基于拼音对齐算法的语音识别多模型结果合并方法及装置与流程
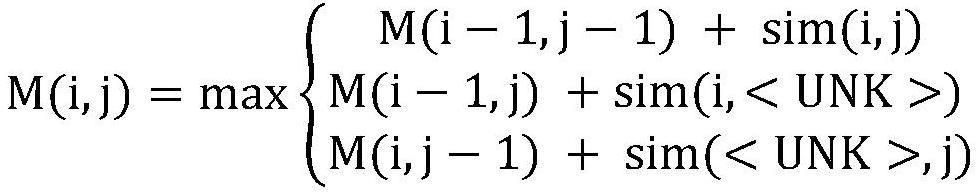
本发明涉及语音识别,尤其是涉及基于拼音对齐算法的语音识别多模型结果合并方法及装置。
背景技术:
1、近年来,在深度学习技术的持续发展推动下,端到端的语音识别技术大放异彩。国内语音识别技术领先的单位,在汉语语音识别的通用场景识别技术研发上,投入了巨大的人力和财力,并且在绝大部分通用场景下都能取得令人满意的识别准确率。但是,在实际的业务场景落地之中,中小公司很难直接使用大公司开源的语音识别引擎,往往需要利用大公司开源的语音识别引擎对语料进行预标注后,再进行人工标注,然后再训练模型。但是,单一的预标注结果往往会有比较大的偏差,在工业界,通常都会采用融合多模型的标注结果来提高整体的准确率。因此,在冷启动阶段,如果能同时利用多方开源的识别引擎,可以提升预标注的质量。由此,亟需一种低成本的多模型结果合并方法。
技术实现思路
1、为解决现有技术的不足,实现提升语料预标注质量的目的,本发明采用如下的技术方案:
2、基于拼音对齐算法的语音识别多模型结果合并方法,包括如下步骤:
3、步骤s1:构建业务领域范围内的拼音-汉字的映射数据对;
4、步骤s2:基于拼音-汉字的映射数据对,训练拼音翻译汉字模型;
5、步骤s3:利用至少两种不同的语音识别模型生成两种不同的文本序列,分别转化为对应的两种不同的拼音序列;
6、步骤s4:利用拼音对齐算法,对齐2种不同的拼音序列,得到一个候选拼音对齐序列,包括如下步骤:
7、步骤s4.1:以尼德曼-翁施算法为基础,以最大化局部相似性为原则,利用动态规划的思想,构建待对齐拼音序列的相似度矩阵;
8、步骤s4.2:利用贪心的思想,从相似度矩阵中找到一条最优对齐路径,并根据设定的拼音生成规则,生成候选拼音对齐序列;
9、步骤s5:利用训练好的拼音翻译汉字模型,将已对齐的候选拼音对齐序列映射为汉字序列。
10、进一步地,所述步骤s1中,映射方式是建立汉字到拼音的映射表,将文本数据映射转写为对应的拼音序列,同时保留声母、韵母和音调;所述步骤s3中,映射方式是基于所述汉字到拼音的映射表,将文本数据映射转写为对应的拼音序列,同时标注出声母、韵母和音调。
11、进一步地,所述步骤s1中的映射表,是规整好词组到拼音的映射表。
12、进一步地,所述步骤s4.1中,拼音序列相似度分数的计算规则为同一位置的相似度累计和,两个序列的相似度计算公式为其中长度更长的序列默认为冗余度更高的,即将短序列向长序列对齐:
13、max(len(a),len(b))
14、
15、其中a、b分别表示进行相似度比较的两个拼音序列,score(·)表示相似度分数,sim(·)表示相似度函数,len(·)表示长度获取函数。
16、进一步地,基于短序列向长序列对齐,在短序列对应位置添加<unk>,构建相似度矩阵m,基于相似度矩阵,寻找一条最符合目标的对齐路径;
17、相似度矩阵各个位置的动态转移方程为:
18、
19、其中m(i,j)表示拼音序列a(a1,a2...ai)和拼音序列b(b1,b2...bj)对齐后的序列最大相似度,i、j分别表示拼音序列a、b的长度序数。
20、进一步地,基于相似度分数,构建相似度分数表,以拼音序列a为行,拼音序列b为列,按序列逐一配对拼音并填充相似度分数,其中路径的方向为:向右,向下,斜角;
21、向右,对应操作即为序列b新增一个<unk>,记为路径操作0;
22、向下,对应操作即为序列a新增一个<unk>,记为路径操作1;
23、斜角,对应操作即为序列a,序列b保留当前位置字符不变,记为路径操作2;
24、最优路径寻找如下:
25、1)在当前节点,总是选择往分值最大的方向前进;
26、2)在当前节点,若三个方向的分值均相同,总是选择向右移动,即总是倾向于在短序列上新增<unk>。
27、进一步地,所述步骤s4.2中,对于不同拼音序列中对应的两个拼音,其相似度计算规则如下:
28、1)若两个拼音的声母、韵母、音调均一致;
29、2)若两个拼音的声母、韵母均一致,但音调不一致;
30、3)若两个拼音的声母一致,但韵母不一致;
31、4)若两个拼音的韵母一致,但声母不一致;
32、5)若两个拼音的声母、韵母均不一致,但声母或者韵母互为混淆对;
33、6)若两个拼音的声母、韵母均不一致,且声母和韵母均不存在混淆对;
34、上述相似度计算规则对应的相似度分数,依次递减。
35、进一步地,易混淆的声母对定义如下:
36、(b,d)/(p,q)/(f,t)/(z,zh)/(c,ch)/(s,sh)
37、易混淆的韵母对定义如下:
