音频的转换方法、装置、计算机设备和存储介质与流程
本技术涉及人工智能,特别是涉及一种音频的转换方法、装置、计算机设备和存储介质。
背景技术:
1、目前,为了便于目标用户理解业务操作,目标用户在操作业务设备的业务页面时,业务设备通过业务页面的文字、以及交易音频与目标用户进行人机交互。其中,业务设备中预先存储有待输出音频。在响应于目标用户的业务操作请求时,业务设备基于待输出音频输出交易音频。
2、然而,预先存储的待输出音频的音频参数(如声调、音量、以及音色等)是固定的,导致基于待输出音频输出的交易音频比较单一、交互效果较差。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够使待输出音频匹配目标用户的实时情绪,提高交互效果的音频的转换方法、装置、计算机设备、计算机可读存储介质和计算机程序产品。
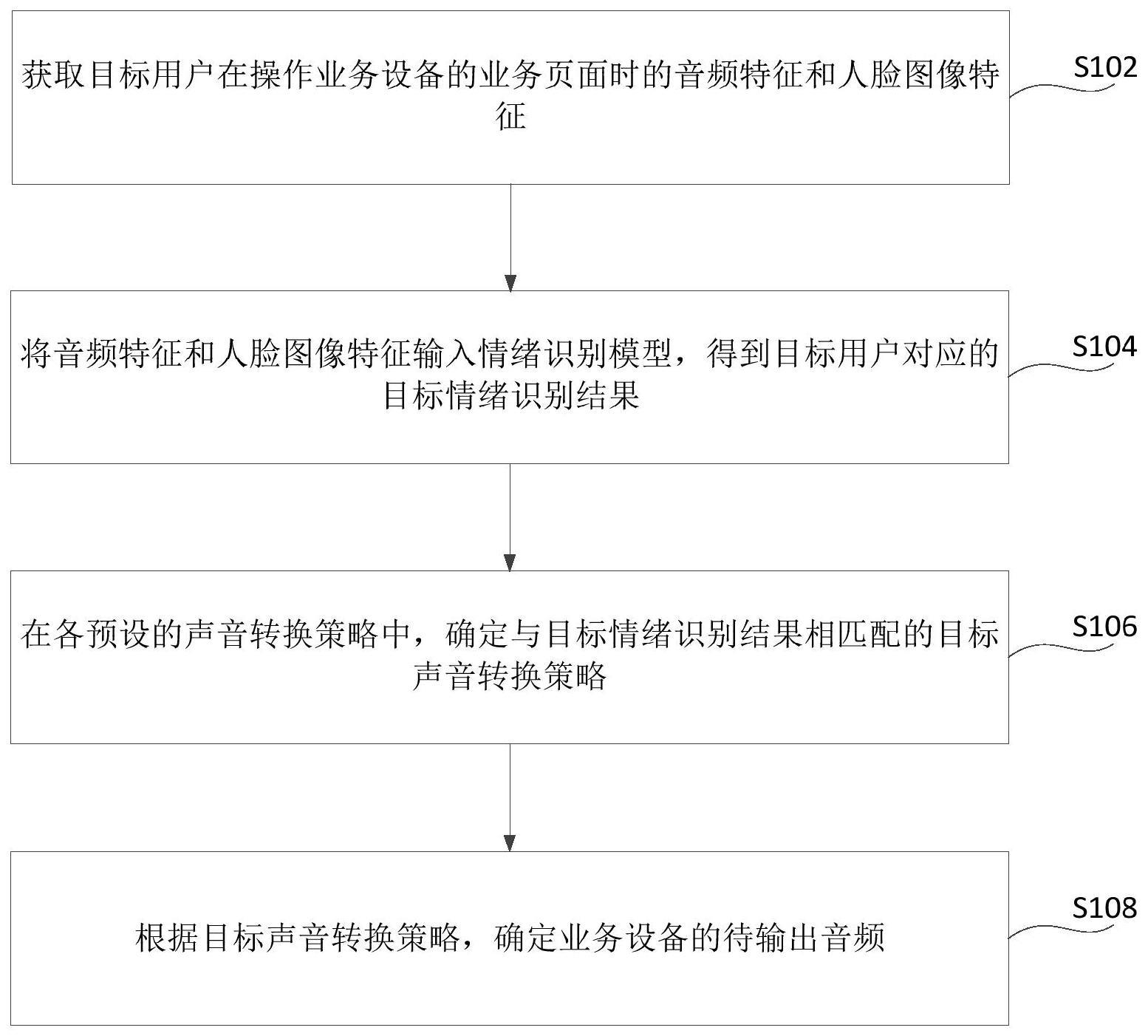
2、第一方面,本技术提供了一种音频的转换方法。所述方法包括:
3、获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征;
4、将所述音频特征和所述人脸图像特征输入情绪识别模型,得到所述目标用户对应的目标情绪识别结果;
5、在各预设的声音转换策略中,确定与所述目标情绪识别结果相匹配的目标声音转换策略;
6、根据所述目标声音转换策略,确定所述业务设备的待输出音频。
7、在其中一个实施例中,所述情绪识别模型包括人脸图像识别子模型、音频识别子模型、以及融合识别子模型;所述将所述音频特征和所述人脸图像特征输入情绪识别模型,得到所述目标用户对应的目标情绪识别结果包括:
8、将所述音频特征输入至所述音频识别子模型,得到音频情绪识别结果;
9、将所述人脸图像特征输入至所述人脸图像识别子模型,得到图像情绪识别结果;
10、将所述音频情绪识别结果、以及所述图像情绪识别结果输入至所述融合识别子模型,得到目标情绪识别结果。
11、在其中一个实施例中,所述人脸图像识别子模型包括残差网络、多个第一双重注意力机制、第一长短期记忆网络、第一拼接层、以及第一情绪识别网络;所述将所述人脸图像特征输入至所述人脸图像识别子模型,得到图像情绪识别结果包括:
12、将所述人脸图像特征输入至包含多个残差子网络的所述残差网络,得到每个所述残差子网络输出的图像语义特征、以及所述残差网络输出的目标图像语义特征;其中,在所述残差网络中除最后一个残差子网络之外的残差子网络的输出是下一个的残差子网络的输入;
13、针对每个所述图像语义特征,将所述图像语义特征输入至所述第一双重注意力机制,得到所述图像语义特征对应的图像加权特征;
14、将各所述图像加权特征分别输入至所述第一长短期记忆网络中对应的输入神经元,得到图像上下文特征;
15、将所述图像上下文特征、以及所述目标图像语义特征输入至所述第一拼接层,得到图像融合特征;
16、将所述图像融合特征输入至所述第一情绪识别网络,得到图像情绪识别结果。
17、在其中一个实施例中,所述音频识别子模型包括第二双重注意力机制、第二长短期记忆网络、以及第二情绪识别网络;所述将所述音频特征输入至所述音频识别子模型,得到音频情绪识别结果包括:
18、将所述音频特征输入至所述第二双重注意力机制,得到所述音频加权特征;
19、将所述音频加权特征输入至所述第二长短期记忆网络中,得到音频上下文特征;
20、将所述音频上下文特征输入至所述第二情绪识别网络,得到音频情绪识别结果。
21、在其中一个实施例中,所述获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征包括:
22、在达到特征提取的触发条件的情况下,获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征。
