一种面向语音识别模型的动态掩码方法与流程
本发明涉及一种编码方法,具体为面向语音识别模型的动态掩码方法。
背景技术:
1、当前,语音识别技术已经应用到生活的方方面面,如语音搜索、语音助手、会议记录和智能音箱等。语音识别技术大大提高了生产生活效率。此外,语音识别技术一直是许多大型科技公司最重要的核心发展方向之一,并且语音识别领域的投资也进一步扩大。未来语音识别仍然有着巨大的市场,并能创造巨大的社会价值和经济价值。
2、尽管语音识别技术从理论研究到开发落地都取得了较好的成绩,但在实际应用过程中仍然存在一些问题,语音识别技术仍面临着挑战。在语音编码中,如何有效地进行语音编码是一个有待解决的问题。语音处理首先需要分辨出一段语音序列中存在的多种频率。宏观来说语音信号是不平稳的,要经过傅立叶变换,因此语音信号要分帧处理,来保证每一帧内的信号是平稳的。但是语音中信号非信息单元是非常多的,与非信息信号相对应的内容会增加声学编码中输入长度,导致占用过多计算资源。
3、基于transformer的模型越来越受欢迎,在各种序列到序列研究领域取得了最先进的性能。端到端模型从音频中提取高频特征(通常每10毫秒)。平均而言,这使得所产生的输入向量序列比相应的文本长10倍,导致内在的冗余(即长而重复的)表示。transformer在输入序列长度方面的复杂性使得它无法应用于通常由长序列表示的音频信号。transformer中的高层无法访问潜在有用的语言信息。为了解决这个问题,当前的解决方案是基于原始音频特征的固定采样进行初始次优压缩,但是这样transformer中的高层无法访问潜在有用的语言信息。
4、由于语音信号中信息传播不均匀,由此导致的信息特征提取困难。与非信息信号相对应的特征,如噪声,暂停等,增加了输入长度,并为各种声学任务带来了无法管理的噪声,增加学习难度的同时也降低了性能。因此,需要一种方法来稀疏编码器状态,将其应用于端到端系统来处理冗余和噪声语音信号。
5、由于transformer的自注意力机制的计算量与token数的平方成正比,所以如果保留完整的输入序列进行输入,则需要消耗巨大的计算资源,且会增加模型的建模复杂度。然而,在论文adaptive feature selection for end-to-end speech translation中说明,至少85%的语音输入是与信息无关的,模型的预测结果只与语音中的少部分的token有关。也就是说,我们可以动态去除掉一些重要性较低的token,而不会对模型的准确率带来较大的影响。
6、连接时序分类(connectionist temporal classification,ctc)是语音处理中一种多任务学习方法,可以将输入序列的每一位置都对应到标注文本中,学习语音和文字之间的软对齐关系。ctc是一个损失函数,通过在输出标签中增加空白符号(blank),通过最大化所有可能对应的序列概率之和,从而无需对训练数据进行划分和对齐,很好的解决了数据对齐问题,并且能够直接输出目标序列,大大简化了模型构建和训练难度。掩码是对某些值进行掩盖,使其在参数更新时不产生效果。有研究人员利用ctc的基于转录和音素的压缩来解决这个问题。然而,由于这些方法被应用于由transformer层编码的表征,出于记忆的原因,仍然需要对输入的初始内容进行不基于理解的下采样,有可能会丢失重要信息,进而影响模型的性能。ctc的尖峰特性又可以检测到空帧,如果只是简单的掩码掉这些元素,又会影响后续ctc的计算,无法帮助模型收敛。
