基于LED显示屏的语音播放方法、装置、设备及介质与流程
本发明涉及语音播放,尤其涉及一种基于led显示屏的语音播放方法、装置、设备及介质。
背景技术:
1、led显示屏一般用来显示文字、图像、视频、录像信号等各种信息,led(lightemitting diode,发光二极管),是一种通过控制半导体发光二极管的显示方式。车载led显示屏因为汽车的流动性,若在led显示屏上显示广告,可以有效地宣传达到宣传的作用,成为极其有效的广告宣传工具,另外也可以在led显示屏也可以用于公交车上提示到站信息以及车内温度等,方便了人们的出行。其中,led语音播报显示屏是语音显示屏的一种,常用于各种信息的播报提醒和显示。目前,现有的led语音播报技术自动程度还比较低,例如,在车辆的启动至行进的过程中,仍需要手动操作车载显示屏,增加了安全隐患;同时,现有语音播放技术采用语音合成方法,在实际使用中会出现音频识别不准确,从而产生显示内容不匹配或者音画不同步的现象。综上所述,如何提高显示屏信息与语音同步播放的技术成为亟待解决的问题。
技术实现思路
1、本发明提供一种基于led显示屏的语音播放方法、装置、设备及介质,其主要目的在于解决显示屏信息与语音同步播放的准确性较低的问题。
2、为实现上述目的,本发明提供的一种基于led显示屏的语音播放方法,包括:
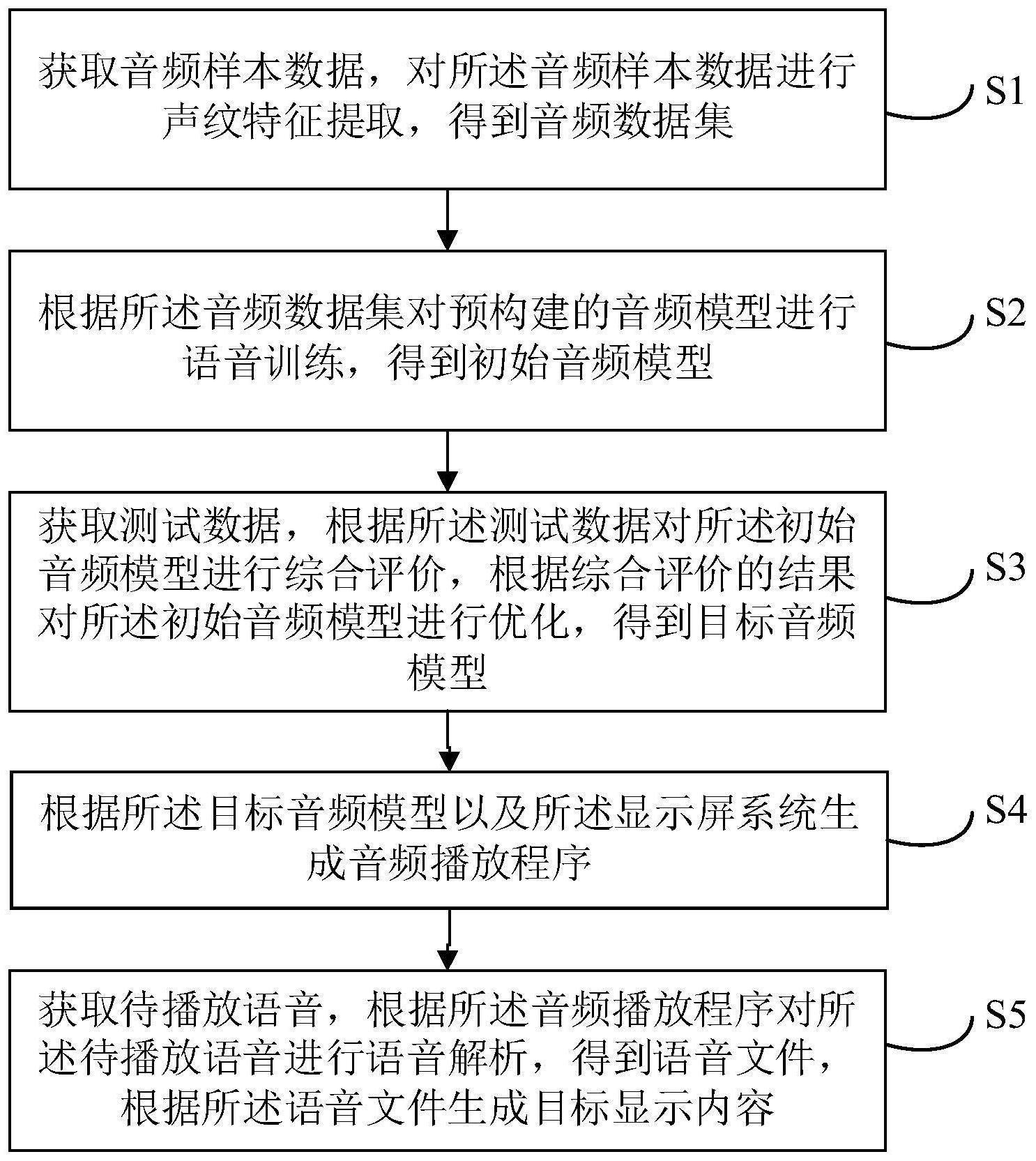
3、获取音频样本数据,对所述音频样本数据进行声纹特征提取,得到音频数据集;
4、根据所述音频数据集对预构建的音频模型进行语音训练,得到初始音频模型;
5、获取测试数据,根据所述测试数据对所述初始音频模型进行综合评价,根据综合评价的结果对所述初始音频模型进行优化,得到目标音频模型;
6、根据所述目标音频模型以及所述显示屏系统生成音频播放程序;
7、获取待播放语音,根据所述音频播放程序对所述待播放语音进行语音解析,得到语音文件,根据所述语音文件生成目标显示内容。
8、可选地,所述对所述音频样本数据进行声纹特征提取,得到音频数据集,包括:
9、对所述音频样本数据进行信号加重,得到音频样本处理数据;
10、对所述音频样本处理数据进行频谱分析,得到与所述音频样本处理数据对应的频谱;
11、对所述频谱进行特征处理,得到音频数据集。
12、可选地,所述对所述音频样本数据进行信号加重,得到音频样本处理数据,包括:
13、对所述音频样本数据进行端点检测,得到音频信号序列;
14、对所述音频信号序列进行加重计算,得到音频样本处理数据;
15、利用下式对所述音频信号序列进行加重计算:
16、
17、
18、其中,y(x)表示为音频样本输出信号;a表示为所述音频信号序列的分数阶倒数的阶数;n表示为所述音频信号序列中固定项的个数;x表示为所述音频信号序列;表示为所述音频信号序列中各个序列对应的加权系数。
19、可选地,所述对所述频谱进行特征处理,得到音频数据集,包括:
20、创建所述频谱的滤波器组,对所述滤波器组进行参数设置,得到目标滤波器组;
21、利用所述目标滤波器组对所述频谱进行过滤,得到能量值;
22、对所述能量值进行函数变换,得到音频数据集。
23、可选地,所述根据所述测试数据对所述初始音频模型进行综合评价,包括:
24、利用所述初始音频模型对所述测试数据进行语音识别,得到识别词;
