面向语音身份匿名的卷积性对抗样本构造方法及装置
1.本发明涉及语音隐私保护领域,具体地说,是一种面向语音身份匿名的卷积性对抗样本构造方法及装置。
背景技术:
2.近年来,语音输入已经成为最为流行的人机交互方式并被广泛应用于各种智能化服务中,为人们提供自动语音转录、高效语音搜索、实时语言翻译等诸多丰富强大的功能。然而,语音数据发布存在潜在的隐私风险并随着语音服务的普及进一步加剧,从而引起了广泛的公众关注。语音服务供应商采集、存储甚至滥用语音数据使得用户暴露于各种隐私安全威胁,例如基于自动内容识别的个人身份泄露、基于用户画像的定向广告甚至基于声纹克隆的身份冒充等。
3.面对语音服务功能和个人身份隐私困境,现有的语音身份匿名研究主要通过语音转换和语音合成的方式消除个体声纹特征并保留文本语义信息,从而支撑隐私保护的语音服务。其中,大部分工作沿袭语音转换的范式通过修改声学特征或变换说话人嵌入码特征来隐藏用户的真实声纹,其他一些研究则提出基于文本重新合成不带任何有效声纹特征的语音以最大程度保护身份隐私。尽管这些工作对语音中的用户身份隐私保护进行了有效探索,但这种直接修改和重新合成的侵入式手段会产生非一致的声纹和严重的失真从而影响匿名化语音的感知质量,无法适用于即时通信、社交媒体等人类听众在场的语音交互场景。其他一些工作利用声学掩蔽效应注入不可感知的加性对抗扰动进行语音身份匿名,但该扰动容易被精心设计的滤波器消除,表现出较低的抗变换能力。
4.因此,现有的语音身份匿名系统利用语音转换、语音合成或者加性对抗样本技术保护用户身份信息,会导致较高的侵入性和较低的鲁棒性。
技术实现要素:
5.本发明针对现有技术的不足之处作出了改进,提供了一种面向语音身份匿名的卷积性对抗样本构造方法及装置,本发明是采用如下技术方案来实现的:
6.一种面向语音身份匿名的卷积性对抗样本构造方法,包括:
7.获得用户的原始语音样本,获得至少1个真实房间脉冲响应(room impulse response,rir)信号;
8.通过获得的真实房间脉冲响应信号初始化卷积性对抗扰动;
9.将获得的用户原始语音样本与卷积性对抗扰动进行卷积运算,得到初始的语音对抗样本;
10.随机选择目标类别的标签,通过嵌入码级别的条件变分自编码器采样说话人嵌入码;
11.根据初始的语音对抗样本,以采样的说话人嵌入码为目标,通过基于梯度的对抗样本构造方法迭代式地优化语音对抗样本实现定向的身份嵌入码变换;
12.通过正则化惩罚卷积性对抗扰动与真实房间脉冲响应之差优化语音对抗样本,模拟自然的混响效应以保留较高的语音质量;
13.最终得到的匿名化语音对抗样本具有目标说话人的身份嵌入码,同时保留了原有的声纹、文本和音质。
14.作为进一步的改进,所述的将获得的用户原始语音样本与卷积性对抗扰动进行卷积运算,得到初始的语音对抗样本,具体包括:
15.通过真实房间脉冲响应信号δ初始化卷积性对抗扰动δ
′
,然后将用户原始语音xs与卷积性对抗扰动δ
′
卷积得到语音对抗样本:
16.xs′
=xs*δ
′
17.根据卷积运算的性质,有:
18.fft(xs′
)=fft(xs)
×
fft(δ
′
)
19.因此,时域卷积等价于频域相乘,该卷积性对抗扰动本质上是一个滤波器,可以决定不同频率分量的重要性,因此可以修改声纹特征进而实现语音匿名的功能;
20.作为进一步的改进,本发明所述的嵌入码级别的条件变分自编码器(cvae)采样说话人嵌入码,具体为:
21.所述的嵌入码级别的条件变分自编码器采用编码器-解码器架构;
22.编码器接收目标类别标签的one-hot编码y
t
