表示mfcc特征向量χi的总样本大小;是有k个簇的聚类,把每个簇ci看作是一个多元的高斯分布:
[0070][0071]
其中,μi和∑i分别是ci的均值向量和协方差矩阵。因此每个簇的参数数量为d是特征向量维数。ni是簇ci中的样本数。进一步的,由上述bic算法原理可知:
[0072][0073][0074]
其中:惩罚项p权重λ一般取1。
[0075]
以切割后的实录鼾声信号作为节点,依据距离度量连续合并两个最近的节点。s={s1,
…
,sk}是当前的节点集;s1和s2是候选的一对合并节点,合并后的新节点是s。因此,将当前的聚类s与新的聚类s
′
={s,s3,
…
,sk}进行比较。将每个节点si建模为多元高斯分布由式(9)可以看出,通过合并s1和s2,bic值为:
[0076]
bic=nln|∑|-n
1 ln|∑1|-n
2 ln|∑2|-λp
ꢀꢀꢀ
(11)
[0077]
其中中,n=n1+n2是合并节点的样本数量,∑是合并节点的样本协方差矩阵。若式(11)为负,则两个节点不合并。
[0078]
提出采用式(11)作为bic的距离度量,同时利用节点的mfcc特征作为初始点,遍历其余节点,计算每个节点与初始点间的bic距离。此外,设置bic距离阈值,确定该段是否与初始点位于同一类簇中,实现osahs患者鼾声、正常鼾声和非鼾声的聚类。
[0079]
请参照图1以及图2所示,s104从聚类的所述鼾声数据片段中提取音频特征,采用回归树和线性判断分析进一步分类所述预设类型,获得鼾声类别。
[0080]
对于分类而言,尽可能选择“纯度”最高的特征让划分后的样本都属于同一类。基尼系数(gini)作为判别数据“纯度”的指标,在大数据量问题上,具有运行速度快的优势。
[0081]
cart(回归树)是依据gini系数选择最优特征并生成二叉决策树的分类模型。bv算法是一个用来解编码函数的量子算法,本技术中,bv算法切割聚类后的实录鼾声数据集为d,若从中提取的特征之一为a,以特征a作为划分指标,将数据集d划分为两部分d1和d2,则在特征a条件下的gini系数为:
[0082][0083][0084]
其中di是dk部分第i类的样本,c是实录鼾声中所含音频的类别数。将划分后gini系数最小的特征作为最优特征的评判标准。
[0085]
经过cart模型特征选择后的最优特征集中包含mfcc等高维度特征,算法的维数与复杂度呈指数级增涨;同时,现阶段两步分类法过程复杂且一步分类法准确率不高。
[0086]
在本技术中,保留cart模型计算速度快,并且使用gini系数能有效选择最优特征的优点,引入lda算法(线性判断降维算法)进行特征降维,节约模型训练时间,去除数据冗余,提高算法的分类准确率。
[0087]
具体的,lda算法是通过投影的方式去除数据之间冗余。假设有两类数据(osahs患者鼾声和正常鼾声),实录鼾声样本xi∈rd,其中维数d=2;所有类别为ci的样本集di={xj|
yj=ci}。所有鼾声数据xi投影到单位向量ω后,其均值表示为:
[0088][0089]
其中,ai是xi在ω上的偏移或者坐标,表示做了一个映射rd→
r,即通过投影将d维向量降到一维;μ1和n1分别是样本集d1的均值向量和样本数。同理,样本集d2的均值向量μ2,投影后的均值m2=ω
t
μ2。
[0090]
为使投影后的鼾声数据能准确分类,这两类鼾声数据的中心距离越远越好,即要使|m
1-m2|最大。但该条件不能保证能正确地对每一个数据进行分类,还需考虑每一类数据的方差,方差大表示两类数据之间有重叠,方差小表示无重叠。
[0091]
lda算法未采用方差,而采用散布矩阵,即:
[0092][0093]
利用式(15)和|m
1-m2|可得优化公式,见式(16)。
[0094][0095]
