音频和视频转换器的制作方法
本发明总体上涉及视频和音频处理。更具体地,它涉及音频转换和嘴唇复活(reanimation)。
背景技术:
1、传统的音频转换技术是极其繁琐且耗时的。经常需要一个或更多个人来听、记录、转录和转换音频。使用现有视频为转换的音频配音可能更加困难,并且通常需要大量的人力投入和干预。此外,转换的音频几乎不会与相应的视频中说话者的嘴唇动作同步。
2、因此,需要一种系统和方法来更高效和更有效地转换音频并使视频中的说话者的嘴唇复活。然而,鉴于在做出本发明时被视为整体的技术,对于本发明的领域的普通技术人员来说,如何克服现有技术的缺点并不明显。
3、所有参考的出版物通过引用完全并入本文。此外,当参考文献中术语的定义或使用与本文提供的术语的定义不一致或相反时,本文提供的术语的定义适用,参考文献中的术语的定义不适用。
4、虽然已经讨论了常规的技术的某些方面以促进本发明的公开,但是申请人绝不否认这些技术方面,并且考虑到所要求保护的发明可以包含本文讨论的一个或更多个常规的技术方面。
5、本发明可以解决上述现有技术的一个或更多个问题和缺陷。然而,预期到本发明可以证明在解决许多技术领域中的其他问题和缺陷方面是有用的。因此,所要求保护的发明不应该被解释为局限于解决本文讨论的任何特定的问题或缺陷。
6、在本说明书中,当提及或讨论文件、行为或知识项目时,这种提及或讨论并不承认该文件、行为或知识项目或其任何组合在优先权日是可公开获得的、为公众所知的、是普通的一般常识的一部分,或者在适用的法律规定下构成现有技术;或者已知与解决本说明书所涉及的任何问题的尝试相关。
技术实现思路
1、一种新的、有用的、非显而易见的发明满足了对改进的音频和视频转换器的长期但迄今未实现的需求。
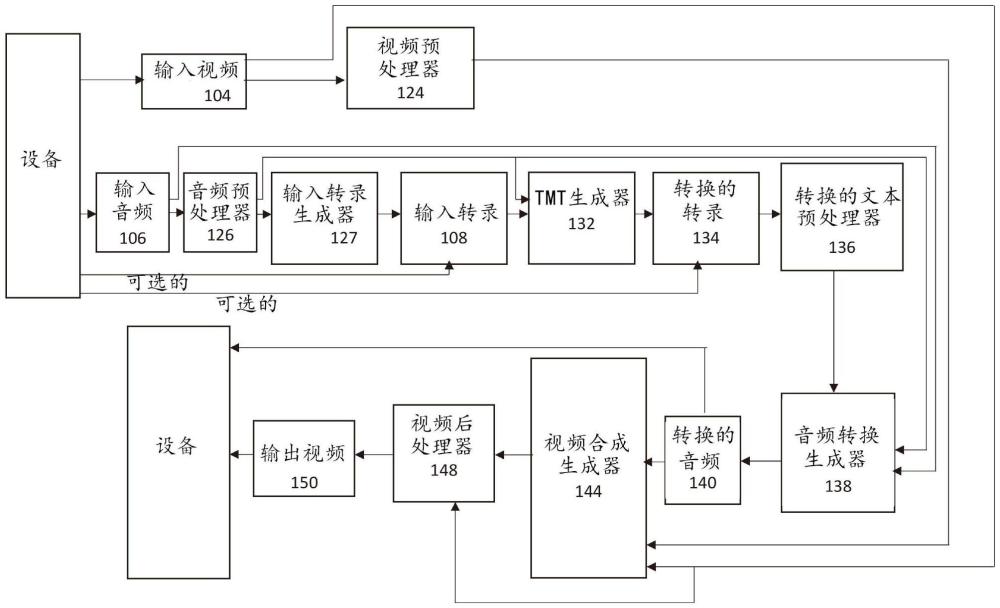
2、本发明包括用于转换媒体文件中的语音的系统和方法。该方法的实施例包括首先获取输入媒体文件。在一些实施例中,输入媒体文件是计算机可读格式的。输入媒体文件包括第一输入语言的输入音频,并且在一些实施例中包括输入视频。该方法还包括获取第一输出语言,并且第一输出语言不同于第一输入语言。
3、一些实施例还包括预处理输入音频,以将一个声音流与另一个声音流分开,减少背景噪音或增强声音流的质量。一些实施例还包括预处理输入视频以捕捉嘴唇动作跟踪数据。
4、一旦获取输入,则输入音频被分割成多个声音片段。多个声音片段中的每个包括说话者标识,以识别每个声音片段的说话者。对于多个声音片段中的每个声音片段,为每个声音片段中的每个单词或音素识别语速信息。在一些实施例中,通过配置为接收作为输入的输入媒体文件的说话者分离处理器来将输入音频分割成多个声音片段并识别定时信息。
5、新方法还包括获取输入转录。输入转录包括对应于每个声音片段中说出的单词的文本。文本转录可以根据国际音标进行格式化。此外,输入转录还可以包括对应于每个声音片段的说话者的解剖关键点(landmark)的情感分析和跟踪数据。在一些实施例中,获取输入音频的输入转录包括将输入音频提供给被配置为将输入音频转换成文本的人工智能(ai)生成器。
6、然后,获取输入元信息。该元信息包括情感数据和音调数据。情感数据对应于来自预定的情感列表的一个或更多个可检测的情感。音调数据同样可以对应于来自预定的情感列表或音调谱的一个或更多个可检测的音调。在一些实施例中,获取输入元信息包括将输入音频和输入转录提供给配置为识别元信息的人工智能元信息处理器。
7、一旦获取元数据,则至少基于定时信息和情感数据,将输入转录和输入元信息转换成第一输出语言,使得转换的转录和元信息包括与输入转录和输入元信息相似的情感和语速。在一些实施例中,相似的语速包括语音字符之间小于或等于20%的汉明距离(hamming distance)差异,以及在适当的位置包括停顿、呼吸和填充音。在一些实施例中,转换输入转录和输入元信息包括将输入转录和输入元信息提供给人工智能转录和元转换生成器,该人工智能转录和元转换生成器被配置为生成转换的转录和元信息。