和原始说话人嵌入码vs作为输入,然后通过多个降采样网络层进行降维,再利用两个并行的线性网络层建模其均值μ和标准差σ;
23.通过重参数技巧构造隐向量z:z=μ+σ
⊙
∈其中∈为一个符合标准高斯分布的随机变量;
24.构造的隐向量z与说话人标签的one-hot编码y
t
拼接后输入到解码器中,经过线性网络层变换后通过多个升采样网络层重构出新的嵌入码vs′
;
25.该条件变分自编码器通过以下目标函数讲行训练:
[0026][0027]
其中,β为权重参数,kl(
·
)为kullback-leibler散度;
[0028]
通过预训练的解码器,可以生成多样化的符合目标身份的说话人嵌入码。
[0029]
作为进一步的改进,本发明所述的基于梯度的对抗样本构造方法用于迭代式地优化语音对抗样本实现定向的身份嵌入码变换,具体包括:
[0030]
所述的基于梯度的对抗样本构造方法,以采样的说话人嵌入码为目标,迭代式优化语音对抗样本,使其在隐空间中趋向目标说话人嵌入码;
[0031]
将语音对抗样本输入声纹识别系统f(
·
)得到语音对抗样本嵌入码f(xs′
);
[0032]
根据随机选择的目标类别的标签y
t
,通过条件变分自编码器的解码器d(
·
)采样目标说话人嵌入码d(y
t
);
[0033]
通过距离函数d(
·
)量化语音对抗样本嵌入码f(xs′
)和目标说话人嵌入码d(y
t
)在隐空间中的距离,并迫使语音对抗样本嵌入码偏向目标说话人嵌入码,从而生成最大程度接近目标身份的对抗样本:
[0034][0035]
该目标函数利用梯度下降方法进行迭代优化,通过输入相关的构造实现任意到任
意的身份转换,允许任意原始用户伪装成一组不同的目标身份,进一步增加自动说话人识别系统的身份检测难度。
[0036]
作为进一步的改进,所述的正则化惩罚对抗性房间脉冲响应与真实房间脉冲响应之差优化语音对抗样本,模拟自然的混响效应以保留较高的语音质量,具体包括:
[0037]
为了保证卷积性对抗扰动近似于真实房间脉冲响应信号,通过正则化来惩罚卷积性对抗扰动与真实房间脉冲响应之差||δ
′‑
δ||;
[0038]
优化的卷积性对抗扰动近似于真实的房间脉冲响应,被人耳感知为混响,从而实现语音匿名系统的隐蔽性。
[0039]
本发明还公开了一种面向语音身份匿名的卷积性对抗样本构造装置,包括:
[0040]
卷积性扰动初始化模块:通过获得的真实房间脉冲响应信号初始化卷积性对抗扰动,将获得的用户原始语音样本与对抗性房间脉冲响应进行卷积运算,得到初始的语音对抗样本;
[0041]
多样化嵌入码生成模块:随机选择目标类别的标签,通过嵌入码级别的条件变分自编码器采样说话人嵌入码;
[0042]
任意到任意身份转换模块:根据初始的语音对抗样本,以采样的说话人嵌入码为目标,通过基于梯度的对抗样本构造方法迭代式地优化语音对抗样本实现定向的身份嵌入码变换;
[0043]
扰动隐蔽性优化模块:通过正则化惩罚卷积性对抗扰动与真实房间脉冲响应之差优化语音对抗样本,模拟自然的混响效应以保留较高的语音质量。
[0044]
本发明的有益效果如下:
[0045]
1)非侵入语音身份匿名。本发明设计卷积性对抗扰动来近似真实自然的房间脉冲响应,能够有效减少扰动注入带来的信号失真,保证文本内容的完整性和声纹的一致性以及良好的音频感知质量,实现语音服务隐私和功用的平衡。
[0046]
2)鲁棒性语音身份匿名。本发明提出的卷积性对抗扰动能够有效抵御常见的基于信号处理技术的对抗扰动破坏手段,保证在音频失真条件或扰动破坏作用下语音身份匿名依然有效。
附图说明
[0047]
图1为本发明的系统框架图;
[0048]
图2为房间脉冲响应示例图;
[0049]
