基于平凡发音的说话者识别方法、系统、存储介质及设备与流程
1.本技术涉及语音识别领域,尤其涉及一种基于平凡发音的说话者识别方法、系统、存储介质及设备。
背景技术:
2.平凡发音,是指在口语对话中时常出现的、受说话者主观控制较弱的发音。平凡发音不同于语义信息,其没有实质语义内容,因此在语音识别技术中,通常都会将平凡发音视作无意义的词进行过滤。
3.而本技术人经研究认为,平凡发音虽然没有实质语义内容,但其仍旧蕴含了说话者丰富的声音特性,可以据此识别出所属说话者。例如,“嗯”、“啊”等平凡发音属于普通语音,同时兼顾上述平凡发音的特性,十分适用于识别说话者。此外,平凡发音占据的数据量很小,处理效率会远高于其他实质语义内容。
4.但是,平凡发音在具有上述优势的同时,也兼顾发音时长短、易受环境噪声影响等劣势,从而使其在识别稳定性方面仍有欠缺。
技术实现要素:
5.本发明提供了一种基于平凡发音的说话者识别方法、系统、存储介质及设备,以解决或者部分解决平凡发音在识别稳定性方面具有欠缺的技术问题。
6.为解决上述技术问题,本发明的第一方面,公开了一种基于平凡发音的说话者识别方法,所述方法包括:
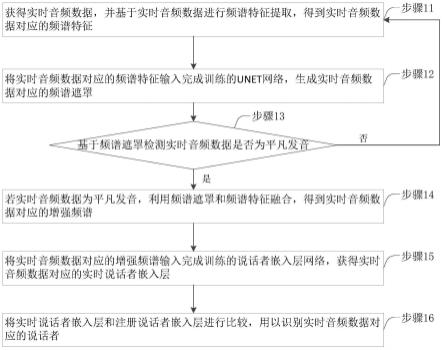
7.获得实时音频数据,并基于所述实时音频数据进行频谱特征提取,得到所述实时音频数据对应的频谱特征;
8.将所述实时音频数据对应的频谱特征输入完成训练的unet网络,生成所述实时音频数据对应的频谱遮罩,并基于所述频谱遮罩检测所述实时音频数据是否为平凡发音;
9.若所述实时音频数据为所述平凡发音,利用所述频谱遮罩和所述频谱特征融合,得到所述实时音频数据对应的增强频谱;
10.将所述实时音频数据对应的增强频谱输入完成训练的说话者嵌入层网络,获得所述实时音频数据对应的实时说话者嵌入层;
11.将所述实时说话者嵌入层和注册说话者嵌入层进行比较,用以识别所述实时音频数据对应的说话者。
12.优选的,所述unet网络的网络结构包括:两个以上自适应卷积模块、三个以上降采样模块、三个以上上采样模块和s型函数;
13.其中,每个所述自适应卷积模块包括两个以上自适应二维卷积层,每个所述自适应二维卷积层后面增加批标准化bn层和线性整流单元relu函数;
14.每个所述降采样模块包括一个以上所述自适应卷积模块和一个以上平均池化层;
15.每个所述上采样模块包括一个以上自适应二维转置卷积层、一个以上通道连接层
和一个以上所述自适应卷积模块。
16.优选的,所述自适应二维卷积层的自适应卷积核同时参考输入数据的时域信息和频域信息生成;
17.所述自适应二维转置卷积层的自适应卷积核同时参考所述输入数据的时域信息和频域信息生成。
18.优选的,所述自适应二维卷积层和所述自适应二维转置卷积层的自适应卷积核均按照下述步骤生成:
19.将所述输入数据分别在时域维度和所述频域维度进行转换,再合并为用于生成所述自适应卷积核的自适应数据;其中,所述自适应数据的尺寸包括:输入通道数,自适应卷积核频域维度大小,自适应卷积核时域维度大小;
20.构建可训练参数;其中,所述可训练参数的尺寸包括:输出通道数,输入通道数,自适应卷积核频域维度大小,自适应卷积核时域维度大小;
21.将自适应数据沿输出通道数扩展至和所述可训练参数相同尺寸,并与所述可训练参数点乘,获得所述自适应卷积核。
22.优选的,所述将所述输入数据分别在时域维度和所述频域维度进行转换,再合并为用于生成所述自适应卷积核的自适应数据,具体包括:
23.将所述输入数据分别通过时域平均池化和频域平均池化,得到不同尺寸的第一时域输出数据和第一频域输出数据;
24.将所述第一时域输出数据和所述第一频域输出数据各自进行一维卷积,得到不同尺寸的第二时域输出数据和第二频域输出数据;其中,所述第二时域输出数据的尺寸包括输入通道数和所述自适应卷积核频域维度,所述第二频域输出数据的尺寸包括输入通道数和所述自适应卷积核时域维度;
25.将所述第二时域输出数据沿频域轴扩展,并将所述第二频域输出数据沿时间轴扩展,使所述第二时域输出数据和所述第二频域输出数据尺寸相同;
