一种莫尔斯自动识别模型的构建方法及自动识别方法与流程
1.本发明涉及报文识别技术领域,尤其涉及一种莫尔斯自动识别模型的构建方法及自动识别方法。
背景技术:
2.莫尔斯码是一种用不同时长的高低电平表示信息的编码方式,电平信号的不同组合代表了不同的符号、数字和英文字母。在无线电领域,莫尔斯码用短音表示高电平中的短码,长音表示高电平中的长码,通常用“嘀”和“嗒”描述这两种信号,收信人员通过听觉识别完成信号的接收。莫尔斯电码的发送方式通常分为机器发送和人工发送,传统的接收方式是人工听音辨识。通常情况下,通过人工听音辨识的方式接收莫尔斯电码,不仅对信号员的专业度和熟练度有较高要求,而且在长时间单一重复的辨识工作中,信号员的收信和译码的准确性也会受到影响。
3.伴随着人工智能的发展,以深度学习技术为基础的莫尔斯自动识别成为新的接收方式。现有技术包括基于卷积神经网络(cnn)、双向长短时记忆网络(bi-lstm)的端到端识别方法以及基于卷积神经网络(cnn)的图像识别方法。由于真实场景下的莫尔斯通信存在发送数据的互相差异性和信号传输、接收的不稳定性,具体表现为人工发送的数据随意性较强,传输和接收过程中易受天气等因素影响产生较大干扰噪音,导致现有的莫尔斯自动识别模型虽然在一定程度上实现了自动识别,但是没有针对差异信号识别和噪声干扰问题的完善解决方案,准确率不能达到业务要求,需要进行大量人工矫正工作。可见,亟需一种能够针对莫尔斯通信特点的全新莫尔斯自动识别模型及自动识别方法,以提高自动识别的准确率,减轻人工矫正的工作量。
技术实现要素:
4.鉴于上述的分析,本发明实施例旨在提供一种莫尔斯自动识别模型的构建方法及自动识别方法,用以解决现有技术中莫尔斯自动识别模型准确率不高,识别结果需要大量人工矫正的问题。
5.一方面,本发明实施例提供了一种莫尔斯自动识别模型的构建方法包括如下步骤:
6.获取莫尔斯语音数据,对莫尔斯音频数据进行标注,得到标注后的数据集d
p’;
7.对标注后的数据集d
p’进行预处理,得到包含原始语速数据和扩展语速数据的预处理数据集d
p1
;
8.对所述预处理数据集d
p1
进行莫尔斯特征提取和特征扩展,得到由莫尔斯语音特征序列和其对应的字符序列构成的训练数据集d
t
;
9.利用所述训练数据集d
t
对语音识别模型m进行训练,得到训练好的莫尔斯自动识别模型m
p
,其中所述语音识别模型m基于transformer框架构建。
10.进一步的,所述对莫尔斯音频数据进行标注包括:
11.通过听译语音标注系统对已切分的莫尔斯语音片段进行标注,将莫尔斯音频数据标注为对应的莫尔斯报文字符;其中所述标注后的数据集d
p’包括语音数据和其对应的标注文本。
12.进一步的,所述对标注后的数据集d
p’进行预处理,包括:
13.将标注后的莫尔斯数据集d
p’以速度变化作扩展,得到由加速语音数据和减速语音数据构成的扩展语速数据;
14.将所述扩展语速数据和原始的标注后的莫尔斯数据集d
p’整合在一起作为模型的预处理数据集d
p1
;
15.进一步的,所述莫尔斯特征提取,包括:
16.(1)对所述训练数据集d
t
中的语音数据进行莫尔斯语音特征频带范围的特征提取,得到每帧语音数据降维后的fbank特征数据集dr;
17.(2)对降维后的fbank特征数据集dr进行拼帧和跳帧的特征处理,得到包含上下文语音特征的fbank特征数据集d
r’,具体公式如下:
18.p(f
n*d
)=f’m*(k+1)d
19.其中f为初始特征,维度为n*d,n代表单条语音数据的帧数,d代表每帧的特征维度,p为拼帧跳帧处理;f’为拼帧跳帧处理后的特征,维度为m*(k+1)d,k为拼k帧跳k帧中的帧数,m为拼帧跳帧处理之后的单条语音数据的特征序列长度。
20.进一步的,所述特征扩展,包括:
21.(1)使用预处理数据集d
p1
对gmm-hmm声学模型进行训练,通过维特比对齐得到单个莫尔斯字符在语音数据对应帧中的特征序列并作为候选特征序列,建立每个莫尔斯字符与所述候选特征序列的映射表;
