一种指令纠正模型训练方法、装置和设备与流程
本技术涉及模型训练,尤其涉及一种指令纠正模型训练方法、装置和设备。
背景技术:
1、现有技术中用户的语音指令不能正确识别时,会出现以下场景:场景1是用户不断地纠正自己的指令甚至是发音,直到设备能够按照用户意图执行相关操作;场景2是用户发出的几次语音指令失败后,从而失去耐心,会采用遥控器或者按键操作设备;在当下信息高速发展的时代,用户更注重工作的准确高效性,以上情形严重影响用户的体验,阻碍用户使用设备的欲望。
2、为了解决上述问题,如果是人群共性的发音问题导致的用户指令识别错误,其中人群共性的发音问题包括方言问题,现有技术中首先采集大量的存在共性问题的语音,建立识别出的语音的错误普通话文本与正确普通话文本的对应关系组成的数据集,并对文本纠正模型进行训练,从而根据训练完成的文本纠正模型实现对语音指令的纠正以及正确识别。
3、图1为现有技术提供的一种指令识别方法的过程示意图,如图1所示,电子设备获取到不清楚的发音指令后,对不清楚的发音指令进行识别得到识别出的错误的文本,基于预先训练完成的文本纠正模型,将错误的文本输入到文本纠正模型后进行纠正,得到纠正后的正确的文本,基于对正确的文本的语义理解控制空调进行正确执行。
4、但是在现实场景中不同用户之间还存在个性化的发音问题,现有技术中无法实现对存在个性化的发音问题的用户语音指令实现准确识别。
技术实现思路
1、本技术提供了一种指令纠正模型训练方法、装置、设备和介质,用以解决现有技术中无法实现对存在个性化的发音问题的用户语音指令实现准确识别的问题。
2、第一方面,本技术提供了一种指令纠正模型训练方法,所述方法包括:
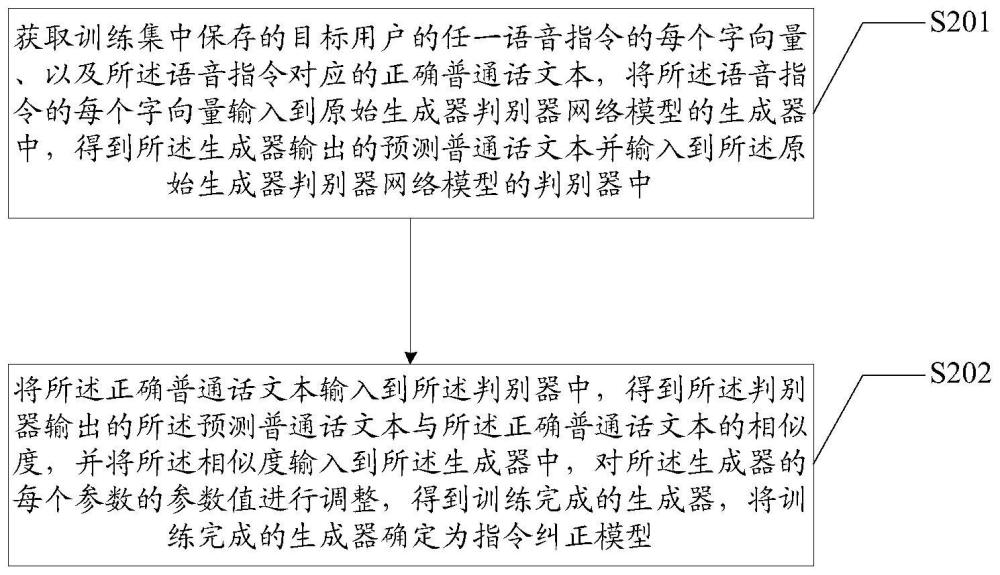
3、获取训练集中保存的目标用户的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本,将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器中,得到所述生成器输出的预测普通话文本并输入到所述原始生成器判别器网络模型的判别器中;
4、将所述正确普通话文本输入到所述判别器中,得到所述判别器输出的所述预测普通话文本与所述正确普通话文本的相似度,并将所述相似度输入到所述生成器中,对所述生成器的每个参数的参数值进行调整,得到训练完成的生成器,将训练完成的生成器确定为指令纠正模型。
5、进一步地,所述获取训练集中保存的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本之前,所述方法还包括:
6、获取采集的所述目标用户的每个语音指令、以及所述每个语音指令对应的每个正确普通话文本;
7、针对所述每个语音指令,识别该语音指令的每个字符,将所述每个字符转换为每个字向量,将该语音指令的每个字向量、以及对应的正确普通话文本保存到训练集中。
8、进一步地,所述获取采集的目标用户的每个语音指令、以及所述每个语音指令对应的每个正确普通话文本包括:
9、获取采集的目标用户的被成功识别的第一语音指令、以及所述第一语音指令采集时间之前的预设时长内采集的每个第二语音指令,确定识别出所述第一语音指令的第一目标普通话文本,将所述每个第二语音指令确定为目标用户的每个语音指令,将所述第一目标普通话文本确定为所述每个语音指令对应的正确普通话文本;或
10、获取输入的目标用户的操作信息对应的目标功能、以及所述操作信息的输入时间之前的预设时长内采集的每个第三语音指令,根据预先保存的每个功能与普通话文本的对应关系,确定所述目标功能对应的第二目标普通话文本,将所述每个第三语音指令确定为目标用户的每个语音指令,将所述第二目标普通话文本确定为所述每个语音指令对应的正确普通话文本。
