音频数据处理方法、设备及存储介质与流程
本技术涉及一种音频数据处理方法、设备及存储介质,属于音频处理。
背景技术:
1、声纹鉴定又称语声鉴定,是指对有声言语进行个人识别的专门技术。通过声纹鉴定技术可以将目标人物的语音数据转换成条带状或曲线形语谱图(即声纹),之后相关鉴定专家可以根据语谱图所反映的音频、音强与时间等声纹特征信息,就目标人物的身份做出鉴别与判断。
2、在声纹鉴定场景中,需要从音频数据中提取出特征数据以供相关鉴定专家进行分析。传统的特征数据提取过程包括以下两种实现方式:
3、(1)采用c++语言对语音数据的处理,通过winform研发桌面端应用。
4、(2)采用c++语言对语音数据的处理,将处理数据转换到web前端。
5、无论哪种方式,采用c++语言对音频的处理需要将音频文件加载至内存,在内存中进行信号处理计算,从而提升计算的性能。但是,若音频文件很大,且桌面端应用同时打开的窗口较多,而每个窗口还要额外占据内存存储计算得到的特征数据,则会导致消耗大量的内存资源的问题。比如:桌面端应用同时打开4个窗口,每个窗口对应的音频文件大小为1g大小的音频文件,此时将四个文件都加载到内存需要4g以上的内存,而计算得到的特征数据还需要额外占用内存空间,大概总共8g大小的内存空间,此时,消耗的内存资源较多,同时打开多个文件,可能会引起系统的崩溃。
技术实现思路
1、本技术提供了一种音频数据处理方法、设备及存储介质,可以解决将音频文件全部加载至内存进行计算导致内存消耗较大,容易导致系统崩溃的问题。本技术提供如下技术方案:
2、第一方面,提供一种音频数据处理方法,所述方法包括:
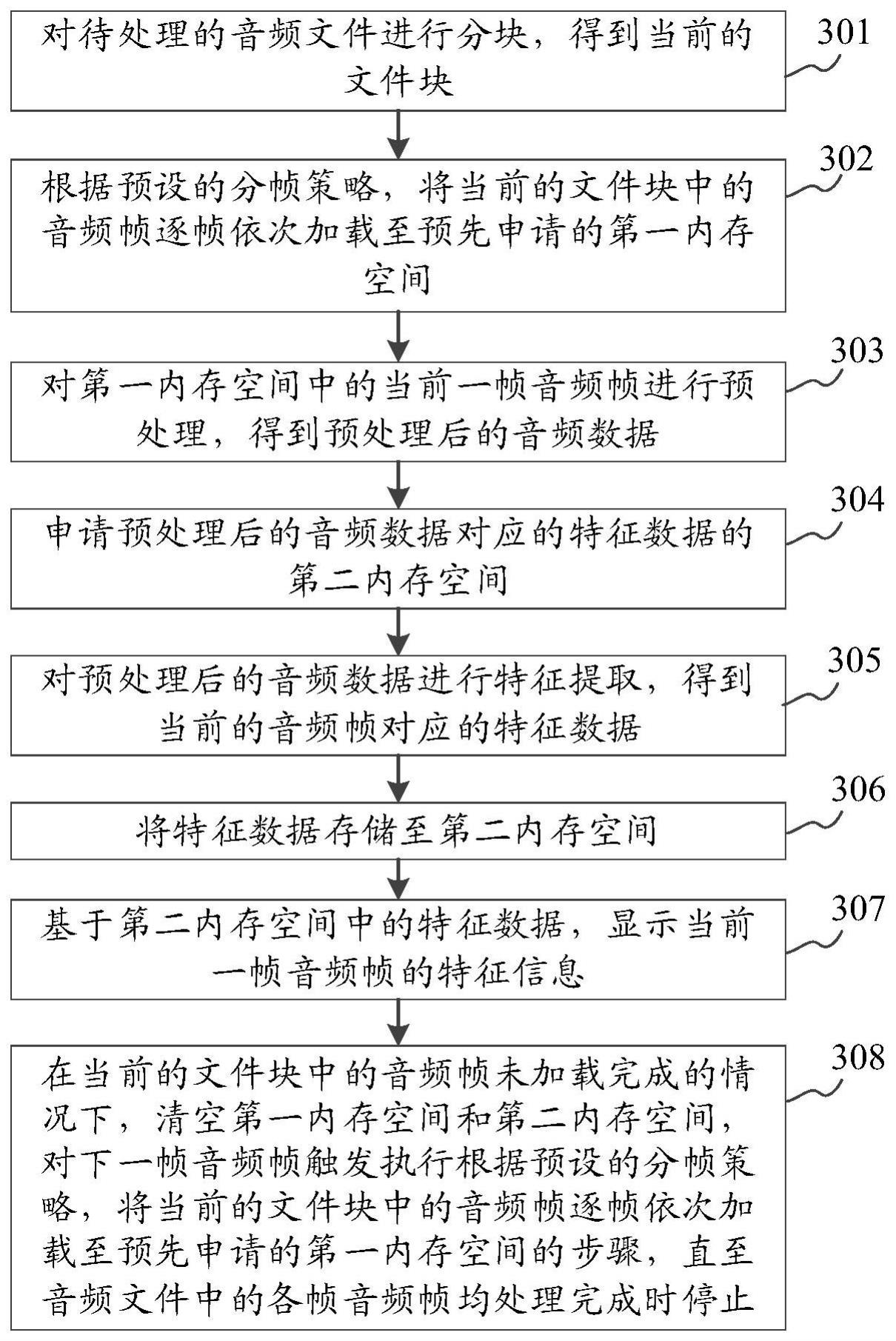
3、对待处理的音频文件进行分块,得到当前的文件块;
4、根据预设的分帧策略,将所述当前的文件块中的音频帧逐帧依次加载至预先申请的第一内存空间;
5、对所述第一内存空间中的当前一帧音频帧进行预处理,得到预处理后的音频数据;
6、申请所述预处理后的音频数据对应的特征数据的第二内存空间;
7、对所述预处理后的音频数据进行特征提取,得到所述当前的音频帧对应的特征数据;
8、将所述特征数据存储至所述第二内存空间;
9、基于所述第二内存空间中的特征数据,显示所述当前一帧音频帧的特征信息;
10、在所述当前的文件块中的音频帧未加载完成的情况下,清空所述第一内存空间和所述第二内存空间,对下一帧音频帧触发执行所述根据预设的分帧策略,将所述当前的文件块中的音频帧逐帧依次加载至预先申请的第一内存空间的步骤,直至所述音频文件中的各帧音频帧均处理完成时停止。
11、可选地,所述对待处理的音频文件进行分块,得到当前的文件块,包括:
12、通过文件系统模块以文件流的方式从所述音频文件中读取预设大小的音频数据;
13、将所述预设大小的音频数据加载至内存,得到所述当前的文件块。
14、可选地,在所述当前的文件块中的音频帧加载完成的情况下,所述方法还包括:
15、确定所述音频文件是否读取完成;
16、在未读取完成的情况下,对于所述音频文件中未读取的数据,再次触发执行所述通过文件系统模块以文件流的方式从所述音频文件中读取预设大小的音频数据;将所述预设大小的音频数据加载至内存,得到所述当前的文件块的步骤,以对再次得到的当前的文件块进行处理。
