包括个性化文本到语音模块的电子装置及其控制方法与流程
本公开涉及一种包括个性化文本到语音(tts)模块的电子装置以及一种用于控制该电子装置的方法。
背景技术:
1、最近正在使用对用户语音输入提供响应的人工智能代理(例如,bixbytm、assistanttm或alexatm)来提供各种服务。文本到语音(tts)技术通过全面地对输入文本与声学特性之间的关系进行建模来实现更自然的合成声音。
2、tts可以指例如通过学习文本和声音源的数据对来创建最适于任何给定文本的语音的技术。个性化tts(p-tts)可以指例如将声学模型转换成用户的语调并且旨在通过以下操作来模仿用户的声音的技术:从用户获得几个文本-声音源数据对,并且基于所获得的文本-声音源数据对生成海量文本-声音源数据对。
技术实现思路
1、技术问题
2、为让个性化tts生成海量声音源,需要将所有发音变体包括在几个文本-声音源数据对中。为此目的,电子装置事先向用户提供包括所有发音变体的文本并且使得用户能够阅读该文本,从而保证声音源。
3、个性化tts的性能主要取决于所收集的声音是否和用户像往常一样讲话一般自然,并且其次取决于是否为每个发音变体收集到足够的声音。
4、然而,通过让用户阅读文本来获得声音的方式不会产生来自用户的好像她在谈话一样的自然语音。
5、本公开的实施例提供了一种用于经由使用聊天机器人的谈话从用户获得自然语音的电子装置以及一种控制该电子装置的方法。
6、技术方案
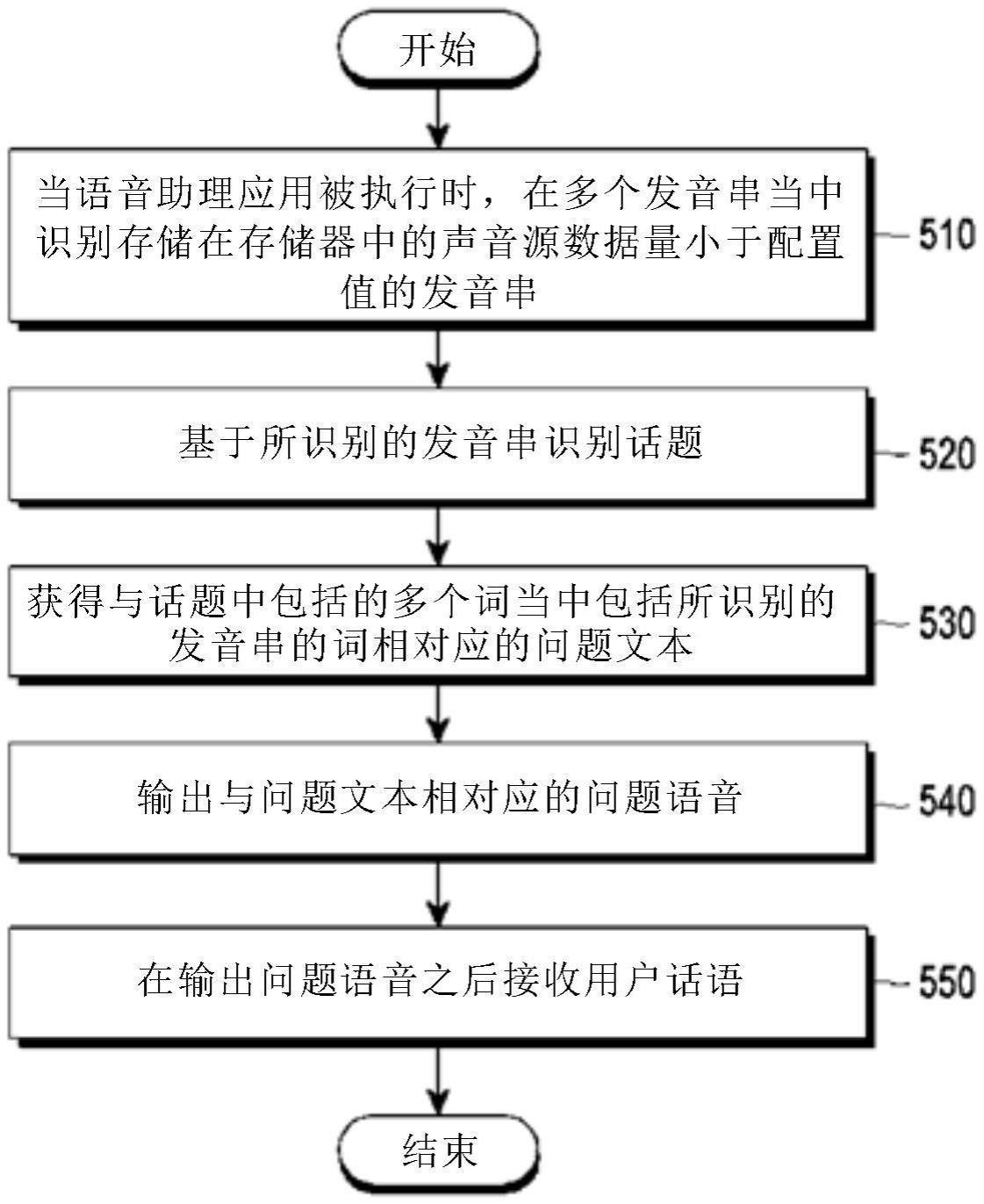
7、根据示例实施例,一种电子装置包括:存储器;以及至少一个处理器,所述至少一个处理器与所述存储器可操作地连接。所述至少一个处理器被配置为:响应于语音助理应用被执行,在多个发音变体当中识别存储在所述存储器中的声音源数据量小于指定值的发音变体;基于所识别的发音变体识别主题;获得与所述主题中包括的多个词当中包括所识别的发音变体的词相对应的问题文本;输出与所述问题文本相对应的问题语音;以及在输出所述问题语音之后接收话语。
8、根据示例实施例,一种控制电子装置的方法包括:响应于语音助理应用被执行,在多个发音变体当中识别存储在存储器中的声音源数据量小于指定值的发音变体;基于所识别的发音变体识别主题;获得与所述主题中包括的多个词当中包括所识别的发音变体的词相对应的问题文本;输出与所述问题文本相对应的问题语音;以及在输出所述问题语音之后接收话语。