其中,b=(μ
1-μ2)(μ
1-μ2)
t
,s=s1+s2。
[0096]
进一步的,对式(16)求导得:
[0097][0098]
其中,λ=j(ω);λ为常量;s为非奇异矩阵。
[0099]
上述算法仅适合二分类问题,为实现osahs患者鼾声、正常鼾声和非鼾声的三分类,提出采用式(18)计算s-1
b对应的最大特征值的特征向量。
[0100][0101]
其中,c为实录鼾声中所含音频的类别数,μ为整个实录鼾声样本的均值向量,ni和μi分别为第i类中样本个数和均值向量。
[0102]
总的来说,提出的上述分类算法的基本思想如下:
[0103]
首先,利用cart模型进行最优特征选择;
[0104]
其次,计算每一类的协方差矩阵si,i=1,2,3,并依据式(18)计算矩阵b,并计算s-1
b的特征向量q=[ω1,ω2,
…
,ωd],其中ω1,ω2,
…
,ωd对应的特征值满足λ1≥λ2≥
…
≥λd,矩阵w=[ω1,ω2,
…
,ωk]由q中前k个特征向量组成,其中k《d;最后,对原实录鼾声数据x进行投影:
[0105]
y=xw
ꢀꢀꢀ
(19)
[0106]
其中,y为分类后的数据集;x为原始数据集;
[0107]
子空间
[0108]
最后,获得最终的获得鼾声类别。
[0109]
本技术还提供一种鼾声分类装置,包括:处理模块301,倒谱模块302,聚类模块303和分类模块304。
[0110]
图3是本技术中鼾声分类装置结构示意图。
[0111]
请参照图3所示,处理模块301,用于录取鼾声数据后,将所述鼾声数据分帧处理,并分割为多个鼾声数据片段作为节点,并在所述鼾声数据片段上设置矩形窗。
[0112]
将夜间实录鼾声作为输入的录取的鼾声数据,对整个鼾声数据的信号进行分帧处理(帧长为25ms,帧移为10ms),分割成多个片段后加矩形窗。
[0113]
请参照图3所示,倒谱模块302,用于获取每个所述矩形窗的频谱,在进行倒谱后提取倒谱系数特征。
[0114]
对每个短时分析窗(矩形窗),通过快速傅里叶变换得到对应的频谱,将频谱通过梅尔(mel)滤波器组得到mel频谱,对其进行倒谱分析,即可从音频信息中提取出梅尔频率倒谱系数(mfcc)特征。
[0115]
请参照图3所示,聚类模块303,用于检测并筛选无效切割点后,采用bic聚类算法遍历并计算每个节点与初始节点的bic距离,通过设置阈值判断每一段所述鼾声数据片段是否是同一聚类,然后将每个所述鼾声数据片段聚类到预设类型中。
[0116]
通过贝叶斯信息准则(bayesian information criterion,bic)检测算法,利用bic值来判断在当前窗口范围内是否存在切割点,通过移动检测窗口和调整窗口大小来实现多切割点检测。
[0117]
其次利用语音端点检测(voice activity detection,vad)算法筛选无效切割点。
[0118]
具体的,所示bic检测算法步骤如下:
[0119]
实录鼾声信号包含osahs(阻塞性睡眠呼吸暂停低通气综合征)患者鼾声、正常鼾声和非鼾声,切割点的检测可视为统计学上的模型选择问题,通常以bic作为判定准则并选择bic值小的模型。为避免过拟合,bic中似然函数要加上与模型拟合参数相关的惩罚项。
[0120]
将实录鼾声信号的特征序列建模成独立多元高斯过程:
[0121][0122]
其中,在提取实录鼾声的mfcc特征时,xi作为从实录鼾声音频流中提取的特征向量序列,其中d是特征向量维数,n是特征向量个数。μi和σi分别是xi的均值向量和协方差矩阵。
[0123]
例如:一段鼾声音频在第i时刻有一个跳变点,寻找跳变点的问题可看作对以下两个模型进行选择的问题,则:
[0124][0125][0126]
若存在跳变点,则模型h1的对数最大似然比为:
