一种驾驶员语音口令识别检测方法与流程
:本发明属于公共交通安全保障;涉及一种通过监控列车驾驶员语音口令,对出现的语音错误或者不规范进行检测及时纠正提示的方法;特别是一种驾驶员语音口令识别检测方法,实时检测列车驾驶员执行的语音口令,保障公共交通安全。
背景技术
0、
背景技术:
1、为了地铁列车行驶安全,地铁列车驾驶员在工作时,需要执行一些指令并做出相应动作。而目前,需要人工查看分析列车驾驶员动作与口令执行规范性,耗时长、效率低,占用人力资源较多。而且列车驾驶员出现疲劳驾驶或者瞌睡,难以被及时发现。
2、在现有技术中,公开号为cn115359462a的中国专利,公开了一种公交驾驶员疲劳参数补偿以及双轨并行检测方法,包括:s1、对驾驶员的眨眼、打哈欠的图像数据制定标签;s2、利用人脸关键点算法计算出公交驾驶员在正脸状态下闭眼、张嘴的帧数,并与当前数据预处理方法进行比较,根据比值进行补偿;
3、s3、疲劳状态时间序列双轨划分;图像帧按时间序列检测完毕后输出各项区域检测结果,结合车速车况按完整时间片段结果划分至双轨时间序列;s4、设定疲劳状态时间序列双轨预警机制;可分析数据包括眨眼帧数、眨眼频率、张嘴帧数、打哈欠次数;定义perclose计算单位内闭眼帧数与总帧数的比例关系,能反映出眼睛闭合持续时间占检测时间的比值以及驾驶员疲劳状态。公开号为cn112686097a的中国专利,公开了一种人体图像关键点姿态估计方法,包括:对输入的训练图像预处理,用基于空洞卷积的大感受野特征金字塔网络的行人检测网络对输入图像进行检测;将检测到的人体形成的边界框进行裁剪,只保留框内图像;将裁剪后图像输入到设计的模型中,进行人体姿态关键点估计。
4、及时发现并纠正列车驾驶员不规范的操作行为,对保障公共交通的安全运行极为重要。因此如何快速、准确的发现列车驾驶员存在的驾驶员疲劳、驾驶动作、口令错误等问题,是保障地铁系统安全运行的重要前提,而在现有技术中,列车驾驶员疲劳驾驶的及时发现,列车驾驶员语音口令核验判定等技术依旧不够成熟,且缺少能够实际应用的可靠技术。
技术实现思路
0、
技术实现要素:
1、本发明的目的在于克服现有技术存在的缺点,针对列车驾驶员存在的驾驶员疲劳、驾驶动作与口令错误等问题,设计一种驾驶员语音口令识别检测方法,能够快速发现列车驾驶员语音口令错误,保障乘客乘车安全。
2、为了实现上述目的,本发明涉及的一种驾驶员语音口令识别检测方法,具步骤如下:
3、步骤一:预处理
4、对采集到的声音信号进行预处理,将驾驶员说出的语音口令从原始信号中提取出来;对采集的语音进行去噪:首先使用短时傅里叶变换将音频信号转换到频域,采用小波去噪算法对收集的语音信息进行去噪处理,得到语音文件;步骤二:语音特征提取
5、读取语音文件,得到声音信号的时域谱矩阵x(t);对语音文件数据进行分帧和汉明窗处理得到数据为x(frame_len,n),n为帧的数量,其中设置25ms为一帧,每一帧的长度设置为frame_len=400,同时为保证帧与帧之间平滑过渡保持连续性,设置帧与帧之间的重叠长度overlap_len=160;对n帧进行循环处理,每一帧进行汉明窗处理后,进行快速傅里叶变换得到频域数据的振幅,这样每一帧处理后的数据在时间上堆叠起来就能够得到声谱特征;
6、步骤三:语音识别模型对声谱特征进行加工识别
7、将步骤二中得到的声谱特征输入语音识别模型,输入特征数据的尺寸为(1600,200,1);(1600,200,1)中1600指输入的音频的长度,200指输出音频的特征的长度,1指输入的音频的数量,输入为1个音频数量;经过语音识别模型结构处理后输出结果数据,结果数据输出的尺寸为(200,1428);
