语音处理方法、装置、设备和介质与流程
本技术涉及人工智能,特别是涉及一种语音处理方法、装置、设备和介质。
背景技术:
1、随着计算机技术的发展,出现了语音处理技术,语音处理技术是指对语音信号进行音频处理的技术。语音提取则属于语音处理技术中的其中一种,通过语音提取技术,可从复杂语音场景中提取用户感兴趣的声音。可以理解,复杂语音场景可以包括多人说话干扰、大混响、高背景噪音和音乐噪音等中的至少一种。比如,通过语音提取技术,用户可以从复杂语音场景中提取出自己感兴趣的对象的声音。传统技术中,通常直接对复杂语音进行语音提取,并将提取得到的语音直接作为最终要提取的对象的语音,但是,通过这种方式提取得到的语音经常会残留有较多噪声(比如,提取的语音中还包括其他对象的声音),从而导致语音提取准确率较低。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够提升语音提取准确率的语音处理方法、装置、设备和介质。
2、第一方面,本技术提供了一种语音处理方法,所述方法包括:
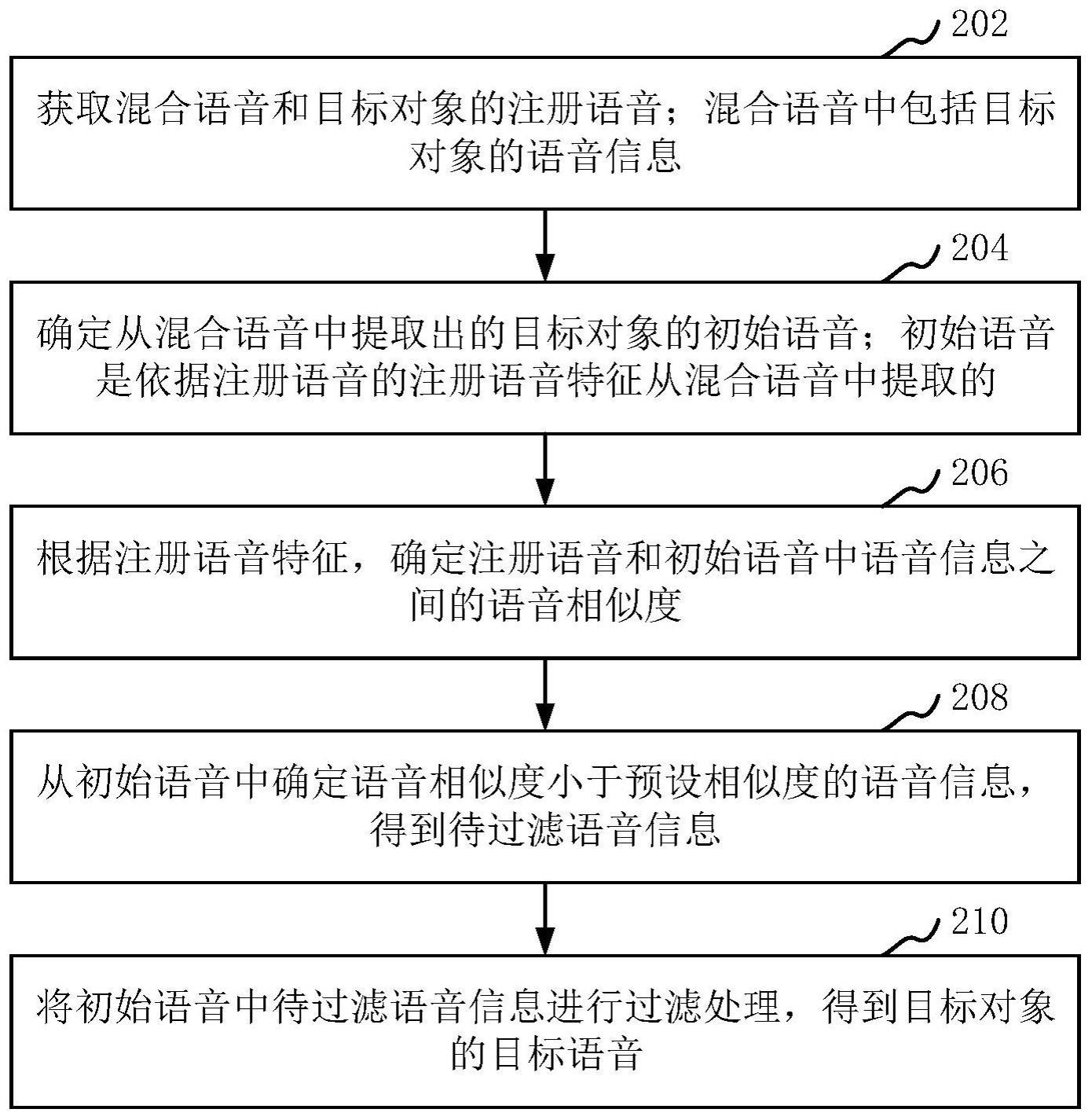
3、获取混合语音和目标对象的注册语音;所述混合语音中包括所述目标对象的语音信息;
4、确定从所述混合语音中提取出的所述目标对象的初始语音;所述初始语音是依据所述注册语音的注册语音特征从所述混合语音中提取的;
5、根据所述注册语音特征,确定所述注册语音和所述初始语音中语音信息之间的语音相似度;
6、从所述初始语音中确定所述语音相似度小于预设相似度的语音信息,得到待过滤语音信息;
7、将所述初始语音中所述待过滤语音信息进行过滤处理,得到所述目标对象的目标语音。
8、第二方面,本技术提供了一种语音处理装置,所述装置包括:
9、获取模块,用于获取混合语音和目标对象的注册语音;所述混合语音中包括所述目标对象的语音信息;
10、第一提取模块,用于确定从所述混合语音中提取出的所述目标对象的初始语音;所述初始语音是依据所述注册语音的注册语音特征从所述混合语音中提取的;
11、确定模块,用于根据所述注册语音特征,确定所述注册语音和所述初始语音中语音信息之间的语音相似度;从所述初始语音中确定所述语音相似度小于预设相似度的语音信息,得到待过滤语音信息;
12、过滤模块,用于将所述初始语音中所述待过滤语音信息进行过滤处理,得到所述目标对象的目标语音。
13、在一个实施例中,在第一处理模式下执行确定语音相似度及后续相应语音过滤步骤;在第二处理模式下依据所述注册语音特征从所述混合语音中还提取出干扰语音;所述干扰语音是在所述混合语音中干扰识别所述目标对象的语音信息的语音;所述装置还包括:
14、第二提取模块,用于在所述第二处理模式下,将所述混合语音的混合语音特征和所述初始语音的语音特征基于注意力机制进行融合,得到第一注意力特征,以及将所述混合语音特征和所述干扰语音的语音特征基于注意力机制进行融合,得到第二注意力特征;基于所述混合语音特征、所述第一注意力特征和所述第二注意力特征进行融合,并基于融合后的特征得到所述目标对象的目标语音。
15、在一个实施例中,所述第二提取模块还用于将所述混合语音特征、所述第一注意力特征、所述第二注意力特征和所述注册语音特征进行融合,并基于融合后的特征得到所述目标对象的目标语音。
16、在一个实施例中,所述初始语音和所述干扰语音是通过预先训练的语音提取模型从所述混合语音中提取出的;所述第二提取模块还用于将所述混合语音和所述注册语音特征输入至所述语音提取模型,以通过所述语音提取模型基于所述混合语音和所述注册语音特征,生成第一掩码信息和第二掩码信息;根据所述第一掩码信息屏蔽所述混合语音中的干扰信息,得到所述目标对象的初始语音;根据所述第二掩码信息屏蔽所述混合语音中所述目标对象的语音信息,得到干扰语音。
17、在一个实施例中,所述语音提取模型中预先训练好的模型参数中包括第一掩码映射参数和第二掩码映射参数;所述第二提取模块还用于将所述混合语音和所述注册语音特征输入至所述语音提取模型,以通过所述第一掩码映射参数映射生成对应的第一掩码信息,以及通过所述第二掩码映射参数映射生成对应的第二掩码信息。
18、在一个实施例中,所述第二提取模块还用于在所述第二处理模式下,将所述混合语音、一级语音提取模型输出的所述初始语音和所述干扰语音分别输入至二级处理模型中的特征提取层进行特征提取,得到所述混合语音的混合语音特征、所述初始语音的语音特征和所述干扰语音的语音特征;将所述初始语音的语音特征和所述混合语音特征输入至所述二级处理模型中的第一注意力单元,以将所述混合语音的混合语音特征和所述初始语音的语音特征基于注意力机制进行融合,得到第一注意力特征;将所述干扰语音的语音特征和所述混合语音特征输入至所述二级处理模型中的第二注意力单元,以将所述混合语音的混合语音特征和所述干扰语音的语音特征基于注意力机制进行融合,得到第二注意力特征。
19、在一个实施例中,提取所述初始语音和所述干扰语音的语音提取模型为一级语音提取模型;所述二级处理模型还包括特征融合层和二级语音提取模型;所述第二提取模块还用于将所述混合语音特征、所述第一注意力特征、所述第二注意力特征和所述注册语音特征输入至所述特征融合层进行融合,得到语音融合特征;将所述语音融合特征输入至所述二级语音提取模型,以通过所述二级语音提取模型基于所述语音融合特征得到所述目标对象的目标语音。