[0127]
r(i)=n ln|σ|-n
1 ln|σ1|-n
2 ln|σ2|
ꢀꢀꢀ
(4)
[0128]
其中:n=n1+n2,n1和∑1分别是{x1…
xi}的特征向量个数和协方差矩阵,n2和∑2分
别是{x
i+1
…
xn}的特征向量个数和协方差矩阵,符号|∑|代表矩阵∑的行列式。
[0129]
因此,跳变点的最大似然估计如下:
[0130][0131]
比较两个模型:h1将xi建模为两个高斯过程,h0将xi建模为一个高斯过程。这两个模型的bic值之差可表示为:
[0132]
bic(i)=r(i)-λp
ꢀꢀꢀ
(6)
[0133]
其中,惩罚项权重λ一般取1,惩罚项p表示为:
[0134][0135]
因此,若式(6)为正,则采用两个高斯过程的模型h1,即存在一个跳变点。所以若则表示此时有两个独立的鼾声音频分段,存在一个切割点;反之若则表示此时只有一个独立的鼾声音频分段,没有切割点。
[0136]
但上述步骤中,仅对鼾声进行单切割点检测,因此提出一种多切割点bic检测算法。具体流程如下:
[0137]
首先设置一个检测窗口,通过bic检测算法判断在当前窗口范围内是否存在切割点;
[0138]
若存在切割点,则该窗口继续移动,且窗口大小不进行调整;
[0139]
反之,则调整窗口的上限。最后,重复上述过程直至检测窗口的上限超出整段音频的终点。
[0140]
进一步的,为解决起始带噪静音段终止点无效切割的问题,本技术还提出利用vad检测算法对切割点进行筛选,设计思路如下:
[0141]
利用多切割点检测算法对处理后的切割点进行音频分段和vad检测,若检测有语音端点,则不处理;反之,则剔除该切割点。
[0142]
具体的,vad算法常用短时能量(short time energy,ste)和短时过零率(zero cross counter,zcc)判别语音信号和非语音信号。信噪比较大时,ste》zcc,而非语音信号的ste《zcc。因此,可利用ste和zcc的大小直接判别语音信号和非语音信号。
[0143]
本技术中,切割后的实录鼾声数据片段还需进行标注,才能用于后续的分类训练。基于此,为提高标注效率提出实录鼾声的bic聚类算法。
[0144]
具体的,假设s={si:i=1,
…
,m}是切割后的实录鼾声音频片段的集合;是从第i段提取的mfcc特征向量;n=∑ini表示mfcc特征向量χi的总样本大小;是有k个簇的聚类,把每个簇ci看作是一个多元的高斯分布:
[0145][0146]
其中,μi和∑i分别是ci的均值向量和协方差矩阵。因此每个簇的参数数量为d是特征向量维数。ni是簇ci中的样本数。进一步的,由上述bic算法原理
可知:
[0147][0148][0149]
其中:惩罚项p权重λ一般取1。
[0150]
以切割后的实录鼾声信号作为节点,依据距离度量连续合并两个最近的节点。s={s1,
…
,sk}是当前的节点集;s1和s2是候选的一对合并节点,合并后的新节点是s。因此,将当前的聚类s与新的聚类s
′
={s,s3,
…
,sk}进行比较。将每个节点si建模为多元高斯分布由式(9)可以看出,通过合并s1和s2,bic值为:
[0151]
bic=nln|∑|-n
1 ln|1|-n
2 ln|∑2|-λp
ꢀꢀꢀ
(11)
[0152]
其中中,n=n1+n2是合并节点的样本数量,∑是合并节点的样本协方差矩阵。若式(11)为负,则两个节点不合并。
[0153]
提出采用式(11)作为bic的距离度量,同时利用节点的mfcc特征作为初始点,遍历其余节点,计算每个节点与初始点间的bic距离。此外,设置bic距离阈值,确定该段是否与初始点位于同一类簇中,实现osahs患者鼾声、正常鼾声和非鼾声的聚类。
[0154]
