一种基于语音识别功能的安全带、方法和车辆与流程
本发明涉及语音识别,尤其涉及一种基于语音识别功能的安全带、方法和车辆。
背景技术:
1、智能座舱就是将车内改造成一个数字化平台,旨在集成多种i t和人工智能技术,打造全新的车内一体化数字平台,为驾驶员提供智能体验,促进行车安全,传统的汽车座舱只能够用来指示各种行车工况。
2、智能座舱的人机交互系统,主要包括以下四个方面:基于语音的交互、基于显示屏的交互、基于触觉的交互和多模式混合界面交互。现有技术中,存在以下问题,当车内乘客在与系统进行语音交互时,若车内乘客较多且车内在播放音乐,车内的噪声较多导致系统语音识别效率低,影响用户与系统的交互体验。
技术实现思路
1、为此,本发明提供一种基于语音识别功能的安全带、方法和车辆,用以克服现有技术中人机语音交互效率低的问题。
2、为实现上述目的,一方面,本发明提供一种基于语音识别功能的安全带,包括:
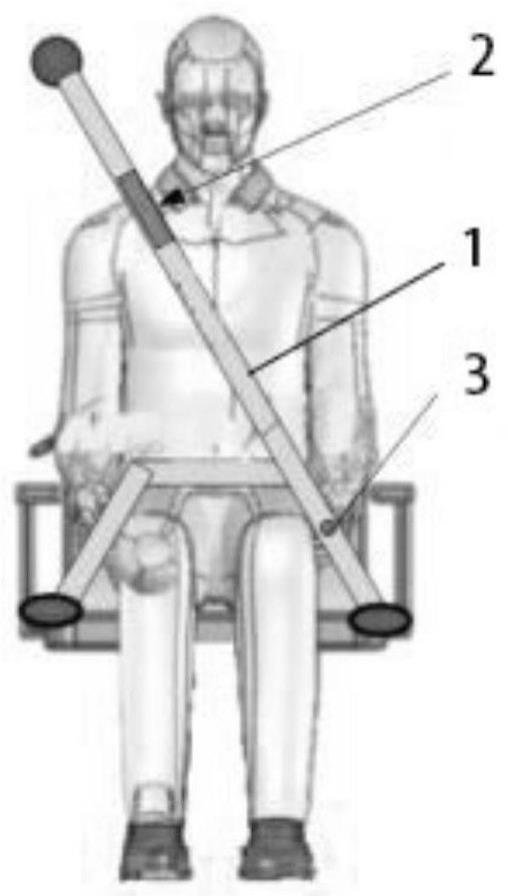
3、安全带本体,其靠近用户头部位置设有主音频设备单元,所述主音频设备单元用以采集用户的交互语音,还用以向用户输出交互语音,所述安全带本体靠近卡口一侧设有副麦克单元,所述副麦克单元用以采集环境音。
4、进一步地,所述主音频设备单元包括:壳体,其一侧设有扬声器,所述扬声器用以向用户进行音频输出,所述扬声器的上方设有按键组件,所述按键组件用以控制扬声器的开闭及扬声器的音量,所述壳体上远离扬声器的一侧设有主麦克,所述主麦克用以采集用户交互时的语音,所述扬声器的下方设有耳机插孔,所述耳机插孔用以插入耳机,所述扬声器的底面与第一电路板连接,所述第一电路板与传输线连接。
5、进一步地,所述副麦克单元包括:副麦克组件,其内部设有第二电路板,所述第二电路板的上方设有副麦克。
6、进一步地,所述安全带在进行语音输入时,通过所述主麦克采集用户语音,通过所述副麦克采集座椅周围环境语音,并将采集的各类语音均传输至音频编解码器,并将音频编解码器处理后的数字信号传输至mcu微处理器进行处理,处理后通过a2b数据传输芯片将信号通过a2b协议数据传输线传输给智能座舱域控制器cdc,以进行信号处理。
7、进一步地,所述安全带在向用户进行语音反馈时,由所述智能座舱域控制器cdc通过所述a2b协议数据传输线将数字音频数据传输给所述音频编解码器,通过音频编解码器进行数字模拟转换后,由放大器放大并经过所述扬声器输出。
8、另一方面,本发明还提供一种应用于基于语音识别功能的安全带的语音识别方法,包括:
9、步骤s11:获取主麦克采集的混合语音信号fo和副麦克采集的混合语音信号f i;
10、步骤s12:去除混合语音信号fo和f i中的汽车音响信号;
11、步骤s13:将与智能座舱域控制器cdc输出的音源相减混合后的混合语音信号fj与fk进行相减混合,得到准目标语音信号fe;
12、步骤s14:对所述准目标语音信号fe进行幅度调节,调节后得到目标语音信号fa。
13、进一步地,所述步骤s12中,分别将混合语音信号fo和f i与经过信号幅度自适应处理的智能座舱域控制器cdc输出的音源进行相减混合,主麦克采集的混合语音信号在相减混合后为fj,副麦克采集的混合语音信号在相减混合后为fk。
14、另一方面,本发明还提供一种应用于基于语音识别功能的安全带的主动降噪方法,包括:
15、步骤s21:将智能座舱域控制器cdc输出的数字音源fc在dsp中进行幅度自适应调整;
16、步骤s22:将调整后的数字音源fc与副麦克采集的混合音源f i进行相减混合,以去除混合音源f i中与数字音源fc频率相同的汽车音响发出的音频分量,并得到噪音音源fb分量;
17、步骤s23:通过dsp生成反向的噪音音源fab,并将反向的噪音音源fab与数字音源fc的反向波形音源fac相加混合后生成音源fae;
18、步骤s24:通过扬声器对音源fae进行播放,音源fae与空中没有混合的音频参考音f i进行混合,得到音源fag;
19、步骤s25:获取主麦克采集的音源fag的幅值v对音源进行调整。
20、进一步地,所述步骤s25中,将音源fag的幅值v与预设幅值|δv|进行比对,当v>|δv|时,生成反向音源fah,当v≤|δv|时,不进行调整。
21、另一方面,本发明还提供一种应用于基于语音识别功能的安全带的车辆,包括:
22、多个安装所述安全带的座椅,各座椅上的安全带通过a2b总线串联形式连接,以使车辆每个座椅区域形成单独音区。