25、对所述识别词进行分类,得到正样本及负样本;
26、根据所述正样本及负样本计算所述初始音频模型的准确率,利用所述准确率与预设的阈值进行比较,将比较的结果作为对所述初始音频模型进行综合评价的结果;
27、利用下式根据所述正样本及负样本计算所述初始音频模型的准确率:
28、
29、其中,p表示为所述初始音频模型的准确率,c1表示为所述正样本中的识别词个数;c2表示为所述负样本中的识别词个数;c1+c2表示为所述识别词的总个数。
30、可选地,所述根据所述音频数据集对预构建的音频模型进行语音训练,得到初始音频模型,包括:
31、根据所述音频模型对所述音频数据集进行卷积计算,得到所述音频数据集对应的特征概率矩阵;
32、根据所述特征概率矩阵对与所述特征概率矩阵对应的音频数据进行对抗学习,得到初始音频模型。
33、可选地,所述根据所述目标音频模型以及所述显示屏系统生成音频播放程序,包括:
34、将所述目标音频模型嵌入至所述显示屏系统中,得到音频控制模块;
35、生成所述音频控制模块的模块指令,利用所述模块指令对所述目标音频模型输出的识别词进行语音合成,得到语音合成命令;
36、当所述显示屏系统完成语音播报时,所述音频控制模块生成停止合成命令,得到所述音频播放程序。
37、为了解决上述问题,本发明还提供一种基于led显示屏的语音播放装置,所述装置包括:
38、声纹特征提取模块,用于获取音频样本数据,对所述音频样本数据进行声纹特征提取,得到音频数据集;
39、语音训练模块,用于根据所述音频数据集对预构建的音频模型进行语音训练,得到初始音频模型;
40、综合评价模块,用于获取测试数据,根据所述测试数据对所述初始音频模型进行综合评价,根据综合评价的结果对所述初始音频模型进行优化,得到目标音频模型;
41、音频播放程序生成模块,用于根据所述目标音频模型以及所述显示屏系统生成音频播放程序;
42、目标显示内容生成模块,用于获取待播放语音,根据所述音频播放程序对所述待播放语音进行语音解析,得到语音文件,根据所述语音文件生成目标显示内容。
43、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
44、至少一个处理器;以及,
45、与所述至少一个处理器通信连接的存储器;其中,
46、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述所述的基于led显示屏的语音播放方法。
47、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的基于led显示屏的语音播放方法。
48、本发明实施例获取音频样本数据,对音频样本数据进行声纹特征提取,得到音频数据集,可以避免音频数据在传输过程中的信号衰减,增强语音播放的准确性;获取测试数据,根据测试数据对初始音频模型进行综合评价,根据综合评价的结果对初始音频模型进行优化,可以使得目标音频模型在语音识别时的准确率符合目标阈值;根据音频播放程序对待播放语音进行语音解析,得到语音文件,根据语音文件生成目标显示内容,实现了语音播报的同时可以在显示屏上显示播报内容,完成同步播放的目的。因此本发明提出的基于led显示屏的语音播放方法、装置、设备及介质,可以解决显示屏信息与语音同步播放的准确性较低的问题。
- 还没有人留言评论。精彩留言会获得点赞!