22.(2)获取历史积累的莫尔斯文本数据,根据所述文本数据中的字符内容从映射表中随机选取对应字符的一条候选特征序列作为单个字符的伪语音特征序列进行完整的单条所述文本数据的伪语音特征拼接,得到包含拼接后的单条文本的伪语音特征序列和其对应的单条文本字符序列的伪特征数据集dh;
23.(3)将数据集d
r’和伪特征数据集dh合并,得到包含莫尔斯语音特征序列和其对应的字符序列的训练数据集d
t
。
24.进一步的,所述对语音识别模型m进行训练包括:
25.(1)采用迁移学习的方式,设置语音识别模型m的初始隐层参数,得到模型m1。其中,所述初始隐层参数,即使用标注数据充分的语音数据训练好的模型的隐层参数;
26.(2)将词表v导入所述模型m1;其中,所述词表v通过统计标注后的数据集d
p
中每个标注字符的频度而获得;
27.(3)使用训练数据集d
t
对所述模型m1进行训练,以标注字符序列为目标输出,训练得到莫尔斯自动识别模型m
p
。
28.进一步的,使用训练数据集d
t
对所述模型m1进行训练,包括:
29.将所述训练数据集d
t
划分为训练集d
train
、验证集d
valid
、测试集d
test
,用d
train
训练模型,用d
valid
进行验证,所述训练集d
train
输入所述模型m1,输出最终结果概率;计算损失并更新模型参数,迭代n轮取最后的m轮模型参数的算术平均作为最终参数,得到训练好的莫尔斯自动识别模型m
p
;
30.更进一步的,训练模型的损失函数为:
[0031][0032]
其中,为transformer的交叉熵损失,为字错误率;yi表示样本i的标注,pi表示样本i预测为正确的概率;字错误指标用于反映识别结果和标注字符序列的编辑距离占标注字符总数的比率,其中s表示需替换的字符数,d表示需删除的字符数,i表示需插入的字符数,n表示标注字符的总数;
[0033]
更进一步的,测试模型采用字错误率(cer)指标,其公式为:
[0034]
accuracy=1-cer
[0035]
其中,s表示需替换的字符数,d表示需删除的字符数,i表示需插入的字符数,n表示标注字符的总数,accuracy表示正确率。
[0036]
进一步的,所述语音识别模型m包括:
[0037]
所述语音模型m基于transformer框架构建,包括一个编码器和一个解码器;其中,所述编码器由n个相同的块组成,所述块包含第一子层多头注意力(multi-head self-attention)和第二子层前馈网络(feed forward network),所述第一子层和所述第二子层均包含一层残差网络连接归一化的下一级子层;所述解码器由n个相同的块组成,包含第三子层多头注意力(multi-head self-attention)、第四子层前馈网络(feed forward network)以及第五子层多头源关注,所述第三子层、所述第四子层和所述第五子层均包含一层残差网络连接归一化的下一级子层。其中,所述第五子层位于第三子层与第四子层之间,用于对编码器堆栈的输出表示执行多头源关注。
[0038]
本发明另一方面还公开了一种莫尔斯自动识别方法,包括如下步骤:
[0039]
获取待识别莫尔斯语音数据d;
[0040]
对待识别莫尔斯语音数据d进行预处理,得到预处理后的数据d’;
[0041]
对预处理后的数据d’进行莫尔斯特征提取,得到包含莫尔斯语音特征序列的莫尔斯特征数据df;
[0042]
将莫尔斯特征数据df输入基于莫尔斯自动识别模型的构建方法构建得到的莫尔斯自动识别模型,识别得到对应的莫尔斯字符文本数据。
[0043]
进一步的,所述对待识别莫尔斯语音数据进行预处理,包括:
[0044]
将所述待识别莫尔斯语音数据d分离为语音段和非语音段;
[0045]
以非语音位置作为分割位置,将所述待识别莫尔斯语音数据d分割为为多个有效的语音片段,得到切分后的数据d’。
