语音信号处理装置、语音信号再现系统以及用于输出去情感化语音信号的方法与流程
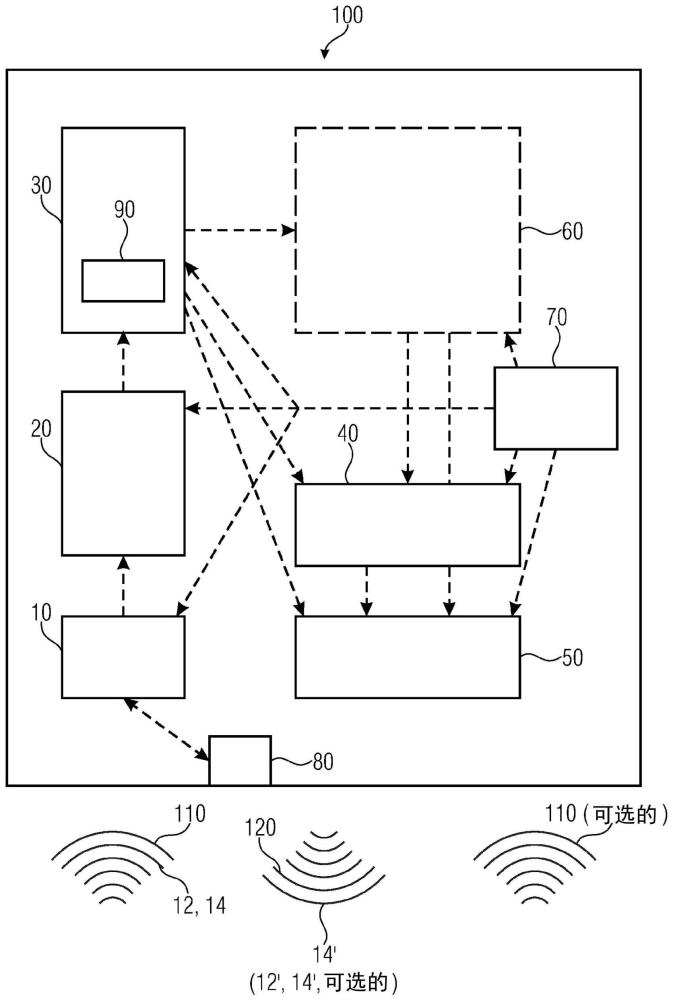
本发明涉及一种用于实时或在一段时间之后输出去情感化语音信号的语音信号处理装置、语音信号再现系统、用于实时或在一段时间之后输出去情感化语音信号的方法、以及计算机可读存储介质。
背景技术:
1、迄今为止,还没有可以解决基于语音的通信的重大问题的已知技术系统。该问题在于口语总是富含所谓的超片段特征(sf),例如语调、语速、语音中停顿的持续时间、强度或音量等。语言的不同方言也可以导致口语的发音不同,这可能给外人带来理解问题。一个示例是北德方言与南德方言的比较。语言的超片段特征是一种以音韵方式指示感受、障碍和个体特定特征的音韵特性(也参见维基百科关于“超片段特征”)。这些sf具体地向听者发送情感,但也发送改变内容的方面。然而,并不是所有人都能够以合适的方式处理这些sf或正确地解释它们。
2、例如,对于患有自闭症的人,了解其他人的情感要明显困难得多。这里,为了简单起见,以非常普遍的方式使用术语自闭症。事实上,自闭症存在不同的形式和程度(也被称为自闭症谱)。然而,为了理解本发明,不必对此进行区分。不仅情感而且经由sf嵌入语言中的内容的变化通常对于他们而言无法辨别和/或令他们感到困惑,直到他们拒绝经由语言进行沟通和使用备选方案,例如书面语言或图片卡。
3、文化差异或外语沟通也可能限制从sf获取信息或者可以导致误解。此外,扬声器所在的情况(例如,消防员直接在火源处)可能导致非常充满情感的通信(例如,带有操作命令),这使得应对该情况变得更加困难。类似问题也存在于一种特别复杂的制订语言中,该制订语言仅对于具有认知障碍的人而言难以理解,其中sf可能使得理解变得更加困难。
4、该问题已经以不同的方式面对,或者根本没有得到解决。对于自闭症患者,使用不同的备选沟通方式(仅基于文本的交互,例如通过在平板计算机上写入信息、使用图片卡等)。对于认知障碍,部分地使用所谓的“简单语言”,例如在书面通知或特定新闻节目中。迄今为止,还没有如下已知解决方案:实时改变口语,使得上述目标组能够理解该口语。
技术实现思路
1、本发明的一个目的在于提供一种语音信号处理装置、语音信号再现系统、以及能够实时输出口语的去情感化语音信号的方法。
2、该目的通过独立权利要求的主题来解决。
3、本发明的核心思想在于提供将提供有sf并且可能以特别复杂方式制订的语音信号转换为完全或部分地从sf特征释放的并且可能以简化方式制订的语音信号,以用于支持针对某些听者组、个体听者或特定聆听情况的基于语音的通信。所提出的解决方案是一种语音信号处理装置、一种语音信号再现系统、以及一种离线或实时地从分别或若干个sf释放语音信号并将该释放的信号提供给收听者或者以合适的方式存储该释放的信号以用于稍后收听的方法。这里,情感的消除可能是显著特征。
