基于跨领域自适应的深度伪造语音检测方法
本发明涉及语音检测,特别涉及一种基于跨领域自适应的深度伪造语音检测方法。
背景技术:
1、深度伪造指的是包含视频伪造、音频伪造和文本伪造等多模态的欺骗技术。随着深度学习技术的迅速发展,深度伪造的“低门槛、高效率、高质量”的特性使之在日常生活中被广泛使用,如影视剧后期换脸换声、智能客服的语音回复等。然而,深度伪造技术的落地和应用也伴生着严重的技术滥用问题。其隐患集中在针对目标人的视频和音频合成,从而盗用他人身份以假乱真。伪造音视频可被滥用至抹黑公众人物、金融诈骗甚至干扰军事指挥等一系列恶意行为中。
2、由于深度伪造技术潜在的威胁,国内外对其都非常重视和警惕。在语音深伪检测领域,目前的检测手段主要是通过构建深度神经网络以寻找伪造算法遗留在音频中的伪造痕迹来进行鉴别,这些伪造检测模型通常需要大量的真伪数据以进行监督式训练。
3、在语音检测领域,相关技术提供了大量具有一定泛化性的语音真伪检测模型来应对未知语种音频的伪造攻击。然而,这些语音真伪检测模型在训练阶段所采用训练数据语种为单一的语种,比如英语语种等,导致其检测效力仅仅局限于特定的源语种领域,而忽视了语音检测领域特有的跨语种检测问题。当语音真伪检测模型接收到非源语种领域的目标语种伪造音频时,仍采用针对源语种音频的真伪识别方法进行识别,容易导致对目标伪造音频的判断误差较大。
4、现存深度伪造检测模型的训练所依赖的检测专用数据集均为通用性较大的源语种数据集,而在非源语种领域,伪造语音数据样本较为稀缺,并且还存在数据质量差,伪造算法种类少,伪造算法训练数据标注难等诸多问题,导致有限的音频数据资源不足以支撑深度伪造检测模型在非源语种领域的训练。
技术实现思路
1、针对现有技术存在的上述问题,本发明提供了一种基于跨领域自适应的深度伪造语音检测方法,基于跨领域自适应技术监督检测模型学习与语种无关的伪造痕迹,利用丰富的源语种伪造音频数据和有限的目标语种音频数据构建深度伪造语音检测模型,可提供针对非源语种音频数据真伪识别的深度伪造语音检测模型构建方案,提高深度伪造语音检测模型对不同语种音频真伪的识别精度。
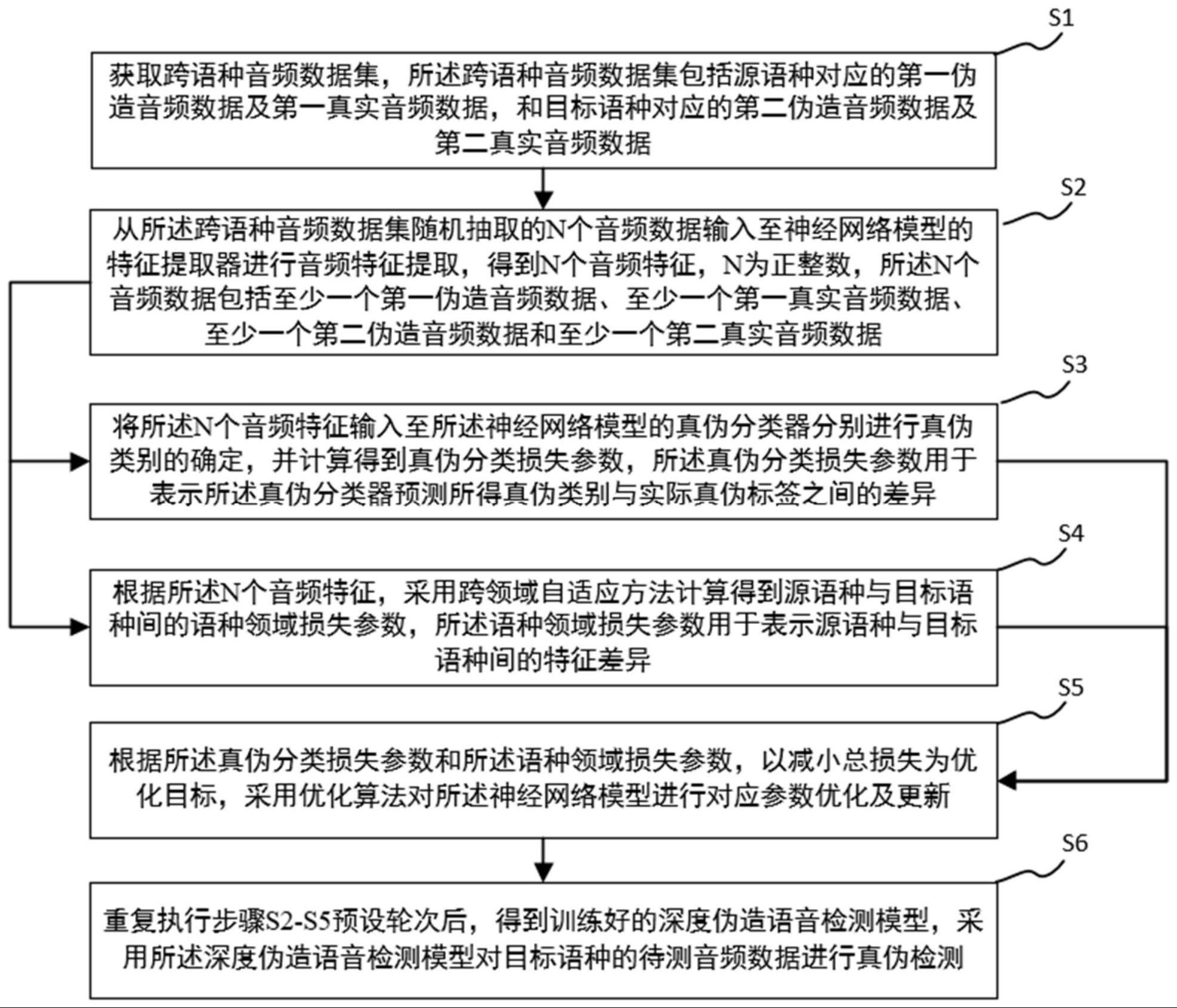
2、根据本发明实施例的一个方面,提供一种基于跨领域自适应的深度伪造语音检测方法,所述方法包括:
3、s1:获取跨语种音频数据集,所述跨语种音频数据集包括源语种对应的第一伪造音频数据及第一真实音频数据,和目标语种对应的第二伪造音频数据及第二真实音频数据;
4、s2:从所述跨语种音频数据集随机抽取的n个音频数据输入至神经网络模型的特征提取器进行音频特征提取,得到n个音频特征,n为正整数,所述n个音频数据包括至少一个第一伪造音频数据、至少一个第一真实音频数据、至少一个第二伪造音频数据和至少一个第二真实音频数据;
