语音合成方法、装置、存储介质和电子设备与流程
本公开涉及人工智能领域,具体地,涉及一种语音合成方法、装置、存储介质和电子设备。
背景技术:
1、现有语音合成系统通常是由目标发音人录制大量语料数据,基于这些语料数据合成该目标发音人的语音。虽然通过该方法合成的语音音色与发音人本身发出的语音较为接近,但是需要录制目标发音人的大量语料数据,工作量大,耗费周期长,而且成本较高。
技术实现思路
1、本公开的目的是提供一种语音合成方法、装置、存储介质和电子设备,以在确保语音合成效果的情况下,减少对目标发音人的语料数据的需求量。
2、为了实现上述目的,本公开第一方面提供一种语音合成方法,该方法包括:
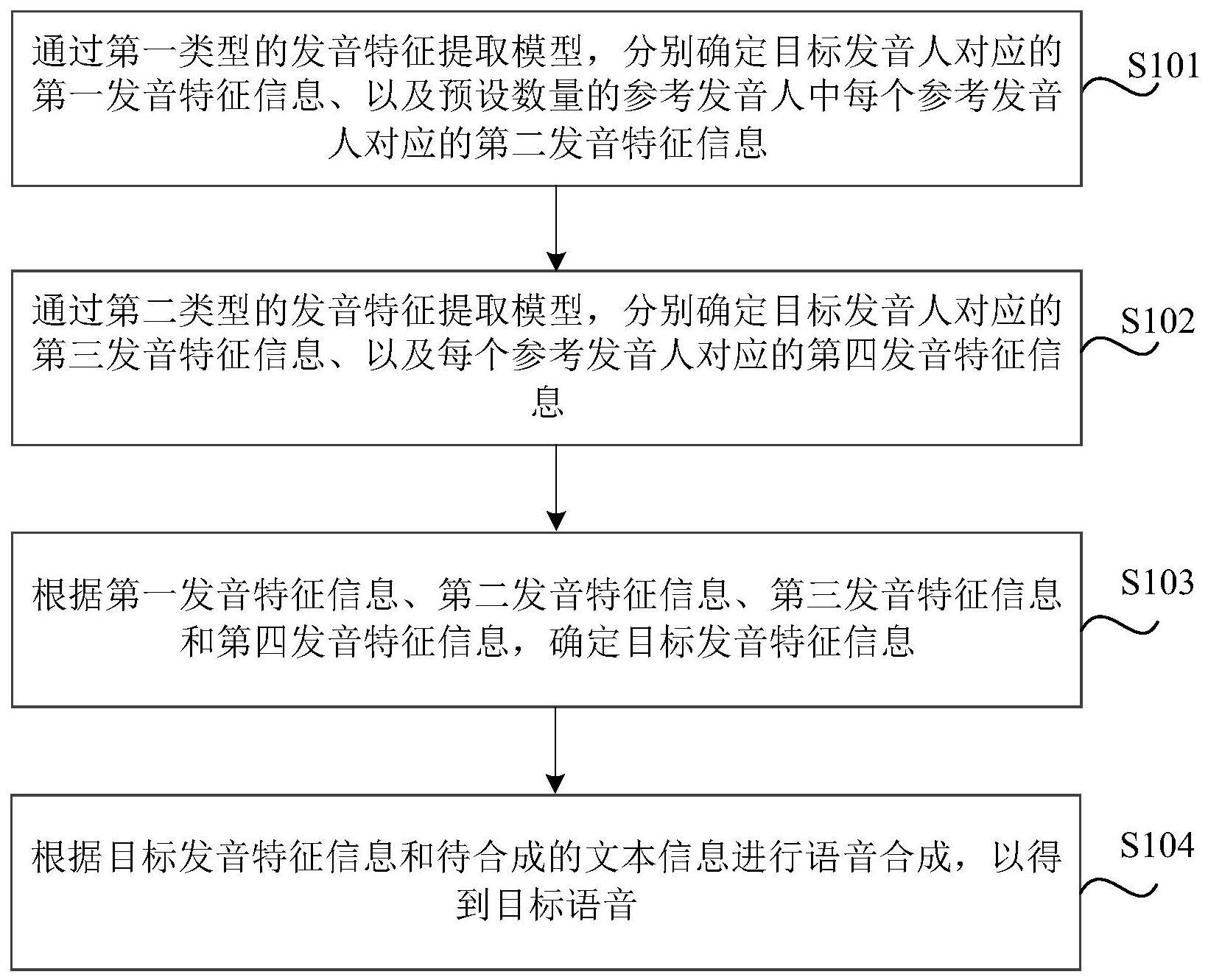
3、通过第一类型的发音特征提取模型,分别确定目标发音人对应的第一发音特征信息、以及预设数量的参考发音人中每个参考发音人对应的第二发音特征信息;
4、通过第二类型的发音特征提取模型,分别确定所述目标发音人对应的第三发音特征信息、以及每个所述参考发音人对应的第四发音特征信息,其中,所述第二类型与所述第一类型不同;
5、根据所述第一发音特征信息、所述第二发音特征信息、所述第三发音特征信息和所述第四发音特征信息,确定目标发音特征信息;
6、根据所述目标发音特征信息和待合成的文本信息进行语音合成,以得到目标语音。
7、可选地,所述根据所述第一发音特征信息、所述第二发音特征信息、所述第三发音特征信息和所述第四发音特征信息,确定目标发音特征信息,包括:
8、确定每个所述参考发音人对应的权重信息;
9、根据所述第一发音特征信息、所述第二发音特征信息、所述第三发音特征信息、所述第四发音特征信息和所述权重信息,确定所述目标发音特征信息。
10、可选地,所述确定每个所述参考发音人对应的权重信息,包括:
11、针对每个所述参考发音人,确定所述目标发音人对应的所述第一发音特征信息与所述参考发音人对应的所述第二发音特征信息之间的第一相似度,并根据所述第一相似度,确定所述参考发音人对应的第一权重;
12、针对每个所述参考发音人,确定所述目标发音人对应的第三发音特征信息与所述参考发音人对应的所述第四发音特征信息之间的第二相似度,并根据所述第二相似度,确定所述参考发音人对应的第二权重;
13、所述根据所述第一发音特征信息、所述第二发音特征信息、所述第三发音特征信息、所述第四发音特征信息和所述权重信息,确定所述目标发音特征信息,包括:
14、根据所述第一发音特征信息、每个所述参考发音人对应的所述第二发音特征信息及所述第一权重、所述第三发音特征信息、每个所述参考发音人对应的所述第四发音特征信息及所述第二权重,确定所述目标发音特征信息。
15、可选地,所述根据所述第一发音特征信息、每个所述参考发音人对应的所述第二发音特征信息及所述第一权重、所述第三发音特征信息、每个所述参考发音人对应的所述第四发音特征信息及所述第二权重,确定所述目标发音特征信息,包括:
16、根据所述第一发音特征信息、每个所述参考发音人对应的所述第二发音特征信息及所述第一权重,确定第一融合特征信息;
17、根据所述第三发音特征信息、每个所述参考发音人对应的所述第四发音特征信息及所述第二权重,确定第二融合特征信息;