26.将所述第二时域输出数据和所述第二频域输出数据相加,得到所述自适应数据。
27.优选的,所述unet网络按照下述方式进行训练:
28.获得第一数据集,所述第一数据集包括:源语音数据x
source
、流式标签y
′
hmm
和目标语音数据x
target
;
29.基于所述第一数据集进行频谱特征提取,得到所述源语音数据x
source
对应的输入频谱s
source
和所述目标语音数据x
target
对应的目标频谱s
target
;
30.基于所述数据集帧级别标签获取,得到所述流式标签y
′
hmm
对应的帧级别标签y
hmm
;
31.计算损失函数,所述损失函数包括频谱优化和频谱遮罩优化;其中,频谱优化通过减小增强频谱和目标频谱s
target
的差异来实现;增强频谱由输入频谱s
source
输入unet网络后得到频谱遮罩m,再与输入频谱s
source
点乘得到;频谱遮罩优化采用下式优化:当前语音帧为平凡发音时,1-y
hmm
的值为0,对频谱遮罩m的优化无限制;当前语音帧为其他音频内容时,1-y
hmm
的值为1,损失函数为计算方式采用平均绝对误差l1损失函数,代表频谱遮罩m应向0值方向优化,为频谱遮罩均值;
32.基于损失函数l进行反向传播训练所述unet网络的参数直至收敛。
33.优选的,所述方法还包括:
34.分析频谱遮罩均值对所述第一数据集中所有平凡发音以及其他音频的分布情况,确定用于区分所述第一数据集中平凡发音和其他音频的阈值α;其中,当大于α时,频谱遮罩对应的源音频数据x
source
为平凡发音,否则为其他音频。
35.优选的,所述损失函数为
⊙
m;其中,mse表示均方误差函数。
36.优选的,所述说话者嵌入层网络的网络结构包括:帧级别特征提取模块、时间平均池化模块和句级别特征提取模块;
37.其中,所述帧级别特征提取模块包括:若干层卷积层、池化层和批标准化bn层,所述句级别特征提取模块包括两层以上全连接层。
38.优选的,所述说话者嵌入层网络按照下述方式进行训练:
39.获得第二数据集,所述第二数据集中的语音数据均为平凡发音,且所述语音数据均具有说话者标签;
40.基于所述第二数据集进行频谱特征提取,获得待处理频谱;
41.将所述待处理频谱输入完成训练的unet网络,获得所述待处理频谱对应的增强频谱;
42.将所述待处理频谱对应的增强频谱作为输入,所述待处理频谱对应的说话者标签作为输出,基于损失函数反向传播训练所述说话人嵌入层网络的参数直至收敛。
43.优选的,所述注册说话者嵌入层按照下述步骤得到:
44.采集说话者的注册音频并进行频谱特征提取,获得所述注册音频对应的频谱特征;其中,所述注册音频为平凡发音;
45.将所述注册音频对应的频谱特征通过完成训练的unet网络,获得所述注册音频对应的频谱遮罩;
46.将所述注册音频对应的频谱特征与所述注册音频对应的频谱遮罩融合,获得所述注册音频对应的增强频谱;
47.将所述注册音频对应的增强频谱输入完成训练的说话者嵌入层网络,获得所述注册说话者嵌入层。
48.本发明的第二方面,公开了一种基于平凡发音的说话者识别系统,包括:
49.获得模块,用于获得实时音频数据,并基于所述实时音频数据进行频谱特征提取,得到所述实时音频数据对应的频谱特征;
50.第一网络处理模块,用于将所述实时音频数据对应的频谱特征输入完成训练的unet网络,生成所述实时音频数据对应的频谱遮罩,并基于所述频谱遮罩检测所述实时音频数据是否为平凡发音;
51.融合模块,用于若所述实时音频数据为所述平凡发音,利用所述频谱遮罩和所述频谱特征融合,得到所述实时音频数据对应的增强频谱;
52.第二网络处理模块,用于将所述实时音频数据对应的增强频谱输入完成训练的说话者嵌入层网络,获得所述实时音频数据对应的实时说话者嵌入层;
53.比较模块,用于将所述实时说话者嵌入层和注册说话者嵌入层进行比较,用以识别所述实时音频数据对应的说话者。
54.本发明的第三方面,公开了一种计算机可读存储介质,其上存储有计算机程序,该
程序被处理器执行时实现上述方法的步骤。
