音视频语音识别模型的训练方法、系统和电子设备与流程
本发明涉及智能语音领域,尤其涉及一种音视频语音识别模型的训练方法、系统和电子设备。
背景技术:
1、随着智能语音技术的发展,智能语音识别技术已经逐步普及到日常生活中。在语音识别中,当语音信号被噪声影响而失真时,会影响对应的语音识别效果。考虑到人在日常的语音交互中,除了声音模态,视觉模态有时对于准确理解语音也是必要的,可以引入不受噪声影响的视觉模态来辅助语音识别。例如avsr(audio-visual speech recognition,音视频语音识别)将视觉流融合到成熟的自动语音识别模型中。
2、在实现本发明过程中,发明人发现相关技术中至少存在如下问题:
3、单模态语音识别系统由于噪声的干扰,难以识别嘈杂环境的语音。
4、音视频语音识别系统虽然能够改善嘈杂环境下语音识别的表现,但当出现音视频不同步的情况时,受限于模型的深度,往往识别效果欠佳。并且音视频语音识别系统在识别单模态的语音时,由于缺少自适应策略,识别效果反而不如单模态语音识别系统。
技术实现思路
1、为了至少解决现有技术中音视频语音识别存在的上述识别问题。第一方面,本发明实施例提供一种音视频语音识别模型的训练方法,包括:
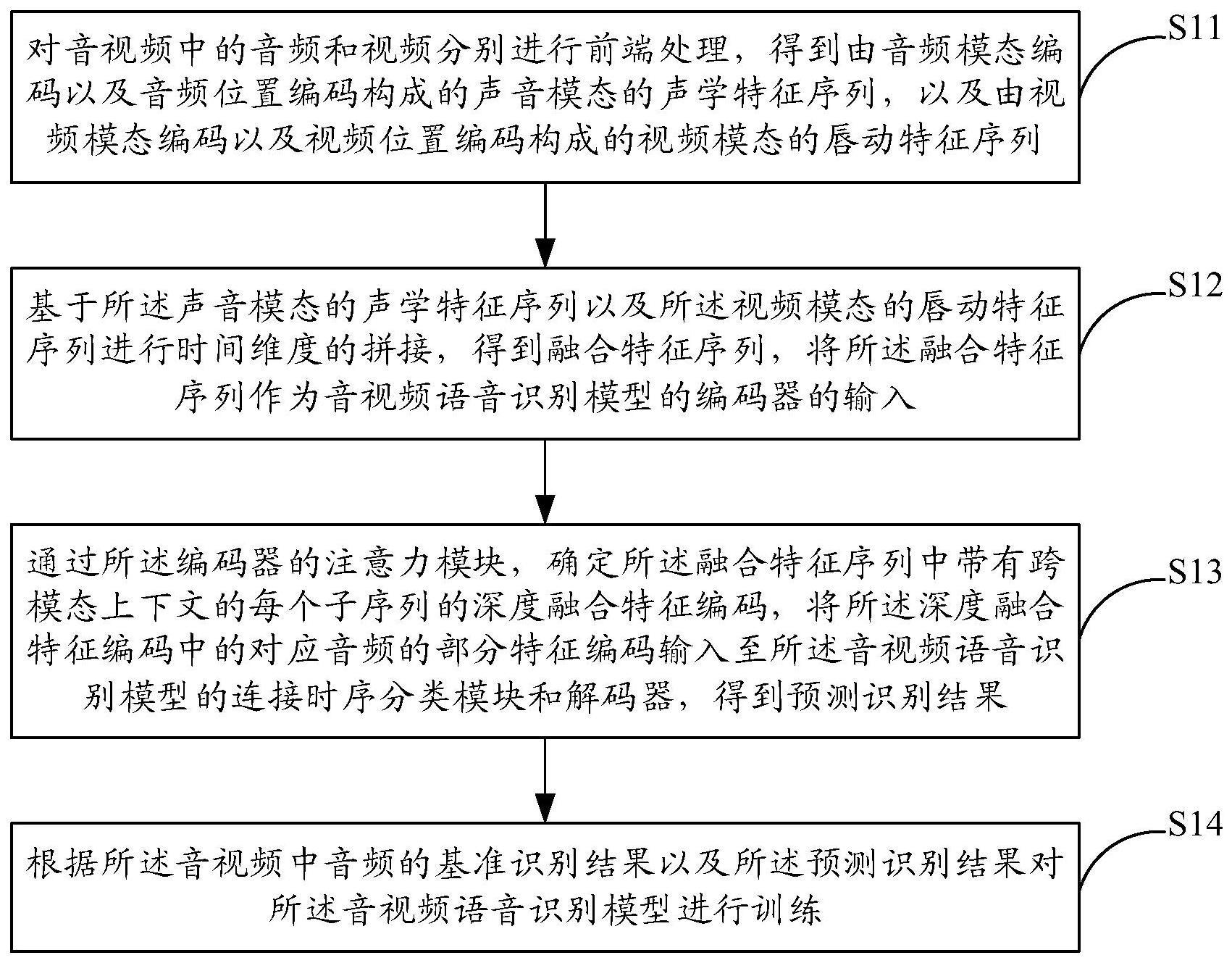
2、对音视频中的音频和视频分别进行前端处理,得到由音频模态编码以及音频位置编码构成的声音模态的声学特征序列,以及由视频模态编码以及视频位置编码构成的视频模态的唇动特征序列;
3、基于所述声音模态的声学特征序列以及所述视频模态的唇动特征序列进行时间维度的拼接,得到融合特征序列,将所述融合特征序列作为音视频语音识别模型的编码器的输入;
4、通过所述编码器的注意力模块,确定所述融合特征序列中带有跨模态上下文的每个子序列的深度融合特征编码,将所述深度融合特征编码中的对应音频的部分特征编码输入至所述音视频语音识别模型的连接时序分类模块和解码器,得到预测识别结果;
5、根据所述音视频中音频的基准识别结果以及所述预测识别结果对所述音视频语音识别模型进行训练。
6、第二方面,本发明实施例提供一种基于音视频语音识别模型的语音识别方法,包括:
7、将接收到的音视频文件输入至音视频语音识别模型中,其中,所述音视频文件包括:音画同步的音视频、预设帧率内音画不同步的音视频;
8、所述音视频语音识别模型对所述音视频文件中的音频和视频分别进行前端处理,得到声音模态的声学特征序列以及视频模态的唇动特征序列;
9、将所述声音模态的声学特征序列以及所述视频模态的唇动特征序列进行时间维度的拼接,将拼接得到的融合特征序列输入至编码器;
