一种帕金森病受试者包络化语音样本段分级融合方法
本发明涉及帕金森病语音识别,尤其涉及一种帕金森病受试者包络化语音样本段分级融合方法。
背景技术:
1、语音识别是帕金森病(pd)诊断的一种有效方式,已成为了近年来的研究热点和难点。在对受试者进行语音采集时,需要采集大量的语音片段。然而,大量的语音片段会增加分类模型的复杂度;少数高质量的语音片段将有助于获得更高的诊断精度。此外,临床医生往往对寻找能反映整个受试者病理情况的诊断性语音标记物感兴趣。但由于每个语音样本片段的最佳相关特征各不相同,所以很难为受试者找到统一的诊断性语音标记物。
技术实现思路
1、本发明提供一种帕金森病受试者包络化语音样本段分级融合方法,解决的技术问题在于:如何将一个受试者的大量语音样本片段重构为少量片段,甚至重构为一个受试者只包含一个语音样本片段,从而有助于提取相关语音特征,进而找到能表征整个受试者病理情况的诊断标记物。
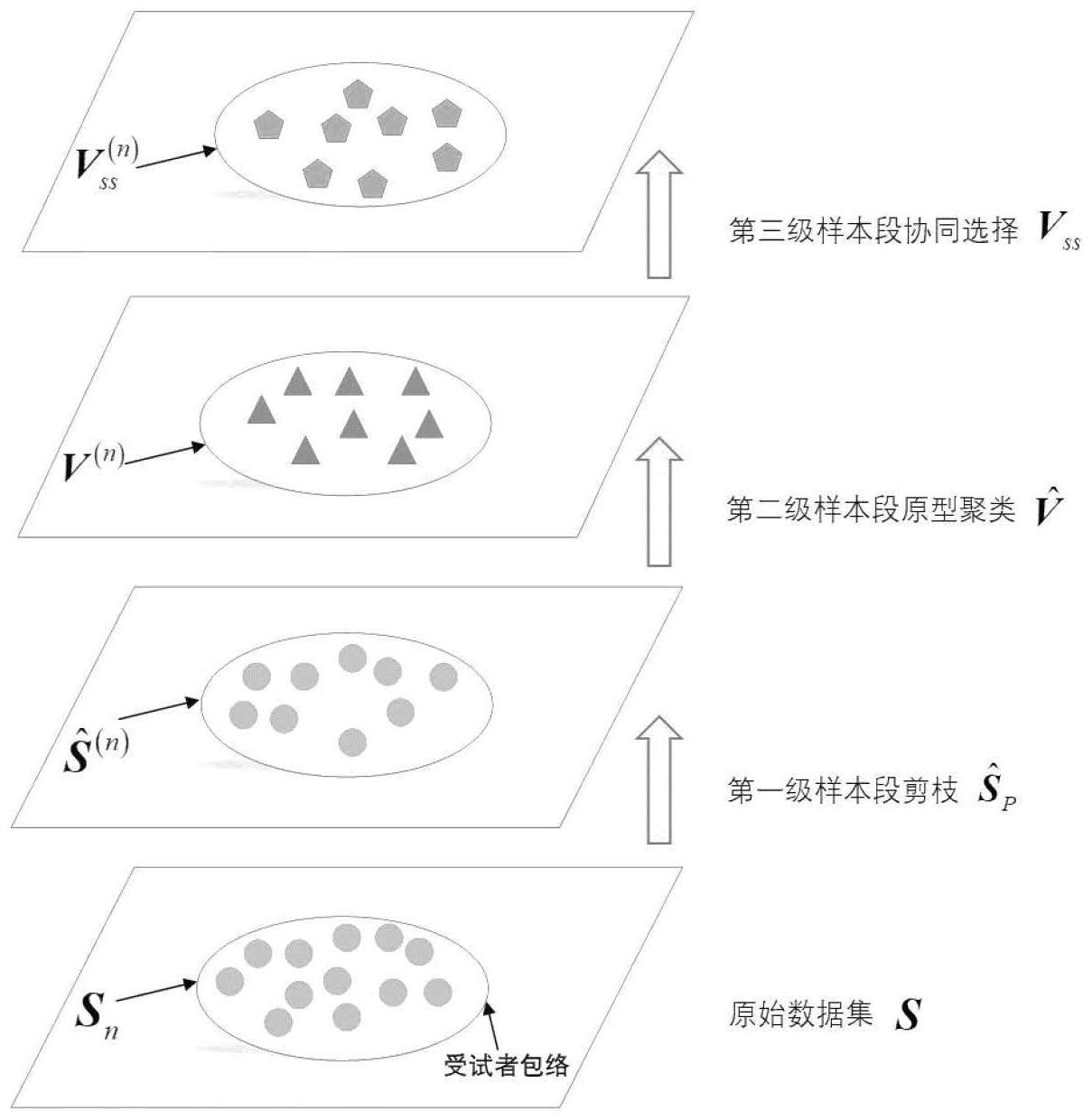
2、为解决以上技术问题,本发明提供一种帕金森病受试者包络化语音样本段分级融合方法,包括步骤:
3、s1、将目标数据集的n个受试者中每个受试者的所有语音样本段进行包络化,得到由n个原始受试者包络sn,n=1,2,...,n构成的原始数据集s;
4、s2、采用样本段剪枝模块对n个所述原始受试者包络sn进行第一级样本段剪枝,保留能够高质量表征受试者病理的样本片段,得到由对应的n个第一级受试者包络构成的数据集
5、s3、采用样本段原型聚类模块对n个所述第一级受试者包络进行第二级样本段原型聚类,得到由对应的n个第二级受试者包络v(n)构成的数据集
6、s4、采用样本段协同选择模块对n个所述第二级受试者包络v(n)进行第三级样本段协同选择,得到由对应的n个第三级受试者包络构成的数据集vss。
7、进一步地,在所述步骤s1中,每个受试者有m个d维的语料样本,n个所述原始受试者包络构成的原始数据集s表示为:
8、
9、表示实数集,sn表示第n个受试者包络,sn具体为:
10、
11、进一步地,在所述步骤s2中,所述样本段剪枝模块执行以下步骤:
12、s21、对n个所述原始受试者包络均进行矩阵转置,并将其按列合并得到数据集snt对应为sn的转置;
13、s22、从数据集中依次选取每一个特征向量sj=[s1j s2j ... smj],j∈1,2,...n×d,并在该数据集中通过计算欧氏距离来遍历寻找到该特征向量sj在各类中的k个最近邻:首先寻找来自和sj相同类别的k个近邻,并将该k个近邻的平均值记作nh(sj),然后寻找来自和sj不同类别的k个近邻,并将该k个近邻的平均值记作nm(sj);
