语音识别方法、装置、计算机设备及存储介质与流程
本技术涉及音频处理,特别涉及一种语音识别方法、装置、计算机设备及存储介质。
背景技术:
1、随着语音处理技术的不断发展,语音识别的应用场景也越来越广泛,而其中的流式语音识别具有实时反馈识别结果的特点。
2、在相关技术中,流式语音识别的识别模块以分片的形式接收音频采集组件采集到的音频数据包,音频数据包中的数据包含多个音频帧,识别模块每次累积到一定数量的音频帧之后即可以进行识别,每次识别的结果可以即时进行显示。
3、在流式语音识别的场景中,首词的识别显示速度是流式语音识别的重要指标,对于如何提升首词的识别显示速度,目前还没有较好的解决方案。
技术实现思路
1、本技术实施例提供了一种语音识别方法、装置、计算机设备及存储介质,能够提高流式语音识别中的首词的识别显示速度。所述技术方案如下:
2、一方面,本技术实施例提供了一种语音识别方法,所述方法包括:
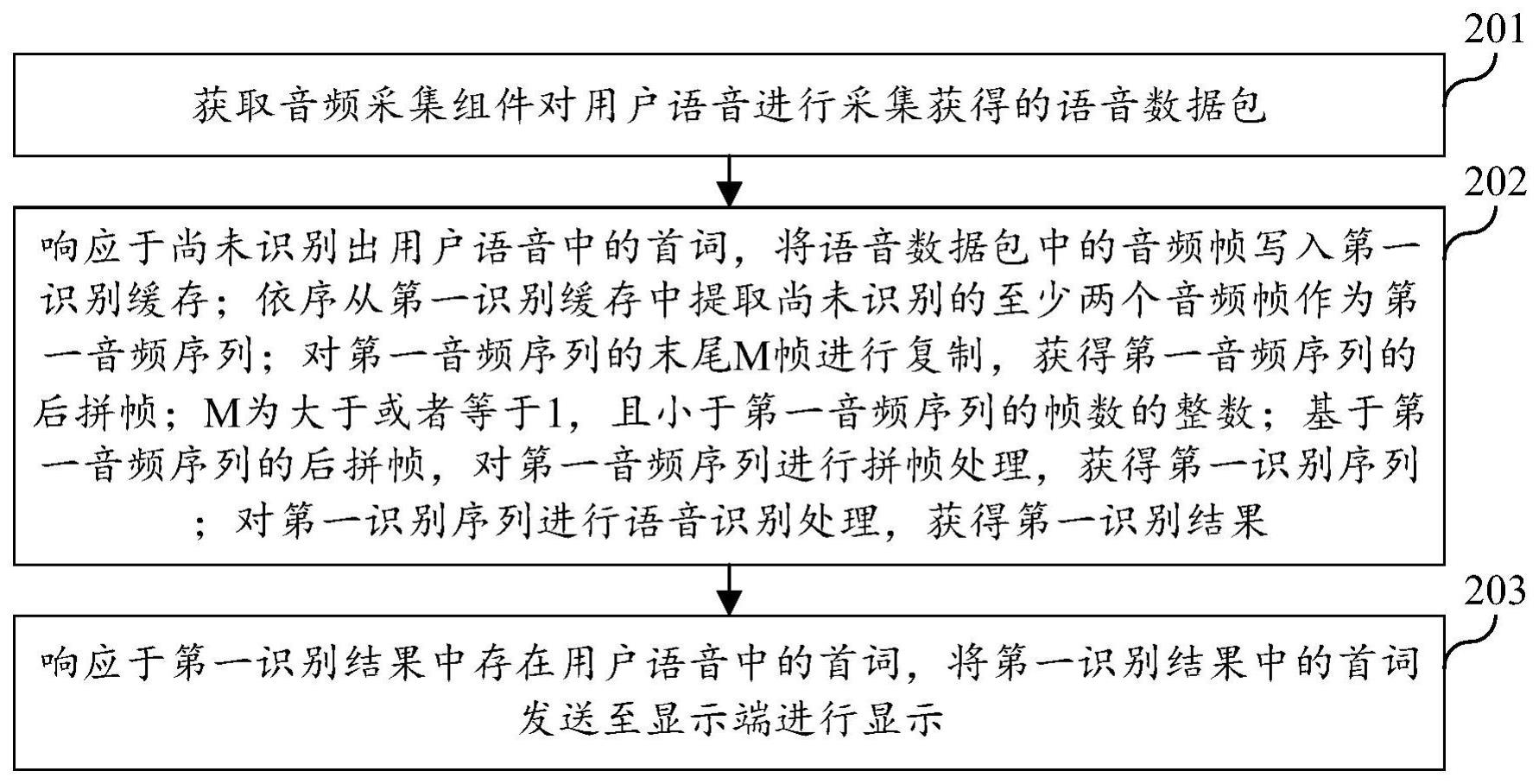
3、获取对用户语音进行采集获得的语音数据包;
4、响应于尚未识别出所述用户语音中的首词,将所述语音数据包中的音频帧写入第一识别缓存;依序从所述第一识别缓存中提取尚未识别的至少两个音频帧作为第一音频序列;对所述第一音频序列的末尾m帧进行复制,获得所述第一音频序列的后拼帧;m为大于或者等于1,且小于所述第一音频序列的帧数的整数;基于所述第一音频序列的后拼帧,对所述第一音频序列进行拼帧处理,获得第一识别序列;对所述第一识别序列进行语音识别处理,获得第一识别结果;
5、响应于所述第一识别结果中存在所述用户语音中的首词,将第一识别结果中的首词发送至显示端进行显示。
6、另一方面,本技术实施例提供了一种语音识别装置,所述装置包括:
7、数据包获取模块,用于获取对用户语音进行采集获得的语音数据包;
8、语音识别模块,用于响应于尚未识别出所述用户语音中的首词,将所述语音数据包中的音频帧写入第一识别缓存;依序从所述第一识别缓存中提取尚未识别的至少两个音频帧,作为第一音频序列;对所述第一音频序列的末尾m帧进行复制,获得所述第一音频序列的后拼帧;m为大于或者等于1,且小于所述第一音频序列的帧数的整数;基于所述第一音频序列的后拼帧,对所述第一音频序列进行拼帧处理,获得第一识别序列;对所述第一识别序列进行语音识别处理,获得第一识别结果;
9、首词发送模块,用于响应于所述第一识别结果中存在所述用户语音中的首词,将第一识别结果中的首词发送至显示端进行显示。
10、在一种可能的实现方式中,所述语音识别模块,用于在所述第一识别缓存中尚未识别的音频帧的数量达到n时,依序从所述第一识别缓存中提取尚未识别的n个音频帧,作为所述第一音频序列;n为大于或者等于2的整数。