10、所述编码器输出的带有跨模态上下文的每个子序列的深度融合特征编码,保留所述深度融合特征编码中对应音频的部分特征编码;
11、将所述对应音频的部分特征编码输入至连接时序分类模块和解码器,得到所述音视频文件的语音识别结果。
12、第三方面,本发明实施例提供一种音视频语音识别模型的训练系统,包括:
13、前端处理程序模块,用于对音视频中的音频和视频分别进行前端处理,得到由音频模态编码以及音频位置编码构成的声音模态的声学特征序列,以及由视频模态编码以及视频位置编码构成的视频模态的唇动特征序列;
14、融合程序模块,用于基于所述声音模态的声学特征序列以及所述视频模态的唇动特征序列进行时间维度的拼接,得到融合特征序列,将所述融合特征序列作为音视频语音识别模型的编码器的输入;
15、编码程序模块,用于通过所述编码器的注意力模块,确定所述融合特征序列中带有跨模态上下文的每个子序列的深度融合特征编码,将所述深度融合特征编码中的对应音频的部分特征编码输入至所述音视频语音识别模型的连接时序分类模块和解码器,得到预测识别结果;
16、训练程序模块,用于根据所述音视频中音频的基准识别结果以及所述预测识别结果对所述音视频语音识别模型进行训练。
17、第四方面,本发明实施例提供一种基于音视频语音识别模型的语音识别系统,包括:
18、音视频接收程序模块,用于将接收到的音视频文件输入至音视频语音识别模型中,其中,所述音视频文件包括:音画同步的音视频、预设帧率内音画不同步的音视频;
19、前端处理程序模块,用于所述音视频语音识别模型对所述音视频文件中的音频和视频分别进行前端处理,得到声音模态的声学特征序列以及视频模态的唇动特征序列;
20、融合程序模块,用于将所述声音模态的声学特征序列以及所述视频模态的唇动特征序列进行时间维度的拼接,将拼接得到的融合特征序列输入至编码器;
21、编码程序模块,用于所述编码器输出的带有跨模态上下文的每个子序列的深度融合特征编码,保留所述深度融合特征编码中对应音频的部分特征编码;
22、语音识别程序模块,用于将所述对应音频的部分特征编码输入至连接时序分类模块和解码器,得到所述音视频文件的语音识别结果。
23、第五方面,提供一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行本发明任一实施例的音视频语音识别模型的训练方法以及基于音视频语音识别模型的语音识别方法的步骤。
24、第六方面,本发明实施例提供一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现本发明任一实施例的音视频语音识别模型的训练方法以及基于音视频语音识别模型的语音识别方法的步骤。