14、s23、计算该特征向量sj到nh(sj)与nm(sj)的欧式距离,并通过以下公式迭代更新权重向量的第i∈(1,2,...,m)维:
15、wi=wi-diff(sij,nh(sij))/td+diff(sij,nm(sij))/td,
16、函数diff(sij,nh(sij))表示计算sj与nh(sj)第i维的距离,diff(sij,nm(sij))表示计算sj与nm(sij)第i维的距离,wi表示sn中第i个样本的权重,td表示迭代次数;
17、s24、对得到的m维样本权重向量做升序排列,按照所设置的剪枝数cutoff依次减去较低权重值所对应的样本段,将剪枝后的数据集以受试者包络为单位进行转置得到样本变换后的数据集n'=m-cutoff即n个第一级受试者包络。
18、进一步地,在所述步骤s23中,diff(sij,nh(sij))表示为:
19、diff(sij,nh(sij))=|sij-nh(sij)|/(max(si·)-min(si·)),
20、其中,·是绝对值符号,max(si·)和min(si·)分别表示中第i维的最大和最小值;
21、同理,diff(sij,nm(sij))表示为:
22、diff(sij,nm(sij))=|sij-nm(sij)|/(max(si·)-min(si·))。
23、进一步地,在所述步骤s3中,v(n)也称作原型样本集,所述样本段原型聚类模块执行以下步骤:
24、s31、依次基于n个第一级受试者包络构造目标函数:
25、
26、约束条件:
27、
28、其中,输入数据集有n'个样本;将通过样本段原型聚类得到的原型样本集记为即第二级受试者包络;为隶属度矩阵;表示欧氏距离下样本到原型样本之间的距离;uik为隶属度值,表示样本对聚类中心的隶属程度;c为聚类数目;λ为拉格朗日乘子;表示一个所有元素都为1的行向量;m>1为模糊系数;κ(·)是核函数;表示由原型样本集v(n)和隶属度矩阵u组成的聚类损失,表示原型样本集v(n)与数据集之间的样本分布差异;
29、s32、对目标函数进行求解,依次输出n个原型样本集v(n),n=1,2,...,n,即对应的n个第二级受试者包络。
30、进一步地,所述步骤s32具体包括步骤:
31、s321、固定原型样本集v(n)不变,求解隶属度矩阵u;具体包括步骤:
32、1)固定原型样本集v(n)不变,并去除隶属度矩阵u的无关项,将所述目标函数转化为第一子目标函数:
33、
34、2)用梯度下降法求解所述第一子目标函数的最小解,得到隶属度矩阵u的迭代公式为:
35、
36、s322、固定隶属度矩阵u不变,求解原型样本集v(n);具体包括步骤:
37、1)固定隶属度矩阵u不变,并去除原型样本集v(n)的无关项,将所述目标函数转化为第二子目标函数:
38、
39、2)基于核函数κ(xk,vi)=(xk)tvi用梯度下降法求得所述第二子目标函数的最小解,得到原型样本集v(n)与数据集之间的转换关系如下所示:
40、
41、其中,中间变量中间变量
42、
43、s323、迭代计算目标函数值,当达到最大迭代次数时,输出目标函数最小时对应的原型样本集v(n)。
44、进一步地,所述步骤s323具体包括步骤:
45、1)设定拉格朗日乘子λ的范围,并基于约束条件和u>0初始化隶属度矩阵u;
46、2)根据基于数据集计算得到原型样本集v(n);
47、3)根据更新隶属度矩阵u;
48、4)根据目标函数的表达式,计算目标函数在当前迭代次数ω下的函数值
49、5)迭代次数加1,当达到迭代最大次数w时停止计算,此时目标函数得到最小值
50、6)输出对应的原型样本集v(n)。
51、进一步地,在所述步骤s4中,所述样本段协同选择模块执行以下步骤:
52、s41、基于n个第二级受试者包络将包络内样本片段拼接在一起从而获得n个新的高维样本
53、s42、这个新样本的特征由这个受试者的所有样本段的特征组成,由这些新的高维样本组成的数据集被表示为其中表示数据集中第l个样本;
54、s43、从该数据集中选择一个样本迭代找到该样本在该数据集中各个类别的k近邻并计算其均值,将其分别记为和为与相同类别的k个近邻的平均值,
55、为与不同类别的k个近邻的平均值,并更新高维特征权重;
56、s44、将权重向量按升序排序,依次减去权重最低的样本特征,得到由n个第三级受试者包络构成的数据集
57、进一步地,所述目标数据集采用sakar数据集,所述sakar数据集共包含40名受试者,包括20名帕金森病患者和20名健康受试者,40名受试者分别提供了26个语音样本片段,每个语音样本片段包含26个发音任务,具体为连续元音、数字、单词和短语的发音,从每个语音样本片段中提取26个特征作为特征向量。
58、进一步地,所述目标数据集采用maxlittle数据集,所述maxlittle数据集共包含31名受试者,其中23人患有pd,8人健康,每个受试者包含6或7个语音样本片段。每个语音样本片段包含22个特征,并由这些特征形成一个特征向量
59、本发明提供的一种帕金森病受试者包络化语音样本段分级融合方法,基于样本段剪枝模块(sp)、样本段原型聚类模块(fc&idmd)、样本段协同选择模块(ss/fsm),对帕金森病受试者包络化语音样本段进行分级快速融合,获得少量的高质量原型样本。这不仅有利于提取反映受试者整体病理情况的语音特征(诊断标志物),还能显著提高分类精度和泛化性能,能更好地满足临床应用的需求。
- 还没有人留言评论。精彩留言会获得点赞!