一种基于多模型叠加的鼾声检测方法及装置与流程
本申请涉及鼾声检测,特别是涉及一种基于多模型叠加的鼾声检测方法及装置。
背景技术:
1、阻塞性睡眠呼吸暂停低通气综合征(osahs)是一种很常见的,也很容易被人们所忽略的疾病。主要是睡眠呼吸暂停低通气或不通气所导致的,该情况可能会引起患者白天嗜睡和反复的呼吸暂停现象的现象。通常该症状最为显著的特点就是可能会出现睡眠时伴随打鼾声,所以在对睡眠时进行鼾声识别,可以有效地检测出可能的阻塞性睡眠呼吸暂停低通气综合征。
2、现有技术一般采用单检测模型进行鼾声识别。对比文件1“一种基于深度学习算法的鼾声监测方法与系统以及相应的电动床控制方法和系统”(申请号202110803746.6),公开了使用预先训练好的深度学习模型进行深度特征提取和分类将每个音频片段分类为包含鼾声的音频切片和不包含鼾声的音频切片,对比文件1直接将mfcc特征数据通过神经网络进行判断,而没有对背景声进行识别处理。对比文件2“一种鼾声信号识别方法”(申请号201910834050.2),公开了使用k-means聚类算法识别出鼾声和非鼾声。对比文件1和对比文件2均存在一定的误检率。
技术实现思路
1、为了解决上述技术问题,本发明提供一种基于多模型叠加的鼾声检测方法及装置,在检测出背景声为寂静声后才进行鼾声检测,减少了因背景声为音乐声或人声时引起的误检测,提高了检测的准确率。
2、本发明采用如下技术方案:
3、一方面,一种基于多模型叠加的鼾声检测方法,包括:
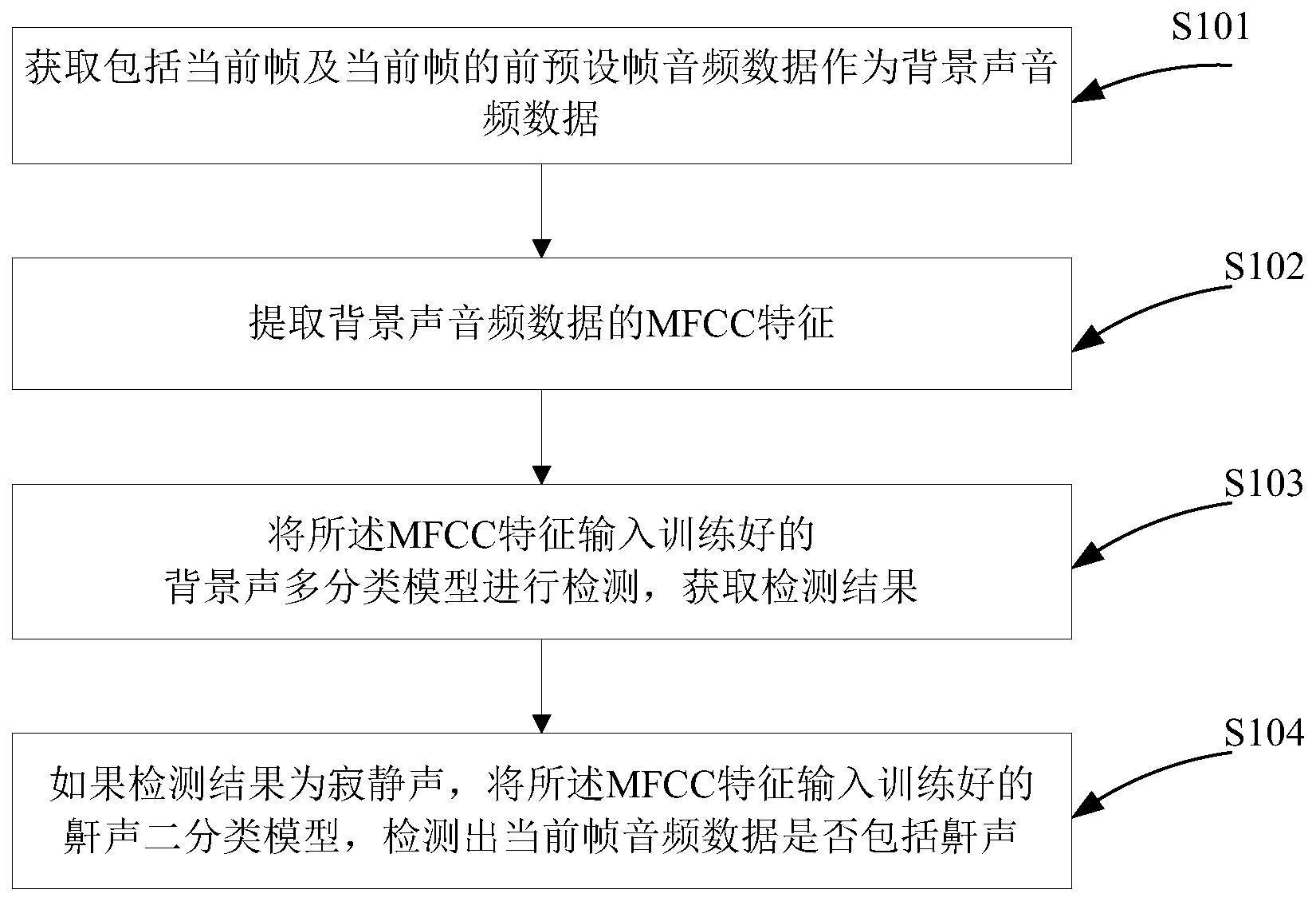
4、获取包括当前帧及当前帧的前预设帧音频数据作为背景声音频数据;
5、提取背景声音频数据的mfcc特征;
6、将所述mfcc特征输入训练好的背景声多分类模型进行检测,获取检测结果;
7、如果检测结果为寂静声,将所述mfcc特征输入训练好的鼾声二分类模型,检测出当前帧音频数据是否包括鼾声。
8、优选的,获取包括当前帧及当前帧的前预设帧音频数据作为背景声音频数据,具体包括:
9、获取当前帧音频数据;
10、将当前帧音频数据与帧缓存队列中的音频数据拼接后插入帧缓存队列;所述帧缓存队列采用先进先出原则且能够存储第一预设帧的音频数据;
11、判断缓存队列中是否包括第一预设帧的音频数据,如果是,将缓存队列中的音频数据作为背景声音频数据。
12、优选的,如果检测出当前帧音频数据包括鼾声,所述方法还包括:
13、计算当前帧音频数据的分贝值;
14、计算当前帧与前一次被判断为鼾声的帧的时间间隔;
15、更新当前存储列表的信息;所述信息包括时间戳和分贝值;
16、判断所述分贝值是否在预设分贝范围内,以及判断所述时间间隔是否在预设时间范围内,如果均满足,提示检测到鼾声。
17、优选的,将所述mfcc特征输入训练好的鼾声二分类模型之前,还包括:
18、将所述mfcc特征输入训练好的自编码器模型对特征进行编解码获得重建后的mfcc特征;
19、将所述mfcc特征输入训练好的鼾声二分类模型,检测出当前帧音频数据是否包括鼾声,具体包括:
20、将重建后的mfcc特征输入训练好的鼾声二分类模型,检测出当前帧音频数据是否包括鼾声。
21、优选的,所述自编码器模型为包括输入层、编码器层、解码器层和输出层的神经网络模型;