[0046]
与现有技术相比,本发明技术方案至少可实现如下有益效果之一:
[0047]
1、在训练基于transformer的语音识别模型的方法中,通过构建伪特征数据扩充训练数据,采用迁移学习的方法共享隐层参数,解决了因训练数据匮乏而导致模型训练不充分的问题;在模型迭代计算中将字错误率计入损失,调节模型的权重,使模型取得更好的训练效果;
[0048]
2、在训练数据集的构建的方法中,采用了模拟实际发送中人工发送信号的速度差
异以速度变化扩展训练数据,使模型得到更充分的训练,提高了模型对互相差异的发送数据的识别准确率;
[0049]
3、在莫尔斯语音的特征提取的方法中,采用了针对莫尔斯语音特征频带范围的特征提取以降低特征维度,采用拼帧跳帧的方法以获得包含上下文语音特征的fbank特征,通过获得更好的莫尔斯语音特征表征,一定程度上解决了莫尔斯语音数据中的噪声干扰问题。
[0050]
本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
附图说明
[0051]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
[0052]
图1为本发明实施例的莫尔斯自动识别模型构建方法流程图;
[0053]
图2为本发明实施例的莫尔斯自动识别模型构建方法示意图;
[0054]
图3为本发明实施例的莫尔斯音频语谱图;
[0055]
图4为本发明实施例训练数据集构建方法流程示意图;
[0056]
图5为本发明实施例构建伪特征数据示意图;
[0057]
图6为本发明实施例获取单个字符候选特征序列示意图;
[0058]
图7为本发明实施例的基于transformer的模型结构示意图;
[0059]
图8为本发明实施例的基于transformer的模型训练示意图。
具体实施方式
[0060]
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本技术一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
[0061]
实施例1
[0062]
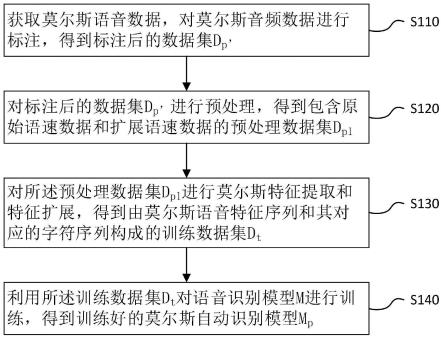
本发明的一个具体实施例,公开了一种莫尔斯自动识别模型的构建方法,如图1所示,包括:
[0063]
步骤s110、获取莫尔斯语音数据集,对莫尔斯语音数据进行标注,得到标注后的数据集d
p’;
[0064]
步骤s120、对标注后的数据集d
p’进行语速预处理,得到包含原始语速数据和扩展语速数据的预处理后数据集d
p1
;
[0065]
步骤s130、对所述预处理后数据集d
p1
进行莫尔斯特征提取和特征扩展,得到由莫尔斯语音特征序列和其对应的字符序列构成的训练数据集d
t
;
[0066]
步骤s140、利用所述训练数据集d
t
对语音识别模型m进行训练,得到训练好的莫尔斯自动识别模型m
p
,其中所述语音识别模型m基于transformer框架构建。
[0067]
本发明实施例,通过构建针对莫尔斯语音数据特点的训练数据集,在对基于transformer的语音识别模型的训练中,采用了扩展构建伪特征数据、迁移学习以及将字错
误率计入模型损失等方法,实现了在有限标注语音数据的条件下达到较高识别准确率的效果,解决了现有技术中因发送信号差异和噪声干扰问题造成的识别准确率不高的问题。
[0068]
在上述实施例的基础上,具体的,上述步骤s110中的获取莫尔斯语音数据包括收集用户使用的莫尔斯通信业务数据。
[0069]
具体的,所述对莫尔斯音频数据进行标注包括:
[0070]
通过听译语音标注系统对已切分的莫尔斯语音片段进行标注,将莫尔斯音频数据标注为对应的莫尔斯报文字符;其中,所述标注后的数据集d
p’包括语音数据和其对应的标注字符文本。
[0071]