18、根据所述第一融合特征信息、所述第一类型的发音特征提取模型对应的模型权重、所述第二融合特征信息、以及所述第二类型的发音特征提取模型对应的模型权重,确定所述目标发音特征信息。
19、可选地,所述确定每个所述参考发音人对应的权重信息,包括:
20、针对每个所述参考发音人,若确定所述参考发音人与所述目标发音人为相同性别,则将第三权重作为所述参考发音人对应的权重信息;若确定所述参考发音人与所述目标发音人为不同性别,则将第四权重作为所述参考发音人对应的权重信息,其中,所述第三权重大于所述第四权重。
21、可选地,根据所述第一发音特征信息、所述第二发音特征信息、所述第三发音特征信息、所述第四发音特征信息和所述权重信息,确定所述目标发音特征信息,包括:
22、根据所述第一发音特征信息、每个所述参考发音人对应的所述第二发音特征信息及所述权重信息,确定第一融合特征信息;
23、根据所述第三发音特征信息、每个所述参考发音人对应的所述第四发音特征信息及所述权重信息,确定第二融合特征信息;
24、根据所述第一融合特征信息、所述第一类型的发音特征提取模型对应的模型权重、所述第二融合特征信息、以及所述第二类型的发音特征提取模型对应的模型权重,确定所述目标发音特征信息。
25、可选地,所述根据所述目标发音特征信息和待合成的文本信息进行语音合成,以得到目标语音,包括:
26、将所述文本信息输入至预先训练的声学模型中,获得所述声学模型输出的与所述文本信息对应的声学特征;
27、将所述声学特征输入至预先训练的声码器模型中,获得所述声码器模型输出的音频,以得到所述目标语音,其中,所述声学模型和所述声码器模型是基于所述目标发音特征信息训练得到的。
28、本公开第二方面提供一种语音合成装置,该装置包括:
29、第一确定模块,用于通过第一类型的发音特征提取模型,分别确定目标发音人对应的第一发音特征信息、以及预设数量的参考发音人中每个参考发音人对应的第二发音特征信息;
30、第二确定模块,用于通过第二类型的发音特征提取模型,分别确定所述目标发音人对应的第三发音特征信息、以及每个所述参考发音人对应的第四发音特征信息,其中,所述第二类型与所述第一类型不同;
31、第三确定模块,用于根据所述第一发音特征信息、所述第二发音特征信息、所述第三发音特征信息和所述第四发音特征信息,确定目标发音特征信息;
32、合成模块,用于根据所述目标发音特征信息和待合成的文本信息进行语音合成,以得到目标语音。
33、可选地,所述第三确定模块包括:
34、第一确定子模块,用于确定每个所述参考发音人对应的权重信息;
35、第二确定子模块,用于根据所述第一发音特征信息、所述第二发音特征信息、所述第三发音特征信息、所述第四发音特征信息和所述权重信息,确定所述目标发音特征信息。
36、可选地,第一确定子模块包括:
37、第三确定子模块,用于针对每个所述参考发音人,确定所述目标发音人对应的所述第一发音特征信息与所述参考发音人对应的所述第二发音特征信息之间的第一相似度,并根据所述第一相似度,确定所述参考发音人对应的第一权重;
38、第四确定子模块,用于针对每个所述参考发音人,确定所述目标发音人对应的第三发音特征信息与所述参考发音人对应的所述第四发音特征信息之间的第二相似度,并根据所述第二相似度,确定所述参考发音人对应的第二权重;
