一种语音合成方法、装置、设备和存储介质与流程
1.本发明涉及音频处理技术领域,尤其涉及一种语音合成方法、装置、设备和存储介质。
背景技术:
2.在语音合成处理中,一般使用前端处理器、声学模型以及声码器三个模块。其中,声码器是将声学模型输出的声学特征转换成最后合成的音频采样点。因此,声码器的优劣对于声音合成的效果起着重要作用。当前流行的声码器主要包括类似于wavernn的自回归模型和类似于hifi-gan的基于gan模型的非自回归模型,基于gan模型的非自回归模型因其优越的解码速度以及效果成为了主流应用。
3.hifi-gan声码器在合成集内音色(训练样本集对应的音色)的语音时,由于hifi-gan声码器是基于训练样本集进行训练,而且针对训练样本,声学模型输出的声学特征已经包含了说话人的所有特征,所以合成效果会比较好,能够较好的还原说话人的音色。但是,在合成集外音色的语音时,由于hifi-gan声码器是使用声学特征的全部内容进行语音合成,并不会关注于特定特征,进而会遇到鲁棒性不足的问题。对于这种问题,需要使用新的集外音色重新训练hifi-gan声码器,对hifi-gan声码器进行微调,这样,每遇到一个新的音色,就要重新训练hifi-gan声码器,过程较为复杂。
技术实现要素:
4.本发明的主要目的在于提出一种语音合成方法、装置、设备和存储介质,旨在解决合成集外音色,需要重新训练声码器的问题。
5.为实现上述技术问题,本发明是通过以下技术方案来实现的:
6.本发明实施例提供了一种语音合成方法,包括:接收声学模型输出的声学特征;在所述声学特征中提取全局特征,并根据所述全局特征确定音色特征;将所述声学特征和所述音色特征输入声码器,使所述声码器根据所述声学特征和所述音色特征合成语音信号。
7.其中,所述在所述声学特征中提取全局特征,包括:计算所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差;根据所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差,构建具有第一预设维度的向量特征,将具有第一预设维度的向量特征作为所述全局特征。
8.其中,所述根据所述全局特征确定音色特征,包括:直接将所述全局特征确定为音色特征;或者,利用预设的转换模块将所述全局向量转换为音色特征;其中,所述转换模块用于纠偏所述全局向量并且将纠偏后的所述全局向量转换为第二预设维度的向量特征,将具有第二预设维度的向量特征作为音色特征。
9.其中,在所述利用预设的转换模块将所述全局向量转换为音色特征之前,还包括:将所述转换模块和所述声码器一并进行训练,直到所述声码器收敛为止。
10.其中,所述声码器包括至少一个上采样模块;所述使所述声码器根据所述声学特
征和所述音色特征合成语音信号,包括:将所述音色特征作为条件,注入所述声码器中的每个所述上采样模块,使每个所述上采样模块根据输入特征和所述音色特征执行上采样处理;其中,所述输入特征为输入所述声码器的声学特征或者当前上采样模块的前一个上采样模块的输出结果。
11.本发明实施例还提供了一种语音合成装置,包括:接收模块,用于接收声学模型输出的声学特征;提取和确定模块,用于在所述声学特征中提取全局特征,并根据所述全局特征确定音色特征;合成模块,用于将所述声学特征和所述音色特征输入声码器,使所述声码器根据所述声学特征和所述音色特征合成语音信号。
12.其中,所述提取和确定模块,用于:计算所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差;根据所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差,构建具有第一预设维度的向量特征,将具有第一预设维度的向量特征作为所述全局特征;直接将所述全局特征确定为音色特征;或者,利用预设的转换模块将所述全局向量转换为音色特征;其中,所述转换模块用于纠偏所述全局向量并且将纠偏后的所述全局向量转换为第二预设维度的向量特征,将具有第二预设维度的向量特征作为音色特征。