具体的,上述步骤s120还可以优化为以下步骤:
[0072]
将标注后的莫尔斯数据集d
p’以速度变化作扩展,得到由加速语音数据和减速语音数据构成的扩展语速数据;
[0073]
将所述扩展语速数据和原始的标注后的莫尔斯数据集d
p’整合在一起作为预处理后数据集d
p1
。
[0074]
优选的,将标注后莫尔斯数据集d
p’以原始速度的0.9倍和1.1倍变化,扩展出2倍于所述标注后莫尔斯数据集d
p’的标注数据,与所述标注后莫尔斯数据集d
p’整合在一起作为预处理数据集d
p1
;需要说明的是,以速度变化扩展数据可以模拟实际发送中人工发送信号的速度差异,使模型得到更充分的训练。
[0075]
具体的,上述步骤s130中莫尔斯特征提取,包括:
[0076]
(1)对所述预处理后数据集d
p1
中的语音数据进行莫尔斯语音特征频带范围的特征提取,得到每帧语音数据降维后的fbank特征数据集dr。
[0077]
可选的,使用kaldi语音特征提取工具对所述训练数据集d
t
中的语音数据进行特征提取,通过设置kaldi的频率上下限参数实现莫尔斯语音特征范围的特征提取。
[0078]
可选的,所述降维后的fbank特征数据集dr每帧的特征维度范围为10~40。
[0079]
优选的,所述莫尔斯语音特征频带范围为900hz~1100hz。
[0080]
优选的,所述降维后的fbank特征数据集dr每帧的特征维度为10。
[0081]
需要说明的是,对常见语音(发音频率分布在0hz~8000hz或者0hz~16000hz)进行特征提取,特征维度将达到几十维或上百维,对莫尔斯语音(频率只分布在1000hz附近)进行特征提取,通过将频带范围限制在莫尔斯语音特征范围内,特征维度可降低到10维。这将极大地降低模型的计算量,一定程度上提高了模型的训练速度。
[0082]
(2)对降维后的fbank特征数据集dr进行拼帧和跳帧的特征处理,得到包含上下文语音特征的fbank特征数据集d
r’,具体公式如下:
[0083]
p(f
n*d
)=f’m*(k+1)d
[0084]
其中f为初始特征,维度为n*d,n代表单条语音数据的帧数,d代表每帧的特征维度,p为拼帧跳帧处理;f’为拼帧跳帧处理后的特征,维度为m*(k+1)d,k为拼k帧跳k帧中的帧数,m为拼帧跳帧处理之后的单条语音数据的特征序列长度。
[0085]
优选的,采用拼3帧跳3帧的方法对降维后每帧的特征维度为10的fbank特征数据集dr进行特征处理,具体公式如下:
[0086]
p(f
n*10
)=f’m*40
[0087]
其中f为kaldi提取的特征,维度为n*10,n代表单条语音数据的帧数,p为拼3帧跳3
帧处理,f’为处理后的特征,维度为m*40,m为拼3帧跳3帧处理之后的单条语音数据的特征序列长度。
[0088]
需要说明的是,根据莫尔斯语音数据的时序特点,采用拼帧和跳帧的方法进行特征处理,得到包含上下文语音特征的fbank特征以表征莫尔斯音频数据,可以加快模型运行速度以及获更好的识别性能。
[0089]
具体的,上述步骤s130中的特征扩展,包括:
[0090]
(1)使用预处理数据集d
p1
对gmm-hmm声学模型进行训练,通过维特比对齐得到单个莫尔斯字符在语音数据对应帧中的特征序列并作为候选特征序列,建立每个莫尔斯字符与所述候选特征序列的映射表;
[0091]
示例性的,字符序列“56486
……”
,其对应语音数据为0-120帧,fbank特征维度为120*10,经过gmm-hmm模型训练和维特比对齐后,确定5对应语音数据的0-20帧,则5对应的候选特征序列的维度为20*10。
[0092]
(2)获取历史积累的莫尔斯文本数据,根据所述文本数据中的字符内容从映射表中随机选取对应字符的一条候选特征序列作为单个字符的伪语音特征序列进行完整的单条所述文本数据的伪语音特征拼接,得到包含拼接后的单条文本的伪语音特征序列和其对应的单条文本字符序列的伪特征数据集dh;