请参照图3所示,分类模块304,用于从聚类的所述鼾声数据片段中提取音频特征,采用回归树和线性判断分析进一步分类所述预设类型,获得鼾声类别。
[0155]
对于分类而言,尽可能选择“纯度”最高的特征让划分后的样本都属于同一类。基尼系数(gini)作为判别数据“纯度”的指标,在大数据量问题上,具有运行速度快的优势。
[0156]
cart(回归树)是依据gini系数选择最优特征并生成二叉决策树的分类模型。bv算法是一个用来解编码函数的量子算法,本技术中,bv算法切割聚类后的实录鼾声数据集为d,若从中提取的特征之一为a,以特征a作为划分指标,将数据集d划分为两部分d1和d2,则在特征a条件下的gini系数为:
[0157][0158][0159]
其中di是dk部分第i类的样本,c是实录鼾声中所含音频的类别数。将划分后gini系数最小的特征作为最优特征的评判标准。
[0160]
经过cart模型特征选择后的最优特征集中包含mfcc等高维度特征,算法的维数与复杂度呈指数级增涨;同时,现阶段两步分类法过程复杂且一步分类法准确率不高。
[0161]
在本技术中,保留cart模型计算速度快,并且使用gini系数能有效选择最优特征的优点,引入lda算法(线性判断降维算法)进行特征降维,节约模型训练时间,去除数据冗余,提高算法的分类准确率。
[0162]
具体的,lda算法是通过投影的方式去除数据之间冗余。假设有两类数据(osahs患
者鼾声和正常鼾声),实录鼾声样本xi∈rd,其中维数d=2;所有类别为ci的样本集di={xj|yj=ci}。所有鼾声数据xi投影到单位向量ω后,其均值表示为:
[0163][0164]
其中,ai是xi在ω上的偏移或者坐标,表示做了一个映射rd→
r,即通过投影将d维向量降到一维;μ1和n1分别是样本集d1的均值向量和样本数。同理,样本集d2的均值向量μ2,投影后的均值m2=ω
t
μ2。
[0165]
为使投影后的鼾声数据能准确分类,这两类鼾声数据的中心距离越远越好,即要使|m
1-m2|最大。但该条件不能保证能正确地对每一个数据进行分类,还需考虑每一类数据的方差,方差大表示两类数据之间有重叠,方差小表示无重叠。
[0166]
lda算法未采用方差,而采用散布矩阵,即:
[0167][0168]
利用式(15)和|m
1-m2|可得优化公式,见式(16)。
[0169][0170]
其中,b=(μ
1-μ2)(μ
1-μ2)
t
,s=s1+s2。
[0171]
进一步的,对式(16)求导得:
[0172][0173]
其中,λ=j(ω);λ为常量;s为非奇异矩阵。
[0174]
上述算法仅适合二分类问题,为实现osahs患者鼾声、正常鼾声和非鼾声的三分类,提出采用式(18)计算s-1
b对应的最大特征值的特征向量。
[0175][0176]
其中,c为实录鼾声中所含音频的类别数,μ为整个实录鼾声样本的均值向量,ni和μi分别为第i类中样本个数和均值向量。
[0177]
总的来说,提出的上述分类算法的基本思想如下:
[0178]
首先,利用cart模型进行最优特征选择;
[0179]
其次,计算每一类的协方差矩阵si,i=1,2,3,并依据式(18)计算矩阵b,并计算s-1
b的特征向量q=[ω1,ω2,
…
,ωd],其中ω1,ω2,
…
,ωd对应的特征值满足λ1≥λ2≥
…
≥λd,矩阵w=[ω1,ω2,
…
,ωk]由q中前k个特征向量组成,其中k《d;最后,对原实录鼾声数据x进行投影:
[0180]
y=xw
ꢀꢀꢀ
(19)
[0181]
其中,y为分类后的数据集;x为原始数据集;
[0182]
子空间
[0183]
最后,获得最终的获得鼾声类别。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1