55.本发明的第四方面,公开了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法的步骤。
56.通过本发明的一个或者多个技术方案,本发明具有以下有益效果或者优点:
57.本发明公开了一种基于平凡发音的说话者识别方法、系统、存储介质及设备,为了应对平凡发音在发音时长短、易受环境噪声影响等方面的劣势,本发明的方法在获得实时音频数据并执行频谱特征提取后,将频谱特征输入完成训练的unet网络用以生成频谱遮罩,通过频谱遮罩来判断实时音频数据是否为平凡发音来避免使用额外的语音唤醒网络等复杂结构,从而能够减少系统的存储量和计算量;此外,通过频谱遮罩与频谱特征融合,能实现对实时音频数据的增强,使得说话人嵌入层网络可以据此获得高质量的实时说话人嵌入层,据此准确识别出实时音频数据对应的说话者,从而整体提升识别稳定性,提高对平凡发音的处理能力。
58.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
59.通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
60.图1示出了根据本发明一个实施例的基于平凡发音的说话者识别方法的实施流程图;
61.图2示出了根据本发明一个实施例的unet网络的生成过程图;
62.图2a-图2d示出了根据本发明一个实施例的unet网络的网络结构示意图;
63.图2e示出了根据本发明一个实施例的自适应卷积核的生成逻辑示意图;
64.图2f示出了根据本发明一个实施例的unet网络的训练过程图;
65.图3示出了根据本发明一个实施例的说话者嵌入层网络的生成过程图;
66.图3a示出了根据本发明一个实施例的说话者嵌入层网络的训练过程图;
67.图4示出了根据本发明一个实施例的基于平凡发音的说话者识别系统的示意图。
具体实施方式
68.下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
69.本发明实施例公开了一种基于平凡发音的说话者识别方法,该方法主要目的是针对平凡发音具有发音时长短、易受环境噪声影响等方面的劣势,准确识别出平凡发音对应的说话者,整体提升识别稳定性,提高对平凡发音的处理能力。本实施例的方法可在多种场景下进行说话者识别,例如抓捕嫌疑人场景,嫌疑人通常仅会发出“嗯”、“啊”等平凡发音,
本实施例的方法可在该场景下仅根据“嗯”、“啊”等简短的平凡发音识别出所属嫌疑人。再例如,公司开会场景,在会议成员都在回答“嗯”、“啊”等简短的平凡发音时,可据此准确识别出各平凡发音所属成员。
70.为了进一步说明和解释本发明,下面参看图1,该方法包括下述步骤:
71.步骤11,获得实时音频数据,并基于实时音频数据进行频谱特征提取,得到实时音频数据对应的频谱特征。
72.其中,本实施例在对实时音频数据进行频谱特征提取时,依次经过短时傅里叶变换、取绝对值与取对数,得到对应的频谱特征。
73.步骤12,将实时音频数据对应的频谱特征输入完成训练的unet网络,生成实时音频数据对应的频谱遮罩。
74.在实际应用中,以平凡发音识别说话者时,需要优先判断实时音频数据对是否为平凡发音,在检测到实时音频数据不是平凡发音时,可直接终止,不运行说话者识别网络,以节省计算量。现有技术一般应用额外的语音唤醒网络检测实时音频数据是否为平凡发音,但此操作会增加系统的计算负担。
75.为了简化计算量,本实施类利用unet网络(一种网络模型)生成频谱遮罩,由于频谱遮罩具有检测实时音频数据是否为平凡发音的能力,因此无需再采用额外的语音唤醒网络进行计算。unet网络的网络结构和训练过程会在后续详细介绍,在此不再赘述。
76.步骤13,基于频谱遮罩检测实时音频数据是否为平凡发音。