[0093]
示例性的,所述单条文本的伪语音特征序列的表达式为:
[0094]fn*10
=c{f
m1*10
,f
m2*10
,f
m3*10
,
…
}
[0095]
其中f表示单个字符的伪语音特征序列,f表示单条文本的伪语音特征序列,c为拼接操作,n为单条文本的伪语音特征序列的帧数,{m1,m2,m3,
…
}为单条文本中每个字符对应的伪语音特征的帧数,n=m1+m2+m3+
…
,表示单条文本的伪语音特征序列的帧数为其对应的字符序列拼接帧的总和。
[0096]
附图5示例性地展示了伪特征数据的构建方法;
[0097]
附图6示例性地展示了获取单个字符候选特征序列的方法;
[0098]
将数据集d
r’和伪特征数据集dh合并,得到包含莫尔斯语音特征序列和其对应的字符序列的训练数据集d
t
。
[0099]
具体的,上述步骤s140中所述语音识别模型m包括:
[0100]
所述语音模型m基于transformer框架构建,如图7所示,包括一个编码器和一个解码器。所述编码器由n个相同的块组成,所述块包含第一子层多头注意力(multi-head self-attention)和第二子层前馈网络(feed forward network),所述第一子层和所述第二子层均包含一层残差网络连接归一化的下一级子层;所述解码器由n个相同的块组成,包含第一子层多头注意力(multi-head self-attention)、第二子层前馈网络(feed forward network)以及第三子层多头源关注,所述第一子层、所述第二子层和所述第三子层均包含一层残差网络连接归一化的下一级子层。其中,所述第三子层位于第一子层与第二子层之间,用于对编码器堆栈的输出表示执行多头源关注。
[0101]
具体的,所述对语音识别模型m进行训练,如图8所示,包括:
[0102]
(1)采用迁移学习的方式,设置语音识别模型m的初始隐层参数,得到模型m1。其中,所述初始隐层参数,通过使用标注数据充分的语音数据预训练模型而获得。
[0103]
可选的,所述初始隐层参数通过使用标注数据充分的中文语音数据200小时对语
音识别模型m进行预训练,得到训练好的基础模型m’并获取所述基础模型m’的隐层参数而获得;
[0104]
需要说明的是,由于莫尔斯标注数据匮乏并且专业性较强,难以构建达到充分训练规模的训练集而导致模型训练效果不佳,因此可以利用不同语言声学层面的共性进行迁移学习共享参数;由于深度神经网络编码器端参数是共享的,可以利用标注充分的语言训练声学模型的编码器隐层参数,以弥补低资源语言识别任务中声学模型训练的不足。
[0105]
(2)将词表v导入所述模型m1;其中,所述词表v通过统计标注后的数据集d
p
中每个标注字符的频度而获得;
[0106]
示例性的,所述词表v结构如下:
[0107][0108]
(3)使用训练数据集d
t
对所述模型m1进行训练,以标注字符序列为目标输出,训练得到莫尔斯自动识别模型m
p
。
[0109]
具体的,将所述训练数据集d
t
划分为训练集d
train
、验证集d
valid
、测试集d
test
,用d
train
训练模型,用d
valid
进行验证,所述训练集d
train
输入所述模型m1,输出最终结果概率;计算损失并更新模型参数,迭代n轮取最后的m轮模型参数的算术平均作为最终参数,得到训练好的莫尔斯自动识别模型m
p
。需要说明的是,针对不同批次的训练数据,均值模型在一定程度上能消除偶然性,提升识别的正确率。训练好的莫尔斯自动识别模型m
p
可将莫尔斯语音数据自动识别为莫尔斯报文字符,以便后续的人工读取。
[0110]
优选的,所述训练集d
train
、验证集d
valid
、测试集d
test
的比例为8:1:1。
[0111]
优选的,设置模型迭代轮数n为100,最后轮数m为20。
[0112]
进一步的,训练模型的损失函数为:
[0113][0114]