20、在一个实施例中,所述语音信息包括语音片段;所述确定模块还用于针对所述初始语音中的每一个语音片段,确定所述语音片段对应的片段语音特征;根据所述片段语音特征和所述注册语音特征,确定所述注册语音和所述语音片段之间的语音相似度。
21、在一个实施例中,所述确定模块还用于针对所述初始语音中的每一个语音片段,将所述语音片段进行重复处理,得到与所述注册语音的时间长度一致的重组语音;其中,所述重组语音包括多个所述语音片段;根据所述重组语音的重组语音特征确定所述语音片段对应的片段语音特征。
22、在一个实施例中,所述获取模块还用于响应于针对目标对象的通话触发操作,从预先存储的候选的注册语音中,确定所述目标对象的注册语音;在基于所述通话触发操作与所述目标对象对应的终端建立语音通话的情况下,接收所述目标对象对应的终端在所述语音通话中发送的混合语音。
23、在一个实施例中,所述获取模块还用于获取多媒体对象的多媒体语音;所述多媒体语音是包括多个发声对象的语音信息的混合语音;响应于针对多媒体语音中的发声对象的指定操作,获取指定的目标对象的对象标识;所述目标对象是所述多个发声对象中指定提取语音的发声对象;从针对多媒体语音中各发声对象预先存储的注册语音中,获取与所述对象标识具有映射关系的注册语音,得到所述目标对象的注册语音。
24、第三方面,本技术提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现本技术各方法实施例中的步骤。
25、第四方面,本技术提供了一种计算机可读存储介质,存储有计算机程序,该计算机程序被处理器执行时实现本技术各方法实施例中的步骤。
26、第五方面,本技术提供了一种计算机程序产品,包括计算机程序,计算机程序被处理器执行时实现本技术各方法实施例中的步骤。
27、上述语音处理方法、装置、设备、介质和计算机程序产品,通过获取混合语音和目标对象的注册语音,混合语音中包括目标对象的语音信息。依据注册语音的注册语音特征,从混合语音中初步提取出目标对象的初始语音,能够初步较为准确地提取到目标对象的初始语音。进而,会在初始语音的基础上进行进阶地过滤处理,即,根据注册语音特征,确定注册语音和初始语音中语音信息之间的语音相似度,并从初始语音中过滤掉语音相似度小于预设相似度的语音信息,就可以将初始语音中残留的噪声过滤掉,从而得到更为干净的目标对象的目标语音,提升语音提取的准确率。
- 还没有人留言评论。精彩留言会获得点赞!