5、s3:将所述n个音频特征输入至所述神经网络模型的真伪分类器分别进行真伪类别的确定,并计算得到真伪分类损失参数,所述真伪分类损失参数用于表示所述真伪分类器预测所得真伪类别与实际真伪标签之间的差异;
6、s4:根据所述n个音频特征,采用跨领域自适应方法计算得到源语种与目标语种间的语种领域损失参数,所述语种领域损失参数用于表示源语种与目标语种间的特征差异;
7、s5:根据所述真伪分类损失参数和所述语种领域损失参数,以减小总损失为优化目标,采用优化算法对所述神经网络模型进行对应参数优化及更新;
8、s6:重复执行步骤s2-s5预设轮次后,得到训练好的深度伪造语音检测模型,采用所述深度伪造语音检测模型对目标语种的待测音频数据进行真伪检测。
9、在一种可能的实现方式中,所述跨语种音频数据集中,所述源语种对应的第一伪造音频数据数量及第一真实音频数据数量,远大于所述目标语种对应的第二伪造音频数据数量及第二真实音频数据数量。
10、在一种可能的实现方式中,所述n个音频数据中,源语种对应的音频数据数量与目标语种对应的音频数据数量相等,且各个语种对应的音频数据中,伪造音频数据数量与真实音频数据数量的比值固定。
11、在一种可能的实现方式中,所述跨语种音频数据集中生成所述第一伪造音频数据所对应的伪造算法,包括有生成所述第二伪造音频数据所对应的伪造算法。
12、在一种可能的实现方式中,步骤s2中所述n个音频数据输入至所述神经网络模型的特征提取器进行音频特征提取前,还包括:
13、对于每个音频数据,将所述音频数据以16k采样率、单声道格式进行转换,并被裁剪或拼接为预设时长,形成音频采样点构成的一维张量。
14、在一种可能的实现方式中,步骤s4包括:
15、将所述n个音频特征输入至所述神经网络模型的语种分类器分别进行语种类别的确定,并计算得到语种分类损失参数lossd,所述语种分类损失参数lossd用于表示语种类别与实际语种标签之间的差异;或,
16、将所述n个音频特征输入至所述神经网络模型的差异测量器进行源语种与目标语种的语种特征间差异测量,并计算得到语种间特征差异损失参数lossmmd,所述语种间特征差异损失参数lossmmd用于表示源语种语音特征分布与目标语种语音特征分布间的不相似程度。
17、在一种可能的实现方式中,所述语种分类器基于对抗性跨领域自适应方法构建,所述语种分类器包括一个梯度反转层,四个卷积块,一个lstm层和一个全连接层。
18、在一种可能的实现方式中,所述差异测量器基于计算最大均值差异的跨领域自适应方法构建,所述差异测量器采用mk-mmd或jmmd测量源语种与目标语种的语种特征间差异。
19、在一种可能的实现方式中,所述优化算法为adam,此时,步骤s5包括:
20、将所述语种分类损失参数lossd与所述真伪分类损失参数相加得到总损失值;或,
21、将所述语种间特征差异损失参数lossmmd与权重因子α相乘后,与所述真伪分类损失参数相加得到总损失值;
22、其中,所述权重因子α由下式计算得到:
23、
24、p是随训练轮次增加而线性递增的变量,α在训练过程中由0逐渐增加至1;
25、以减小所述总损失值为优化目标,使用优化算法adam对所述神经网络模型进行对应参数优化及更新。
26、根据本发明实施例的另一个方面,提供一种基于跨领域自适应的深度伪造语音检测装置,所述装置包括:
27、获取模块,用于获取跨语种音频数据集,所述跨语种音频数据集包括源语种对应的第一伪造音频数据及第一真实音频数据,和目标语种对应的第二伪造音频数据及第二真实音频数据;
28、特征提取模块,用于从所述跨语种音频数据集随机抽取的n个音频数据输入至神经网络模型的特征提取器进行音频特征提取,得到n个音频特征,n为正整数,所述n个音频数据包括至少一个第一伪造音频数据、至少一个第一真实音频数据、至少一个第二伪造音频数据和至少一个第二真实音频数据;
29、第一计算模块,用于将所述n个音频特征输入至所述神经网络模型的真伪分类器分别进行真伪类别的确定,并计算得到真伪分类损失参数,所述真伪分类损失参数用于表示所述真伪分类器预测所得真伪类别与实际真伪标签之间的差异;
30、第二计算模块,用于根据所述n个音频特征,采用跨领域自适应方法计算得到源语种与目标语种间的语种领域损失参数,所述语种领域损失参数用于表示源语种与目标语种间的特征差异;
31、优化模块,用于根据所述真伪分类损失参数和所述语种领域损失参数,以减小总损失为优化目标,采用优化算法对所述神经网络模型进行对应参数优化及更新;
32、检测模块,用于重复执行特征提取模块-优化模块中的步骤预设轮次后,得到训练好的深度伪造语音检测模型,采用所述深度伪造语音检测模型对目标语种的待测音频数据进行真伪检测。
33、与现有技术相比,本发明提供的一种基于跨领域自适应的深度伪造语音检测方法具有以下优点:
34、1、利用已有的大规模源语种音频数据提升深度伪造语音检测模型在其他目标语种领域的检测适用性和精确性,可提高非源语种音频检测模型的构建效率,降低构建成本;
35、2、基于包含大量源语种音频数据和少量目标语种音频数据的数据集,通过跨领域自适应方法训练检测模型学习与语种无关的伪造痕迹,实现了深度伪造检测的语种无关性;
36、3、基于由不同说话人录制的真实音频,和不同伪造算法生成的伪造音频构成的大批量源语种语音数据辅助跨语种检测模型的训练,提升了检测模型在未知音频类别和未知伪造算法上的泛化性。
37、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!