25、本发明实施例的有益效果在于:由于在训练过程中编码器通过跨模态注意力机制学习了特征序列一定范围内的上下文,在纯净或者嘈杂的音视频输入上能够得到更低的错误率之外,还能够在一定范围内抵抗音视频不同步的问题,例如可以在3到5帧的不同步的音视频输入上,仍然可以得到一个相对稳定准确的结果。并且在视觉模态缺失时,也就是变成了单模态的语音识别时,通过本方法训练的音视频语音识别模型可以无损的适应单模态输入,并且性能能够和常规单模态系统保持相当的水平。
技术特征:
1.一种音视频语音识别模型的训练方法,包括:
2.根据权利要求1所述的方法,其中,所述对音视频中的音频和视频分别进行前端处理包括:
3.一种基于音视频语音识别模型的语音识别方法,包括:
4.根据权利要求3所述的方法,其中,所述音视频文件还包括:缺失视觉模态的单模态纯音频;
5.一种音视频语音识别模型的训练系统,包括:
6.根据权利要求5所述的系统,其中,所述前端处理程序模块用于:
7.一种基于音视频语音识别模型的语音识别系统,包括:
8.根据权利要求7所述的系统,其中,所述音视频文件还包括:缺失视觉模态的单模态纯音频;
9.一种电子设备,其包括:至少一个处理器,以及与所述至少一个处理器通信连接的存储器,其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1-4中任一项所述方法的步骤。
10.一种存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现权利要求1-4中任一项所述方法的步骤。
技术总结
本发明实施例提供一种音视频语音识别模型的训练方法、系统和电子设备。该方法包括:对音视频中的音频和视频分别进行前端处理,得到声学特征序列以及唇动特征序列;基于声音模态的声学特征序列以及视频模态的唇动特征序列进行时间维度的拼接,得到融合特征序列;通过编码器的注意力模块,确定融合特征序列中带有跨模态上下文的每个子序列的深度融合特征编码,将深度融合特征编码中的对应音频的部分特征编码输入至音视频语音识别模型的连接时序分类模块和解码器;根据音频的基准识别结果以及预测识别结果对音视频语音识别模型进行训练。本发明实施例在纯净或者嘈杂的音视频输入上能够得到更低的错误率之外,还能够在一定范围内抵抗音视频不同步。
技术研发人员:钱彦旻,李嘉鸿,李晨达,吴逸飞
受保护的技术使用者:思必驰科技股份有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!