39、第二确定子模块用于通过以下方式确定所述目标发音特征信息:
40、根据所述第一发音特征信息、每个所述参考发音人对应的所述第二发音特征信息及所述第一权重、所述第三发音特征信息、每个所述参考发音人对应的所述第四发音特征信息及所述第二权重,确定所述目标发音特征信息。
41、可选地,所述第二确定子模块包括:
42、第五确定子模块,用于根据所述第一发音特征信息、每个所述参考发音人对应的所述第二发音特征信息及所述第一权重,确定第一融合特征信息;
43、第六确定子模块,用于根据所述第三发音特征信息、每个所述参考发音人对应的所述第四发音特征信息及所述第二权重,确定第二融合特征信息;
44、第七确定子模块,用于根据所述第一融合特征信息、所述第一类型的发音特征提取模型对应的模型权重、所述第二融合特征信息、以及所述第二类型的发音特征提取模型对应的模型权重,确定所述目标发音特征信息。
45、可选地,第一确定子模块包括:
46、第八确定子模块,用于针对每个所述参考发音人,若确定所述参考发音人与所述目标发音人为相同性别,则将第三权重作为所述参考发音人对应的权重信息;若确定所述参考发音人与所述目标发音人为不同性别,则将第四权重作为所述参考发音人对应的权重信息,其中,所述第三权重大于所述第四权重。
47、可选地,所述第二确定子模块包括:
48、第九确定子模块,用于根据所述第一发音特征信息、每个所述参考发音人对应的所述第二发音特征信息及所述权重信息,确定第一融合特征信息;
49、第十确定子模块,用于根据所述第三发音特征信息、每个所述参考发音人对应的所述第四发音特征信息及所述权重信息,确定第二融合特征信息;
50、第十一确定子模块,用于根据所述第一融合特征信息、所述第一类型的发音特征提取模型对应的模型权重、所述第二融合特征信息、以及所述第二类型的发音特征提取模型对应的模型权重,确定所述目标发音特征信息。
51、可选地,所述合成模块包括:
52、第一获取子模块,用于将所述文本信息输入至预先训练的声学模型中,获得所述声学模型输出的与所述文本信息对应的声学特征;
53、第二获取子模块,用于将所述声学特征输入至预先训练的声码器模型中,获得所述声码器模型输出的音频,以得到所述目标语音,其中,所述声学模型和所述声码器模型是基于所述目标发音特征信息训练得到的。
54、本公开第三方面提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本公开第一方面提供的所述方法的步骤。
55、本公开第四方面提供一种电子设备,包括:
56、存储器,其上存储有计算机程序;
57、控制器,所述计算机程序被控制器执行时,实现本公开第一方面提供的所述方法的步骤
58、在上述技术方案中,通过不同的第一类型的发音特征提取模型和第二类型的发音特征提取模型,可提取到同一发音人的不同发音特征信息,如此,确定出的每一发音人的发音特征信息更加全面、准确,以提高语音合成的效果。根据目标发音人和预设数量的参考发音人的发音特征信息,确定目标发音特征信息,并结合待合成的文本信息进行语音合成,以得到目标语音。如此,能够在确保目标语音合成效果的情况下,减少对目标发音人的语料数据的需求量。
59、本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!