11、进一步地,所述将所述每个第二语音指令确定为目标用户的每个语音指令之前,所述方法还包括:
12、针对所述每个第二语音指令,确定识别出的该第二语音指令的普通话文本中的每个字符的拼音,根据所述第一目标普通话文本的语句拼音、以及所述每个字符的拼音,确定该第二语音指令的普通话文本与所述第一目标普通话文本的编辑距离;
13、根据每个第二语音指令的编辑距离以及预先保存的编辑距离阈值,确定不大于所述编辑距离阈值的每个目标编辑距离对应的每个目标第二语音指令,将所述每个目标第二语音指令确定为更新后的每个第二语音指令;
14、所述将所述每个第三语音指令确定为目标用户的每个语音指令之前,所述方法还包括:
15、针对所述每个第三语音指令,确定识别出的该第三语音指令的普通话文本中的每个字符的拼音,根据所述第二目标普通话文本的语句拼音、以及所述每个字符的拼音,确定该第三语音指令识别的普通话文本与所述第二目标普通话文本的编辑距离;
16、根据每个第三语音指令的编辑距离以及预先保存的编辑距离阈值,确定不大于所述编辑距离阈值的每个目标编辑距离对应的每个目标第三语音指令,将所述每个目标第三语音指令确定为更新后的每个第三语音指令。
17、进一步地,若所述生成器为采用单注意力机制的编码器解码器模型,所述将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器中,得到所述生成器输出的预测普通话文本包括:
18、将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器的编码器中,得到所述编码器的每一层编码后输出的语义特征向量组成的上下文向量contextvector、以及所述编码器的最后一层编码后输出的隐藏状态;
19、将所述隐藏状态和所述context vector进行拼接后输入到所述生成器的解码器中进行解码,得到所述解码器输出的预测普通话文本。
20、进一步地,若所述生成器为采用双注意力机制的编码器解码器模型,所述获取所述训练集中保存的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本包括:
21、获取所述训练集中保存的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本,并获取预先保存的设备的设备名称编码的词向量构成的词向量矩阵,其中所述词向量矩阵是所述语音指令对应目标设备的设备名称编码的词向量构成的单行词向量矩阵、或是具有所述语音指令对应功能的每个设备的设备名称编码的每个词向量组成的多行词向量矩阵;
22、所述将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器中,得到所述生成器输出的预测普通话文本并输入到判别器中包括:
23、将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器的编码器中,得到所述编码器的每一层编码后输出的语义特征向量组成的上下文向量contextvector、以及所述编码器的最后一层编码后输出的隐藏状态;
24、将所述隐藏状态、所述词向量矩阵和所述context vector进行拼接后输入到所述生成器的解码器中进行解码,得到所述解码器输出的预测普通话文本。
25、进一步地,所述方法还包括:
26、获取待识别的目标语音指令,识别所述目标语音指令的每个目标字符,将所述每个目标字符转换为每个目标字向量;
27、基于预先训练完成的指令纠正模型,将所述每个目标字向量输入所述指令纠正模型,获取所述指令纠正模型输出的纠正后的普通话文本,将所述纠正后的普通话文本确定为目标指令。
28、进一步地,所述方法还包括:
29、获取待识别的目标语音指令、以及预先保存的所述语音指令对应目标设备、或具有所述语音指令对应功能的每个设备的设备名称编码的词向量构成的目标词向量矩阵,识别所述目标语音指令的每个目标字符,将所述每个目标字符转换为每个目标字向量;