22、自编码器模型模型采用均分欧氏距离度量损失,如下:
23、
24、其中,xj表示模型输入的原始数据,表示模型输出的预测结果。
25、优选的,所述编码器层包括若干相连接的卷积层与池化层,所述解码器层包括若干相连接的卷积层与上采样层。
26、优选的,所述背景声多分类模型采用audiolitenet神经网络模型,包括若干相连接的块;块与块之间通过直接连接或跳层连接;所述直接连接是利用块中提前定义好的算子进行数据管道流式的计算;所述跳层连接为将特征进行相加处理。
27、优选的,所述背景声多分类模型采用五帧音频数据作为背景声音频数据,背景声多分类模型的输入为提取的mfcc特征,背景声多分类模型的输出为音乐声、人声和寂静声的置信度,取置信度最大的类作为检测结果。
28、优选的,所述鼾声二分类模型采用audiolitenet神经网络模型,包括若干相连接的块;块与块之间通过直接连接或跳层连接;所述直接连接是利用块中提前定义好的算子进行数据管道流式的计算;所述跳层连接为将特征进行相加处理。
29、优选的,所述鼾声二分类模型的输入为提取的mfcc特征,所述鼾声二分类模型的输出为鼾声和非鼾声的置信度,取置信度最大的类作为检测结果。
30、优选的,所述背景声多分类模型和鼾声二分类模型均采用二值化交叉熵损失函数,如下:
31、
32、其中,n表示需要度量的节点个数总量即分类总数,yi表示第i个节点真实标注的值即正确的分类,表示神经网络预测的第i节点的分类值。
33、另一方面,一种基于多模型叠加的鼾声检测装置,包括:
34、背景声音频数据获取模块,用于获取包括当前帧及当前帧的前预设帧音频数据作为背景声音频数据;
35、mfcc特征提取模块,用于提取背景声音频数据的mfcc特征;
36、背景声多分类模型检测获取模块,用于将所述mfcc特征输入训练好的背景声多分类模型进行检测,获取检测结果;
37、鼾声检测模块,用于在检测结果为寂静声时,将所述mfcc特征输入训练好的鼾声二分类模型,检测出当前帧音频数据是否包括鼾声。
38、本发明具有如下有益效果:
39、(1)本发明通过背景声多分类模型检测出背景声类型,在检测出背景声为寂静声后,使用鼾声二分类模型检测出鼾声或非鼾声,能够减少因背景声为音乐声或人声时引起的误检测,提高了检测的准确率;
40、(2)本发明在检测出背景声为寂静声后,使用自编码器模型对mfcc特征图谱进行编解码重建,将注意力集中在与鼾声相关联的特征图谱信息中,并将无关特征视为噪声进行去除,可能够达到在特征图谱上进行特征编码并去除一定噪声的效果;
41、(3)本发明用于检测背景声的背景声音频数据比用于检测鼾声的音频数据更长,能够进一步增加检测准确率;
42、(4)本发明使用鼾声二分类模型检测出鼾声后,进一步通过判断当前帧音频数据的分贝值的范围以及判断当前帧与前一次被判断为鼾声的帧的时间间隔是否在预设时间范围内,如果均满足,才提示检测到鼾声,增加了检测准确率。
43、为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
技术特征:
1.一种基于多模型叠加的鼾声检测方法,其特征在于,包括:
