卷积循环神经网络、语音增强方法及装置与流程
1.本发明属于智能语音技术领域,涉及语音增强技术,具体涉及一种卷积循环神经网络、语音增强方法及装置。
背景技术:
2.语音增强技术一直以来都是智能语音技术领域的热门研究方向。最近几年,由于深度学习技术的快速发展,将深度学习方法应用于语音增强技术的方法也层出不穷,且取得了良好的效果。
3.卷积循环神经网络是一种将卷积神经网络和循环神经网络有效结合起来的神经网络。由于卷积循环神经网络既包含有卷积神经网络,可以有效提取语音信号局部特征,又包含有循环神经网络,可以有效处理时间序列信号。因此,卷积循环神经网络在语音增强处理上得到广泛运用。如西北工业大学谢磊老师实验室提出的深度复数卷积循环网络(deep complex convolution recurrent network,dccrn),南京大学现代声学实验室乐小怀等人提出的双路径卷积循环网络(dual-path convolution recurrent network,dpcrn)等,均在噪声抑制,语音增强上取得了很不错的效果。但由于这些神经网络大多是在短时傅里叶变换后进行处理,需要对信号的实部和虚部分别处理或者直接进行复数形式处理,这使得模型的参数量和计算量都较大,给嵌入式系统移植部署带来很大的挑战。
技术实现要素:
4.为了减少模型参数量和计算量,使得设计的卷积循环神经网络满足实时计算和适合嵌入式系统移植。在参考双路径卷积循环网络模型的基础上,本发明公开了一种卷积循环神经网络、语音增强方法及装置。
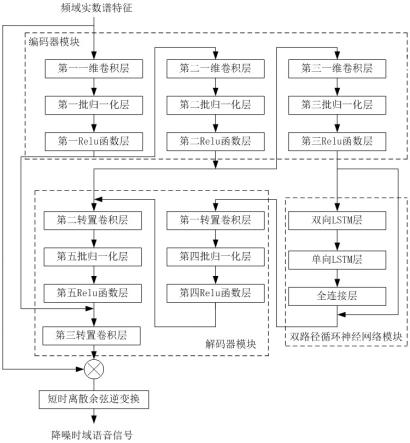
5.本发明所述卷积循环神经网络,包括依次串联的编码器模块、双路径循环神经网络模块及解码器模块:所述编码器模块包括3个依次串联的第一至第三一维卷积模块,各个一维卷积模块包括依次串联的一维卷积层、批归一化层和激活函数层 ;所述双路径循环神经网络模块包括依次串联的双向长短时记忆网络层,单向长短时记忆网络层和全连接层;所述双向长短时记忆网络层的输入端还与所述全连接层的输出端连接;所述解码器模块包括两个串联的第一转置卷积模块和第二转置卷积模块,所述第一转置卷积模块包括依次串联的第一转置卷积层、批归一化层和激活函数层,所述第二转置卷积模块包括依次串联的第二转置卷积层、批归一化层、激活函数层和第三转置卷积层;所述第一一维卷积模块的激活函数层输出端还与第二转置卷积模块的第三转置卷积层输入端连接,所述第二一维卷积模块的激活函数层输出端还与第二转置卷积模块的第二转置卷积层输入端连接。
6.优选的,所述激活函数层为relu函数层。
7.本发明所述语音增强方法,包括如下步骤:步骤1.对获取的带噪混合语音时域信号进行短时离散余弦变换处理,得到每帧信号的频域实数谱特征;步骤2.将频域实数谱特征输入卷积循环神经网络模型的输入端进行前向推理,得到带噪混合语音的实数谱掩蔽值,并将掩蔽值与所述频域实数谱特征相乘;步骤3.将相乘结果进行短时离散余弦逆变换,得到降噪后的时域语音信号;所述卷积循环神经网络为如前所述卷积循环神经网络。
8.优选的,步骤1具体为,对获取的带噪混合语音时域信号进行分帧加窗处理,对分帧加窗后的每帧信号进行短时离散余弦逆变换,得到所述频域实数谱特征。
9.本发明所述语音增强装置,包括如下组成部分:音频分析模块:用于对拾音设备采集的原始带噪混合语音进行分帧加窗及短时离散余弦变换,得到所述带噪混合语音的频域实数谱。
10.音频处理模块:用于将所述带噪混合语音的频域实数谱输入卷积循环神经网络模型,得到所述带噪混合语音的频域实数谱掩蔽值;其中音频处理模块包含能进行卷积神经网络、激活函数层和全连接层硬件加速的神经网络加速器。
11.音频输出模块:用于将频域实数谱掩蔽值与所述频域实数谱特征相乘,并进行合帧合窗及短时离散余弦逆变换,得到降噪后的时域语音信号。
12.本发明所述卷积循环神经网络及语音增强方法,通过多层一维卷积层架构设计,既保证提取局部特征的技术效果,又相对现有技术采用的二维卷积层减少了参数量,能够满足实时计算要求和适合嵌入式系统移植,通过构造一个参数量较小的神经网络模型,达到嵌入式端语音增强的目的。
附图说明
13.图1为本发明所述卷积循环神经网络及利用该网络进行语音增强的一种具体实施方式示意图;图2为本发明所述卷积循环神经网络装置的示意图。
具体实施方式
14.下面对本发明的具体实施方式作进一步的详细说明。