30、基于预先训练完成的指令纠正模型,将所述每个目标字向量和所述目标词向量矩阵输入所述指令纠正模型,获取所述指令纠正模型输出的纠正后的普通话文本,将所述纠正后的普通话文本确定为目标指令。
31、第二方面,本技术提供了一种指令纠正模型训练装置,所述装置包括:
32、获取模块,用于获取训练集中保存的目标用户的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本;
33、训练模块,用于将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器中,得到所述生成器输出的预测普通话文本并输入到所述原始生成器判别器网络模型的判别器中;将所述正确普通话文本输入到所述判别器中,得到所述判别器输出的所述预测普通话文本与所述正确普通话文本的相似度,并将所述相似度输入到所述生成器中,对所述生成器的每个参数的参数值进行调整,得到训练完成的生成器,将训练完成的生成器确定为指令纠正模型。
34、进一步地,所述获取模块,还用于所述获取训练集中保存的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本之前,获取采集的所述目标用户的每个语音指令、以及所述每个语音指令对应的每个正确普通话文本;针对所述每个语音指令,识别该语音指令的每个字符,将所述每个字符转换为每个字向量,将该语音指令的每个字向量、以及对应的正确普通话文本保存到训练集中。
35、进一步地,所述获取模块,具体用于获取采集的目标用户的被成功识别的第一语音指令、以及所述第一语音指令采集时间之前的预设时长内采集的每个第二语音指令,确定识别出所述第一语音指令的第一目标普通话文本,将所述每个第二语音指令确定为目标用户的每个语音指令,将所述第一目标普通话文本确定为所述每个语音指令对应的正确普通话文本;或获取输入的目标用户的操作信息对应的目标功能、以及所述操作信息的输入时间之前的预设时长内采集的每个第三语音指令,根据预先保存的每个功能与普通话文本的对应关系,确定所述目标功能对应的第二目标普通话文本,将所述每个第三语音指令确定为目标用户的每个语音指令,将所述第二目标普通话文本确定为所述每个语音指令对应的正确普通话文本。
36、进一步地,所述获取模块,还用于所述将所述每个第二语音指令确定为目标用户的每个语音指令之前,针对所述每个第二语音指令,确定识别出的该第二语音指令的普通话文本中的每个字符的拼音,根据所述第一目标普通话文本的语句拼音、以及所述每个字符的拼音,确定该第二语音指令的普通话文本与所述第一目标普通话文本的编辑距离;根据每个第二语音指令的编辑距离以及预先保存的编辑距离阈值,确定不大于所述编辑距离阈值的每个目标编辑距离对应的每个目标第二语音指令,将所述每个目标第二语音指令确定为更新后的每个第二语音指令;所述将所述每个第三语音指令确定为目标用户的每个语音指令之前,针对所述每个第三语音指令,确定识别出的该第三语音指令的普通话文本中的每个字符的拼音,根据所述第二目标普通话文本的语句拼音、以及所述每个字符的拼音,确定该第三语音指令识别的普通话文本与所述第二目标普通话文本的编辑距离;根据每个第三语音指令的编辑距离以及预先保存的编辑距离阈值,确定不大于所述编辑距离阈值的每个目标编辑距离对应的每个目标第三语音指令,将所述每个目标第三语音指令确定为更新后的每个第三语音指令。
37、进一步地,所述训练模块,具体用于若所述生成器为采用单注意力机制的编码器解码器模型,将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器的编码器中,得到所述编码器的每一层编码后输出的语义特征向量组成的上下文向量context vector、以及所述编码器的最后一层编码后输出的隐藏状态;将所述隐藏状态和所述context vector进行拼接后输入到所述生成器的解码器中进行解码,得到所述解码器输出的预测普通话文本。