77.在检测实时音频数据是否为平凡发音的过程中,基于频谱遮罩求取实时音频数据对应的频谱遮罩均值,通过频谱遮罩均值与用于区分平凡发音和其他音频的阈值α进行比较;当频谱遮罩均值大于α时,实时音频数据为平凡发音,否则为其他音频。在为平凡发音时,执行步骤14,在为其他音频时,停止下述操作,返回步骤11,处理另外的实时音频数据。值得注意的是,阈值α是在训练unet网络训练好之后,由第一数据集对应的频谱遮罩均值检测其中所有平凡发音以及其他音频的分布情况时产生,用作检测是否为平凡发音的标准。对于频谱遮罩来说,当实时音频数据是平凡发音时,频谱遮罩的大部分元素不会为0,此时对频谱遮罩无限制;而实时音频数据不是平凡发音时,频谱遮罩的值应接近于0。因此,实际应用时,可以使用简单的均值计算与阈值比较检测实时音频数据是否为平凡发音,以替代语音唤醒网络等复杂结构,从而大大减少系统存储量和计算量,提高处理效率。
78.步骤14,若实时音频数据为平凡发音,利用频谱遮罩和频谱特征融合,得到实时音频数据对应的增强频谱。
79.在本实施例中,频谱遮罩具有增强实时音频数据的能力。具体来说,由于平凡发音具有发音时长短、易受环境噪声影响等方面的劣势,在将实时音频数据的频谱特征输入说话人嵌入层网络前,本实施例额外增加了unet网络,利用输出的频谱遮罩和频谱特征融合,提升输入实时音频数据的品质,为后续得到高质量的实时说话人嵌入层,准确识别实时音频数据对应的说话者打好基础。
80.进一步的,在本实施例中,可采用点乘方式将频谱遮罩和频谱特征融合,从而得到对应的增强频谱。
81.步骤15,将实时音频数据对应的增强频谱输入完成训练的说话者嵌入层网络,获得实时音频数据对应的实时说话者嵌入层。
82.说话者嵌入层网络,主要目的为根据说话者发出的语音验证身份,说话者嵌入层网络的网络结构和训练过程后续会详细介绍,在此不再赘述。说话人嵌入层,是指利用说话者嵌入层网络处理实时音频数据的增强频谱后得到的代表说话者身份的矢量,可用于识别说话者。
83.步骤16,将实时说话者嵌入层和注册说话者嵌入层进行比较,用以识别实时音频数据对应的说话者。
84.在本实施例中,将实时说话者嵌入层和注册说话者嵌入层进行比较,判断两者是否为同一说话者,进而识别实时音频数据对应的说话者。若两者一致,则表示两者为同一说话者,从而能够识别出实时音频数据对应的说话者。若两者不一致,则无法识别实时音频数据对应的说话者。在实际应用中,将上述方案应用到具体的检测设备中之后,可根据语音播报、文字提示等方式公开识别结果。
85.本实施例的方法利用unet网络生成频谱遮罩来检测实时音频数据是否为平凡发音,并在确认时提升输入实时音频数据的品质,再结合说话者嵌入层网络来对说话者进行最终识别,从而提高对平凡发音的处理能力。
86.在上述图1所示实施例的基础上,作为本实施例一种可选的实施方式,本实施例介绍unet网络的结构及其训练方式。值得注意的是,unet网络的结构及其训练可在实施前述识别方案前操作。参看图2,该方法包括下述步骤:
87.步骤21,构建能够检测与增强平凡发音的unet网络的网络结构。
88.具体来说,unet网络的网络结构包括:两个以上自适应卷积模块、三个以上降采样模块、三个以上上采样模块和非线性作用函数(也即:s型函数)。图2a示出了unet网络中的最基本网络结构,各模块的具体使用数量以实际引用为准。s型函数输出频谱遮罩m。输入频谱s与频谱遮罩m点乘后得估计频谱完成对平凡发音的增强,以及其他音频的滤除。
89.其中,每个自适应卷积模块包括两个以上自适应二维卷积层,每个自适应二维卷积层后面增加bn(batch normalization,批标准化)层和relu(rectified linear unit,线性整流单元)函数。如图2b所示,示出了自适应卷积模块的最基本结构。
90.每个降采样模块包括一个以上自适应卷积模块和一个以上平均池化层。如图2c所示,示出了降采样模块的最基本结构。
91.每个上采样模块包括一个以上自适应二维转置卷积层、一个以上通道连接层和一个以上自适应卷积模块。如图2d所示,示出了降采样模块的最基本结构。
92.在本实施例中,因平凡发音受环境影响较大,而环境又处于随时变化之中,因此稳定性较差。为了应对这一难题,自适应二维卷积层的自适应卷积核同时参考输入数据的时域信息和频域信息生成;并且自适应二维转置卷积层的自适应卷积核也同时参考输入数据的时域信息和频域信息生成。可见,自适应二维卷积层和自适应二维转置卷积层均同时使用输入数据的时域信息和频域信息生成自适应卷积核,将其应用在unet网络中,能够提高网络对随机变化的环境噪声的稳定性,进而增强平凡发音频谱,使得说话者嵌入层网络可以获得高质量的说话者嵌入层,整体稳定性能够得以提升。