11、在一种可能的实现方式中,所述装置还包括:
12、第一确定模块,用于语音识别模块在所述第一识别缓存中尚未识别的音频帧的数量达到n时,依序从所述第一识别缓存中提取尚未识别的n个音频帧,作为所述第一音频序列之前,基于所述第一识别缓存中尚未识别的音频帧的数量确定n的数值。
13、在一种可能的实现方式中,所述第一确定模块,用于,
14、响应于所述第一识别缓存中尚未识别的音频帧的数量大于或者等于nmax,确定n的数值为nmax;
15、响应于所述第一识别缓存中尚未识别的音频帧的数量小于或者等于nmin,确定n的数值为nmin;2≤nmin<nmax,且nmax、nmin为偶数;
16、响应于第一识别缓存中尚未识别的音频帧的数量处于nmax和nmin之间,确定n的数值为小于或者等于所述第一识别缓存中尚未识别的音频帧的数量的偶数的最大值。
17、在一种可能的实现方式中,所述语音识别模块,用于对所述第一音频序列的前l帧进行复制,获得所述第一音频序列的前拼帧;l为大于或者等于1,且小于所述第一音频序列的帧数的整数;
18、将所述第一音频序列的前拼帧、所述第一音频序列以及所述第一音频序列的后拼帧依次拼接,获得所述第一识别序列。
19、在一种可能的实现方式中,所述语音识别模块,用于,
20、响应于所述第一音频序列中包含对所述用户语音进行采集获得的首个音频帧,对所述第一音频序列的前l帧进行复制,获得所述第一音频序列的前拼帧;或者,响应于所述第一音频序列中不包含对所述用户语音进行采集获得的首个音频帧,将位于所述第一音频序列之前的l个音频帧获取为所述第一音频序列的前拼帧;l为大于或者等于1,且小于所述第一音频序列的帧数的整数;
21、将所述第一音频序列的前拼帧、所述第一音频序列以及所述第一音频序列的后拼帧依次拼接,获得所述第一识别序列。
22、在一种可能的实现方式中,所述语音识别模块,还用于,
23、将所述语音数据包中的音频帧写入第二识别缓存;
24、依序从所述第二识别缓存中提取尚未识别的至少两个音频帧,作为第二音频序列;
25、对所述第二识别缓存中,位于所述第二音频序列之后的p帧音频帧进行复制,获得所述第二音频序列的后拼帧;p为大于或者等于1,且小于所述第二音频序列的帧数的整数;
26、基于所述第二音频序列的后拼帧,对所述第二音频序列进行拼帧处理,获得第二识别序列;
27、对所述第二识别序列进行语音识别处理,获得第二识别结果。
28、在一种可能的实现方式中,所述语音识别模块,用于,
29、响应于所述第二音频序列中包含对所述用户语音进行采集获得的首个音频帧,对所述第二音频序列的前l帧进行复制,获得所述第二音频序列的前拼帧;或者,响应于所述第二音频序列中不包含对所述用户语音进行采集获得的首个音频帧,将位于所述第二音频序列之前的q个音频帧获取为所述第二音频序列的前拼帧;q为大于或者等于1,且小于所述第二音频序列的帧数的整数;