2.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,获取包括当前帧及当前帧的前预设帧音频数据作为背景声音频数据,具体包括:
3.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,如果检测出当前帧音频数据包括鼾声,所述方法还包括:
4.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,将所述mfcc特征输入训练好的鼾声二分类模型之前,还包括:
5.根据权利要求4所述的基于多模型叠加的鼾声检测方法,其特征在于,所述自编码器模型为包括输入层、编码器层、解码器层和输出层的神经网络模型;
6.根据权利要求5所述的基于多模型叠加的鼾声检测方法,其特征在于,所述编码器层包括若干相连接的卷积层与池化层,所述解码器层包括若干相连接的卷积层与上采样层。
7.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,所述背景声多分类模型采用audiolitenet神经网络模型,包括若干相连接的块;块与块之间通过直接连接或跳层连接;所述直接连接是利用块中提前定义好的算子进行数据管道流式的计算;所述跳层连接为将特征进行相加处理。
8.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,所述背景声多分类模型采用五帧音频数据作为背景声音频数据,背景声多分类模型的输入为提取的mfcc特征,背景声多分类模型的输出为音乐声、人声和寂静声的置信度,取置信度最大的类作为检测结果。
9.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,所述鼾声二分类模型采用audiolitenet神经网络模型,包括若干相连接的块;块与块之间通过直接连接或跳层连接;所述直接连接是利用块中提前定义好的算子进行数据管道流式的计算;所述跳层连接为将特征进行相加处理。
10.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,所述鼾声二分类模型的输入为提取的mfcc特征,所述鼾声二分类模型的输出为鼾声和非鼾声的置信度,取置信度最大的类作为检测结果。
11.根据权利要求1所述的基于多模型叠加的鼾声检测方法,其特征在于,所述背景声多分类模型和鼾声二分类模型均采用二值化交叉熵损失函数,如下:
12.一种基于多模型叠加的鼾声检测装置,其特征在于,包括:
技术总结
本发明提供一种基于多模型叠加的鼾声检测方法及装置,方法包括:获取包括当前帧及当前帧的前预设帧音频数据作为背景声音频数据;提取背景声音频数据的MFCC特征;将所述MFCC特征输入训练好的背景声多分类模型进行检测,获取检测结果;如果检测结果为寂静声,将所述MFCC特征输入训练好的鼾声二分类模型,检测出当前帧音频数据是否包括鼾声。本发明在检测出背景声为寂静声后才进行鼾声检测,减少了因背景声为音乐声或人声时引起的误检测,提高了检测的准确率。
技术研发人员:卢伟,严靖宇,邓亮涛,黄影
受保护的技术使用者:漳州松霖智能家居有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!