其中,为transformer的交叉熵损失,为字错误率;yi表示样本i的标注,pi表示样本i预测为正确的概率;字错误指标用于反映识别结果和标注字符序列的编辑距离占标注字符总数的比率,其中s表示需替换的字符数,d
表示需删除的字符数,i表示需插入的字符数,n表示标注字符的总数。需要说明的是,将字错误率计入模型训练中的损失,调节模型的权重,有助于模型取得更优效果。
[0115]
进一步的,测试模型采用字错误率(cer)指标,其公式为:
[0116][0117]
其中,s表示需替换的字符数,d表示需删除的字符数,i表示需插入的字符数,n表示标注字符的总数,accuracy表示正确率。需要说明的是,在模型迭代计算中将字错误率计入损失,调节模型的权重,有助于模型取得更优效果。
[0118]
示例性的,针对包含7549条,有效时长约8小时的训练集数据,筛选其中的500条作为测试数据集,测试结果如表1所示。
[0119]
表1使用字错误率指标评估模型性能的测试结果
[0120]
测试集nsdicercernoi500条2578467212.872.06
[0121]
其中,cer no i表示忽略需插入的字符数后的错误率,此指标在行业内具有一定的参考意义。
[0122]
可见,在训练集数据有效时长只有8小时的情况下,整体字错误率低于3%,相比现有技术中的其它方法,准确率高、稳定性好、适应性强,可用于实战。
[0123]
综上所述,本实施例的有益效果如下:
[0124]
与现有技术相比,本发明至少可实现如下有益效果:
[0125]
1、在训练基于transformer的语音识别模型的方法中,通过构建伪特征数据扩充训练数据,采用迁移学习的方法共享隐层参数,解决了因训练数据匮乏而导致模型训练不充分的问题;在模型迭代计算中将字错误率计入损失,调节模型的权重,使模型取得更好的训练效果;
[0126]
2、在训练数据集的构建的方法中,采用了模拟实际发送中人工发送信号的速度差异以速度变化扩展训练数据,使模型得到更充分的训练,提高了模型对互相差异的发送数据的识别准确率;
[0127]
3、在莫尔斯语音的特征提取的方法中,采用了针对莫尔斯语音特征频带范围的特征提取以降低特征维度,采用拼帧跳帧的方法以获得包含上下文语音特征的fbank特征,通过获得更好的莫尔斯语音特征表征,一定程度上解决了莫尔斯语音数据中的噪声干扰问题。
[0128]
实施例2
[0129]
本发明的一个实施例公开一种莫尔斯自动识别方法,其特征在于,包括如下步骤:
[0130]
获取待识别莫尔斯语音数据d;
[0131]
对待识别莫尔斯语音数据d进行预处理,得到预处理后的数据d’;
[0132]
对预处理后的数据d’进行莫尔斯特征提取,得到包含莫尔斯语音特征序列的莫尔斯特征数据df;
[0133]
将莫尔斯特征数据df输入基于莫尔斯自动识别模型的构建方法构建得到的莫尔斯自动识别模型,识别得到对应的莫尔斯字符文本数据。
[0134]
具体的,所述对待识别莫尔斯语音数据进行预处理,包括:
[0135]
对所述待识别莫尔斯语音数据d按静音切分,得到切分后的数据d’。
[0136]
将所述待识别莫尔斯语音数据d分离为语音段和非语音段;
[0137]
以非语音位置作为分割位置,将所述待识别莫尔斯语音数据d分割为为多个有效的语音片段,得到切分后的数据d’。
[0138]
可选的,使用vad引擎完成所述对待识别莫尔斯语音数据进行预处理。
[0139]
本实施例中的莫尔斯自动识别模型为采用实施例一中莫尔斯自动识别模型的构建方法构建得到,具体的模型中的模块组成和训练过程与上一实施例相同,请参照上一实施例中的具体内容,在此就不一一赘述了。
[0140]
本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
[0141]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1