30、将所述第二音频序列的前拼帧、所述第二音频序列以及所述第二音频序列的后拼帧依次拼接,获得所述第二识别序列。
31、在一种可能的实现方式中,所述语音识别模块,用于在所述第二识别缓存中尚未识别的音频帧的数量达到s时,依序从所述第二识别缓存中提取尚未识别的s个音频帧,作为所述第二音频序列;s为大于或者等于2的整数。
32、在一种可能的实现方式中,所述装置还包括:
33、第二确定模块,用于在语音识别模块在所述第二识别缓存中尚未识别的音频帧的数量达到s时,依序从所述第二识别缓存中提取尚未识别的s个音频帧,作为所述第二音频序列之前,基于所述第二识别缓存中尚未识别的音频帧的数量确定s的数值。
34、在一种可能的实现方式中,所述装置还包括:
35、比对模块,用于响应于所述第二识别结果中存在所述用户语音中的首词,将所述第二识别结果中的首词,与所述第一识别结果中的首词进行比对;
36、更新模块,用于响应于所述第二识别结果中的首词与所述第一识别结果中的首词不同,将所述显示端显示的首词更新为所述第二识别结果中的首词。
37、另一方面,本技术实施例提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条计算机程序,所述至少一条计算机程序由所述处理器加载并执行以实现如上述方面所述的语音识别方法。
38、另一方面,本技术实施例提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一条计算机程序,所述至少一条计算机程序由处理器加载并执行以实现如上述方面所述的语音识别方法。
39、另一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机程序,该计算机程序存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机程序,处理器执行该计算机程序,使得该计算机设备执行上述方面的各种可选实现方式中提供的语音识别方法。
40、本技术实施例提供的技术方案的有益效果至少包括:
41、在进行流式语音识别的过程中,在尚未识别出用户语音中的首词的情况下,将语音数据包中的音频帧写入第一识别缓存后,依序从第一识别缓存中提取尚未识别的至少两个音频帧作为第一音频序列;将第一音频序列的末尾m帧作为第一音频序列的后拼帧进行拼帧处理,然后对拼帧获得的第一识别序列进行语音识别处理;也就是说,上述方案中,在识别前的拼帧过程中,直接使用待识别的音频帧序列中的最后几帧进行后拼处理,不需要等待后续音频帧到达即可以进行识别,能够提高首词的识别和显示速度,从而提高流式语音识别的性能。
- 还没有人留言评论。精彩留言会获得点赞!