17、可选地,所述特征数据包括fft变换后得到的值,相应地,所述申请所述预处理后的音频数据对应的特征数据的第二内存空间,包括:
18、确定所述当前一帧音频帧进行fft变换后的数据空间;
19、基于所述数据空间的二倍申请所述第二内存空间。
20、可选地,所述基于所述第二内存空间中的特征数据,显示所述当前一帧音频帧的特征信息,包括:
21、通过主进程以事件方式将所述第二内存空间中fft变换后得到的值发送至所述渲染进程;
22、通过所述渲染进程显示所述fft变换后得到的值对应的语谱图。
23、可选地,所述基于所述第二内存空间中的特征数据,显示所述当前一帧音频帧的特征信息,包括:
24、基于所述fft变换后得到的值计算fbank特征和/或梅尔频率倒谱特征;
25、通过主进程以事件方式将所述fbank特征和/或梅尔频率倒谱特征发送至所述渲染进程;
26、通过所述渲染进程显示所述fbank特征和/或梅尔频率倒谱特征对应的语谱图。
27、可选地,所述基于所述第二内存空间中的特征数据,显示所述当前一帧音频帧的特征信息,包括:
28、应用webgl可视化技术通过所述渲染进程显示所述fft变换后得到的值对应的语谱图、或者所述fbank特征和/或梅尔频率倒谱特征对应的语谱图。
29、可选地,预处理使用的预处理算法和特征提取使用的特征提取算法使用js编程语言实现;
30、或者,
31、预处理使用的预处理算法和特征提取使用的特征提取算法使用c++编程语言和动态链接库node-addon实现。
32、第二方面,提供一种电子设备,所述设备包括处理器和存储器;所述存储器中存储有程序,所述程序由所述处理器加载并执行以实现第一方面提供的音频数据处理方法。
33、第三方面,提供一种计算机可读存储介质,所述存储介质中存储有程序,所述程序被处理器执行时用于实现第一方面提供的音频数据处理方法。
34、本技术的有益效果至少包括:通过对待处理的音频文件进行分块,得到当前的文件块;根据预设的分帧策略,将当前的文件块中的音频帧逐帧依次加载至预先申请的第一内存空间;对第一内存空间中的当前一帧音频帧进行预处理,得到预处理后的音频数据;申请预处理后的音频数据对应的特征数据的第二内存空间;对预处理后的音频数据进行特征提取,得到当前的音频帧对应的特征数据;将特征数据存储至第二内存空间;基于第二内存空间中的特征数据,显示当前一帧音频帧的特征信息;在当前的文件块中的音频帧未加载完成的情况下,清空第一内存空间和第二内存空间,对下一帧音频帧触发执行根据预设的分帧策略,将当前的文件块中的音频帧逐帧依次加载至预先申请的第一内存空间的步骤,直至音频文件中的各帧音频帧均处理完成时停止;可以解决将音频文件全部加载至内存进行计算导致内存消耗较大,容易导致系统崩溃的问题;由于音频文件不需要全部加载至内存,仅需要将文件块逐个加载至内存,且在处理时对文件块逐帧加载处理,可以减少数据处理过程中的内存消耗,降低对设备的内存要求。
35、另外,通过js编写语音信号处理算法,可以为后续的语音处理实现方案提供更多的选择。
36、另外,通过应用webgl可视化技术显示特征数据,可以提升特征数据的展示性能。
37、上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,并可依照说明书的内容予以实施,以下以本技术的较佳实施例并配合附图详细说明如后。
- 还没有人留言评论。精彩留言会获得点赞!