9、有益效果
10、根据各种示例实施例,由于用户的话语是通过与聊天机器人的谈话收集的,所以可以从用户获得自然话语,从而提高个性化tts的质量。
11、根据各种示例实施例,可以解决要用于个性化tts的声音源量方面的不平衡。
技术特征:
1.一种电子装置,所述电子装置包括:
2.根据权利要求1所述的电子装置,其中,所述至少一个处理器被配置为:识别包括有包括所识别的发音变体的大多数词的主题。
3.根据权利要求1所述的电子装置,其中,所述至少一个处理器被配置为:
4.根据权利要求1所述的电子装置,其中,所述至少一个处理器被配置为:
5.根据权利要求1所述的电子装置,其中,所述至少一个处理器被配置为:
6.根据权利要求1所述的电子装置,其中,所述至少一个处理器被配置为:
7.根据权利要求6所述的电子装置,其中,所述至少一个处理器被配置为:响应于所获得的声音源数据当中的所识别的发音变体的所述声音源数据量不小于所设置的声音源数据量,基于所获得的发音变体和所获得的声音源数据训练所述p-tts模块。
8.根据权利要求1所述的电子装置,所述电子装置还包括:
9.根据权利要求1所述的电子装置,所述电子装置还包括:
10.根据权利要求9所述的电子装置,其中,所述电子装置包括服务器,所述服务器被配置为与所述外部电子装置进行通信。
11.一种控制电子装置的方法,所述方法包括:
12.根据权利要求11所述的方法,其中,识别所述主题包括:识别包括有包括所识别的发音变体的大多数词的主题。
13.根据权利要求11所述的方法,其中,识别所述主题包括:
14.根据权利要求11所述的方法,其中,识别所述发音变体包括:
15.根据权利要求11所述的方法,其中,获得所述问题文本包括:
技术总结
根据实施例,一种电子装置可以包括:存储器;以及至少一个处理器,所述至少一个处理器可操作地连接到所述存储器,其中,所述至少一个处理器:在语音助理应用被执行时,在多个发音串当中识别存储在所述存储器中的声音源数据量的值小于特定值的发音串;基于所识别的发音串识别话题;获得与所述话题中包括的多个词当中包括所识别的发音串的词相对应的问题文本;输出与所述问题文本相对应的问题语音;以及在输出所述问题语音之后接收话语。
技术研发人员:柳哲,金光勋,成准植
受保护的技术使用者:三星电子株式会社
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!