93.具体来说,自适应二维卷积层和自适应二维转置卷积层的自适应卷积核均按照下述步骤生成:首先,将输入数据分别在时域维度和频域维度进行转换,再合并为用于生成自适应卷积核的自适应数据。其中,自适应数据的尺寸包括:输入通道数,自适应卷积核频域
维度大小,自适应卷积核时域维度大小。其次,构建可训练参数。其中,可训练参数的尺寸包括:输出通道数,输入通道数,自适应卷积核频域维度大小,自适应卷积核时域维度大小。因可训练参数和自适应数据的尺寸大小并不一致,需将自适应数据沿输出通道数扩展至和可训练参数相同尺寸,并与可训练参数点乘,获得自适应卷积核。
94.具体来说,将输入数据分别通过时域平均池化和频域平均池化,得到不同尺寸的第一时域输出数据和第一频域输出数据;再将第一时域输出数据和第一频域输出数据各自进行一维卷积,得到不同尺寸的第二时域输出数据和第二频域输出数据。其中,第二时域输出数据的尺寸包括输入通道数和自适应卷积核频域维度,第二频域输出数据的尺寸包括输入通道数和自适应卷积核时域维度。由于两者的尺寸不一致无法合并,因此,需要将第二时域输出数据沿频域轴扩展,并将第二频域输出数据沿时间轴扩展,使第二时域输出数据和第二频域输出数据尺寸相同;再将第二时域输出数据和第二频域输出数据相加,得到自适应数据。
95.为了详细说明和解释本实施例,下面使用具体的示例进行说明自适应卷积核的生成过程。
96.如图2e所示,输入卷积的输入数据x的尺寸大小为[c
in
,f,t],其中,c
in
是输入通道数,f为频域维数,t为时间帧数。输入数据x首先分别通过时域平均池化和频域平均池化,得到尺寸大小为[c
in
,f]和[c
in
,t]的第一频域输出数据xf和第一时域输出数据x
t
,然后第一频域输出数据xf和第一时域输出数据x
t
各自通过一维卷积,得到新的输出第二频域输出数据x
′f和第二时域输出数据x
′
t
,尺寸大小分别为[c
in
,kf]和[c
in
,k
t
],其中kf和k
t
分别为自适应卷积核的频域维度大小和时域维度大小。由于此时两个数据x
′f和x
′
t
尺寸大小不同,不能直接相加,因此需要将第二频域输出数据x
′f沿着时间轴扩展到[c
in
,kf,k
t
],将第二时域输出数据x
′
t
沿着频域轴扩展到[c
in
,kf,k
t
],之后二者相加,得到用于生成自适应卷积核的自适应数据x
′
。
[0097]
除了得到自适应数据x
′
之外,自适应卷积还需要可训练参数k,尺寸大小为[c
out,cin
,kf,k
t
],其中c
out
是输出通道数。最后将自适应数据x
′
沿输出通道扩展尺寸至[c
out
,c
in
,kf,k
t
]后,与可训练参数参数k点乘,获得期望的自适应卷积核
[0098]
值得注意的是,输入数据x通过自适应二维卷积层或自适应二维转置卷积层时,需要先利用输入数据x按照上述过程生成自适应卷积核然后输入数据x与自适应卷积核进行卷积操作。由于自适应二维卷积层和自适应二维转置卷积层均同时在时域和频域对输入数据进行了缩放以及映射,因此应用了卷积层的网络,将提高对随机变化的环境噪声的稳定性。
[0099]
具体来说,自适应二维卷积层和自适应二维转置卷积层的基本计算流程图均包括:输入数据-生成用于生成自适应卷积核的自适应数据-生成自适应卷积核-自适应二维卷积(或自适应二维转置卷积)计算-输出。其中,自适应数据的和自适应卷积核的生成过程参看图2e。自适应二维卷积和自适应二维转置卷积在计算时的主要区别在于,自适应二维转置卷积层的自适应卷积核(也称为转置卷积核)的参数尺寸大小为:[输入通道,输出通道,自适应卷积核高,自适应卷积核宽],不同于自适应二维卷积层的自适应卷积核的尺寸大小:[输出通道,输入通道,自适应卷积核高,自适应卷积核宽],因此需要额外的转置操作。此外,自适应卷积核改变维度时,是将[批次大小,输入通道,输出通道,自适应卷积核