图3为不同语音身份匿名方法的客观指标对比;
[0050]
图4为不同语音身份匿名方法的主观指标对比;
[0051]
图5为原始音频、带正常rir的音频以及带对抗性rir的音频示例。
具体实施方式
[0052]
下面通过结合说明书附图,通过具体实施例,对本发明的技术方案作进一步地说明:
[0053]
本发明的目的是针对语音数据身份隐私泄露的安全问题,提出了一种面向语音身份匿名的卷积性对抗样本构造方法,实现本发明方法的装置包括麦克风、处理器,图1是本
发明的数据流程图;
[0054]
本发明的具体实施方法如下:
[0055]
步骤一、当麦克风接收到用户的原始语音时,将原始语音传输给处理器,同时将至少1个真实房间脉冲响应信号(room impulse response,rir)传输给处理器,本实施例中为1个,如图2房间脉冲响应示例图所示,该房间脉冲响应信号通过ess(exponential sweep sine)测量手段获得;
[0056]
步骤二、处理器通过获得的真实房间脉冲响应信号,初始化卷积性对抗扰动。将获得的用户原始语音样本与卷积性对抗扰动进行卷积运算,得到初始的语音对抗样本。具体而言,通过真实房间脉冲响应信号δ初始化卷积性对抗扰动δ
′
,然后将用户原始语音xs与卷积性对抗扰动δ
′
卷积得到语音对抗样本:
[0057]
xs′
=xs*δ
′
[0058]
根据卷积运算的性质,有:
[0059]
fft(xs′
)=fft(xs)
×
fft(δ
′
)
[0060]
因此,时域卷积等价于频域相乘,该卷积性对抗扰动本质上是一个滤波器,可以决定不同频率分量的重要性,因此可以修改声纹特征进而实现语音匿名的功能;
[0061]
步骤三、处理器随机选择目标类别的标签,通过嵌入码级别的条件变分自编码器采样一批多样化的说话人嵌入码。该嵌入码级别的条件变分自编码器采用编码器-解码器架构:编码器接收目标类别标签的one-hot编码y
t
和原始说话人嵌入码vs作为输入,然后通过多个降采样网络层进行降维,再利用两个并行的线性网络层建模其均值μ和标准差σ;通过重参数技巧构造隐向量z:z=μ+σ
⊙
∈其中∈为一个符合标准高斯分布的随机变量;构造的隐向量z与说话人标签的one-hot编码y
t
拼接后输入到解码器中,经过线性网络层变换后通过多个升采样网络层重构出新的嵌入码vs′
;该条件变分自编码器通过以下目标函数进行训练:
[0062][0063]
其中,β为权重参数,kl(
·
)为kullback-leibler散度;通过预训练的解码器,可以生成多样化的符合目标身份的说话人嵌入码;
[0064]
步骤四、根据初始的语音对抗样本,以采样的说话人嵌入码为目标,通过基于梯度的对抗样本构造方法,迭代式优化语音对抗样本,使其在隐空间中趋向目标说话人嵌入码,实现定向的身份嵌入码变换。具体为,将语音对抗样本输入声纹识别系统f(
·
)得到语音对抗样本嵌入码f(xs′
);根据随机选择的目标类别的标签y
t
,通过条件变分自编码器的解码器d(
·
)采样目标说话人嵌入码d(y
t
);通过距离函数d(
·
)量化语音对抗样本嵌入码f(xs′
)和目标说话人嵌入码d(y
t
)在隐空间中的距离,并迫使语音对抗样本嵌入码偏向目标说话人嵌入码,从而生成最大程度接近目标身份的对抗样本:
[0065][0066]
该目标函数利用梯度下降方法进行迭代优化,通过输入相关的构造实现任意到任意的身份转换,允许任意原始用户伪装成一组不同的目标身份,进一步增加自动说话人识别系统的身份检测难度;
[0067]
步骤五、通过正则化惩罚卷积性对抗扰动与真实房间脉冲响应之差优化语音对抗