13.其中,所述声码器包括至少一个上采样模块;所述合成模块,用于:将所述音色特征作为条件,注入所述声码器中的每个所述上采样模块,使每个所述上采样模块根据输入特征和所述音色特征执行上采样处理;其中,所述输入特征为输入所述声码器的声学特征或者当前上采样模块的前一个上采样模块的输出结果。
14.本发明实施例提供了一种语音合成设备,所述语音合成设备包括处理器、存储器;所述处理器用于执行所述存储器中存储的语音合成程序,以实现上述任一项所述的语音合成方法。
15.本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现上述任一项所述的语音合成方法。
16.本发明有益效果如下:
17.本发明在声学特征中提取全局特征,进而确定音色特征,将音色特征作为条件注入声码器,使得声码器在根据声学特征进行语音信号合成时关注并参考音色特征,这样在语音合成时,额外强调音色特征,声码器就可以很好地合成具有该音色的语音信号。本发明保证了声码器对音色的学习能力,而且效果较佳,无需每遇到新的音色都要重新训练声码器,增强了声码器对集外音色的鲁棒性,提高了语音合成效率。
附图说明
18.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
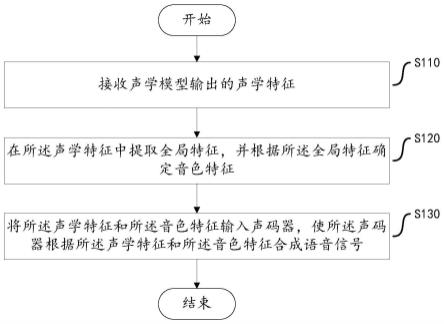
19.图1为根据本发明一实施例的语音合成方法的流程图;
20.图2为根据本发明一实施例的语音合成的示意图;
21.图3为根据本发明一实施例的语音合成装置的结构图;
22.图4为根据本发明一实施例的语音合成设备的结构图。
具体实施方式
23.为使本发明的目的、技术方案和优点更加清楚,以下结合附图及具体实施例,对本发明作进一步地详细说明。
24.根据本发明的实施例,提供了一种语音合成方法。如图1所示,为根据本发明一实施例的语音合成方法的流程图。
25.步骤s110,接收声学模型输出的声学特征。
26.在语音合成处理中,前端处理器在文本中提取语言学特征;声学模型根据语言学特征生成声学特征;声码器根据声学特征合成语音信号。本发明实施例在声学模型和声码器之间执行。
27.声学特征用于反映声音的音色、内容、情绪等。声学特征可以是梅尔谱。
28.步骤s120,在所述声学特征中提取全局特征,并根据所述全局特征确定音色特征。
29.全局特征用于反映声学特征中持续不变的特征。
30.音色特征用于反映声音的音色。
31.音色是声音特有的,相同发声体的音色相同,不同发声体的音色不同,并且同一发声体的音色具有稳定不变的特性,例如:同一个人的语音信号,不管持续多长时间,音色都不会发生改变。因此音色特征是一种具有全局性的特征。
32.具体而言,音色特征是一种全局性的特征,来自不同音色的声学特征一般存在不同的特征分布,同时声学特征的均值和方差可以较好的体现该特征分布的特性,也就是音色特征。
33.在本实施例中,计算所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差;根据所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差,构建具有第一预设维度的向量特征,将具有第一预设维度的向量特征作为所述全局特征。直接将所述全局特征确定为音色特征;或者,为了避免全局特征具有误差,利用预设的转换模块将所述全局向量转换为音色特征。
34.进一步地,第一预设维度的维度数大于第二预设维度的维度数。第二预设维度的维度数小于声学特征的维度数。
35.进一步地,转换模块用于纠偏所述全局向量并且将纠偏后的所述全局向量转换为第二预设维度的向量特征,将具有第二预设维度的向量特征作为音色特征。其中,转换模块可以包括特征纠偏单元和维度转换单元。
36.特征纠偏单元用于纠正全局向量中的误差。特征纠偏单元可以是cnn(convolutional neural networks,卷积神经网络)。
37.维度转换单元用于将具有第一预设维度的全局特征转换为具有第二预设维度的全局特征。维度转换单元可以是linear(线性)层。
38.转换模块具有学习能力,将所述转换模块和所述声码器一并进行训练,直到所述声码器收敛为止。在训练声码器的过程,也在训练转换模块,转换模块的学习目标即是为全局特征纠偏。
