语音转换模型的训练方法、装置、设备及介质与流程
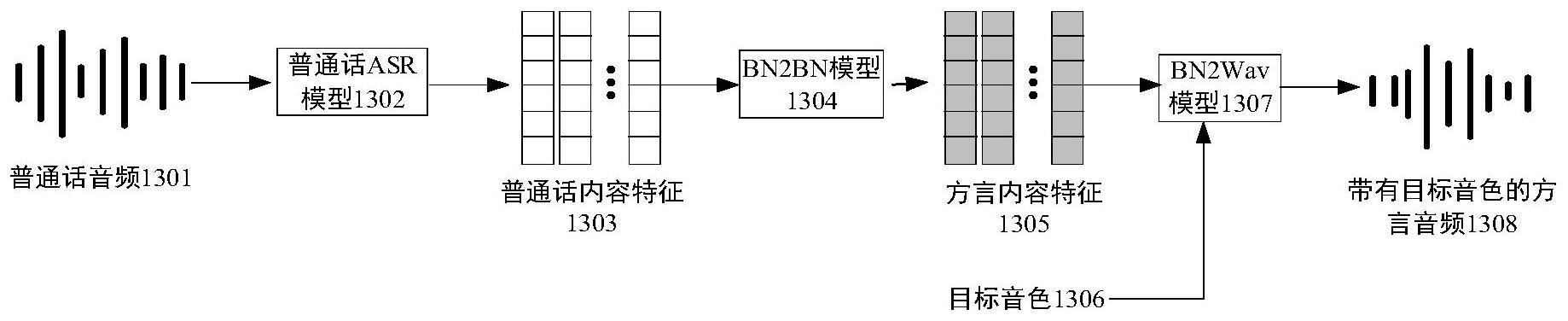
本申请实施例涉及音频处理,特别涉及一种语音转换模型的训练方法、装置、设备及介质。
背景技术:
1、随着网络技术的不断发展,越来越多用户开始使用虚拟形象在网络中进行直播、游戏、社交或者在线会议。
2、为了保护个人隐私安全,用户在使用虚拟形象过程中,可以设置虚拟形象的口音,使原始口音的用户语音被转换为所设置口音后播放,并保证用户语音内容保持不变。相关技术中,口音转换通常使用语音转换模型实现,而在训练语音转换模型过程中,需要基于大量平行语料。其中,该平行语料为相同语音内容的不同口音音频。
3、然而,平行语料通常需要人工录制,导致平行语料的获取难度较高,在平行语料不足的情况下,训练得到语音转换模型的质量较差,进而影响口音转换效果。
技术实现思路
1、本申请实施例提供了一种语音转换模型的训练方法、装置、设备及介质,能够在降低对人工录制的平行语料的需求的前提下,保证语音转换模型的训练质量。所述技术方案如下:
2、一方面,本申请实施例提供了一种语音转换模型的训练方法,包括:
3、基于第一样本音频训练第一asr(automatic speech recognition,自动语音识别)模型,以及基于第二样本音频训练第二asr模型,所述第一样本音频对应第一口音,所述第二样本音频对应第二口音;
4、基于所述第一样本音频对应的第一样本文本以及第一样本内容特征,训练第一转换模型,所述第一样本内容特征由所述第一asr模型对所述第一样本音频进行提取得到,所述第一转换模型用于将文本转换为所述第一口音的内容特征;
5、基于所述第一转换模型、所述第二样本音频对应的第二样本文本以及第二样本内容特征,构建平行样本数据,所述第二样本内容特征由所述第二asr模型对所述第二样本音频进行提取得到,所述平行样本数据由不同内容特征构成,不同内容特征对应不同口音,且不同内容特征对应相同文本;
6、基于所述平行样本数据训练第二转换模型,所述第二转换模型用于对所述第一口音和所述第二口音间进行内容特征转换;
7、基于不同样本音频的样本内容特征训练第三转换模型,所述第三转换模型用于将内容特征转换为音频;
8、基于训练得到的所述第一asr模型、所述第二转换模型和所述第三转换模型生成语音转换模型,所述语音转换模型用于将第一口音的音频转换为第二口音的音频。
9、另一方面,本申请实施例提供了一种语音转换模型的训练装置,所述装置包括:
10、训练模块,用于基于第一样本音频训练第一asr模型,以及基于第二样本音频训练第二asr模型,所述第一样本音频对应第一口音,所述第二样本音频对应第二口音;
11、所述训练模块,还用于基于所述第一样本音频对应的第一样本文本以及第一样本内容特征,训练第一转换模型,所述第一样本内容特征由所述第一asr模型对所述第一样本音频进行提取得到,所述第一转换模型用于将文本转换为所述第一口音的内容特征;
12、所述训练模块,还用于基于所述第一转换模型、所述第二样本音频对应的第二样本文本以及第二样本内容特征,构建平行样本数据,所述第二样本内容特征由所述第二asr模型对所述第二样本音频进行提取得到,所述平行样本数据由不同内容特征构成,不同内容特征对应不同口音,且不同内容特征对应相同文本;基于所述平行样本数据训练第二转换模型,所述第二转换模型用于对所述第一口音和所述第二口音间进行内容特征转换;
13、所述训练模块,还用于基于不同样本音频的样本内容特征训练第三转换模型,所述第三转换模型用于将内容特征转换为音频;
14、生成模块,用于基于训练得到的所述第一asr模型、所述第二转换模型和所述第三转换模型生成语音转换模型,所述语音转换模型用于将第一口音的音频转换为第二口音的音频。
15、另一方面,本申请实施例提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现如上述方面所述的语音转换模型的训练方法。
16、另一方面,本申请实施例提供了一种计算机可读存储介质,所述可读存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如上述方面所述的语音转换模型的训练方法。