23、与现有技术相比,本发明的有益效果在于,本发明可有效提高语音识别的识别率,同时本发明对于车内各个用户的乘坐区域内进行了声音分割,使车内每个用户都有独立的音区,在音区范围能可以有效提高语音的识别效果,同时还可以使车内任何位置的用户均具有相同的语音交互体验,本发明还可使用户对音区内进行主动降噪,来降低来自其它音区的干扰,给用户带来良好的交互体验和优越静谧性,且本发明所述安全带上的麦克靠近人口处,位置相对身体固定,不会因为人体扭动或是座椅调整而距离发生太大变化,保证了麦克接收的输入信号质量高且稳定。
24、尤其,本发明所述安全带通过设置主音频设备单元和副麦克单元对区域内用户的交互语音进行采集,可提高语音采集的精确度,同时通过在车辆的各座椅均安装所述安全带,可使不同座椅形成不同音区,提高各音区内用户的语音识别效率,且可使车载系统准确区分交互时用户的位置,同时可有效降低其他区域用户的干扰,从而提高语音交互时的语音识别效率,且本发明在进行语音识别时,通过所述安全带可准确获取用户区域内的不同音源,并对不同音源进行音源混合相减,从而准确识别出交互用户的语音信息,可有效滤除语音交互中的杂音,从而提高语音识别的精确度和效率,且本发明所述安全带通过设置主动降噪功能,可有效降低用户区域内的噪音,从而提高用户体验。
技术特征:
1.一种基于语音识别功能的安全带,其特征在于,包括:
2.根据权利要求1所述的基于语音识别功能的安全带,其特征在于,所述主音频设备单元包括:壳体,其一侧设有扬声器,所述扬声器用以向用户进行音频输出,所述扬声器的上方设有按键组件,所述按键组件用以控制扬声器的开闭及扬声器的音量,所述壳体上远离扬声器的一侧设有主麦克,所述主麦克用以采集用户交互时的语音,所述扬声器的下方设有耳机插孔,所述耳机插孔用以插入耳机,所述扬声器的底面与第一电路板连接,所述第一电路板与传输线连接。
3.根据权利要求2所述的基于语音识别功能的安全带,其特征在于,所述副麦克单元包括:副麦克组件,其内部设有第二电路板,所述第二电路板的上方设有副麦克。
4.根据权利要求3所述的基于语音识别功能的安全带,其特征在于,所述安全带在进行语音输入时,通过所述主麦克采集用户语音,通过所述副麦克采集座椅周围环境语音,并将采集的各类语音均传输至音频编解码器,并将音频编解码器处理后的数字信号传输至mcu微处理器进行处理,处理后通过a2b数据传输芯片将信号通过a2b协议数据传输线传输给智能座舱域控制器cdc,以进行信号处理。
5.根据权利要求4所述的基于语音识别功能的安全带,其特征在于,所述安全带在向用户进行语音反馈时,由所述智能座舱域控制器cdc通过所述a2b协议数据传输线将数字音频数据传输给所述音频编解码器,通过音频编解码器进行数字模拟转换后,由放大器放大并经过所述扬声器输出。
6.一种应用于如权利要求1-5任一项所述的基于语音识别功能的安全带的语音识别方法,其特征在于,包括:
7.根据权利要求6所述的语音识别方法,其特征在于,所述步骤s12中,分别将混合语音信号fo和fi与经过信号幅度自适应处理的智能座舱域控制器cdc输出的音源进行相减混合,主麦克采集的混合语音信号在相减混合后为fj,副麦克采集的混合语音信号在相减混合后为fk。
8.一种应用于如权利要求1-5任一项所述的基于语音识别功能的安全带的主动降噪方法,其特征在于,包括:
9.根据权利要求8所述的主动降噪方法,其特征在于,所述步骤s25中,将音源fag的幅值v与预设幅值|δv|进行比对,当v>|δv|时,生成反向音源fah,当v≤|δv|时,不进行调整。
10.一种应用于如权利要求1-5任一项所述的基于语音识别功能的安全带的车辆,其特征在于,包括:
技术总结
本发明涉及一种基于语音识别功能的安全带、方法和车辆,尤其涉及语音识别技术领域,包括安全带本体,其靠近用户头部位置设有主音频设备单元,所述主音频设备单元用以采集用户的交互语音,还用以向用户输出交互语音,所述安全带本体靠近卡口一侧设有副麦克单元,所述副麦克单元用以采集环境音,所述主音频设备单元包括:壳体,其一侧设有扬声器,所述扬声器用以向用户进行音频输出,所述扬声器的上方设有按键组件,所述按键组件用以控制扬声器的开闭及扬声器的音量,所述壳体上远离扬声器的一侧设有主麦克,所述主麦克用以采集用户交互时的语音,所述扬声器的下方设有耳机插孔。本发明有效提高了人机交互的语音识别效率。
技术研发人员:宋太威,赵永航,雷超,韩冰,齐林,陈鹏,高建龙,焦博涵,宋宪磊
受保护的技术使用者:中国第一汽车股份有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!