样本,模拟自然的混响效应以保留较高的语音质量。为了保证卷积性对抗扰动近似于真实房间脉冲响应信号,通过正则化来惩罚卷积性对抗扰动与真实房间脉冲响应之差||δ
′‑
δ||,该正则化项添加到语音对抗样本优化的目标函数中进行多任务训练。优化的卷积性对抗扰动近似于真实的房间脉冲响应,被人耳感知为混响,从而实现语音匿名系统的隐蔽性。
[0068]
最终得到的匿名化语音对抗样本具有目标说话人的身份嵌入码,同时保留了原有的声纹、文本和音质。
[0069]
本发明还公开了一种面向语音身份匿名的卷积性对抗样本构造装置,包括:
[0070]
卷积性扰动初始化模块:通过获得的真实房间脉冲响应信号初始化卷积性对抗扰动,将获得的用户原始语音样本与对抗性房间脉冲响应进行卷积运算,得到初始的语音对抗样本;
[0071]
多样化嵌入码生成模块:随机选择目标类别的标签,通过嵌入码级别的条件变分自编码器采样说话人嵌入码;
[0072]
任意到任意身份转换模块:根据初始的语音对抗样本,以采样的说话人嵌入码为目标,通过基于梯度的对抗样本构造方法迭代式地优化语音对抗样本实现定向的身份嵌入码变换;
[0073]
扰动隐蔽性优化模块:通过正则化惩罚卷积性对抗扰动与真实房间脉冲响应之差优化语音对抗样本,模拟自然的混响效应以保留较高的语音质量。
[0074]
本发明公开了一种面向语音身份匿名的卷积性对抗样本构造方法及装置。通过以上四个模块生成的匿名化语音对抗样本经过自动说话人识别系统会被识别为不同的目标说话人,而输入到自动语音识别系统时仍然输出正确的转录文本,同时在声纹、文本、音质方面保持良好的一致性。
[0075]
为了验证本发明的有效性,在大规模语料库librispeech的测试集上进行实验,该数据集包含40个说话人(20男和20女)的2189条英语语音,涵盖不同口音、职业和年龄。其中,每条语音长度在数秒到数十秒,采样率为16khz。实现了多个主流的说话人辨认模型作为目标系统,包括d-vector,deepspeaker,x-vector和ecapa-tdnn,这些模型具有不同的特征提取器、网络结构和参数设置。根据对抗样本损失函数和房间脉冲响应约束,采用梯度下降方法优化卷积性对抗扰动,默认设置学习率η=0.001。采用如下指标评估本发明的性能:
[0076]
1)匿名成功率(dsr):其中x和y分别为匿名成功的样本数和总体测试样本数,dsr越高匿名性能越好。
[0077]
2)词准确率(wa):其中n为语句的单词数,c为转录文本中的正确词数目,i为转录文本相比真实文本的插入词数目,wa越高语音识别结果越准确。
[0078]
3)梅尔倒谱失真(mcd):其中m cr和m c
t
分别为参考语音和待测语音的梅尔倒谱系数,mcd越小音频信号失真越小。
[0079]
4)平均意见分数(mos):一个人类主观评判音质的量化指标,数值范围在1至5之间,mos越高音质越好。
[0080]
匿名有效性和语音可用性客观评估。随机采样不同的目标说话人嵌入码,在40个说话人的语料上针对每个说话人识别系统生成了2819条对抗样本,然后分别输入到这些说
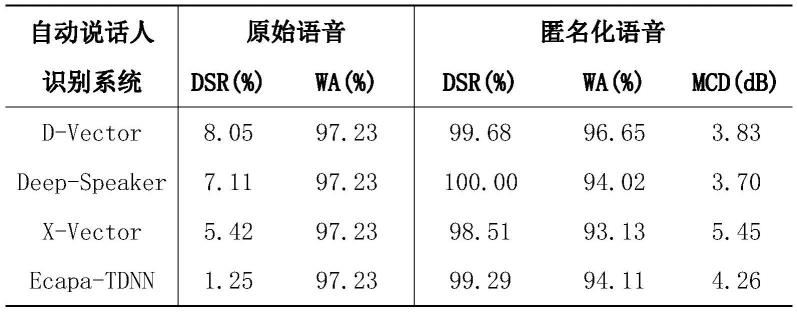
话人识别系统和一个端到端语音识别系统中进行测试。表1展示了本发明在最新说话人识别模型上的匿名成功率、词准确率和梅尔倒谱失真:
[0081]
表1本发明在最新说话人识别模型上的匿名成功率、词准确率和梅尔倒谱失真
[0082][0083]