4、提出了一种用于实时或在一段时间之后输出去情感化语音信号的语音信号处理装置。语音信号处理装置包括用于检测语音信号的语音信号处理装置。语音信号包括至少一条情感信息和至少一条词语信息。另外,语音信号处理装置包括:分析装置,用于针对至少一条情感信息和至少一条词语信息分析语音信号;处理装置,用于将语音信号划分为至少一条词语信息和至少一条情感信息;以及耦合装置和/或再现装置,用于将语音信号再现为去情感化语音信号,该去情感化语音信号包括至少一条情感信息和/或至少一条词语信息,该至少一条情感信息被转换为其他词语信息。该至少一条词语信息也可以被认为是至少一条第一词语信息。该其他词语信息可以被认为是第二词语信息。这里,只要将情感信息转录为词语信息,就可以将情感信息转录为第二词语信息。这里,术语信息与术语信号同义地使用。情感信息包括超分段特征。优选地,该至少一条情感信息包括一个或若干个超分段特征。如所提出的,所检测到的情感信息或者根本不被再现,或者情感信息与原始词语信息一起也被再现为第一词语信息和第二词语信息。由此,只要将情感信息再现为其他的词语信息,收听者就可以毫无问题地理解情感信息。然而,如果情感信息不提供任何显著信息贡献,则也可以从语音信号中减去情感信息并且仅再现原始(第一)条词语信息。这里,由于分析装置被配置为识别所检测到的语音信号的哪一部分描述了词语信息以及所检测到的语音信号的哪一部分描述了情感信息,因此分析装置也可以被称为识别系统。此外,分析装置可以被配置为标识不同的扬声器。这里,去情感化语音信号意指完全或部分地从情感释放的语音信号。因此,去情感化语音信号具体地仅包括第一词语信息和/或第二词语信息,其中,一条或若干条词语信息可以基于情感信息。例如,利用机器人话音的语音合成可以导致完全消除情感。例如,还可以生成愤怒的机器人话音。语音信号中的情感的部分减少可以通过直接操纵语音音频材料来执行,例如通过减少电平动态、减少或限制基频、改变语速、改变语言的频谱内容和/或改变语音信号的韵律等。
5、语音信号还可以源自音频流(音频数据流),例如电视、收音机、播客、音频书。更接近意义上的语音信号检测装置可以被认为是“麦克风”。另外,语音信号检测装置可以被认为是允许使用例如来自上述源的一般语音信号的装置。
6、所提出的语音信号处理装置的技术实现基于分析装置对输入语音(语音信号)的分析,例如识别系统(例如,神经元网络、人工智能等),该分析装置或者已经学习基于训练数据的到目标信号的转录(端到端转录)或基于所检测到的情感的基于规则的转录,这些情感本身也可以在个体间或个体内教导给识别系统。
7、两个或更多个语音信号处理装置形成语音信号再现系统。通过语音信号再现系统,例如,提供语音信号的扬声器可以向两个或若干个听者实时提供单独适配的去情感化语音信号。这种情况的一个示例是在学校上课或在导游的引导下参观博物馆等。