8、最后,使用转换的输入转录和元信息生成转换的音频。在一些实施例中,生成转换的音频包括向被配置为生成转换的音频的人工智能音频转换生成器提供转换的转录和元信息。
9、该方法的一些实施例还包括将每个声音片段的转换的音频拼接回单个音频文件。一些实施例还包括将转换的音频和输入视频提供给视频同步生成器,并且由视频同步生成器生成同步的视频,其中,转换的音频与输入视频同步。
10、随着本公开的进行,本发明的这些和其他重要目的、优点和特征将变得清楚。
11、因此,本发明包括将在下文阐述的公开内容中举例说明的结构的特征、元素的组合和部件的布置,而且本发明的范围将在权利要求中指明。
技术特征:
1.一种用于转换媒体文件内的语音的方法,包括:
2.根据权利要求1所述的方法,其中,所述输入媒体文件是计算机可读格式的。
3.根据权利要求1所述的方法,还包括预处理输入音频,以将一个声音流与另一个声音流分开,从而减少背景噪音或增强所述声音流的质量。
4.根据权利要求1所述的方法,还包括预处理所述输入视频以捕获嘴唇动作跟踪数据。
5.根据权利要求1所述的方法,其中,由被配置为接收所述输入媒体文件作为输入的说话者分离处理器来执行将所述输入音频分割成所述多个声音片段并识别语速信息。
6.根据权利要求1所述的方法,其中,所述文本转录根据国际音标进行格式化。
7.根据权利要求1所述的方法,其中,所述输入转录还包括情绪分析和跟踪数据,所述情绪分析和跟踪数据对应于每个声音片段的所述说话者的解剖关键点。
8.根据权利要求1所述的方法,其中,获取所述输入音频的所述输入转录包括将所述输入音频提供给人工智能(ai)生成器,所述人工智能生成器被配置为将所述输入音频转换成文本。
9.根据权利要求1所述的方法,其中,获取输入元信息包括将所述输入音频和所述输入转录提供给被配置为识别元信息的人工智能元信息处理器。
10.根据权利要求1所述的方法,其中,转换所述输入转录和输入元信息包括将所述输入转录和输入元信息提供给人工智能转录和元转换生成器,所述人工智能转录和元转换生成器被配置为生成转换的转录和元信息。
11.根据权利要求1所述的方法,其中,相似的语速包括小于或等于20%的差异。
12.根据权利要求1所述的方法,其中,生成转换的音频包括向被配置为生成所述转换的音频的人工智能音频转换生成器提供所述转换的转录和元信息。
13.根据权利要求1所述的方法,还包括将每个声音片段的所述转换的音频拼接回单个音频文件。
14.根据权利要求1所述的方法,其中,所述输入媒体文件包括输入视频。
15.根据权利要求15所述的方法,还包括将所述转换的音频和所述输入视频提供给视频同步生成器,并由所述视频同步生成器生成同步的视频,其中,所述转换的音频与所述输入视频同步。
技术总结
一种用于在需要时转换音频和视频的系统和方法。转换包括使用人工智能系统生成的合成的媒体和数据。通过独特的处理器和生成器执行独特的步骤序列,该系统和方法产生更准确的转换,该转换可以考虑各种语音特征(例如,情感、语速、习语、讽刺、笑话、音调、音素等)。这些语音特征在输入媒体中被识别,并被综合地合并到转换的输出中,以反映输入媒体中的特征。一些实施例还包括处理输入视频的系统和方法,使得说话者的面部和/或嘴唇看起来好像他们正在自然地说出生成的音频。
技术研发人员:里尤尔·古普塔,艾玛·布朗
受保护的技术使用者:深度传媒有限公司
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!