15.本发明所述卷积循环神经网络,包括依次串联的编码器模块、双路径循环神经网络模块及解码器模块:所述编码器模块包括3个依次串联的第一至第三一维卷积模块,各个一维卷积模块包括依次串联的一维卷积层、批归一化层和激活函数层 ;所述双路径循环神经网络模块包括依次串联的双向lstm层,单向lstm层和全连接层;所述双向lstm 层的输入端还与所述全连接层的输出端连接;所述解码器模块包括两个串联的第一转置卷积模块和第二转置卷积模块,所述第一转置卷积模块包括依次串联的第一转置卷积层、批归一化层和激活函数层,所述第二转置卷积模块包括依次串联的第二转置卷积层、批归一化层、激活函数层和第三转置卷积层;
所述第一一维卷积模块的激活函数层输出端还与第二转置卷积模块的第三转置卷积层输入端连接,所述第二一维卷积模块的激活函数层输出端还与第二转置卷积模块的第二转置卷积层输入端连接。
16.所述编码器模块由依次串联的第一至第三一维卷积模块构成,为防止带噪混合语音信号在处理过程中出现幅值溢出现象,一维卷积模块中每个卷积层后带有一个批归一化层(batch normalization,bn)和激活函数层。
17.其中,如图1所示的具体实施方式中,激活函数层优选线性整流函数(linear rectification function,relu)作为激活函数。相比于sigmoid激活函数和tanh激活函数,relu函数可大大减少激活层的计算时间。其中,第一一维卷积层的输入为步骤1中输出的频域实数谱特征;其他层的输入均为上一层的输出。
18.所述双路径循环神经网络模块包括两个长短时记忆网络(lstm)层和一个全连接层。第一个lstm层为双向lstm层,其数据流向是在频域轴方向双向流动,其目的在于充分利用语音信号的谐波结构。第二个lstm层为单向lstm层,其数据流向是在时间轴上随时间单向流动,其目的在于利用语音信号是时间上的序列信号特性,单向lstm层可以在语音信号连续帧上的进行时间依赖性建模。最后通过一个全连接层输出单向lstm层处理后的语音信号特征。
19.所述解码器模块包括3个转置卷积层,前两个转置卷积层后分别带有一个bn层和relu函数层,每一个转置卷积层的输入为上一层的输出和其对应的卷积层的输出所连接的数据。最后一个转置卷积层的输出即为实数谱的掩蔽值。
20.下面结合附图对本发明的具体实施方式作进一步的详细说明。
21.利用前述卷积循环神经网络进行语音增强处理的一个具体实施方式如图1所示。
22.步骤1.对获取的带噪混合语音时域信号进行处理,得到每帧信号的频域实数谱特征;一个具体处理方式为:对获取的时域带噪混合语音信号进行分帧加窗处理,帧长可采用512个采样点,帧移为256个采样点。窗函数可采用汉明窗。对分帧加窗后的每帧信号进行短时离散余弦变换,得到每帧信号的512维频域实数谱特征。
23.采用短时离散余弦变换(stdct)的原因在于,stdct作为短时离散傅里叶变换(short-time discrete fourier transform,stdft)的另一种变换,不仅继承了stdft的属性,而且其变换后的频谱值是实数,在神经网络中计算时可以有效减少参数量和计算量。
24.步骤2.将步骤1得到的频域实数谱特征输入卷积循环神经网络中的第一一维卷积层;所述卷积循环神经网络的后续具体处理步骤如下:s11.在第一一维卷积层中进行数据填充;本实施例中,第一一维卷积层中设置卷积核长度为5,步长为2,输出通道为8。通过数据填充后,第一个卷积层的输出数据维度为256x8。
25.将第一一维卷积层的输出数据输入第一批归一化层和第一relu函数层处理,输出数据维度不变的数据;s12.将经过第一relu函数层处理后的数据输入第二一维卷积层,通过数据填充后输出;
其中第二一维卷积层的输出通道大于第一一维卷积层;本实施例中,第二一维卷积层卷积核长度为3,步长为2,输出通道为16。通过数据填充后,第二个卷积层的输出数据维度为128x16。
26.s13.将第二一维卷积层的输出数据先后经第二批归一化层和第二relu函数层处理,输出数据维度不变的数据;s14.将经过第二relu函数层处理后的数据输入第三一维卷积层,通过数据填充后输出;本实施例中,第三一维卷积层卷积核长度为3,步长为2,输出通道为32。通过数据填充后,第二个卷积层的输出数据维度为64x32。