高,自适应卷积核宽]变为[批次大小*输入通道,输出通道,自适应卷积核高,自适应卷积核宽]。
[0100]
在unet网络的网络结构中,由于自适应二维卷积层和自适应二维转置卷积层可直接替代unet网络中的普通二维卷积和普通二维转置卷积,因此无需修改unet网络结构。
[0101]
以上是unet网络的网络结构介绍,在此基础上执行步骤22,基于unet网络的网络结构进行训练。参看图2f,unet网络按照下述方式进行训练:
[0102]
步骤221,获得第一数据集。第一数据集包括:源语音数据x
source
、流式标签y
′
hmm
和目标语音数据x
target
。源语音数据x
source
为包含平凡发音的整句语音,例如包含了平凡发音“嗯”声的整句语音;流式标签y
′
hmm
在平凡发音“嗯”声出现的语音段值为1,其他部分均为0;目标语音数据x
target
由源语音数据x
source
转换得到,时间长度与x
source
一致,但在平凡发音“嗯”声出现的时间段内没有杂音,只有干净的“嗯”声,其他时间段的数据为0值。
[0103]
步骤221,基于第一数据集进行频谱特征提取,得到源语音数据x
source
对应的输入频谱s
source
和目标语音数据x
target
对应的目标频谱s
target
。具体的,源语音数据x
source
和目标语音数据x
target
分别依次经过短时傅里叶变换、取绝对值与取对数,得到对应的输入频谱s
source
和目标频谱s
target
。
[0104]
步骤222,基于数据集帧级别标签获取,得到流式标签y
′
hmm
对应的帧级别标签y
hmm
。具体的,流式标签y
′
hmm
按照前述短时傅里叶变换使用的帧移变为帧级别标签y
hmm
。
[0105]
步骤223,计算损失函数。
[0106]
在本实施例中,unet网络生成的频谱遮罩m能够检测实时音频数据是否为平凡发音,并且增强平凡发音的频谱。其主要原因在于unet网络的损失函数包括频谱优化和频谱遮罩优化。
[0107]
其中,频谱优化通过减小增强频谱和目标频谱s
target
的差异来实现,增强频谱由输入频谱s
source
输入unet网络后得到频谱遮罩m,再与输入频谱s
source
点乘得到。在本实施例中,增强频谱和目标频谱s
target
的差异越小越好。该差异可选为mse(mean square error,均方误差)函数。
[0108]
对于频谱遮罩m,本实施例需要据此直观给出当前语音帧是否含有平凡发音。当前语音帧为平凡发音时,频谱遮罩m的大部分元素不会为0,因此无需做出限制,由于平凡发音声以外的其他音频均需要滤除,即输出频谱的值为0,此时频谱遮罩m的值也应接近于0,因此,可使用m中所有元素的均值指示当前语音帧的内容,并采用下式优化频谱遮罩m:当前语音帧为平凡发音时,1-y
hmm
的值为0,对频谱遮罩m的优化无限制;当前语音帧为其他音频内容时,1-y
hmm
的值为1,损失函数为计算方式采用平均绝对误差l1损失函数,代表频谱遮罩m应向0值方向优化,为频谱遮罩均值。
[0109]
结合上述描述,在本实施例中提供一种损失函数为:结合上述描述,在本实施例中提供一种损失函数为:其中,mse表示均方误差函数。该损失函数包括对频谱的优化和对频谱遮罩m的优化,从而能够支持unet网络生成频谱遮罩m,并使频谱遮罩m具备检测实时音频数据是否为平凡发音,并且增强平凡发音的频谱的能力。
[0110]
步骤224,基于损失函数l进行反向传播训练unet网络的参数直至收敛。
[0111]
在unet网络训练完毕之后,考虑到额外使用语音唤醒网络的计算量太大,本实施
分析频谱遮罩均值对第一数据集中所有平凡发音以及其他音频的分布情况,确定用于区分第一数据集中平凡发音和其他音频的阈值α;其中,当大于α时,频谱遮罩对应的源音频数据x
source
为平凡发音,否则为其他音频,通过使用简单的均值计算与阈值比较检测实时音频数据是否为平凡发音,以替代语音唤醒网络等复杂结构,从而大大减少系统存储量和计算量,提高处理效率。