可以看出四个说话人识别系统在原始语音上dsr仅为1%至8%,表现出优良的识别性能,而经过本发明的语音身份匿名后dsr均达到98.5%以上,表明本发明的身份匿名有效性。相比于原始语音上97%的wa,匿名化语音的wa保持在93%至96%之间,证明了本发明的匿名操作对语音之中文本内容的影响较小。另外,匿名化语音的mcd在3.8db至5.5db之间也证明卷积性扰动引入的音频失真较小。
[0084]
此外,将本发明与领域内前沿的语音身份匿名方法进行对比。如图3为不同语音身份匿名方法的客观指标对比,其中voicemask为基于信号处理的语音转换方法,disentangle-vc为基于深度学习的语音转换方法,pgd为加性对抗样本方法。可以看出,voicemask和disentangle-vc的词准确率下降幅度和梅尔倒谱失真明显大于其他两种对抗样本方法,这是由于他们使用侵入性较强的语音转换方法从而产生严重的信号失真。pgd的词准确率下降幅度最小但产生了不可接受的梅尔倒谱失真,这是高频率和高能量的加性噪声导致的结果。相比而言,本发明能够同时实现较小的词准确率下降幅度和梅尔倒谱失真,能够有效保留语音文本内容和感知质量。
[0085]
匿名有效性和语音可用性主观评估。除了客观指标的衡量,还进行了主观实验来评估本发明的匿名有效性和语音可用性。在主观实验中,招募了50个志愿者(28男22女,18至53岁)来参加mos测试,每个志愿者听取10对原始语音和四种不同语音身份匿名方法的匿名化语音然后记录二者在声纹、文本和音质方面的相似性。如图4为不同语音身份匿名方法的主观指标对比,可以看出四种语音身份匿名方法都表现出了较高的文本mos,而voicemask和disentangle-vc方法由于语音转换的缺陷在声纹和音质方面表现较差。另一方面,pgd和本发明在声纹和文本方面表现优良,但本发明在音质方面明显由于pgd方法,证明卷积性对抗扰动相比加性对抗扰动的优越性。以上结果综合证明了本发明能够有效保留文本完整性、声纹一致性以及良好感知音质。
[0086]
如图5为原始音频、带正常rir的音频以及带对抗性rir的音频示例,直观展示了本发明的非侵入匿名效果。相比原始音频的波形,经过空气传播的带正常rir的音频波形展现出了明显变化;而在频谱方面,经过空气传播的带正常rir的频谱依然相似于原始语音,只是存在一些多径效应导致的频带漂移。类似的结果可以在带对抗性rir的音频波形和频谱上观察到。发现带正常rir和对抗性rir的音频波形和频谱都非常相近,说明本发明的卷积
性对抗扰动成功近似了真实世界的房间脉冲响应。
[0087]
鲁棒性评估。为了验证本发明的鲁棒性,在四种基于信号处理的对抗扰动破坏手段(带通滤波、重量化、梅尔变换、声学滤波)上进行实验,这些信号处理的参数根据最小化自动说话人识别系统的影响并最大化对抗扰动破坏程度进行配置:(1)带通滤波:滤除200hz以下和7khz以上的语音信号;(2)重量化:将16-bit的语音信号量化到8-bit再恢复到16-bit;(3)梅尔变换:将语音信号提取80-bin的梅尔倒谱系数,再通过griffin-lim算法恢复成音频信号;(4)声学滤波:计算语音信号的听域曲线并滤除听域曲线0db以下的部分。如表2展示了本发明在基于信号处理的对抗扰动破坏手段下在正常语音和匿名化语音上的匿名成功率。可以看出,四种信号处理手段只能影响部分匿名性能而且会牺牲部分自动说话人识别系统的性能,特别是在更强的说话人识别系统下生成的对抗样本上仍然保持较高的匿名成功率,证明了本发明卷积性对抗扰动的鲁棒性。
[0088]
表2本发明在基于信号处理的对抗扰动破坏手段下的匿名成功率(无扰动/有扰动)
[0089][0090]
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1