27.s15.继续将第三一维卷积层的输出数据输入第三批归一化层和第三relu函数层处理,输出数据维度不变的数据;s16.将第三relu函数层处理后的数据输入双路径循环神经网络模块的双向lstm层,数据流在频率轴方向双向流动。本实施例中,双向lstm的节点数为32。
28.s17.将经过双向lstm层处理后的数据输入单向lstm层,数据流在时间轴上流动,本实施例中,单向lstm层的节点数为32;s18.将经过单向lstm层处理后的数据通过双路径循环神经网络模块的全连接层输出,本实施例中,全连接层的节点数为32。
29.s19.将s18步骤中全连接层的输出数据与s15步骤中第三relu函数层输出的数据选用按元素相加的连接方式,其目的是既可防止梯度消失,同时可保持数据维度不变。本实施例中,连接后仍以64乘32的数据维度输入解码器模块的第一转置卷积层,卷积核长度为3,步长为2,输出通道为16.。则第一个转置卷积层输出维度为128x16。
30.s20.将第一转置卷积层的输出数据输入第四批归一化层和第四relu函数层处理,得到数据维度不变的输出数据。
31.s21、将s20步骤的输出数据和s13步骤中第二relu函数层的输出数据按元素相加,本实施例中,连接后仍以128x16的数据维度输入第二转置卷积层,卷积核长度为3,步长为2,输出通道为8。则第二个转置卷积层输出维度为256x8。
32.s22.将第二转置卷积层的输出数据输入第五批归一化层和第五relu函数层处理,得到数据维度不变的输出数据。
33.s23.将s22步骤的输出数据和s11步骤中第一relu函数层的输出数据按元素相加,构成256x8的数据维度输入第三个转置卷积层,卷积核长度为5,步长为2,输出通道为1。则第三个转置卷积层输出维度为512x1,即为神经网络模型推理出的带噪混合语音实数谱的掩蔽值。由于编码模块和解码模块是对称结构,s19,s21,s23步骤中将不同模块输出的维度相同的数据按元素相加,可防止梯度消失,同时可保持数据维度不变。
34.s24.将s1步骤中得到的频域实数谱特征乘以s15步骤中掩蔽值,再经过短时离散余弦逆变换(stdct),得到降噪后的时域语音信号。掩蔽值相当于滤波系数,频域实数谱特征与之相乘可得到降噪后的语音。
35.采用本发明所述卷积循环神经网络及语音增强方法,通过多层一维卷积层架构设计,既保证提取局部特征的技术效果,又相对现有技术采用的二维卷积层减少了参数量,能够满足实时计算要求和适合嵌入式系统移植,通过构造一个参数量较小的神经网络模型,达到语音增强的目的。
36.本发明根据上述实施例提供一种语音增强装置,可依靠搭载成都启英泰伦科技有限公司ci130x系列智能语音芯片实现。具体包括进行混合语音采集的拾音设备,如带有麦克风的风扇、空调等产品或者裸露的数字麦克风或模拟麦克风。存储器如sram,rom,flash等,音频分析模块,音频处理模块以及音频输出模块等。
37.音频分析模块可进行信号模数转换,对信号进行分帧加窗及短时离散余弦变换,短时傅里叶变换等。音频处理模块主要对带噪混合语音的频域实数谱进行预训练卷积循环神经网络模型的前向推理,得到所述带噪混合语音的频域实数谱掩蔽值。其中音频处理模块主要包含能进行神经网络层加速运算的神经网络硬件加速器。如卷积神经网络模块加速运算,全连接层加速运算,激活函数层加速运算等,该神经网络加速器通过芯片硬件设计实现,为本领域现有技术。音频输出模块主要对处理后的语音实数谱进行合帧合窗及短时离散余弦逆变换以及包含可进行实时音频录制的iis,iic硬件配置。
38.在本技术所提供的具体实施方式中,所公开的神经网络和各个模块,可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。所述功能可以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个处理器可执行的非易失的计算机或端侧设备可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对于现有技术作出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器或者端侧设备)执行本发明各个实施例所述方法的全部或部分步骤。
39.前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1