[0112]
在上述图1所示实施例的基础上,作为本实施例一种可选的实施方式,本实施例介绍说话者嵌入层网络的结构及其训练方式。值得注意的是,此实施例可在实施前述识别方案前事先进行准备。参看图3,该方法包括下述步骤:
[0113]
步骤31,构建说话者嵌入层网络的网络结构。
[0114]
其中,说话者嵌入层网络的网络结构包括:帧级别特征提取模块、时间平均池化模块和句级别特征提取模块;其中,帧级别特征提取模块包括:若干层卷积层、池化层和批标准化bn层,句级别特征提取模块包括两层以上全连接层。
[0115]
以上是说话者嵌入层网络的网络结构介绍,在此基础上执行步骤32,基于说话者嵌入层网络的网络结构进行训练。
[0116]
参看图3a,说话者嵌入层网络按照下述方式进行训练:
[0117]
步骤321,获得第二数据集。
[0118]
其中,第二数据集中的语音数据均为平凡发音,且语音数据均具有说话者标签。
[0119]
步骤322,基于第二数据集进行频谱特征提取,获得待处理频谱。
[0120]
具体的,将第二数据集中的语音数据依次通过短时傅里叶变换、取绝对值与取对数,获得待处理频谱。
[0121]
步骤323,将待处理频谱输入完成训练的unet网络,获得待处理频谱对应的增强频谱。
[0122]
具体的,将每一条待处理频谱都通过完成训练的unet网络,获得对应增强频谱。
[0123]
步骤324,将待处理频谱对应的增强频谱作为输入,待处理频谱对应的说话者标签作为输出,基于损失函数反向传播训练说话人嵌入层网络的参数直至收敛。
[0124]
其中,损失函数可选为交叉熵,此时句级别特征提取模块后应额外连接一个全连接层代表所有说话人,训练结束后移除该全连接层。
[0125]
以上是说话者嵌入层网络的训练过程,在说话者嵌入层网络完成训练之后,可利用其处理说话者的注册音频,得到注册说话者嵌入层。
[0126]
具体的,注册说话者嵌入层按照下述步骤得到:采集说话者的注册音频并进行频谱特征提取,获得注册音频对应的频谱特征。其中,注册音频为平凡发音。将注册音频对应的频谱特征通过完成训练的unet网络,获得注册音频对应的频谱遮罩。将注册音频对应的频谱特征与注册音频对应的频谱遮罩融合,获得注册音频对应的增强频谱。将注册音频对应的增强频谱输入完成训练的说话者嵌入层网络,获得注册说话者嵌入层。
[0127]
基于和前述一个或者多个实施例相同的发明构思,下面的实施例介绍一种基于平凡发音的说话者识别系统,参看图4,包括:
[0128]
获得模块41,用于获得实时音频数据,并基于实时音频数据进行频谱特征提取,得到实时音频数据对应的频谱特征;
[0129]
第一网络处理模块42,用于将实时音频数据对应的频谱特征输入完成训练的unet
网络,生成实时音频数据对应的频谱遮罩;
[0130]
判断模块43,用于基于频谱遮罩检测实时音频数据是否为平凡发音;
[0131]
融合模块44,用于若实时音频数据为平凡发音,利用频谱遮罩和频谱特征融合,得到实时音频数据对应的增强频谱;
[0132]
第二网络处理模块45,用于将实时音频数据对应的增强频谱输入完成训练的说话者嵌入层网络,获得实时音频数据对应的实时说话者嵌入层;
[0133]
比较模块46,用于将实时说话者嵌入层和注册说话者嵌入层进行比较,用以识别实时音频数据对应的说话者。
[0134]
基于和前述一个或者多个实施例相同的发明构思,本发明实施例还公开了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现前文任一方法的步骤。
[0135]
基于和前述一个或者多个实施例相同的发明构思,本发明实施例还公开了一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现前文任一方法的步骤。
[0136]
通过本发明的一个或者多个实施例,本发明具有以下有益效果或者优点:
[0137]