38、进一步地,所述训练模块,具体用于若所述生成器为采用双注意力机制的编码器解码器模型,获取所述训练集中保存的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本,并获取预先保存的设备的设备名称编码的词向量构成的词向量矩阵,其中所述词向量矩阵是所述语音指令对应目标设备的设备名称编码的词向量构成的单行词向量矩阵、或是具有所述语音指令对应功能的每个设备的设备名称编码的每个词向量组成的多行词向量矩阵;将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器的编码器中,得到所述编码器的每一层编码后输出的语义特征向量组成的上下文向量context vector、以及所述编码器的最后一层编码后输出的隐藏状态;将所述隐藏状态、所述词向量矩阵和所述context vector进行拼接后输入到所述生成器的解码器中进行解码,得到所述解码器输出的预测普通话文本。
39、进一步地,所述获取模块,还用于获取待识别的目标语音指令;
40、所述装置还包括:
41、识别模块,用于识别所述目标语音指令的每个目标字符,将所述每个目标字符转换为每个目标字向量;基于预先训练完成的指令纠正模型,将所述每个目标字向量输入所述指令纠正模型,获取所述指令纠正模型输出的纠正后的普通话文本,将所述纠正后的普通话文本确定为目标指令。
42、进一步地,所述获取模块,还用于获取待识别的目标语音指令、以及预先保存的所述语音指令对应目标设备、或具有所述语音指令对应功能的每个设备的设备名称编码的词向量构成的目标词向量矩阵;
43、所述装置还包括:
44、识别模块,用于识别所述目标语音指令的每个目标字符,将所述每个目标字符转换为每个目标字向量;基于预先训练完成的指令纠正模型,将所述每个目标字向量和所述目标词向量矩阵输入所述指令纠正模型,获取所述指令纠正模型输出的纠正后的普通话文本,将所述纠正后的普通话文本确定为目标指令。
45、第三方面,本技术提供了一种电子设备,包括:处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
46、所述存储器中存储有计算机程序,当所述程序被所述处理器执行时,使得所述处理器执行上述指令纠正模型训练方法中任一所述方法的步骤。
47、第四方面,本技术提供了一种计算机可读存储介质,其存储有计算机程序,所述计算机程序被处理器执行时实现上述指令纠正模型训练方法中任一所述方法的步骤。
48、本技术提供了一种指令纠正模型训练方法、装置、设备和介质,由于该方法中获取训练集中保存的目标用户的任一语音指令的每个字向量、以及所述语音指令对应的正确普通话文本,将所述语音指令的每个字向量输入到原始生成器判别器网络模型的生成器中,得到所述生成器输出的预测普通话文本并输入到所述原始生成器判别器网络模型的判别器中;将所述正确普通话文本输入到所述判别器中,得到所述判别器输出的所述预测普通话文本与所述正确普通话文本的相似度,并将所述相似度输入到所述生成器中,对所述生成器的每个参数的参数值进行调整,得到训练完成的生成器,将训练完成的生成器确定为指令纠正模型,由于本技术中基于目标用户的存在个性化发音问题的语音指令的每个字向量对原始生成器判别器网络模型中的生成器进行训练,将训练完成的生成器确定为指令纠正模型,由于指令纠正模型能够对目标用户的存在个性化发音问题的语音指令进行预测,预测出语音指令的正确普通话文本,因此实现了对存在个性化的发音问题的用户语音指令的准确识别。
- 还没有人留言评论。精彩留言会获得点赞!