23、在其中一个实施例中,所述在达到特征提取的触发条件的情况下,获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征包括:
24、获取业务设备的待输出音频的已确定次数;
25、在所述已确定次数属于第一预设区间的情况下,获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征;
26、在所述已确定次数属于预设第二区间、且当前的目标声音转换策略与上一次目标声音转换策略不相同的情况下,获取所述目标用户在操作所述业务设备的业务页面时的音频特征和人脸图像特征;其中,所述第一预设区间的上限值小于所述第二预设区间的下限值。
27、在其中一个实施例中,所述获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征包括:
28、获取目标用户在操作业务设备的业务页面时的音频数据和人脸图像;
29、确定所述音频数据的梅尔频率倒谱系数,得到音频特征;
30、根据预设的分割策略,对所述人脸图像进分割,得到各人脸子图像,并根据预设的缩放策略,对所述人脸子图像进行缩放,得到人脸图像特征。
31、在其中一个实施例中,所述目标情绪识别结果包括积极情绪概率和消极情绪概率;所述在各预设的声音转换策略中,确定与所述目标情绪识别结果相匹配的目标声音转换策略包括:
32、计算所述积极情绪概率与所述消极情绪概率的差异度;
33、在所述差异度大于或者等于预设差异度阈值的情况下,若所述消极情绪概率大于所述积极情绪概率,则将重度消极情绪对应的声音转换策略作为目标声音转换策略;
34、在所述差异度小于所述预设差异度阈值的情况下,基于消极情绪概率、积极情绪概率以及声音转换策略的映射关系,确定与所述目标情绪识别结果包含的积极情绪概率和消极情绪概率相匹配的目标声音转换策略。
35、在其中一个实施例中,所述方法还包括:
36、在所述差异度大于或者等于预设差异度阈值的情况下,若所述积极情绪概率大于所述消极情绪概率,则保持当前的声音转换策略不变。
37、第二方面,本技术还提供了一种音频的转换装置。所述装置包括:
38、第一获取模块,用于获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征;
39、第一确定模块,用于将所述音频特征和所述人脸图像特征输入情绪识别模型,得到所述目标用户对应的目标情绪识别结果;
40、第二确定模块,用于在各预设的声音转换策略中,确定与所述目标情绪识别结果相匹配的目标声音转换策略;
41、第三确定模块,用于根据所述目标声音转换策略,确定所述业务设备的待输出音频。
42、在其中一个实施例中,所述情绪识别模型包括人脸图像识别子模型、音频识别子模型、以及融合识别子模型;所述第一确定模块具体用于:
43、将所述音频特征输入至所述音频识别子模型,得到音频情绪识别结果;
44、将所述人脸图像特征输入至所述人脸图像识别子模型,得到图像情绪识别结果;
45、将所述音频情绪识别结果、以及所述图像情绪识别结果输入至所述融合识别子模型,得到目标情绪识别结果。
46、在其中一个实施例中,所述人脸图像识别子模型包括残差网络、多个第一双重注意力机制、第一长短期记忆网络、第一拼接层、以及第一情绪识别网络;所述第一确定模块具体用于:
47、将所述人脸图像特征输入至包含多个残差子网络的所述残差网络,得到每个所述残差子网络输出的图像语义特征、以及所述残差网络输出的目标图像语义特征;其中,在所述残差网络中除最后一个残差子网络之外的残差子网络的输出是下一个的残差子网络的输入;
48、针对每个所述图像语义特征,将所述图像语义特征输入至所述第一双重注意力机制,得到所述图像语义特征对应的图像加权特征;
49、将各所述图像加权特征分别输入至所述第一长短期记忆网络中对应的输入神经元,得到图像上下文特征;
50、将所述图像上下文特征、以及所述目标图像语义特征输入至所述第一拼接层,得到图像融合特征;
51、将所述图像融合特征输入至所述第一情绪识别网络,得到图像情绪识别结果。