本发明公开了一种基于平凡发音的说话者识别方法、系统、存储介质及设备,为了应对平凡发音在发音时长短、易受环境噪声影响等方面的劣势,本发明的方法在获得实时音频数据并执行频谱特征提取后,将频谱特征输入完成训练的unet网络用以生成频谱遮罩,通过频谱遮罩来判断实时音频数据是否为平凡发音来避免使用额外的语音唤醒网络等复杂结构,从而能够减少系统的存储量和计算量;此外,通过频谱遮罩与频谱特征融合,能实现对实时音频数据的增强,使得说话人嵌入层网络可以据此获得高质量的实时说话人嵌入层,据此准确识别出实时音频数据对应的说话者,从而整体提升识别稳定性,提高对平凡发音的处理能力。
[0138]
在此提供的算法和显示不与任何特定计算机、虚拟系统或者其它设备固有相关。各种通用系统也可以与基于在此的示教一起使用。根据上面的描述,构造这类系统所要求的结构是显而易见的。此外,本发明也不针对任何特定编程语言。应当明白,可以利用各种编程语言实现在此描述的本发明的内容,并且上面对特定语言所做的描述是为了披露本发明的最佳实施方式。
[0139]
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本发明的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
[0140]
类似地,应当理解,为了精简本发明并帮助理解各个发明方面中的一个或多个,在上面对本发明的示例性实施例的描述中,本发明的各个特征有时被一起分组到单个实施例、图、或者对其的描述中。然而,并不应将该公开的方法解释成反映如下意图:即所要求保护的本发明要求比在每个权利要求中所明确记载的特征更多的特征。更确切地说,如下面的权利要求书所反映的那样,发明方面在于少于前面公开的单个实施例的所有特征。因此,遵循具体实施方式的权利要求书由此明确地并入该具体实施方式,其中每个权利要求本身都作为本发明的单独实施例。
[0141]
本领域那些技术人员可以理解,可以对实施例中的设备中的模块进行自适应性地
改变并且把它们设置在与该实施例不同的一个或多个设备中。可以把实施例中的模块或单元或组件组合成一个模块或单元或组件,以及此外可以把它们分成多个子模块或子单元或子组件。除了这样的特征和/或过程或者单元中的至少一些是相互排斥之外,可以采用任何组合对本说明书(包括伴随的权利要求、摘要和附图)中公开的所有特征以及如此公开的任何方法或者设备的所有过程或单元进行组合。除非另外明确陈述,本说明书(包括伴随的权利要求、摘要和附图)中公开的每个特征可以由提供相同、等同或相似目的的替代特征来代替。
[0142]
此外,本领域的技术人员能够理解,尽管在此的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本发明的范围之内并且形成不同的实施例。例如,在下面的权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
[0143]
本发明的各个部件实施例可以以硬件实现,或者以在一个或者多个处理器上运行的软件模块实现,或者以它们的组合实现。本领域的技术人员应当理解,可以在实践中使用微处理器或者数字信号处理器(dsp)来实现根据本发明实施例的网关、代理服务器、系统中的一些或者全部部件的一些或者全部功能。本发明还可以实现为用于执行这里所描述的方法的一部分或者全部的设备或者装置程序(例如,计算机程序和计算机程序产品)。这样的实现本发明的程序可以存储在计算机可读介质上,或者可以具有一个或者多个信号的形式。这样的信号可以从因特网网站上下载得到,或者在载体信号上提供,或者以任何其他形式提供。
[0144]
应该注意的是上述实施例对本发明进行说明而并非限制,并且本领域技术人员在不脱离所附权利要求的范围的情况下可设计出替换实施例。在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包括”不排除存在未列在权利要求中的元件或步骤。位于元件之前的单词“一”或“一个”不排除存在多个这样的元件。本发明可以借助于包括有若干不同元件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1