39.例如:第一预设维度为6维,第二预设维度为10维。接收到一段vocoder的声学特征,对该声学特征的全部,该声学特征中随机挑选的1/2部分,该声学特征中随机挑选的1/4部分,分别计算均值和方差,每个均值和每个方差作为一个特征值,形成一个6维的向量特
征,将该6维的向量特征作为全局特征。全局特征在经过cnn网络和linear层之后,输出一个10维的特征向量,将之作为音色特征。
40.步骤s130,将所述声学特征和所述音色特征输入声码器,使所述声码器根据所述声学特征和所述音色特征合成语音信号。
41.声码器包括至少一个上采样模块;将所述音色特征作为条件(condition),注入所述声码器中的每个所述上采样模块,使每个所述上采样模块根据输入特征和所述音色特征执行上采样处理;其中,所述输入特征为输入所述声码器的声学特征或者当前上采样模块的前一个上采样模块的输出结果。
42.例如:如图2所示,为根据本发明一实施例的语音合成的示意图。声学模型输出声学特征,声学特征被输入全局特征提取模块和声码器。声学特征进入全局特征提取模块之后,被求取均值和方差,进而构建全局特征,全局特征经过转换模块的纠偏和维度转换之后,输出音色特征。在图2中,声码器中包括4个上采样模块,向每个上采样模型输入音色特征,每个上采样模块将接收到的声学特征或者中间特征结合音色特征,进行上采样处理,将输出结果向下一个上采样模块输出,直到输出语音信号。
43.在本实施例中,在声学特征中提取全局特征,进而可以确定音色特征,将音色特征作为条件注入声码器,使得声码器在根据声学特征进行语音信号合成时关注并参考音色特征,这样在语音合成时,额外强调音色特征,声码器就可以很好地合成具有该音色的语音信号,保证了声码器对音色的学习能力,而且效果较佳,无需每遇到新的音色都要重新训练声码器,增强了声码器对集外音色的鲁棒性,提高了语音合成效率。
44.在本实施例中,提高了一种较为简单的音色特征提取方式,在声学特征中提取全局特征,将全局特征直接作为音色特征或者使用转换模块将全局特征转换为音色特征即可。转换模块在训练声码器时作为声码器的预处理层一同训练即可,无需单独设置大量的训练样本,单独预训练一个用于输出音色特征的speaker encoder模型,因此,本实施例的使用友好度较高。
45.本发明实施例还提供了一种语音合成装置。如图3所示,为根据本发明一实施例的语音合成装置的结构图。
46.该语音合成装置,包括:
47.接收模块310,用于接收声学模型输出的声学特征。
48.提取和确定模块320,用于在所述声学特征中提取全局特征,并根据所述全局特征确定音色特征。
49.合成模块330,用于将所述声学特征和所述音色特征输入声码器,使所述声码器根据所述声学特征和所述音色特征合成语音信号。
50.所述提取和确定模块320,用于:计算所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差;根据所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差,构建具有第一预设维度的向量特征,将具有第一预设维度的向量特征作为所述全局特征;直接将所述全局特征确定为音色特征;或者,利用预设的转换模块将所述全局向量转换为音色特征;其中,所述转换模块用于纠偏所述全局向量并且将纠偏后的所述全局向量转换为第二预设维度的向量特征,将具有第二预设维度的向量特征作为音色特征。
51.所述装置还包括训练模块,用于在所述利用预设的转换模块将所述全局向量转换为音色特征之前,将所述转换模块和所述声码器一并进行训练,直到所述声码器收敛为止。
52.所述声码器包括至少一个上采样模块;所述合成模块330,用于:将所述音色特征作为条件,注入所述声码器中的每个所述上采样模块,使每个所述上采样模块根据输入特征和所述音色特征执行上采样处理;其中,所述输入特征为输入所述声码器的声学特征或者当前上采样模块的前一个上采样模块的输出结果。
53.本发明实施例所述的装置的功能已经在上述方法实施例中进行了描述,故本实施例的描述中未详尽之处,可以参见前述实施例中的相关说明,在此不做赘述。