38、(an,ang)/(en,eng)/(in,ing)/(un,ui)/(ei,ai)。
39、进一步地,所述步骤s4.2中,生成的候选拼音规则如下:
40、1)若两个拼音的声母、韵母、音调均一致,则保持原有拼音;
41、2)若两个拼音的声母、韵母一致,但音调不一致,则去掉音调,保持声母和韵母;
42、3)若两个拼音的声母一致,韵母不一致,则仅保留声母;
43、4)若两个拼音的韵母一致,但声母不一致,则仅保留韵母;
44、5)若两个拼音的声母、韵母均不一致,则返回<unk>。
45、基于拼音对齐算法的语音识别多模型结果合并装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现所述的基于拼音对齐算法的语音识别多模型结果合并方法。
46、本发明的优势和有益效果在于:
47、本发明的基于拼音对齐算法的语音识别多模型结果合并方法及装置,能够利用多个语音模型的结果,融合生成一个合并的结果,为语音模型的融合提供了一种新的思路,并且是有成效的;在冷启动数据标注阶段,能够充分利用开源已有的模型的识别结果,对多个结果进行融合,能够有效提高模型预测的准确率,降低冷启动标注阶段的标注成本。
技术特征:
1.基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于包括如下步骤:
2.根据权利要求1所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:所述步骤s1中,映射方式是建立汉字到拼音的映射表,将文本数据映射转写为对应的拼音序列,同时保留声母、韵母和音调;所述步骤s3中,映射方式是基于所述汉字到拼音的映射表,将文本数据映射转写为对应的拼音序列,同时标注出声母、韵母和音调。
3.根据权利要求2所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:所述步骤s1中的映射表,是规整好词组到拼音的映射表。
4.根据权利要求1所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:所述步骤s4.1中,采用拼音序列相似度分数的计算规则,对同一位置的相似度累计和,两个序列的相似度计算公式为其中长度更长的序列默认为冗余度更高的,即将短序列向长序列对齐:
5.根据权利要求4所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:基于短序列向长序列对齐,在短序列对应位置添加<unk>,构建相似度矩阵m,基于相似度矩阵,寻找一条最符合目标的对齐路径;
6.根据权利要求5所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:基于相似度分数,构建相似度分数表,以拼音序列a为行,拼音序列b为列,按序列逐一配对拼音并填充相似度分数,其中路径的方向为:向右,向下,斜角;
7.根据权利要求2所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:所述步骤s4.2中,对于不同拼音序列中对应的两个拼音,其相似度计算规则如下:
8.根据权利要求7所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:易混淆的声母对定义如下:
9.根据权利要求2所述的基于拼音对齐算法的语音识别多模型结果合并方法,其特征在于:所述步骤s4.2中,生成的候选拼音规则如下:
10.基于拼音对齐算法的语音识别多模型结果合并装置,其特征在于,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现权利要求1-9中任一项所述的基于拼音对齐算法的语音识别多模型结果合并方法。
技术总结
本发明公开了基于拼音对齐算法的语音识别多模型结果合并方法及装置,通过构建业务领域范围内的拼音‑汉字的映射数据对,并基于拼音‑汉字的映射数据对,训练拼音翻译汉字模型;利用至少两种不同的语音识别模型生成的文本序列,分别转化为对应的拼音序列;再利用拼音对齐算法,对齐不同的拼音序列,得到候选拼音对齐序列;以最大化局部相似性为原则,利用动态规划的思想,构建待对齐拼音序列的相似度矩阵;利用贪心的思想,从相似度矩阵中找到一条最优对齐路径,并根据相似度计算规则,生成候选拼音对齐序列;最后,通过训练好的拼音翻译汉字模型,将候选拼音对齐序列映射为汉字序列。
技术研发人员:陶金,陈禹,汪健
受保护的技术使用者:杭州健海科技有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!