7、因此,依据ctc的特点,探究一种掩码方式是非常必要的,期望可以减少计算资源,又不影响后续的ctc计算,同时可以提升模型表现。
技术实现思路
1、针对现有技术中声学编码中输入长度过长,占用过多计算资源,ctc无法计算及存在的信息丢失问题,本发明要解决的技术问题是提供一种语音识别模型的动态掩码方法,借助ctc的尖峰特性来检测空帧,将空帧掩码掉,减少计算资源,帮助模型收敛。
2、为解决上述技术问题,本发明采用的技术方案是:
3、本发明提供一种面向语音识别模型的动态掩码方法,包括以下步骤:
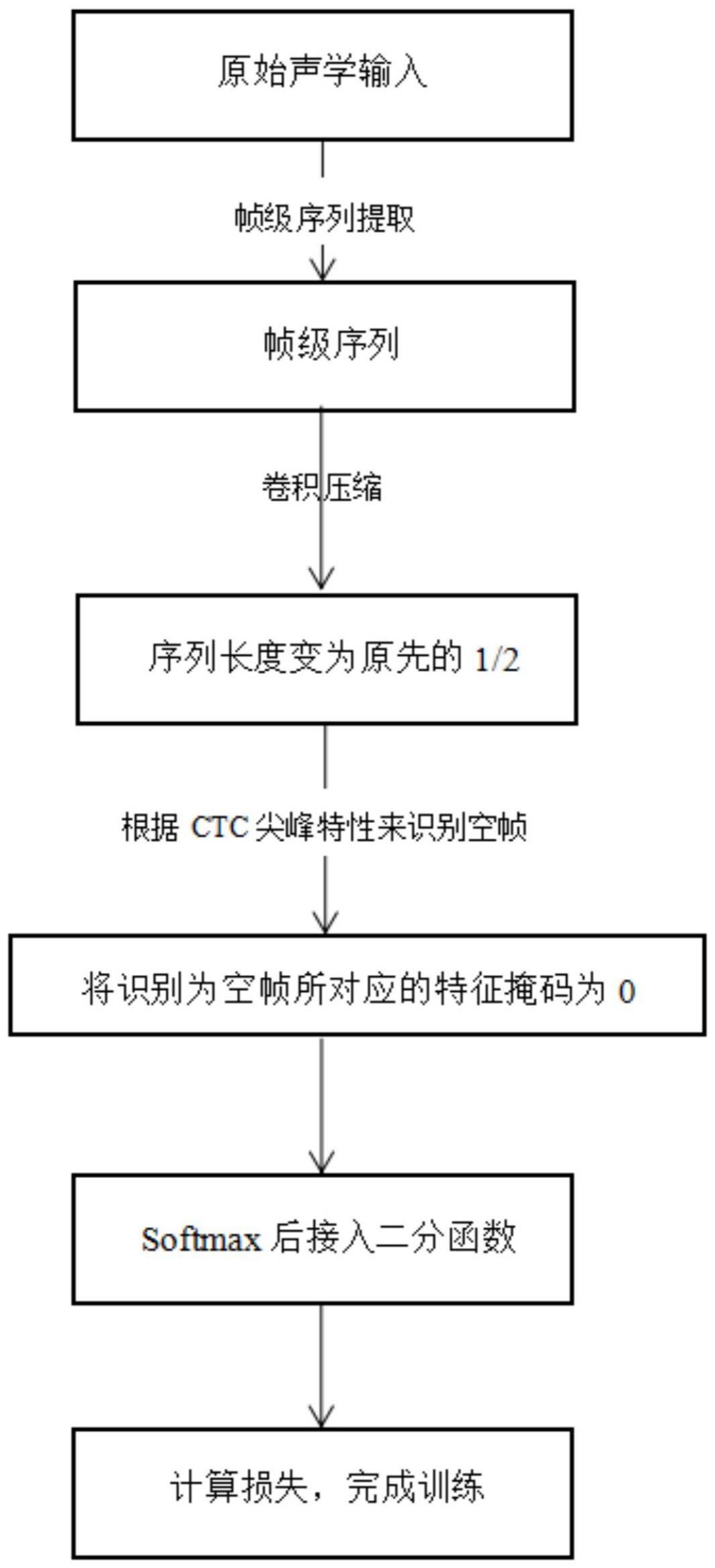
4、1)对语音数据集中原始音频输入进行声学特征提取,将原始的不定长时序信号转换成特征向量表示,通过分帧使声学信号由快速变化的非平稳参数信号变为阈值范围内的平稳信号,得到音频对应的帧级特征序列;
5、2)对音频对应的帧级特征序列进行编码,使用ctc进行序列建模,编码过程中基于ctc的尖峰特性,检测到空帧,将识别为空帧所对应的特征向量掩码为0;
6、3)定义二分函数来避免神经网络的行为不稳定和ctc计算问题;
7、4)将二分函数处理后的表示传递给语音识别模块,进而完成整个建模过程,最终实现动态掩码。
8、步骤2)具体为:
9、201)将音频特征序列输入到声学模型中,通过一个间隔为2、核大小为5的卷积层对其进行序列长度压缩,使序列长度变为之前的1/2;
10、202)压缩后的音频特征在经过编码器计算之后,通过ctc引入空字符来进行序列扩展,从而完成输入声学特征到输出预测字符的映射,得到对齐结果;
11、203)将ctc预测为blank的位置所对应的特征掩码为0,以代表无意义元素;
12、204)把blank所对应的特征位置的值加上无穷大的负数,经过softmax函数处理后,特征位置的概率为0。
13、步骤3)具体为:
14、301)在ctc的softmax函数后面接入一个二分函数,二分函数定义为如果输入大于0则直接返回输入,否则返回0;
15、302)将这个二分函数设置为斜率为1的线性函数,它的反向传播梯度为1,从而实现反向传播,解决ctc计算问题。
16、步骤4)具体为:
17、401)将声学模型作为语音识别模型的编码器,transformer仅由注意力机制和前馈神经网络组成,在自注意力机制中,其中包含查询(query,q),键(key,k)和值(value,v),其中键(key,k)和值(value,v)来自相同的内容,对查询矩阵、键矩阵以及值矩阵分别进行线性变换,然后进行缩放点积操作,即计算query与key进行点积计算,除以key的维度来达到调节作用,如下述公式所示:
18、
19、其中,q为查询矩阵,k为键矩阵,v为值矩阵,为key的维度。
20、402)将动态编码后的表示与ctc损失进行联合训练,计算联合训练损失,使用ctc后验对解码进行重新排序,通过解码器得到一个语音识别模型。
21、本发明具有以下有益效果及优点:
22、1.本发明提出一种面向语音识别模型的动态掩码方法,借助ctc的尖峰特性来检测空帧,将其对应的空帧掩码掉,从而在编码过程中逐步减小序列的长度,减少计算资源;
23、2.本发明方法可以克服因掩码相应特征所导致的ctc无法计算的问题;
24、3.本发明方法通过与ctc在解码阶段的结合,加速transformer模型的收敛速度。
- 还没有人留言评论。精彩留言会获得点赞!