54.本实施例提供一种语音合成设备。如图4所示,为根据本发明一实施例的语音合成设备的结构图。
55.在本实施例中,所述语音合成设备包括但不限于:处理器410、存储器420。
56.所述处理器410用于执行存储器420中存储的语音合成程序,以实现上述的语音合成方法。
57.具体而言,所述处理器410用于执行存储器420中存储的语音合成程序,以实现以下步骤:接收声学模型输出的声学特征;在所述声学特征中提取全局特征,并根据所述全局特征确定音色特征;将所述声学特征和所述音色特征输入声码器,使所述声码器根据所述声学特征和所述音色特征合成语音信号。
58.其中,所述在所述声学特征中提取全局特征,包括:计算所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差;根据所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差,构建具有第一预设维度的向量特征,将具有第一预设维度的向量特征作为所述全局特征。
59.其中,所述根据所述全局特征确定音色特征,包括:直接将所述全局特征确定为音色特征;或者,利用预设的转换模块将所述全局向量转换为音色特征;其中,所述转换模块用于纠偏所述全局向量并且将纠偏后的所述全局向量转换为第二预设维度的向量特征,将具有第二预设维度的向量特征作为音色特征。
60.其中,在所述利用预设的转换模块将所述全局向量转换为音色特征之前,还包括:将所述转换模块和所述声码器一并进行训练,直到所述声码器收敛为止。
61.其中,所述声码器包括至少一个上采样模块;所述使所述声码器根据所述声学特征和所述音色特征合成语音信号,包括:将所述音色特征作为条件,注入所述声码器中的每个所述上采样模块,使每个所述上采样模块根据输入特征和所述音色特征执行上采样处理;其中,所述输入特征为输入所述声码器的声学特征或者当前上采样模块的前一个上采样模块的输出结果。
62.本发明实施例还提供了一种计算机可读存储介质。这里的计算机可读存储介质存储有一个或者多个程序。其中,计算机可读存储介质可以包括易失性存储器,例如随机存取存储器;存储器也可以包括非易失性存储器,例如只读存储器、快闪存储器、硬盘或固态硬盘;存储器还可以包括上述种类的存储器的组合。
63.当计算机可读存储介质中一个或者多个程序可被一个或者多个处理器执行,以实现上述的语音合成方法。
64.具体而言,所述处理器用于执行存储器中存储的语音合成程序,以实现以下步骤:
接收声学模型输出的声学特征;在所述声学特征中提取全局特征,并根据所述全局特征确定音色特征;将所述声学特征和所述音色特征输入声码器,使所述声码器根据所述声学特征和所述音色特征合成语音信号。
65.其中,所述在所述声学特征中提取全局特征,包括:计算所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差;根据所述声学特征中全部特征的均值和方差,和/或,部分特征的均值和方差,构建具有第一预设维度的向量特征,将具有第一预设维度的向量特征作为所述全局特征。
66.其中,所述根据所述全局特征确定音色特征,包括:直接将所述全局特征确定为音色特征;或者,利用预设的转换模块将所述全局向量转换为音色特征;其中,所述转换模块用于纠偏所述全局向量并且将纠偏后的所述全局向量转换为第二预设维度的向量特征,将具有第二预设维度的向量特征作为音色特征。
67.其中,在所述利用预设的转换模块将所述全局向量转换为音色特征之前,还包括:将所述转换模块和所述声码器一并进行训练,直到所述声码器收敛为止。
68.其中,所述声码器包括至少一个上采样模块;所述使所述声码器根据所述声学特征和所述音色特征合成语音信号,包括:将所述音色特征作为条件,注入所述声码器中的每个所述上采样模块,使每个所述上采样模块根据输入特征和所述音色特征执行上采样处理;其中,所述输入特征为输入所述声码器的声学特征或者当前上采样模块的前一个上采样模块的输出结果。
69.以上所述仅为本发明的实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1