17、另一方面,本申请实施例提供了一种计算机程序产品,所述计算机程序产品包括计算机指令,所述计算机指令存储在计算机可读存储介质中;计算机设备的处理器从所述计算机可读存储介质读取所述计算机指令,所述处理器执行所述计算机指令,使得所述计算机设备执行如上述方面所述的语音转换模型的训练方法。
18、本申请实施例中,在缺少第二口音的第二样本音频对应平行语料的情况下,首先基于第一口音的第一样本音频,训练用于将文本转换为内容特征的第一转换模型,从而利用该第一转换模型以及第二样本音频对应的第二样本文本,构建得到包含对应相同文本内容但对应不同口音的平行样本数据,进而利用该平行样本数据训练在不同口音间进行内容特征转换的第二转换模型,以及用于将内容特征转换为音频的第三转换模型,完成语音转换模型训练;模型训练过程中,利用训练得到的中间模型构建平行语料,无需在模型训练前录制不同口音的平行语料,能够在保证模型训练质量的情况下,降低模型训练对人工录制的平行语料的需求,有助于提高模型训练效率,并提高样本不足情况下模型的训练质量。
技术特征:
1.一种语音转换模型的训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述第一转换模型、所述第二样本音频对应的第二样本文本以及第二样本内容特征,构建平行样本数据,包括:
3.根据权利要求2所述的方法,其特征在于,所述基于所述平行样本数据训练第二转换模型,包括:
4.根据权利要求1所述的方法,其特征在于,所述基于所述第一样本音频对应的第一样本文本以及第一样本内容特征,训练第一转换模型,包括:
5.根据权利要求4所述的方法,其特征在于,所述第一转换模型中包括第一转换子模型、时长预测子模型以及第二转换子模型;
6.根据权利要求5所述的方法,其特征在于,所述第一转换子模型和所述第二转换子模型由fft堆叠而成,所述fft由多头注意力机制层和卷积层构成。
7.根据权利要求1所述的方法,其特征在于,所述基于不同样本音频的样本内容特征训练第三转换模型,包括:
8.根据权利要求7所述的方法,其特征在于,所述第三转换模型包括第三转换子模型以及声码器;
9.根据权利要求8所述的方法,其特征在于,所述将所述预测音频谱特征输入所述声码器,得到所述预测音频之前,所述方法还包括:
10.根据权利要求1至9任一所述的方法,其特征在于,所述方法包括:
11.根据权利要求10所述的方法,其特征在于,所述口音转换指令中包含目标音色;
12.一种语音转换模型的训练装置,其特征在于,所述装置包括:
13.一种计算机设备,其特征在于,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由所述处理器加载并执行以实现如权利要求1至11任一所述的语音转换模型的训练方法。
14.一种计算机可读存储介质,其特征在于,所述可读存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如权利要求1至11任一所述的语音转换模型的训练方法。
15.一种计算机程序产品,其特征在于,所述计算机程序产品包括计算机指令,所述计算机指令存储在计算机可读存储介质中;计算机设备的处理器从所述计算机可读存储介质读取所述计算机指令,所述处理器执行所述计算机指令,使得所述计算机设备执行如权利要求1至11任一所述的语音转换模型的训练方法。
技术总结
本申请公开了一种语音转换模型的训练方法、装置、设备及介质。包括:基于第一样本音频训练第一ASR模型,以及基于第二样本音频训练第二ASR模型;基于第一样本音频对应的第一样本文本以及第一样本内容特征,训练第一转换模型,第一转换模型用于将文本转换为第一口音的内容特征;基于第一转换模型、第二样本音频对应的第二样本文本以及第二样本内容特征,构建平行样本数据;基于平行样本数据训练第二转换模型,第二转换模型用于对第一口音和第二口音间进行内容特征转换;基于不同样本音频的样本内容特征训练第三转换模型,第三转换模型用于将内容特征转换为音频;基于训练得到的第一ASR模型、第二转换模型和第三转换模型生成语音转换模型。
技术研发人员:杨培基
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!