52、在其中一个实施例中,所述音频识别子模型包括第二双重注意力机制、第二长短期记忆网络、以及第二情绪识别网络;所述第一确定模块具体用于:
53、将所述音频特征输入至所述第二双重注意力机制,得到所述音频加权特征;
54、将所述音频加权特征输入至所述第二长短期记忆网络中,得到音频上下文特征;
55、将所述音频上下文特征输入至所述第二情绪识别网络,得到音频情绪识别结果。
56、在其中一个实施例中,所述第一获取模块具体用于:
57、在达到特征提取的触发条件的情况下,获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征。
58、在其中一个实施例中,所述第一获取模块具体用于:
59、获取业务设备的待输出音频的已确定次数;
60、在所述已确定次数属于第一预设区间的情况下,获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征;
61、在所述已确定次数属于预设第二区间、且当前的目标声音转换策略与上一次目标声音转换策略不相同的情况下,获取所述目标用户在操作所述业务设备的业务页面时的音频特征和人脸图像特征;其中,所述第一预设区间的上限值小于所述第二预设区间的下限值。
62、在其中一个实施例中,所述第一获取模块具体用于:
63、获取目标用户在操作业务设备的业务页面时的音频数据和人脸图像;
64、确定所述音频数据的梅尔频率倒谱系数,得到音频特征;
65、根据预设的分割策略,对所述人脸图像进分割,得到各人脸子图像,并根据预设的缩放策略,对所述人脸子图像进行缩放,得到人脸图像特征。
66、在其中一个实施例中,所述目标情绪识别结果包括积极情绪概率和消极情绪概率;所述第二确定模块具体用于:
67、计算所述积极情绪概率与所述消极情绪概率的差异度;
68、在所述差异度大于或者等于预设差异度阈值的情况下,若所述消极情绪概率大于所述积极情绪概率,则将重度消极情绪对应的声音转换策略作为目标声音转换策略;
69、在所述差异度小于所述预设差异度阈值的情况下,基于消极情绪概率、积极情绪概率以及声音转换策略的映射关系,确定与所述目标情绪识别结果包含的积极情绪概率和消极情绪概率相匹配的目标声音转换策略。
70、在其中一个实施例中,所述第二确定模块还用于:
71、在所述差异度大于或者等于预设差异度阈值的情况下,若所述积极情绪概率大于所述消极情绪概率,则保持当前的声音转换策略不变。
72、第三方面,本技术还提供了一种计算机设备。所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以第一方面所述的步骤。
73、第四方面,本技术还提供了一种计算机可读存储介质。所述计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以第一方面所述的步骤。
74、第五方面,本技术还提供了一种计算机程序产品。所述计算机程序产品,包括计算机程序,该计算机程序被处理器执行时以第一方面所述的步骤。
75、上述音频的转换方法、装置、计算机设备、存储介质和计算机程序产品,通过获取目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征;将音频特征和人脸图像特征输入情绪识别模型,得到目标用户对应的目标情绪识别结果;在各预设的声音转换策略中,确定与目标情绪识别结果相匹配的目标声音转换策略;根据目标声音转换策略,确定业务设备的待输出音频。上述方案中,根据音频特征、人脸图像特征、情绪识别模型、以及各预设的声音转换策略,确定目标声音转换策略,并根据该目标声音转换策略确定业务设备的待输出音频。也就是说,本方案可以根据目标用户在操作业务设备的业务页面时的音频特征和人脸图像特征,来实时转换业务设备的待输出音频,因此,待输出音频匹配目标用户的实时情绪,交互效果好。
- 还没有人留言评论。精彩留言会获得点赞!