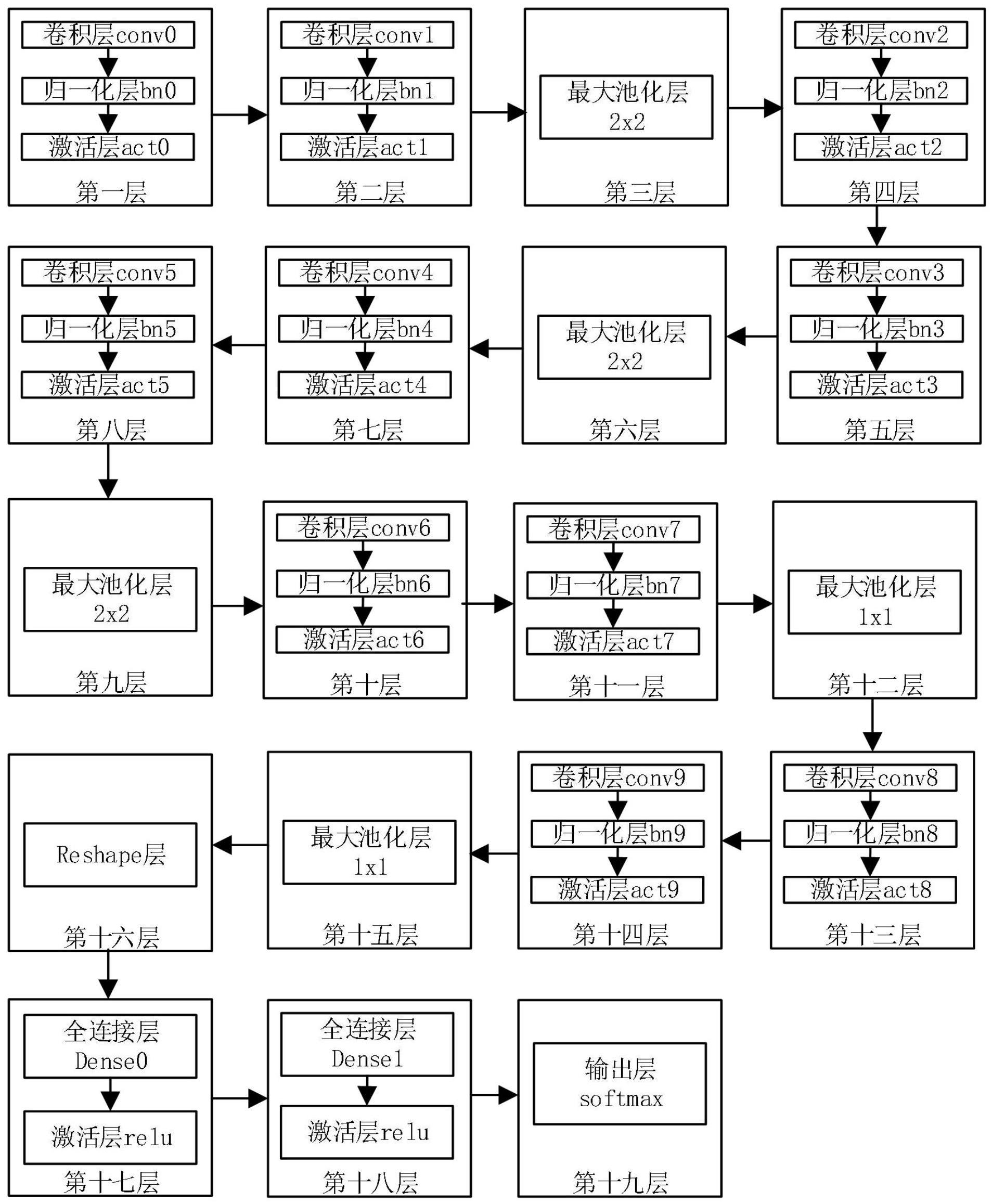
8、步骤四:语音口令正确度判断
9、将语音识别模型输出的结果数据对应到由文字库字典获取指定的文字内容,将语音对应的文字内容拼接成一句文字内容语句;该文字内容语句与标准语句内容对比,准确率达到85%以上,即认为驾驶员所作的语音口令合格。
10、本发明所述语音识别模型对声谱特征进行加工识别的具体过程为:
11、1)语音识别模型的构建:语音识别模型结构包括19层,每层网络结构为串联而成,当前层的输出作为下一层的输入;网络模型的每一层结构都是提取特征的过程,输入的数据经过层层网络结构传递,从抽象特征到具体特征,随着网络层数的增加,提取的特征更复杂详细,使语音识别模型最终的输出特征中能够得到具体的词或者词语;
12、2)、语音识别模型的训练:利用人工标注的语音数据对模型进行训练,语音数据包括语音文件、以及语音文件包含的文字内容;将语音数据输入模型进行特征提取,语音识别模型最终输出的结果是预测值,利用损失函数计算当前模型输出的结果与真实值的差距,进而指导、调整网络进行训练学习,一步步更新模型参数的过程,直到最终网络模型收敛,模型训练完毕;
13、其中损失函数计算是语音识别模型的组成部分,损失函数计算具体为:
14、语音识别模型采用ctc的损失函数,定义如下:
15、l(s)=-lnπ(x,z)∈sp(z|x)=-σ(x,z)∈slnp(z|x)
16、其中p(z|x)代表给定输入样本x,输入样本x为语音识别模型真实的输入样本,输出序列为z的概率,s为训练集;应用该损失函数,给定输入样本x,输出正确标签的概率乘积,输入结果越小,准确度越高;
17、3)、采集的驾驶员语音文件输入语音识别模型,语音识别模型输出结果数据,语音识别模型最终输出的结果数据尺寸为[200,1428],该数据包含预测的文字索引,因此能够直接从文字库中获取文字的内容。
18、本发明所述语音识别模型结构具体如下:
19、第1层为:卷积层conv0,输出通道32,滤波核大小为3x3;填充方式为same;归一化层bn0,batchnormalization;激活层act0,选择的激活函数为relu;第1层输出尺寸为[1600,200,32];卷积后特征图的大小与卷积核无关,只于步长有关,因为默认步长为1,所以输出后的特征图大小仍然为[1600,200],32表示输出的通道数;
20、第2层为:卷积层conv1,输出通道32,滤波核大小为3x3;填充方式为same;归一化层bn1,batchnormalization;激活层act1,选择的激活函数为relu;第2层输出尺寸为[1600,200,32];
21、第3层为:池化层maxpooling2d,池化窗口大小为2x2,填充方式为valid;第3层输出尺寸为[800,100,32];因第3层的池化窗口为2x2,因此特征图的大小缩小一倍,所以为[1600/2,200/2],32表示该层的输出通道数为32;
22、第4层为:卷积层conv2,输出通道64,滤波核大小为3x3;填充方式为same;归一化层bn2,batchnormalization;激活层act2,选择的激活函数为relu;第4层输出尺寸为[800,100,64];