8、本发明的另一方面涉及一种用于实时或在一段时间之后输出去情感化语音信号的方法。该方法包括检测语音信号,该语音信号包括至少一条词语信息和至少一条情感信息。例如,演讲者可以在一组听者面前实时提供语音信号。该方法还包括针对至少一条词语信息和至少一条情感信息分析该语音信号。必须针对其词语信息和情感信息检测语音信号。该至少一条情感信息包括至少一个超分段特征,该超分段特征将被转录为其他(具体地,第二)词语信息。因此,该方法包括:将语音信号划分为至少一条词语信息和至少一条情感信息,并且将语音信号再现为去情感化语音信号,该去情感化语音信号包括被转录为其他词语信息的至少一条情感信息和/或包括至少一条词语信息。
9、出于冗余原因,不再重复关于语音信号处理装置的术语的解释。然而,显然这些术语的解释类似地适用于该方法,反之亦然。
10、本文描述的技术教导的核心是:识别sf中包括的信息(例如,还有情感),并且该信息以口头或书面或图画的方式插入到输出信号中。例如:扬声器以非常兴奋的方式说“你拒绝接近我真是胆大妄为”可以被转录为“由于......胆大妄为,我很沮丧”。
11、本文公开的技术教导的一个优点在于:通过标识对于用户而言严重干扰的sf,将语音信号处理装置/方法单独地与用户匹配。由于个体对sf的严重程度和敏感性可能强烈地变化,这对于患有自闭症的人特别重要。例如,可以经由用户界面通过密切相关的人(例如,父母)的直接反馈或输入或者通过神经生理学测量(例如,心率变异性(hrv)或eeg)来确定个体敏感性。神经生理学测量已经在科学研究中被标识为用于由声学信号引起的压力、劳累或积极/消极情感的感知的标记,因此基本上可以用于确定sf和与上述检测器系统连接的个体障碍之间的连接。在确定这种连接之后,语音信号处理装置/方法可以减少或抑制各个特别干扰sf比例,而其他sf比例不被处理或以不同的方式被处理。
12、如果不直接操纵该语音,而是在没有sf的情况下“人工地”(即,以端到端方法)生成语音,则可以基于相同信息将所容忍的sf比例添加到该无sf信号中,和/或可以生成可以支持理解的特定sf比例。
13、本文公开的技术教导的另一优点是:除了sf部分的修改之外,去情感化信号的再现还可以适配收听者的听觉需要。例如,已知患有自闭症的人对于良好语音可理解性具有特定要求,并且例如由于录音中包括的干扰噪音,很容易从该语音信息分心。这可以例如通过干扰噪音减少来减少,其在程度方面可能是个性化的。此外,当处理语音信号时(例如,通过助听器中使用的非线性频率相关放大)可以补偿个体听力障碍,或者附加地将由sf部分减少的语音信号处理为通用的、非单独匹配的处理,这例如提高话音的清晰度或抑制干扰噪音。
14、本技术教导的一个具体潜力是在与患有自闭症的人和讲外语的人的沟通中的使用。将本文描述的语音信号自动转录为从fs比例释放的或在其fs比例方面进行修改和/或将sf比例中包括的信息映射到内容的新语音信号的方法是具有实时能力的,其缓解并改善与患有自闭症的人和/或讲外语的人或充满情感的沟通场景中的人(消防队、军队、警报激活)或具有认知障碍的人的沟通。
- 还没有人留言评论。精彩留言会获得点赞!