23、第5层为:卷积层conv3,输出通道64,滤波核大小为3x3;填充方式为same;归一化层bn3,batchnormalization;激活层act3,选择的激活函数为relu;第5层输出尺寸为[800,100,64];
24、第6层为:池化层,maxpooling2d,池化窗口大小为2x2,填充方式为valid;第6层输出尺寸为[400,50,64];
25、第7层为:卷积层conv4,输出通道128,滤波核大小为3x3;填充方式为same;归一化层bn4,batchnormalization;激活层act4,选择的激活函数为relu;第7层输出尺寸为[400,50,128];
26、第8层为:卷积层conv5,输出通道128,滤波核大小为3x3;填充方式为same;归一化层bn5,batchnormalization;激活层act5,选择的激活函数为relu;第8层输出尺寸为[400,50,128];
27、第9层为:池化层,maxpooling2d,池化窗口大小为2x2,填充方式为valid;第9层输出尺寸为[200,25,128];
28、第10层为:卷积层conv6,输出通道128,滤波核大小为3x3;填充方式为same;归一化层bn6,batchnormalization;激活层act6,选择的激活函数为relu;第10层输出尺寸为[200,25,128];
29、第11层为:卷积层conv7,输出通道128,滤波核大小为3x3;填充方式为same;归一化层bn7,batchnormalization;激活层act7,选择的激活函数为relu;第11层输出尺寸为[200,25,128];
30、第12层为:池化层,maxpooling2d,池化窗口大小为1x1,填充方式为valid;第12层输出尺寸为[200,25,128];
31、第13层为:卷积层conv8,输出通道128,滤波核大小为3x3;填充方式为same;归一化层bn8,batchnormalization;激活层act8,选择的激活函数为relu;第13层输出尺寸为[200,25,128];
32、第14层为:卷积层conv9,输出通道128,滤波核大小为3x3;填充方式为same;归一化层bn9,batchnormalization;激活层act9,选择的激活函数为relu;第14层输出尺寸为[200,25,128];
33、第15层为:池化层,maxpooling2d,池化窗口大小为1x1,填充方式为valid;第15层输出尺寸为[200,25,128];
34、第16层为:reshape层;第16层输出尺寸为[200,3200];
35、第17层为:全连接层dense0,输出通道128,激活函数为relu;第17层输出尺寸为[200,128];
36、第18层为:全连接层dense1,输出通道1428,激活函数为relu;第18层输出尺寸为[200,1428];
37、第19层为:输出层,选择的激活函数为softmax;第19层输出尺寸为[200,1428];
38、所述语音识别模型的每层网络结构中的输出通道数代表该层网络结构的滤波核数量;滤波核大小的选择根据实际需要进行调整,即需要根据输入数据的形状进行选择。
39、本发明与现有技术相比,所设计的驾驶员语音口令识别检测方法实现了应用模型轻量化、语音识别准确,能够快速发现语音口令中的错误,及时进行更正,保证列车运营安全;本发明能够应用于地铁、火车、轻轨、航空、大型基建设备操作场所及其控制室等,具有广阔的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!